SGLang Fused MoE 中高效的 MoE 对齐和排序设计




通过全面启用任意专家数量(MAX_EXPERT_NUMBER==256)的并发多块执行,并积极使用共享内存(5kB LDS)和寄存器(52 VGPRs,48 SGPRs),MoE 对齐和排序逻辑得以精心设计,实现在 A100 上 📈3 倍🎉,在 H200 上 📈3 倍🎉,在 MI100 上 📈10 倍🎉,在 MI300X/Mi300A 上 📈7 倍🎉的性能提升:...
作者:王磊 (yiak.wy@gmail.com)
SGLang Fused MoE 中高效的 MoE 对齐和排序设计
MoE 模型模仿了人脑的低功耗模式:功能被划分为多个部分,在思考时通过自适应路由部分激活。
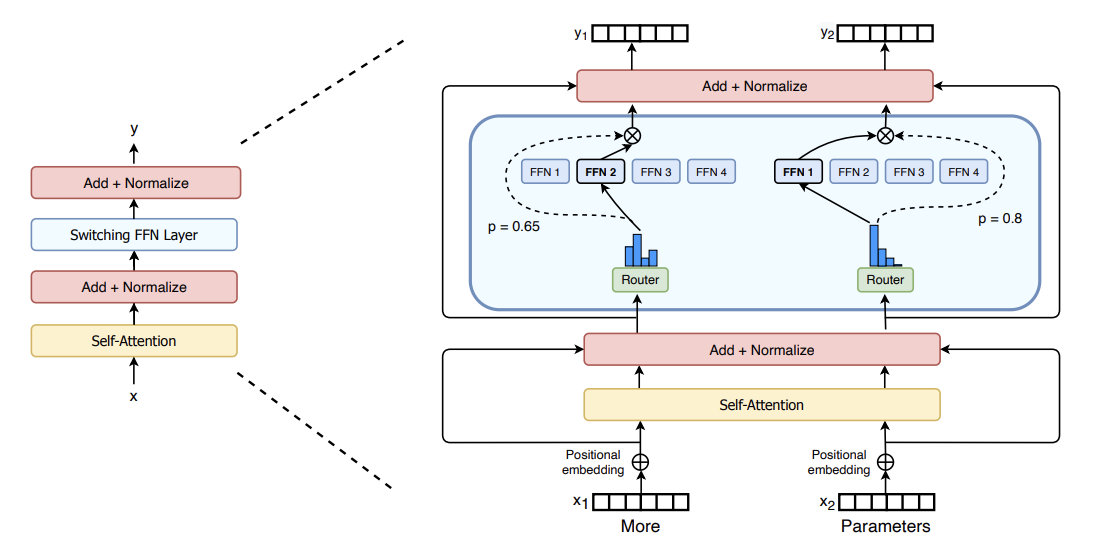
第一个真正可用的 CUDA 版本是 SwitchTransformer[1],然后 Mistral[2] 通过升级密集模型进行了改进
后来 DeepSeek V2/V3/R1 [3][4][5] 通过引入共享专家 [3] 和门控偏差 [4][5] 改进了 MoE,最终实现了无辅助损失的 MoE 模型 [4][5]。这主要归因于以下事实:当使用共享专家(DeepSeek 团队选择为 1)时,可以通过对大量专家(256)强制施加偏差分数惩罚来缓解专家路由不平衡问题 [11]。
MoE 层实现为多专家 FFN 层,它包含门控函数,根据 topk 门控分数(DeepSeek V3/R1 中带有偏差)路由激活,并通过对选定的 FFN 层进行 Group GEMM 来生成 logits。
该函数严重依赖底层的基数排序逻辑。通过 MoE 对齐和排序,ML 研究人员和实践者可以按专家 ID 的顺序对令牌进行排序。
在某些应用中,例如 TransformerEngine [6][7],该操作通过已弃用的 cub::DeviceRadixSort 实现,而 permute 用于记录 src(左) 到 dest(右) 的映射,其梯度为 unpermute。

尽管 cub::DeviceRadixSort 大量使用共享内存,这比仅使用线程局部内存的 __shfl_xor_sync 实现稍慢,但它不允许进行 对齐排序。
对齐排序对于 Group Gemm 效率至关重要,因为专家可以按块处理令牌。
SGLang 中的 MoE 对齐和排序算法采用了 对齐排序,但在处理 MoE 模型的大规模预填充操作(多达 256 个专家)时效率不高。该问题在 issue#2732 中被指出。当前的实现将 MoE 对齐和排序拆分为两次内核启动
对齐:在 单个块 内对基数排序算法进行传统的基于对齐的偏移量计算;
放置:根据在 多个块 中计算的偏移量放置令牌;
我们提出并编写了使用我们提出的 MoE 对齐和排序算法的 AMD 友好型 CUDA 内核。因此,将充分考虑 AMD 平台上的分析和优化。
通过使用 RocProfiler-Compute 进行不同的工作负载分析,我们可以清楚地看到,即使不计算跟踪配置文件中的多次内核启动开销,第一个内核也需要 33W 周期,第二个内核需要 8W 周期。
