SGLang v0.4.8 中 H800x104 DGX SuperPod 解耦策略的综合研究




我们使用 13x8 H800 DGX SuperPod 节点,在解耦的 LLM 推理架构中评估了最大预填充和解码的良好吞吐量(在 SLO 下的吞吐量,即 TTFT < 2s,ITL < 50ms)[6]。该系统在各种服务器端解耦配置((P3x3)D4 (即 3 组 P3,1 组 D4)、P4D9、P4D6、P2D4、P4D2、P2D2)下,输入吞吐量达到了约 130 万 tokens/秒,最大输出吞吐量达到了 20,000 tokens/秒。在主要情况下,预填充是实验中的瓶颈,导致 TTFT 很高。参考 DeepSeek 工作负载[9]中计算出的解码/预填充节点比率
1.4,为了实现高服务器端良好吞吐量,我们尝试了更大的P节点组 (3) 和更小的 TP 大小 (24)。性能使用 SGLang 的bench_one_batch_server.py基准测试脚本[1]进行测量,该脚本评估 URL API 调用性能,随后使用genai-bench[10]在不同并发级别下生成更可靠的输出吞吐量。在用户端,我们根据服务水平目标 (SLO) 进行在线观察,使用 evalscope [2] 对支持 API 密钥身份验证的 OpenAI 兼容端点 API 进行基准测试。在这些条件下,系统在并发 50 时维持了 25,000 tokens/秒的输出吞吐量,在并发 150 时对于小输入查询维持了 55,000 tokens/秒的输出吞吐量。我们观察到,当batch size × input length超过某个阈值(例如,由于 KV 缓存传输限制[7])时,首次生成令牌时间(TTFT)急剧增加。此外,为了获得更好的良好吞吐量,输入序列长度(ISL)与输出序列长度(OSL)应保持特定比例,最好是 4:1。因此,如果我们希望以更大的批处理大小和序列长度实现高吞吐量,则整体延迟主要由 TTFT 决定。为了保持高 GPU 利用率和良好吞吐量,并发量应小于 128,以避免 TTFT 急剧增长。这种平衡在H800DGX SuperPod 系统上特别有效。过高的 TTFT 会导致输出吞吐量不稳定,并导致服务器端良好吞吐量显著下降。
作者: 王磊 (yiakwang@ust.hk), 蒲玉洁 (yujiepu@ust.hk), 郭安迪 (guozhenhua@hkgai.org), 巢弋 (chao.yi@hkgai.org), 王怡雯 (yepmanwong@hkgai.org), 薛伟 (weixue@ust.hk)
目录
动机与背景
在预填充-解码聚合的 LLM 推理架构中,预填充令牌和解码令牌之间的交错调度计划已在 vLLM 2024 年第二季度之前实施,随后通过连续调度[3]得到了改进,整体 GPU 利用率更高。
然而,由于预填充和解码阶段计算性质的差异,将传入请求的完整未分块预填充令牌与运行中请求的解码令牌连续批处理会显著增加解码延迟。这导致较大的令牌间延迟(ITL)并降低响应能力。
为了解决这个问题,提出了分块预填充功能[4],并在 PR#3130 中引入,以便将传入请求的分块预填充令牌和运行中请求的解码令牌在共置系统中进行批处理,如下所示,以获得更好的 ITL 和 GPU 利用率

然而,分块预填充没有考虑到预填充和解码之间不同的计算性质。
解码过程通常由 CUDA 图捕获以进行多轮生成,因此当解码与分块预填充批处理时会带来额外的开销,因为 CUDA 图不适用于这种情况。
此外,正如在 DistServe [4][5][6] 对 13 B 密集模型以及我们对 671 B MoE 模型的实验中所观察到的,一旦在共置服务系统中 batch_size x output_length 超过某个阈值(即 128 x 128),预填充计算成本会显著增加,而与分块大小无关。