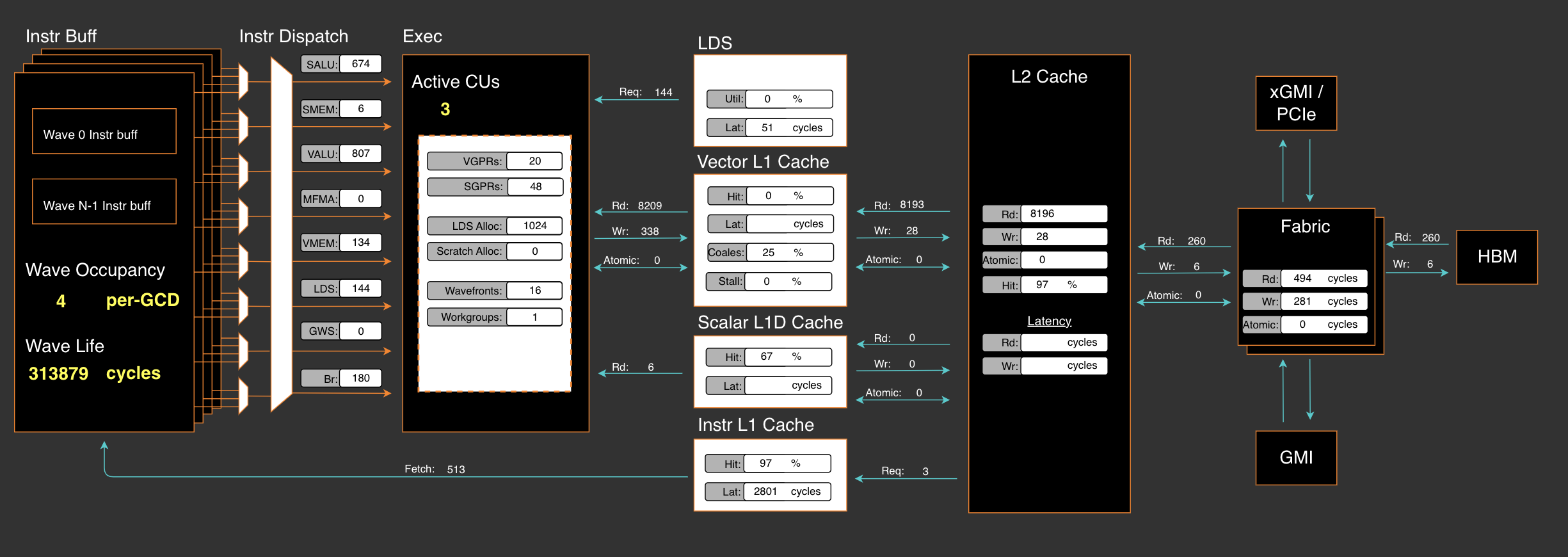
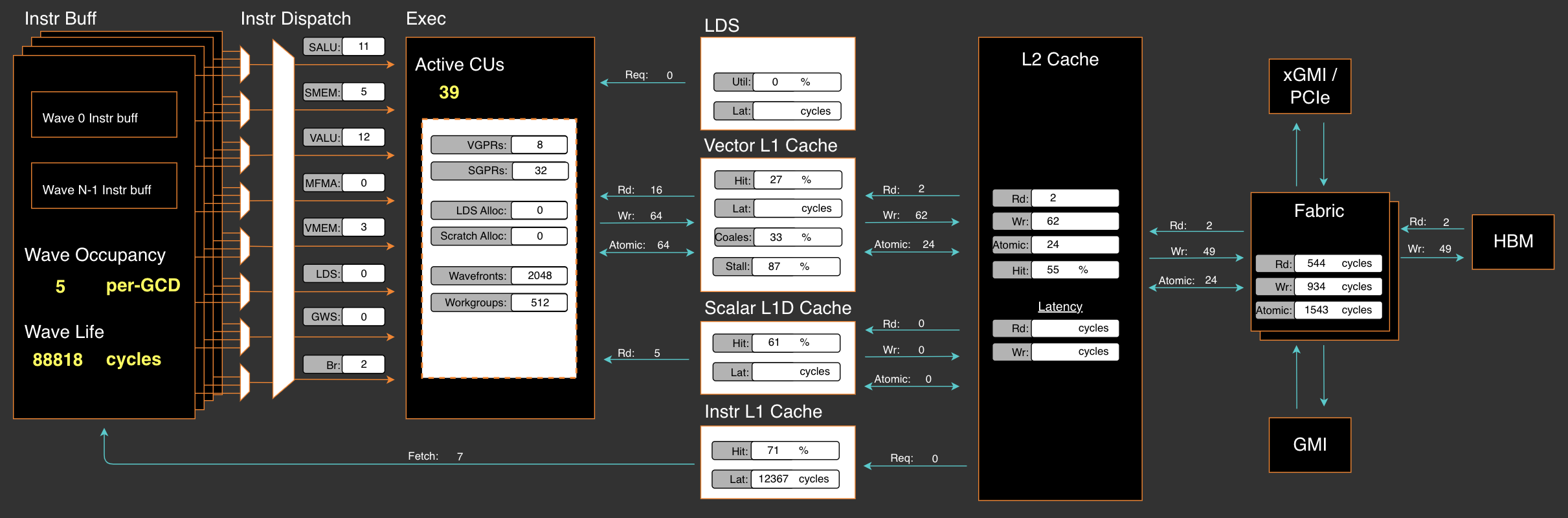
在 ROCm SDK 6.3.0 中,omniperf 已更名为 rocprof-compute。尽管它积极支持 MI300X/MI300A,但默认情况下并未随 ROCm SDK 6.3.0 提供。但是,设置 ROCm 计算分析器只需三个简单的步骤,如 Tools-dockerhub 中所示。
现在,在应用我们在 PR#3613 中提出的优化后,片上开销将立即从之前的 41W 周期减少到 20W 周期

通过全面启用任意专家数量(MAX_EXPERT_NUMBER==256)的并发多块执行,并积极使用共享内存(5kB LDS)和寄存器(52 VGPRs,48 SGPRs),MoE 对齐和排序逻辑得以精心设计,实现在 A100 上 📈3 倍🎉,在 H200 上 📈3 倍🎉,在 MI100 上 📈10 倍🎉,在 MI300X/Mi300A 上 📈7 倍🎉的性能提升。
| 优化基准测试(所有情况) | 优化基准测试(快照) | GPU |
|---|---|---|
| A100 | ||
| MI100 (gfx908) |
通过 Rocprof-Compute,我们可以轻松收集捕获到的内核的一些关键指标,并在远程 GUI 服务器中将其可视化
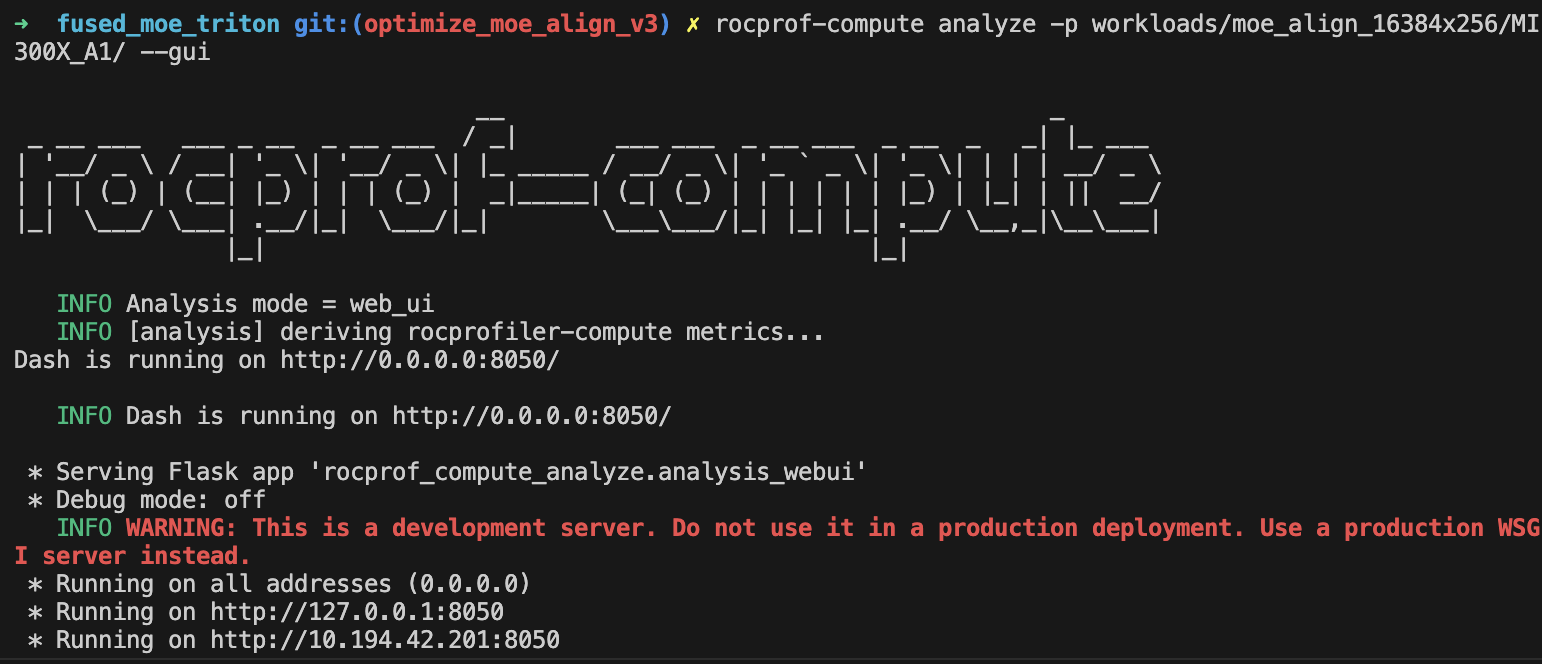
总结一下,在 AMD MI300X/MI300A 上,所提出的高效多块 MoE 对齐和排序算法积极使用了每波形向量寄存器(52 个),且没有寄存器溢出(我将初始线程块大小调整到最佳),并且每个 CU 使用了 LDS(5kB),冲突率仅为 6.8%。
我们还分析了 MoE 排序和对齐的屋脊线模型。屋脊线模型显示内核性能在内存受限区域下降。
在 AMD 计算配置文件 部分,我们详细介绍了 ROCm 平台上我们算法设计的数据分析和分析。
本质上,MI300X/MI300A 是世界上第一个基于多芯片设计的XPU高性能AI加速器架构。因此,在该芯片上进行操作的微调将与 NVIDIA 平台上的有所不同。
基本规则是,XCDs(加速计算管芯)之间的同步是昂贵的,最好充分利用 XCDs 和 L2 缓存局部性亲和性来提高性能。
当网格大小小于每芯片 XCD 数量(MI300X 为 8,MI300A 为 6)时,应避免通过使用 最低速度的计算管芯(MI300X 为 XCD7,MI300A 为 XCD5)进行昂贵的同步,或者当网格大小超过该阈值时,将其调整为每芯片 XCD 数量的倍数。
当块之间的数据交换(尤其是管芯间交换)增加时,通过 hipCooperativeLaunch 启动协作内核可能会增加 L2 缓存压力(与纹理寻址器停滞率和忙碌率相关)。
在这个例子中,之前 main 分支的实现使用了 39 个活动 CU,这 几乎很好,因为本质上使用了两个管芯。
我们的实现使用 66 个活动 CU 进行多块执行,横跨两个管芯,并且管芯间交换在块级归约中不可避免。我们将在本季度晚些时候向 SGLang 提交进一步的 V4 优化。
细节将在分析部分进一步讨论。
SGLang 中 MoE 对齐与排序的评论
SGLang 团队首先使用 triton 方法实现逻辑,并在 2024 年 12 月对 DeepSeek V3 的零日支持取得了巨大成功。
SGLang MoE 启动了在 triton 中实现的 融合 MoE 内核。
在内核启动之前,应用 MoE 对齐和排序算法。MoE 对齐和排序 triton 内核被分为 4 个阶段,其中直接访问 DRAM 而不使用共享内存,这与 向量化 triton 版本 相反。
与单块 CUDA 实现相比,多次启动以及对 LDS、本地缓存和寄存器(例如 VGPR)的低效使用导致小工作负载的单次测试执行效率低下。
然后 CUDA 实现最终被分为两个阶段,并且只有第二阶段的执行在多个块中加速。
其他开源平台中的 MoE 对齐和排序 CUDA 算法
FasterTransformer
在 Mistral[2] 和 DeepSeek V2[3] 之前,开放式密集模型在推理场景中更受欢迎。这正是 FasterTransformer[8] 诞生的时期。
在 NVIDIA 发起的 FasterTransformer[8] 项目中,MoE 模型主要通过 cub::DeviceRadixSort 和 moe_softmax(本质上是 cub::BlockReduce 中的 softmax)、moe_top_k 及其融合版本 topk_gating_softmax、用于排序潜在向量 logits 的 permute,最后是 group gemm 来支持的。
因此,融合很大程度上(按成本计算)限于 topk 门控 softmax、偏置 topk 门控 softmax,这些后来被整合到 SGLang 中。
Megatron
Megatron 在本文发布之前,对于 FP16/BF16,主要采用 FasterTransformer 方法,但增加了 permute 的梯度操作:unpermute,以促进 训练工作负载。
这意味着 MoE 也不能高效融合。
vLLM
SGLang 使用了许多 vLLM 内核,但 vLLM 的 Fused Moe 最初是由 DeepSeek 团队 贡献的,随后由 AnyScale 和 SGLang 提交者进行了完善。因此,他们采用了相同的方法。
CK
AMD 友好的融合 MoE 的第一个版本于 2024 年 11 月 26 日在 CK#1634 中提出。随后,MoE Align & Sort 在 CK#1771 和 CK#1840 中添加。
其高级思想是将 MoE 排序与 Group GEMM 融合。CK 中的 MoE 和排序在很大程度上采用了 SGLang 团队的方法,除了 CK 管道器和分区器。
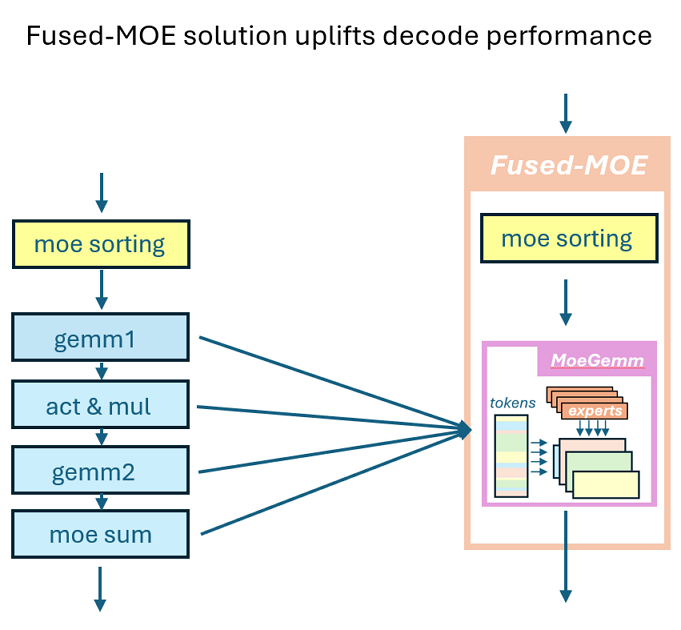
通过将基数排序计算逻辑整合到 Group GEMM 管道器中,可以立即解决 per_group_token_quant(用于在线 fp8 量化)、MoE 排序 和 Group GEMM 的融合:计算出现次数以计算偏移量,然后进行并行放置。