因此,提出了解耦服务架构[4]。DeepSeek 通过 DeepEP 和 MLA 进一步降低了延迟和提高了吞吐量,这些功能很快被集成到 SGLang 中,系统在部署单元 P4D18 下,在 SLOs 方面实现了惊人的 73.7k toks/节点/秒和 14.8k toks/节点/秒。
然而,一个常见的误解是,P 节点的数量不应超过 D 节点的数量,因为 DeepSeek 在其博客文章 [8] 中没有披露 P 与 D 节点的实际比例。
根据其公布的每天 24 小时内总服务令牌量 608B 输入令牌 和 168B 输出令牌,以及预填充/解码速度,使用的预填充节点总数估计为
,解码节点总数估计为
解码/预填充节点的参考测试比率计算为 1.4 = 1314 / 955,而 P4D18 配置比率为 3.27 : 1 = (955 / 4) / (1314 / 18)。对于 H800 13x8 DGX SuperPod,因此建议采用 P/D 解耦配置 (P3x2)D4、(P3x3)D4 和 (P4x2)D4。由于预填充在我们分析中更可能是系统的瓶颈,我们将 TP 大小限制为 4,因为更大的 TP 大小会降低推理速度,而更小的 TP 大小会导致 KV 缓存保留的容量更少。
在我们的测试中,由于更小的 TP 大小和相对更多的预填充阶段处理能力,(P3x3)D4 和 P4D6 在 TTFT 方面优于 P9D4。
| 并发 | 输入 | 输出 | 延迟 | 输入吞吐量 | 输出吞吐量 | 总吞吐量 | TTFT (95) (秒) | |
|---|---|---|---|---|---|---|---|---|
| (P3x3)D4 | 1 | 2000 | 200 | 901.13 | 214.74 | 21.75 | 0.44 | |
| 2 | 2000 | 200 | 611.92 | 413.22 | 41.83 | 0.61 | ||
| 8 | 2000 | 200 | 160.74 | 1,587.72 | 160.74 | 2.69 | ||
| 64 | 2000 | 200 | 27.27 | 9,267.40 | 938.58 | 2.91 | ||
| 128 | 2000 | 200 | 18.64 | 13,555.56 | 1,372.96 | 7.69 | ||
| 256 | 2000 | 200 | 21.60 | 23,398.95 | 2,370.23 | 8.4 | ||
| 512 | 2000 | 500 | 522.80 | 31,016.53 | 7,852.82 | 4.97 | ||
| 1024 | 2000 | 500 | 374.90 | 53,494.96 | 13,543.28 | 9.85 | ||
| P4D6 | ||||||||
| 1024 | 1024 | 32 | 15.85 | 75,914.78 | 16,103.44 | 68,234.85 | 13.81 | |
| 1024 | 1024 | 128 | 18.30 | 100,663.25 | 16,626.85 | 64,462.25 | 10.42 | |
| 1024 | 1024 | 256 | 23.97 | 95,540.18 | 20,176.66 | 54,686.99 | 10.98 | |
| 1024 | 1024 | 512 | 39.84 | 79,651.21 | 19,654.31 | 39,479.45 | 13.16 | |
| 2048 | 2048 | 256 | 60.08 | 77,367.28 | 89,299.88 | 78,533.27 | 54.21 | |
| P4D9 | ||||||||
| 64 | 128 | 128 | 12.51 | 1,701.88 | 1,064.16 | 1,309.50 | 4.81 | |
| 64 | 4,096 | 128 | 20.21 | 22,185.68 | 975.58 | 13,374.37 | 11.82 | |