其中最关键的问题是如何平衡这两种工作负载(基数排序和 Group GEMM)。
在 AMD 数据中心芯片中,Group GEMM 片段更有可能均匀分布到 XCD 中的所有可用块。然而,如果涉及多个 XCD,不同 CU 中块之间的数据交换通过低速的 L2 缓存和 L2 缓存结构进行。
编写 CK 内核需要编写主机端的 CK 解决方案启动器
// Here is the entry of fused MoE :
// https://github.com/ROCm/composable_kernel/blob/1342ecf7fbf64f43d8621cf6665c583fdc49b2c6/example/ck_tile/15_fused_moe/instances/fused_moegemm_api_internal.hpp
using f_pipeline = ck_tile::FusedMoeGemmPipeline_FlatmmUk<f_problem>;
using f_partitioner = ck_tile::FusedMoeGemmTilePartitioner_Linear<f_shape>;
using f_kernel = ck_tile::FusedMoeGemmKernel<f_partitioner, f_pipeline, void>;
const dim3 grids = f_kernel::GridSize(a);
constexpr dim3 blocks = f_kernel::BlockSize();
constexpr ck_tile::index_t kBlockPerCu = 1;
static int printed = 0;
auto kargs = f_kernel::MakeKargs(a);
if(s.log_level_ > 0 && printed == 0)
{
std::cout << ", " << f_kernel::GetName() << std::flush;
printed = 1;
}
return ck_tile::launch_kernel(
s, ck_tile::make_kernel<blocks.x, kBlockPerCu>(f_kernel{}, grids, blocks, 0, kargs));
、内核的设备入口、瓦片分区器和阶段管道器。
AMD CK 分区器和用于融合 MoE 的阶段管道器也对最终组装非常有趣,但这超出了本文的范围。
但请记住,其 MoE 对齐和排序是生产者代码的一部分
// https://github.com/ROCm/composable_kernel/blame/fdaff5603ebae7f8eddd070fcc02941d84f20538/include/ck_tile/ops/fused_moe/kernel/moe_sorting_kernel.hpp#L438
CK_TILE_DEVICE void moe_align_block_size_kernel(...)
{
const index_t tid = static_cast<index_t>(threadIdx.x);
const index_t start_idx = tid * tokens_per_thread;
...
#if 1
if(tid < num_experts){ // each thread reduce a column segment of tokens_cnts with # blockDim.x elements
...
}
#else
...
#endif
__syncthreads();
// do cumsum to compute offsets based on condition
// do parallel placement based on the offsets computed
}
因此,AMD CK 解决方案中的 MoE 对齐和排序几乎与 SGLang 的主要实现一致,除了分区器和管道器。
请注意,该实现并不能始终保证在 AMD 平台上的最佳性能(参见 AITER 中的 asm MoE)。
由于 AMD CDNA3 架构不支持 Graphcore 类似的片上乱序(我们抽象并泛化了片上乱序作为 PopART[12] 和 PopRT 在 2023 年的 Remapping 操作)魔法,——现在 NVIDIA H100/H200/B200 通过高效的片上 SM<->SM 通信支持了这种魔法。
因此,在块之间廉价地调整数据布局以使其达到最佳状态,将是 AMD 开源解决方案中一个非常有趣的部分。
因此,从哲学上讲,这两种不同工作负载的基于平铺的融合代码可能并不总是优于非融合版本。本研究的详细信息将在我们的 V4 版本中进行。
AITER
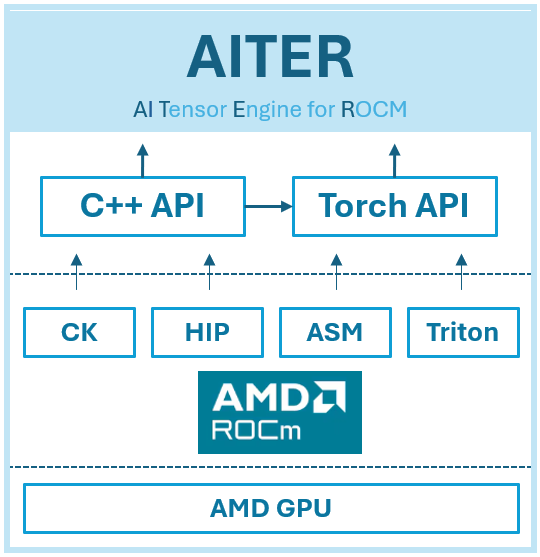
AITER 于今年年初推出,旨在整合不同项目中使用的 LLM 内核。它通过 ck moe、通过 hipModule 的 asm 版本 MoE 和 triton 融合 MoE 来支持融合 MoE。
因此,它部分开源,因为对 MI300X 开发人员来说,汇编代码和开发计划是不透明的。
据称 AITER 中融合 MoE 的 3 倍加速 [10] 已由 Bruce Xu [13] 验证,并且本质上来源于不同形状的 group GEMM 中观察到的加速:一个 GEMM,其中每个专家的 FFN 权重乘以令牌的隐藏状态块。
证据是 asm gemm 在 PR#199 中产生了近 3 倍的改进

值得注意的是,仍然存在选择从 SGLang 社区改编的 triton 内核的情况。为了在 MI300X/MI300A 上高效运行 triton 内核,他们使用多管芯架构特定的逻辑将线程块映射到管芯
# https://github.com/ROCm/triton/blob/f669d3038f4c03ee7a60835e875937c65b5cec35/python/perf-kernels/gemm.py#L115
...
## pid remapping on xcds
# Number of pids per XCD in the new arrangement
pids_per_xcd = (GRID_MN + NUM_XCDS - 1) // NUM_XCDS
# When GRID_MN cannot divide NUM_XCDS, some xcds will have
# pids_per_xcd pids, the other will have pids_per_xcd - 1 pids.
# We calculate the number of xcds that have pids_per_xcd pids as
# tall_xcds
tall_xcds = GRID_MN % NUM_XCDS
tall_xcds = NUM_XCDS if tall_xcds == 0 else tall_xcds
# Compute current XCD and local pid within the XCD
xcd = pid % NUM_XCDS
local_pid = pid // NUM_XCDS
# Calculate new pid based on the new grouping
# Note that we need to consider the following two cases:
# 1. the current pid is on a tall xcd
# 2. the current pid is on a short xcd
if xcd < tall_xcds:
pid = xcd * pids_per_xcd + local_pid
else:
pid = tall_xcds * pids_per_xcd + (xcd - tall_xcds) * (pids_per_xcd - 1) + local_pid
if GROUP_SIZE_M == 1:
pid_m = pid // num_pid_n
pid_n = pid % num_pid_n
else:
num_pid_in_group = GROUP_SIZE_M * num_pid_n
group_id = pid // num_pid_in_group
first_pid_m = group_id * GROUP_SIZE_M
group_size_m = min(num_pid_m - first_pid_m, GROUP_SIZE_M)
pid_m = first_pid_m + (pid % group_size_m)
pid_n = (pid % num_pid_in_group) // group_size_m
...