| 64 | 2,048 | 128 | 41.70 | 3,553.74 | 1,699.56 | 3,339.43 | 36.88 | |
| 64 | 1,024 | 128 | 69.72 | 1,017.38 | 1,543.28 | 64.42 | ||
| 512 | 4,096 | 128 | 36.75 | 85,749.88 | 5,332.19 | 58,853.06 | 24.46 | |
| 512 | 2,048 | 128 | 213.43 | 5,021.26 | 14,249.05 | 5,220.12 | 208.83 | |
| 512 | 1,024 | 128 | 112.81 | 4,849.07 | 13,976.04 | 5,228.45 | 108.12 | |
| 1,024 | 4,096 | 128 | 58.47 | 77,876.48 | 28,407.07 | 73,972.85 | 53.86 | |
| 2,048 | 4,096 | 256 | 105.21 | 80,227.44 | 808,820.03 | 84,716.46 | 104.56 | |
| 2,048 | 2,048 | 256 | 72.53 | 89,296.97 | 20,513.48 | 65,058.45 | 46.97 |
我们使用 SGLang v0.4.8 中我们自己的微调版 DeepSeek V3 (0324) 类似模型,在大规模下进行了聚合和解耦服务实验。
给定输入序列长度(in_seq_len:128 ~ 4096)和短输出序列长度(out_seq_len:1~256),通过调整各种批量大小(bs),我们得出结论:
在聚合 LLM 推理架构中,服务 DeepSeek V3 类似的大型 MoE 模型时,预填充的最大良好吞吐量出现在特定的
批量大小 (bs) x 输出长度 (out_seq_len);在解耦 LLM 推理架构中,则出现在特定的批量大小 (bs) * 输入长度 (in_seq_len);预填充更可能是瓶颈,因此建议使用更多的预填充组(P3x3,即 3 组 P3),并且预填充组与解码组的
WORLD_SIZE比率建议在 (0.75(P3D4), 1(PXDX)) 范围内;
与在 DistServe [4][5][6] 中服务 13 B 密集模型不同,服务 671 B 大型 MoE 模型(256 个专家中的 8 个,加上 P * 8 个冗余专家)时,预填充的良好吞吐量受到输出长度和批量大小的乘积的负面影响,直到达到其最大值。详细统计数据可在附录中找到。
预填充解码共置架构 H800 x 2 测试回顾
在 H800 x 2 (DGX SuperPod) 测试配置中,每个节点通过 infiniband 连接,最大输入吞吐量达到 20k toks/秒
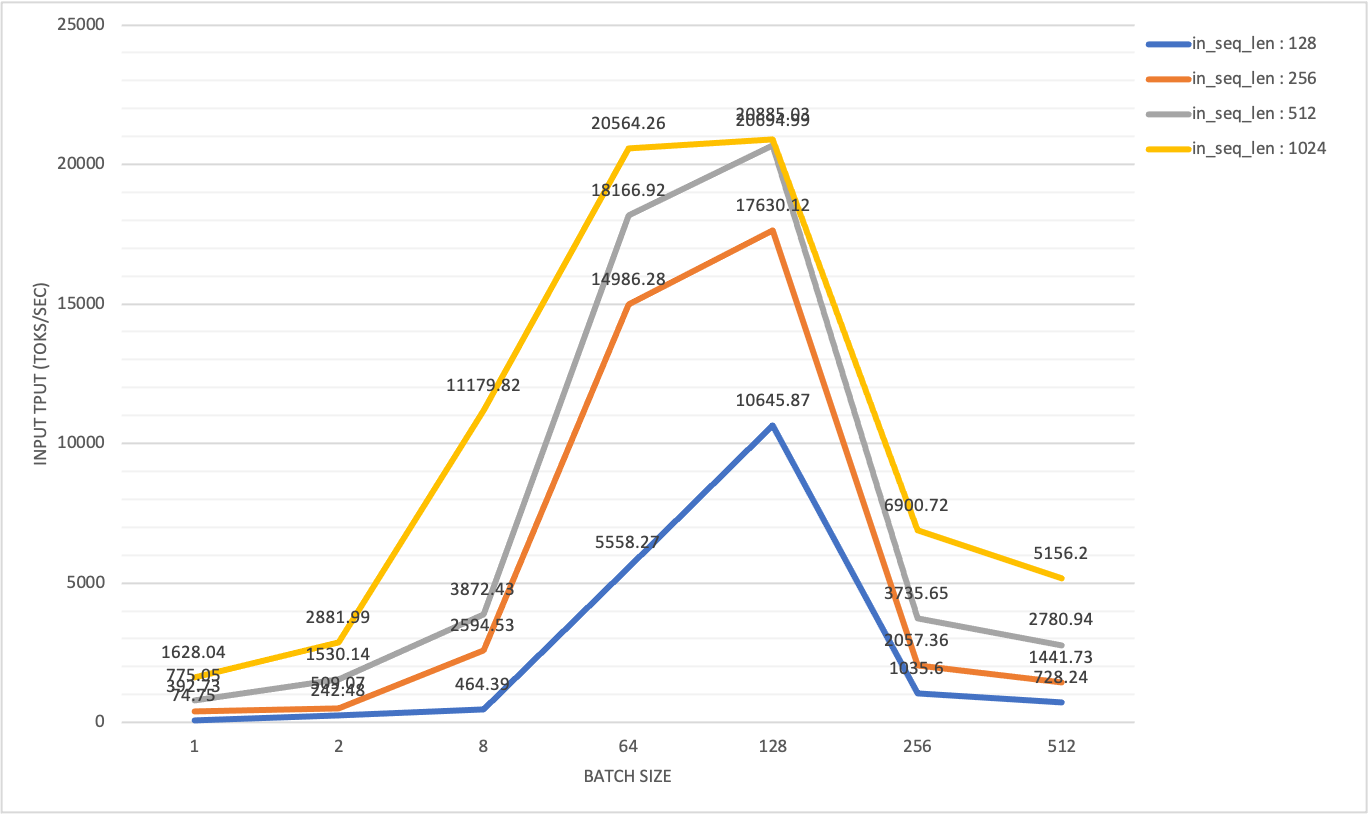
当 batch size x output length 超过 128x128 时,我们观察到输入吞吐量显著下降,同时 TTFT 突然急剧增长。相比之下,输出吞吐量随着批处理量的增加而逐渐增加,并达到最大值。
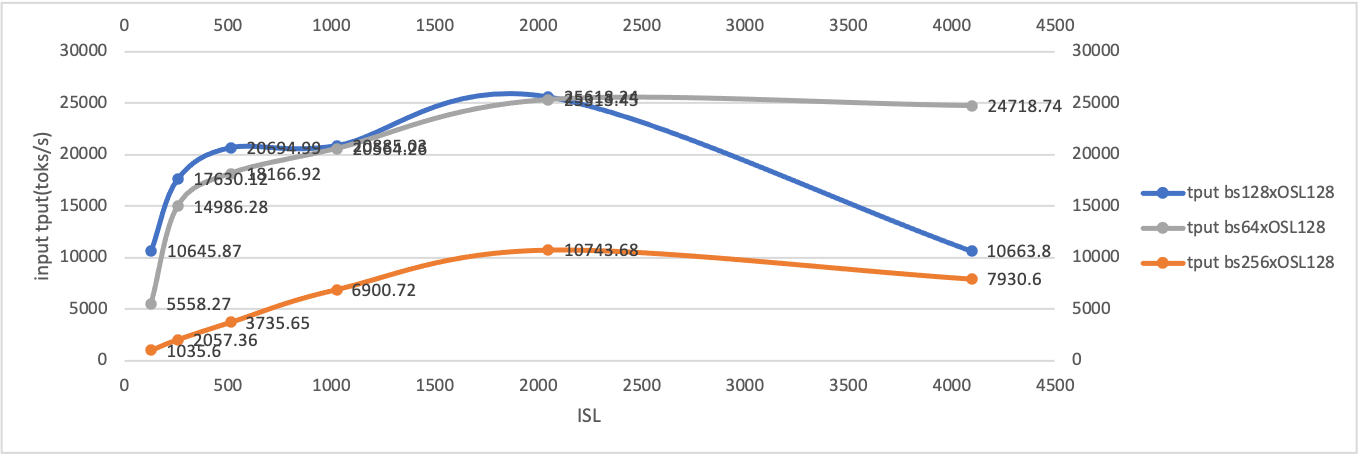
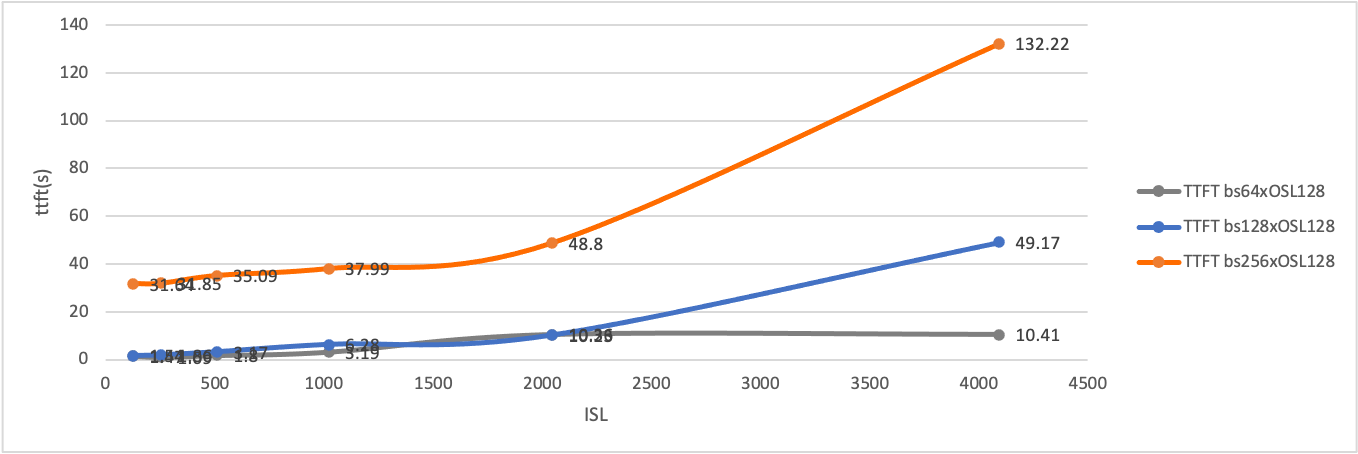
所有这些统计数据都表明,要实现预填充和解码的最大吞吐量,需要不同的工作负载模式。
直观地看,在解耦服务架构中,具有合适分块预填充大小和 TP 大小的预填充节点的良好吞吐量受限于特定的批量大小,因为 KV 缓存传输速度有限 [7]。
SGLang 中 P/D 的工作原理
SGLang 负载均衡器服务现在支持多个预填充 (P) 节点设置(多个 P 节点主地址)和多个解码 (D) 节点设置(多个 D 节点主地址)
# start_lb_service.sh
...