此外,CK 融合 MoE 中还使用了各种 AMD 芯片内在函数,例如
__builtin_nontemporal_load,
__builtin_amdgcn_ds_swizzle,
__builtin_amdgcn_ds_permute/__builtin_amdgcn_ds_bpermute,
__builtin_amdgcn_mov_dpp
等等。这些被认为是融合 MoE 最终汇编版本的原因。
例如,使用 __builtin_nontemporal_load,我们可以跳过 L2 缓存,为预计会被重用的数据在 L2 缓存行中留出更多空间。
Cutlass v3.8
在我撰写本文时,NVIDIA Cutlass 3.8.0 尚未公开支持融合 MoE。因此,此存储库中没有 MoE 对齐和排序功能。
TRT-LLM
在 v0.16.0 之前,TRT-LLM 主要遵循 FasterTransformer 方法。在 v0.17.0 之后,MoE 部分被披露。
采用 AMD 友好的 CUDA 实现,实现 3 到 7 倍的加速
该算法采用多块执行方案,由 3 个不同部分(D-C-P)组成
- 分布式并发计数
- 计算累加和
- 并行未对齐的局部累加和
- 归约未对齐的累加和
- 对齐全局累加和
- 存储全局累加和
- 并行放置

并行未对齐的局部累加和

该算法由我们首次在 PR#2970 中提出并实现。
我们平衡了每个块中的累加和执行到 kElementsPerThr(16) 个线程,其中每个线程需要处理 kElementsPerThr + kElementsPerThr + threadIdx.x 个加法操作。
因此,与当前仓库中的单线程版本相比,波前更快地达到,我们在此版本实现中观察到 30% 的改进。
归约未对齐累加和
一旦我们在每个块中获得局部未对齐累加和,我们就对预分配的 HBM 缓冲区中存储的累加和进行块级归约。
我们选择 FRAG_SIZE_M(16) x FRAG_SIZE_N(16) x FRAGS_PER_BLOCK(4) 个 SRAM 片段进行块级归约,其中 FRAGS_PER_BLOCK 是可调的
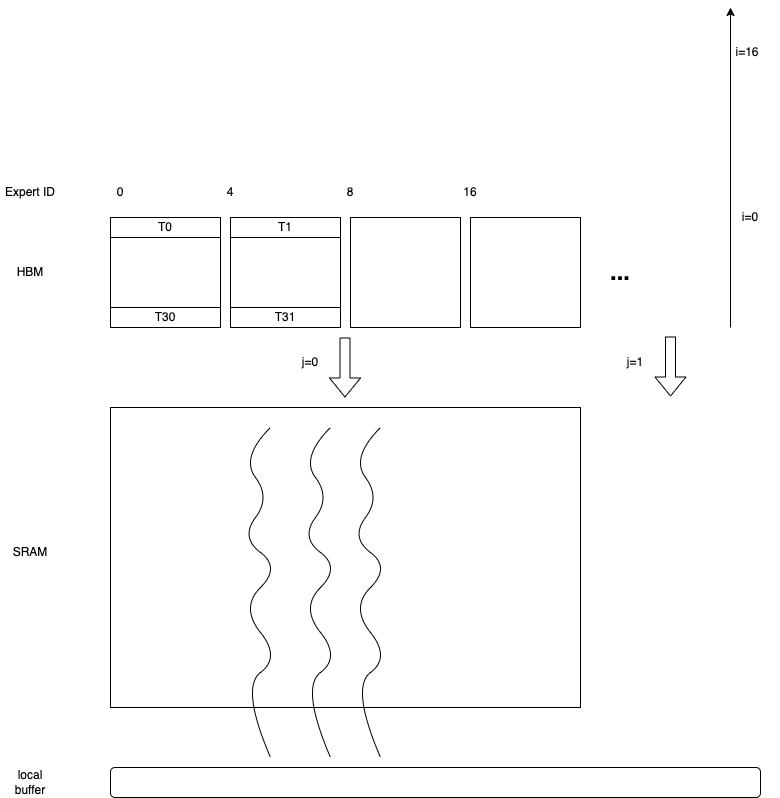
在 AMD 平台中,计算基于 1 warp 加载/1 warp 计算,而在 NVIDIA 平台中,是 2 warps 加载和 1 warp 计算。
该设计充分利用了 CDNA3 架构中 AMD 64 SIMD 通道的优势。并且在多管芯架构芯片中,块的数量始终是 XCD 数量的倍数。
FRAGS_PER_BLOCK 设置为 4,以利于多轮中 SMEM 的重复使用。
对齐全局累加和并存储全局累加和
我们改进了矢量化代码,并处理了输入数据大小与 kElementsPerAccess 常量未对齐时的循环尾部。
基准测试显示合并率有所提高,但仍限制在 30%。我们将在 V4 版本中解决此问题。
编写 AMD 友好型 CUDA
编写 PyTorch 扩展程序可以在 ROCm SDK 的帮助下将 CUDA 内核自动转换为 HIP 内核。
然而,在某些情况下,HIP 内核与 CUDA 内核的工作方式不同
Warp size 是一个依赖于架构的全局变量,在 ROCm SDK 中定义为 warpSize;在 CDNA3 架构中,warpSize 定义为 64
设备函数签名可能无法与 CUDA 完全对齐,需要条件编译来支持这些符号
了解多管芯芯片架构中的 L2 缓存优化
基准测试
我们对 DeepSeek v3 模型的大规模工作负载进行了广泛测试,没有进行 CUDA 图捕获。因此,专家数量设置为 256。该算法目前不支持在 CUDA 图捕获下运行,我们将在 V4 版本中解决此问题。
由于 GPU 机器的虚拟化和分配给测试节点的 CPU 数量,性能可能会不时地与裸机测试有所不同。
因此,我们使用 triton 实现作为基线,以演示我们提出的 MoE 对齐和排序算法的加速倍数和效率。
每次测试在基准测试之前都经过验证。在基准测试期间,我们观察到在 AMD 平台上,triton 的运行时间明显长于 NV 平台。因此,我们建议对 triton MLIR 进行进一步优化,以实现比 NVIDIA triton 更高效的降级过程。
对于 AMD triton,我们观察到 MI300X 快了 1.5 倍,因此 MI300X 的改进倍数不如 MI100 显著。而且,尽管 MI300X 通常被认为比 MI100 快,但在我们的测试中,MI100 上的算法表现优于 MI300X。
这部分归因于以下事实:对于内存受限的操作,多管芯芯片之间的通信会降低执行速度。
在这两个平台上,我们观察到在应用我们提出的算法后有显著的改进,而现有的 CUDA 实现几乎与 Triton 花费相同的时间。
AMD 系统准备
为了更好地利用 AMD 异构系统,建议进行一些检查。
NVIDIA Grace CPU 和 AMD EPYC 9004 系统通常都建议禁用 NUMA 自动平衡以与 GPU 配合使用;但是,在某些情况下不是这样。
当虚拟化启用时,建议使用 IOMMU 直通模式以消除 DMA 转换,从而提高性能。
MI100 基准测试
git clone https://github.com/yiakwy-xpu-ml-framework-team/AMD-sglang-benchmark-fork.git -b optimize_moe_align_v3 && cd sgl-kernel && python setup_rocm.py install
可以验证不同输入令牌和专家组合的可行性
cd ../benchmark/kernels/fused_moe_trition && python benchmark_deepseekv3_moe_align_blocks.py --verify
| 令牌数 | 专家 | SGLang | Triton (AMD) | GPU |
|---|---|---|---|---|
| 8192 | 256 | 79.36 | 426.71 | MI100 |
| 16384 | 256 | 86.4 | 681.12 | MI100 |
| 16384 x 128 | 256 | 3047.68 | 62442.85 | MI100 |
| 32768 x 128 | 256 | 7211.37 | 129388.43 | MI100 |
A100 基准测试
| 令牌数 | 专家 | SGLang | Triton (NV) | GPU |
|---|---|---|---|---|
| 8192 | 256 | 77.44 | 124.92 | A100 |
| 16384 | 256 | \ | \ | A100 |
| 16384 x 128 | 256 | 5966.81 | 17396.51 | A100 |
| 32768 x 128 | 256 | 12450.05 | 34711.14 | A100 |
H200 基准测试
| 令牌数 | 专家 | SGLang | Triton (NV) | GPU |
|---|---|---|---|---|
| 8192 | 256 | \ | \ | H200 |
| 16384 | 256 | \ | \ | H200 |
| 16384 x 128 | 256 | 4508.42 | 12361.15 | H200 |
| 32768 x 128 | 256 | 9023.48 | 24683.70 | H200 |
MI300X 基准测试
| 令牌数 | 专家 | SGLang | Triton (AMD) | GPU |
|---|---|---|---|---|
| 8192 | 256 | 88.16 | 281.64 | MI300X |
| 16384 | 256 | 134.02 | 448.88 | MI300X |
| 16384 x 128 | 256 | 6865.64 | 43266.09 | MI300X |
| 32768 x 128 | 256 | 13431.80 | 89788.58 | MI300X |
AMD 计算性能分析
设置
在 ROCm 6.3.3 中,设置 rocprof-compute 可以轻松完成三步设置,详细信息可在此处找到:https://github.com/yiakwy-xpu-ml-framework-team/Tools-dockerhub/tree/main
矢量 L1 缓存分析结果
除非另有说明,否则工作负载为 16384 个令牌 x(256 个专家中的前 8 个专家)。
| 内核 | VGPRs | SGPRs | 活跃 CU | 矢量 L1 缓存命中率 | 合并率/利用率 |
|---|---|---|---|---|---|
| 旧主干 moe_align_block_size_kernel (k1) | 20 | 48 | 3 | 0% | 25% / 7% |
| 旧主干 count_and_sort_expert_tokens_kernel (k2) | 8 | 32 | 39 | 27% | NaN |
| 我们的 moe_align_block_size_kernel | 52 | 48 | 66 | 61% | 36% / 18% |
我们在算法中最大限度地利用了 VGPRs,但减少了 SGPRs 的总使用量。数据还表明 VGPRs/SGPRs 没有溢出,这表明寄存器使用健康,并且此内核没有性能损失。
向量 L1 缓存(vL1D)是每个 CU 的本地单元,命中率记录了从 L2 缓存到 CU 的数据请求的缓存行命中率。vL1D 的纹理寻址器合并了 30% 的 L2 缓存请求,并达到了 61% 的命中率,必要时还可以进一步提高。
当数据从 CU 请求到 vL1D 的寻址处理单元(纹理寻址器)时,有四种状态供该复合体决定是否接受或回滚数据请求到 CU,通过 vL1D 中的数据处理器单元。
忙碌:纹理寻址器正在处理地址
地址停滞:纹理寻址器停止向 vL1D 发送地址
数据发送停滞:纹理寻址器停止向 vL1D 发送数据
数据等待停滞:纹理寻址器停止等待向 vL1D 中的数据处理器单元发送数据
此微架构行为的详细信息可在 AMD CDNA3 ISA 和 rocProfiler-compute 文档 中找到。
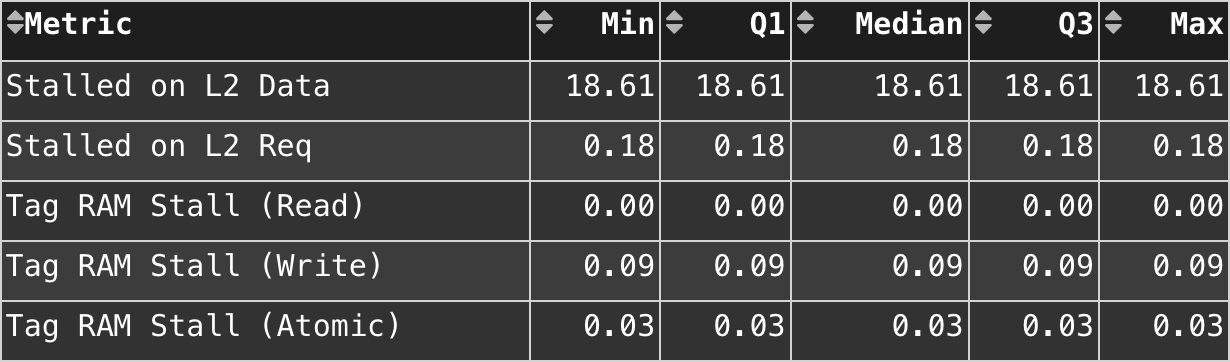
我们在这个算法设计中观察到矢量 L1 缓存有 18.61% 的数据等待停滞率。