docker_args=$(echo -it --rm --privileged \
--name $tag \
--ulimit memlock=-1:-1 --net=host --cap-add=IPC_LOCK --ipc=host \
--device=/dev/infiniband \
-v $(readlink -f $SGLang):/workspace \
-v $MODEL_DIR:/root/models \
-v /etc/localtime:/etc/localtime:ro \
-e LOG_DIR=$LOG_DIR \
--workdir /workspace \
--cpus=64 \
--shm-size 32g \
$IMG
)
# (P3x3)D4 setup
docker run --gpus all "${docker_args[@]}" python -m sglang.srt.disaggregation.mini_lb \
--prefill "http://${prefill_group_0_master_addr}:${api_port}" \
"http://${prefill_group_1_master_addr}:${api_port}" \
"http://${prefill_group_2_master_addr}:${api_port}" \
--decode "http://${decode_group_0_master_addr}:${api_port}" \
--rust-lb
也可以调整 TP 大小,因为 P 节点可以比 D 节点拥有更小的 TP 大小以获得更好的 TTFT。
提供了两个负载均衡器:RustLB 和旧的 MiniLoadBalancer。它们遵循相同的 HTTP API 分别将 HTTP 请求重定向到预填充和解码服务器。
# load balance API interface
INFO: 10.33.4.141:41296 - "GET /get_server_info HTTP/1.1" 200 OK
INFO: 10.33.4.141:41312 - "POST /flush_cache HTTP/1.1" 200 OK
INFO: 10.33.4.141:41328 - "POST /generate HTTP/1.1" 200 OK
它们在内部也以相同的方式处理传入请求。
# Rust : sgl-pdlb/src/lb_state.rs
pub async fn generate(
&self,
api_path: &str,
mut req: Box<dyn Bootstrap>,
) -> Result<HttpResponse, actix_web::Error> {
let (prefill, decode) = self.strategy_lb.select_pair(&self.client).await;
let stream = req.is_stream();
req.add_bootstrap_info(&prefill)?;
let json = serde_json::to_value(req)?;
let prefill_task = self.route_one(&prefill, Method::POST, api_path, Some(&json), false);
let decode_task = self.route_one(&decode, Method::POST, api_path, Some(&json), stream);
let (_, decode_response) = tokio::join!(prefill_task, decode_task);
decode_response?.into()
}
SGLang 负载均衡器的问题在于,预填充服务器和解码服务器的配对选择不是基于流量的。因此,无法保证预填充服务器之间的负载均衡。
预填充服务器总是首先返回以完成 KV 缓存生成
参考 Dynamo 工作流[11],我们为基于 SGLang RustLB 的 P/D 架构草拟了一个简单的工作流,以便更好地理解我们将来如何优化工作流
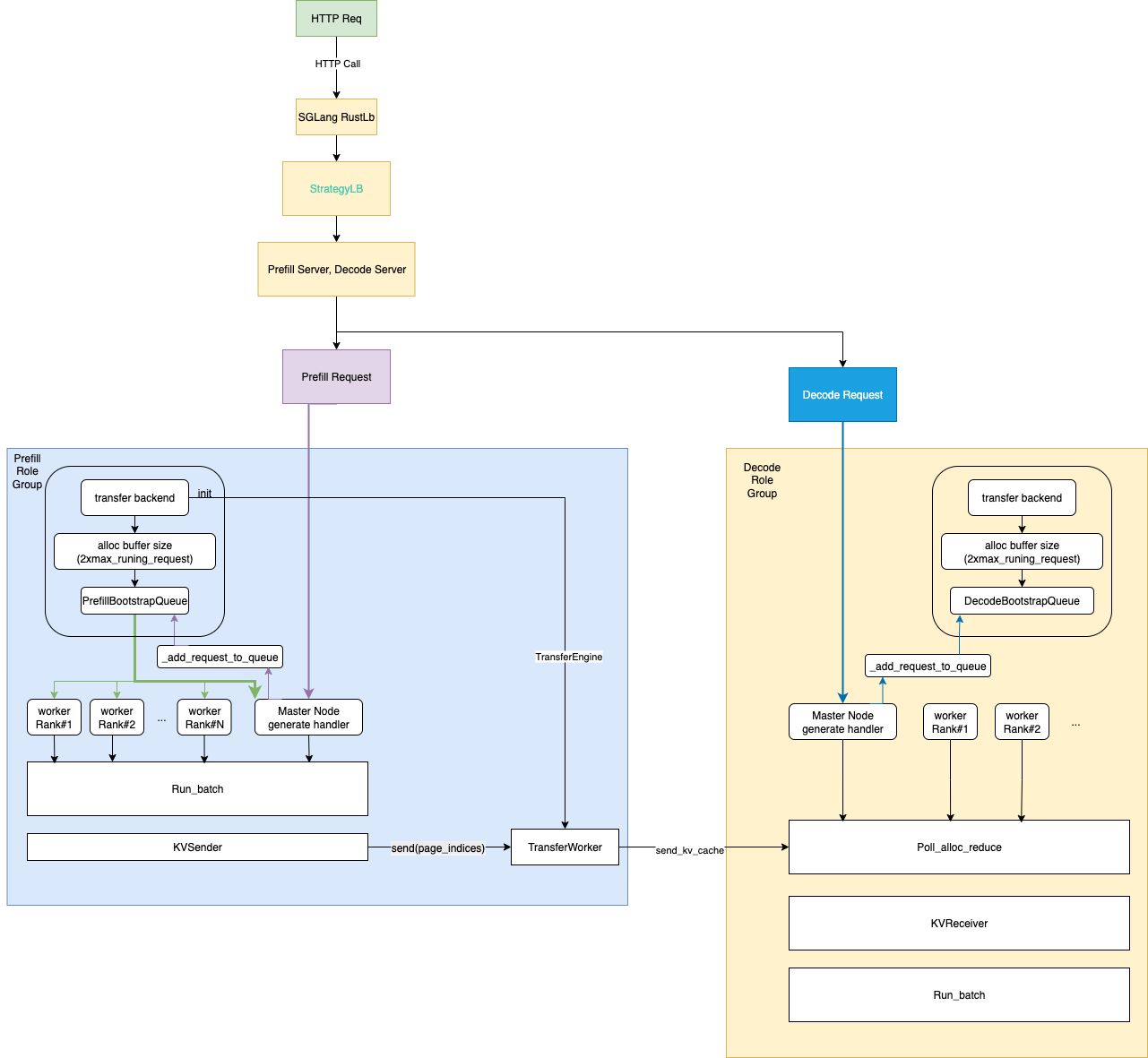
每个 P/D 进程启动一个后台线程,运行一个无限事件循环,以收集请求、其输入批次和可选的 KV 缓存以开始推理。
基准测试方法
通过对 13 台 H800 DGX SuperPod 机器上所有可行的解耦配置进行调查,并深入研究 SGLang (v4.8.0) 的解耦模式,我们独立地在服务器端和用户端进行了在线 P/D 解耦服务评估。
为了准备测试,我们首先将硬件和软件与最新的开源社区保持一致,并按照 SGLang 团队 [1] 的说明准备配置文件
| 名称 | 角色 | 示例 |
|---|---|---|
| EXPERT_DISTRIBUTION_PT_LOCATION | 解码 | ./attachment_ep_statistics/decode_in1000out1000.json |
| EXPERT_DISTRIBUTION_PT_LOCATION | 预填充 | ./attachment_ep_statistics/prefill_in1024.json |
| DEEP_EP_CFG | 预填充 | ./benchmark/kernels/deepep/deepep_nnodes_H800x4_tuned.json |
| fused_moe_config | 预填充/解码 | fused_moe/configs/E=257,N=256,device_name=NVIDIA_H800,block_shape=[128,128].json |
获取配置文件并正确准备测试脚本后,我们通过 CURL API 用几批查询预热服务,因为 JIT 内核编译服务在 SGLang 事件循环工作器冷启动时需要很长时间。一旦预热完成,我们便开始收集测试统计数据。
硬件与软件
本次实验使用的 H800 SuperPod 硬件以机架形式组织
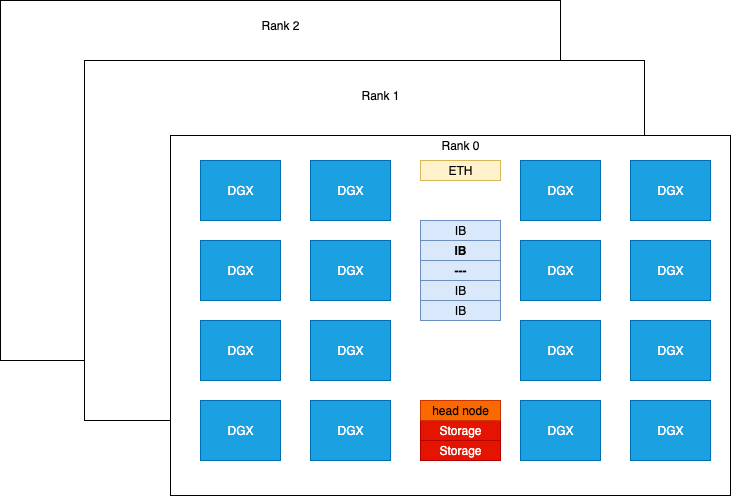
NVIDIA H800 DGX 的计算性能与 H100 DGX 相当,除了 FP64/FP32 数据类型以及由于 NVLINK 配置减少而导致通信带宽近似减半。每张 H800 卡都连接到一块 Mellanox CX-7 (MT2910) NIC 网卡,该网卡连接到 Infiniband 交换机,支持 50 GB/s 的峰值双向带宽。