数据读/写负载均衡从 8 kB 读操作、27 B 写操作大幅减少到 109 B 读操作、468 B 写操作和 202 B 原子操作的组合。
L2 缓存分析结果
在 CDNA3 架构中,L2 缓存由所有 CU 共享,是不同 CU 之间线程块共享数据的主要入口。
通过多通道和地址交错设计,L2 缓存的请求可以大部分并发处理。
此外,通过 AMD 特定内联函数,例如 __builtin_nontemporal_load,我们可以绕过 L2 缓存,对于不需要再次访问的数据。
L2 缓存研究的详细信息将在 V4 版本中披露。
结论
新算法通过最大限度地利用 LDS 和向量寄存器,在 CUDA 和 ROCm 平台上显著加速了 MoE 对齐和排序,达到 3 到 7 倍的性能提升。
我们还观察到,内存受限的操作在多管芯芯片上的性能可能比单管芯芯片差,这表明在编程 MI300X/MI300A 和 B200/B300 等多管芯芯片的设备代码时,有一个新的微调方向。
然而,算法的细节仍然可以进行改进,以提高缓存命中率和主内存合并率。
致谢
特别感谢来自 NUS 团队的张涵教授(hanzhangqin8@gmail.com)和王云洪博士(yunhongwang2000@gmail.com)在 MI100/MI250 性能验证方面的合作,Zev Rekhter(connect@evergrid.ai)在 MI300X 性能验证方面的合作,范舒宜(fsygd1996@163.com)在 H200 验证方面的合作,以及 BBuf(1182563586@qq.com)在 SGLang 解决方案讨论和评审方面的贡献。
请注意,这是 SGLang 社区之外的独立工作。
我还要衷心感谢 Bingqing、Peng Sun 和 ShawHai,他们抽出时间审阅了这篇文章,并提出了修改建议。
参考文献
- W. Fedus, B. Zoph, and N. Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. CoRR, abs/2101.03961, 2021. URL https://arxiv.org/ abs/2101.03961。
- A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. d. l. Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, et al. Mistral 7b. arXiv preprint arXiv:2310.06825, 2023。
- DeepSeek-AI. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model. CoRR, abs/2405.04434, 2024c. URL https://doi.org/10.48550/arXiv.2405.04434。
- DeepSeek V3 : https://arxiv.org/abs/2412.19437; 检索于 2025 年 3 月 18 日
- DeepSeek R1 : https://arxiv.org/pdf/2501.12948; 检索于 2025 年 3 月 18 日
- TransformerEngine : https://github.com/NVIDIA/TransformerEngine; 检索于 2025 年 3 月 18 日
- NV Group GEMM : https://github.com/yiakwy-xpu-ml-framework-team/NV_grouped_gemm; 检索于 2025 年 3 月 18 日
- FasterTransformer : https://github.com/NVIDIA/FasterTransformer; 检索于 2025 年 3 月 18 日
- CK Fused MoE V1 : https://github.com/ROCm/composable_kernel/pull/1634
- AMD 3X MOE : https://rocm.blogs.amd.com/artificial-intelligence/DeepSeekR1-Part2/README.html
- Lean Wang and Huazuo Gao and Chenggang Zhao and Xu Sun and Damai Dai Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts, 2024. URL https://arxiv.org/abs/2408.15664。
- PopART on chip TensorRemap : https://github.com/graphcore/popart/tree/sdk-release-3.4
- DeepSeek V3 Optimizatoin based on AITER backend : https://github.com/sgl-project/sglang/pull/4344
赞助来源
另见 AMD, evergrid.ai , 新智元 和 Github