在单节点 NCCL 测试中,nccl_all_reduce 运行在 213 GB/s 的总线带宽下。在双节点测试中,nccl_all_reduce 运行在 171 GB/s 的总线带宽下。在 rail 测试(所有 GPU 跨机架通过相同的 ib 链路连接)中,nccl_all_reduce 运行在 49 GB/s 的带宽下。
我们在 P/D 解耦测试中的大多数通信功能都使用 NVSHMEM 运行 DeepEP。DeepEP 自 SGLang 核心团队在 2025 年 5 月用于 P/D 实验的版本以来已发生很大变化。因此,我们在客户 docker 内部从头开始构建它
Deepep:deep-ep==1.1.0+c50f3d6
目前,我们选择 mooncake 作为我们的解耦后端,但稍后将尝试其他后端。
# optional for disaggregation option
disaggregation_opt=" \
$disaggregation_opt \
--disaggregation-transfer-backend mooncake \
"
我们需要最新的传输引擎,因为它比 2025 年 5 月使用的传输引擎快 10 倍(参见 PR#499 和 PR#7236)。
mooncake-transfer-engine==v0.3.4
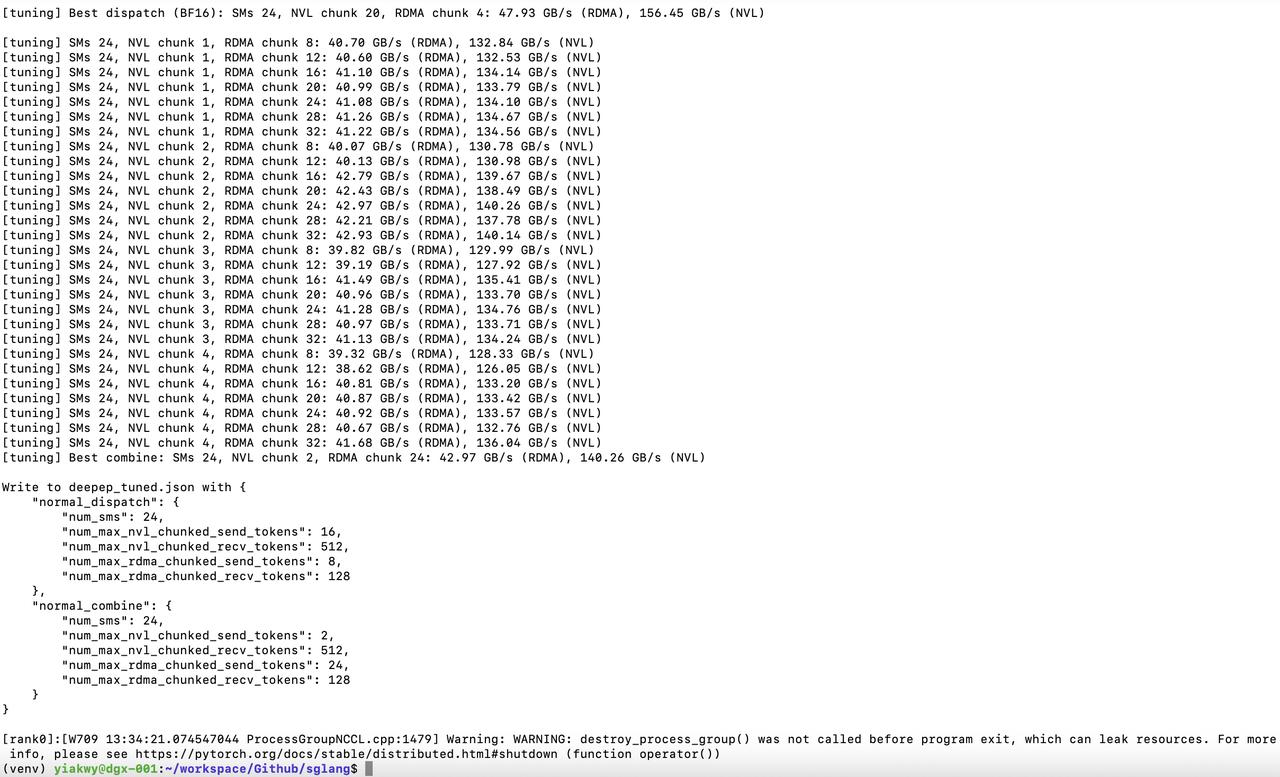
调整 DeepEP 是我们测试的第一步。预填充节点为 2、3(当前 SGLang v0.4.8 配置中直接使用 3 个预填充节点可能会导致问题)和 4
| 预填充 GPU | 数据类型 | 调度(RDMA GB/秒) | 调度(NVL GB/秒) | 合并(RDMA GB/秒) | 合并(NVL GB/秒) | 位置 |
|---|---|---|---|---|---|---|
| 4 | bf16 | 60.58 | 121.63 | 56.72 | 113.88 | deepep_nnodes_H800x4_tuned.json |
| 2 | bf16 | 47.93 | 156.45 | 42.97 | 140.26 | deepep_nnodes_H800x2_tuned.json |
在本实验中,DeepEP 测试表明 bf16 的性能远高于 OCP fp8e4m3。我们尝试了 NCCL、NVSHMEM 环境变量的不同组合,但由于与 libtorch 的兼容性问题,只有少数成功。
# env - nccl 2.23, nccl 2.27 symmetric memroy branch
export NCCL_IB_HCA=mlx5_0,mlx5_3,mlx5_4,mlx5_5,mlx5_6,mlx5_9,mlx5_10,mlx5_11
# traffic class for QoS tunning
# export NCCL_IB_TC=136
# service level that maps virtual lane
# export NCCL_IB_SL=5
export NCCL_IB_GID_INDEX=3
export NCCL_SOCKET_IFNAME=ibp24s0,ibp41s0f0,ibp64s0,ibp79s0,ibp94s0,ibp154s0,ibp170s0f0,ibp192s0
# export NCCL_DEBUG=DEBUG
# export NCCL_IB_QPS_PER_CONNECTION=8
# export NCCL_IB_SPLIT_DATA_ON_QPS=1
# export NCCL_MIN_NCHANNELS=4
# NOTE Torch 2.7 has issues to support commented options
# env - nvshmem
# export NVSHMEM_ENABLE_NIC_PE_MAPPING=1
# export NVSHMEM_HCA_LIST=$NCCL_IB_HCA
# export NVSHMEM_IB_GID_INDEX=3
# NOTE Torch 2.7 has issues to support commented options, see Appendix
成功调优应预期看到如下结果
在 SGLang v0.4.8 中,DeepGEMM 默认不使用,并且没有为 H800 中运行的 fused MoE triton kernels 提供调优配置。
因此,我们微调了 fused MoE triton kernels,为 H800 生成 triton kernel 配置,并启用 DeepGEMM JIT GEMM kernel。
由于 H800 的系统内存限制,预填充和解码的部署单元经过仔细选择
| 部署单元 | TP | E(D)P | |
|---|---|---|---|
| H100 / H800 | 2+X | 16 + 8 X | 16 + 8 X |
| H200 / H20 / B200 | 2+Y | 8 + 8 Y | 8 + 8 Y |
在我们的测试脚本中,我们将配置分类为 scaling config(扩展配置)、model info(模型信息)、server info(服务器信息)、basic config(基本配置)、disaggregation config(解耦配置)、tuning parameters(调优参数)、environmental variables(环境变量)。
常见基础配置
#### Scaling config
RANK=${RANK:-0}
WORLD_SIZE=${WORLD_SIZE:-2}
TP=${TP:-16} # 32
DP=${DP:-1} # 32
#### Model config
bs=${bs:-128} # 8192
ctx_len=${ctx_len:-65536} # 4096
#### Basic config
concurrency_opt=" \
--max-running-requests $bs
"
if [ "$DP" -eq 1 ]; then
dp_attention_opt=""
dp_lm_head_opt=""
deepep_moe_opt=""
else
dp_attention_opt=" \
--enable-dp-attention \
"
dp_lm_head_opt=" \
--enable-dp-lm-head \
"
# in this test, we use deep-ep==1.1.0+c50f3d6
# decode is in low_latency mode
deepep_moe_opt=" \
--enable-deepep-moe \
--deepep-mode normal \
"
fi
log_opt=" \
--decode-log-interval 1 \
"
timeout_opt=" \
--watchdog-timeout 1000000 \
"
# dp_lm_head_opt and moe_dense_tp_opt are needed
dp_lm_head_opt=" \
--enable-dp-lm-head \
"
moe_dense_tp_opt=" \
--moe-dense-tp-size ${moe_dense_tp_size} \
"
page_opt=" \
--page-size ${page_size} \
"
radix_cache_opt=" \
--disable-radix-cache \
"
##### Optimization Options
batch_overlap_opt=" \
--enable-two-batch-overlap \
"
#### Disaggregation config
ib_devices="mlx5_0,mlx5_3,mlx5_4,mlx5_5,mlx5_6,mlx5_9,mlx5_10,mlx5_11"
disaggregation_opt=" \
--disaggregation-ib-device ${ib_devices} \
--disaggregation-mode ${disaggregation_mode} \
"
这些用于预填充和解码解耦角色的通用配置包含可调参数 WORLD_SIZE、TP、DP、max_running_request_size、page_size。
max_running_request_size 影响批量大小和缓冲区大小。页面大小影响传输的令牌数量。我们建议将 max_running_request_size 设置为 128,将 page_size 设置为 32。
对于预填充节点,deepep_mode 设置为 normal,而在解码节点中,设置为 low_latency
| deepep 模式 | 输入 | 输出 | CUDA 图 | |
|---|---|---|---|---|
| 预填充 | 正常 | 长 | 短 (1) | --禁用 CUDA 图 |
| 解码 | 低延迟 | 短 | 很长 | --cuda-graph-bs 256,128,64,32,16,8,4,2,1 |
此外,对于预填充节点,设置小到中等的 chunk-prefill size 总是更好的,以减少 TTFT。
此外,除了预填充-解码配置之外,还应配置专家并行负载均衡。
#### expert distribution options
if [ "$deepep_moe_opt" != "" ]; then
if [ "$stage" == "create_ep_dis" ]; then
create_ep_dis_opt=" \
--expert-distribution-recorder-mode stat \
--disable-overlap-schedule \
--expert-distribution-recorder-buffer-size -1 \
"
expert_distribution_opt=""
else
create_ep_dis_opt=""
expert_distribution_opt=" \
--init-expert-location ${EXPERT_DISTRIBUTION_PT_LOCATION} \
"
fi
fi
# --enable-tokenizer-batch-encode \
nccl_opts=" \
--enable-nccl-nvls \
"
#### EP Load balance - Prefill
if [ "$deepep_moe_opt" == "" ]; then
moe_dense_tp_opt=""
eplb_opt=""
else
moe_dense_tp_opt=" \
--moe-dense-tp-size ${moe_dense_tp_size} \
"
deepep_opt=" \
--deepep-config $DEEP_EP_CFG \
"
ep_num_redundant_experts_opt=" \
--ep-num-redundant-experts 32 \
"
rebalance_iters=1024
eplb_opt=" \
--enable-eplb \
--eplb-algorithm deepseek \
--ep-dispatch-algorithm dynamic \
--eplb-rebalance-num-iterations $rebalance_iters \
$ep_num_redundant_experts_opt \
$deepep_opt \
"
fi
#### EP Load balance - Decode
deepep_opt=""
eplb_opt=" \
$ep_num_redundant_experts_opt \
"
因此,测试中的完整配置如下
#### Full Basic Common Config
basic_config_opt=" \
--dist-init-addr $MASTER_ADDR:$MASTER_PORT \
--nnodes ${WORLD_SIZE} --node-rank $RANK --tp $TP --dp $DP \
--mem-fraction-static ${memory_fraction_static} \
$moe_dense_tp_opt \
$dp_lm_head_opt \
$log_opt \
$timeout_opt \
$dp_attention_opt \
$deepep_moe_opt \
$page_opt \
$radix_cache_opt \
--trust-remote-code --host "0.0.0.0" --port 30000 \
--log-requests \
--served-model-name DeepSeek-0324 \
--context-length $ctx_len \
"
#### Prefill Config
chunk_prefill_opt=" \
--chunked-prefill-size ${chunked_prefill_size} \
"
max_token_opt=" \
--max-total-tokens 131072 \
"
ep_num_redundant_experts_opt=" \
--ep-num-redundant-experts 32 \
"
prefill_node_opt=" \
$disaggregation_opt \
$chunk_prefill_opt \
$max_token_opt \
--disable-cuda-graph
"
# optional for prefill node
prefill_node_opt=" \
$prefill_node_opt \
--max-prefill-tokens ${max_prefill_tokens} \
"
#### Decode Config
decode_node_opt=" \
$disaggregation_opt \
--cuda-graph-bs {cubs} \
"
环境变量
现在 SGLang 支持 DeepGEMM 中的 GEMM 内核,由于我们观察到,当批量大小超过一定水平时,预填充将始终是系统吞吐量的瓶颈,因此我们默认启用了 DeepGEMM 和 moon-cake (0.3.4) 更快的 GEMM 实现。
这些由环境变量控制。
#### SGLang env
MC_TE_METRIC=true
SGLANG_TBO_DEBUG=1
export MC_TE_METRIC=$MC_TE_METRIC
export SGLANG_TBO_DEBUG=$SGLANG_TBO_DEBUG
export SGL_ENABLE_JIT_DEEPGEMM=1
export SGLANG_SET_CPU_AFFINITY=1
export SGLANG_DEEPEP_NUM_MAX_DISPATCH_TOKENS_PER_RANK=256
export SGLANG_HACK_DEEPEP_NEW_MODE=0
export SGLANG_HACK_DEEPEP_NUM_SMS=8
export SGLANG_DISAGGREGATION_BOOTSTRAP_TIMEOUT=360000
# env - nccl
export NCCL_IB_HCA=mlx5_0,mlx5_3,mlx5_4,mlx5_5,mlx5_6,mlx5_9,mlx5_10,mlx5_11
export NCCL_IB_GID_INDEX=3
export NCCL_SOCKET_IFNAME=ibp24s0,ibp41s0f0,ibp64s0,ibp79s0,ibp94s0,ibp154s0,ibp170s0f0,ibp192s0
调整参数。
基本的调整参数是预填充节点和解码节点的世界大小:P${P}D${D}。我们迭代不同的 P/D 解耦设置,以找到合理的服务器端分区,从而优化客户端基准测试中观察到的良好吞吐率。
尽管我们未能实现 SLO 下的 DeepSeek 性能,但我们发现 P4D6 和 (P3x3)D4 在良好吞吐量方面优于 P4D9,在 1024 批处理大小、1K 输入/256 输出的情况下,生成 95k toks/秒的输入吞吐量,20k toks/秒的输出吞吐量,最大传输速度为 356 MB/秒,TTFT 为 9~10 秒,低于总延迟的 30%。
#### Scaling config
RANK=${RANK:-0}
WORLD_SIZE=${WORLD_SIZE:-2}
TP=${TP:-16} # 32
DP=${DP:-1} # 32
#### Model config
bs=${bs:-128} # 8192
# ctx_len=${ctx_len:-65536}
ctx_len=4096
#### Tunning info
EXPERT_DISTRIBUTION_PT_LOCATION="./attachment_ep_statistics/decode_in1000out1000.json"
# NOTE (yiakwy) : create in 'create_ep_dis' stage
moe_dense_tp_size=${moe_dense_tp_size:-1}
page_size=${page_size:-1}
cubs=${cubs:-256}
memory_fraction_static=${memory_fraction_static:-0.81}
附加选项
MTP
在我们最初的尝试中(感谢蒲玉洁),MTP 解码(使用 DeepSeek 草稿模型)并未显示出对整体良好吞吐量的改进,我们将在后续调查中进行研究。
P/D 的基准测试
P2D2
对于 P2D2 配置,由于 KV 缓存保留空间有限(P 节点 65 GB / 79 GB,D 节点 70 GB / 79 GB HBM 利用率),我们经常在客户端遇到批量大小为 1024 时的 KV 缓存 OOM。当批量大小 * 输入长度 > 128 时,我们观察到 SGLang 中 TTFT 急剧增长,输出吞吐量测量不可靠。
| 批处理大小 | 输入 | 输出 | 延迟 | 输入吞吐量 | 输出吞吐量 | 总吞吐量 | TTFT (95) (秒) | 最大传输 (MB/秒) | 最后令牌生成 (tokens/秒) | 评论 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1024 | 1024 | 1 | 72.97 | 14,370.73 | 1,367,184.47 | 14,384.62 | 72.7 | 109.82 | 22.19 | |
| 1024 | 1024 | 32 | 异常 KVTransferError(bootstrap_room=8053843183886796622): 请求 8053843183886796622 在 KVPoll.Bootstrapping 中超时 120.0 秒", 'status_code': 500, 'err_type': None}, 'prompt_tokens': 512, 'completion_tokens': 0, 'cached_tokens': 0, 'e2e_latency': 124.1377534866333}} | |||||||
| 1024 | 512 | 32 | 52.38 | 10,341.56 | 19,519.12 | 10,635.72 | 50.7 | 144.17 | 19.4 | |
| 1024 | 512 | 128 | 68.95 | 8,418.81 | 19,640.21 | 9,504.93 | 62.28 | 54.92 | 99.08 | |
| 1024 | 512 | 512 | 异常 KVTransferError(bootstrap_room=8053843183886796622): 请求 8053843183886796622 在 KVPoll.Bootstrapping 中超时 120.0 秒", 'status_code': 500, 'err_type': None}, 'prompt_tokens': 512, 'completion_tokens': 0, 'cached_tokens': 0, 'e2e_latency': 124.1377534866333}} | |||||||
| 1024 | 128 | 128 | 72.37 | 1,971.51 | 22,267.64 | 3,622.32 | 66.48 | 89.23 | 147.64 | |
| 512 | 256 | 256 | ||||||||
| 256 | 128 | 128 | 47.3 | 799.71 | 5,184.33 | 1,385.67 | 40.98 | 36.04 | 222.95 | |
| 128 | 128 | 128 | 49.64 | 389.53 | 2161.38 | 42.06 | 42.88 | |||
| 64 | 128 | 128 | 9.05 | 5365.11 | 1089.32 | 1.53 | 39.74 | |||
| 64 | 128 | 256 | 16.76 | 4678.39 | 1091.4 | 1.75 | 19.06 | |||
| 64 | 128 | 512 | 32.42 | 3638.99 | 1086.33 | 2.25 | 16.96 | |||
| 8 | 128 | 128 | 7.02 | 1464.24 | 162.07 | 0.7 | 16.95 | |||
| 64 | 256 | 128 | 9.88 | 6782.64 | 1097.06 | 2.42 | 20.28 | |||
| 64 | 512 | 128 | 12.65 | 5934.04 | 1149.83 | 5.52 | 16.94 | |||
| 64 | 1024 | 128 | 28.09 | 3064.63 | 1221.39 | 21.38 | 19.49 |
基于这些观察,我们随后将用户端的在线测试输入分为两类
短查询(in_seq_len < 128)以在最多 128 个并发下实现高良好吞吐量;
长查询,最大吞吐量,最大 120 秒返回
当批处理大小 * 输入长度超过 P2D2 的 128 x 128 时,传输 KV 缓存会阻塞推理速度,然后整个系统在数据平面中变为网络 IO 瓶颈。
Mooncake 开发人员在 PR#499 中发现传输引擎的性能问题,并迅速将新的批量传输功能集成到 SGLang v0.4.8 中(也需要安装 transfer-engine==0.3.4),参见 PR#7236。
尽管传输引擎带来了 10 倍的提升,但数据平面中的网络 IO 瓶颈在不同的 P/D 设置中普遍存在。
如果不考虑 SLO 下的良好吞吐量,很容易获得最大输入吞吐量 45k toks/秒。正如我们上面分析的那样,输出吞吐量受 TTFT 限制,因此测量不准确。
值得注意的是,当输入序列长度与输出长度的比率为 4:1 时,在这台 H800 SuperPod 机器上,GPU 利用率达到最佳,并且最后一次令牌生成速度达到最大值。

P2D4/P4D2
在 P2D4 和 P4D2 测试中,其中一个目标是确定扩展方向以减少 TTFT 和最大良好吞吐量。为了减少 TTFT,正如我们在动机部分所讨论的,一个选项是减少分块预填充大小,并减少预填充节点的数据并行度。
| 分块预填充大小 | 批处理大小 | 输入 | 输出 | 延迟 | 输入吞吐量 | 输出吞吐量 | TTFT (95) (秒) | 最后生成吞吐量 (tokens/秒) |
|---|---|---|---|---|---|---|---|---|
| 大型 | 64 | 128 | 128 | 44.74 | 235.92 | 817.68 | 34.72 | 66.61 |
| 小型 | 64 | 128 | 128 | 8.16 | 4820.89 | 1268.5 | 1.7 | 24.01 |
| 大型 | 128 | 128 | 128 | 13.78 | 3055.26 | 1947.41 | 5.36 | 20.79 |
| 小型 | 128 | 128 | 128 | 9.96 | 5425.92 | 2358.96 | 3.02 | 22.62 |
数据并行和 dp 注意力 (DP > 1) 必须打开,否则,我们将看到 TTFT 和良好吞吐率的显著下降
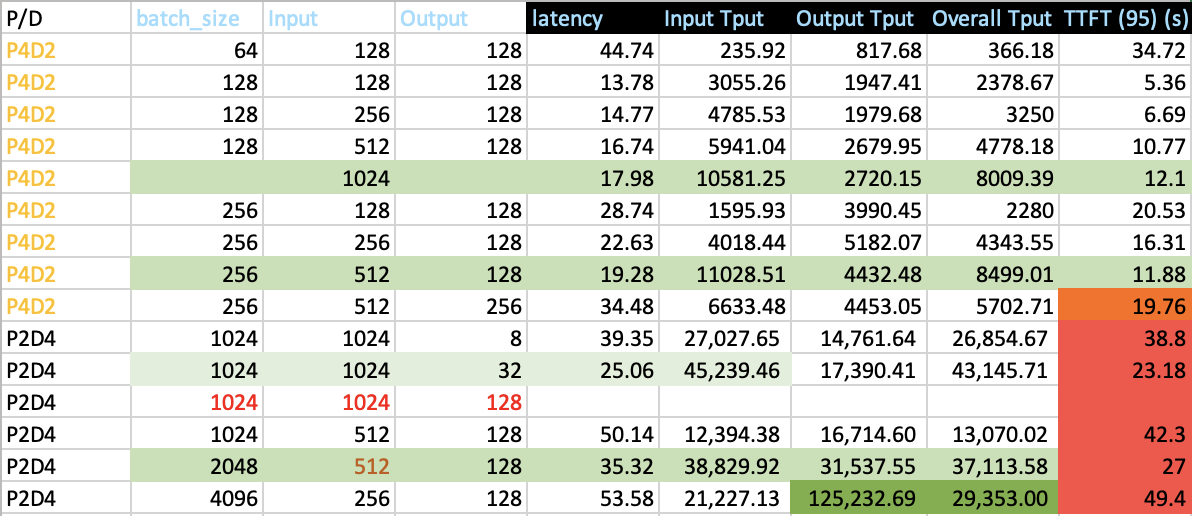
从上面收集的统计数据来看,我们得出结论,为了支持 P2D4 中超过 1024 的输入序列长度,大部分运行时间都花在了预填充阶段,因此 TTFT 非常接近整体延迟。
因此,我们考虑扩大预填充节点 r 的百分比(r > 1,r < 2)。
P4D6

对于 P4D6 解耦测试,平均 TTFT 上升到 10 秒,当 batch size * input_length > 2048 * 1024 时,TTFT 以急剧的斜率增长。
P4D9
P4D9 是 SGLang 团队推荐的黄金配置[8],但在我们的测试中,它未能产生可接受的良好吞吐率,其总体吞吐量在 4K 输入、256 输出长度下限制为 80k toks/秒。

我们通过用户端在线测试 P4D9 解耦配置验证了这一点。对于短查询,用户端(用户 SDK)观察到最大 8k tokens/秒。
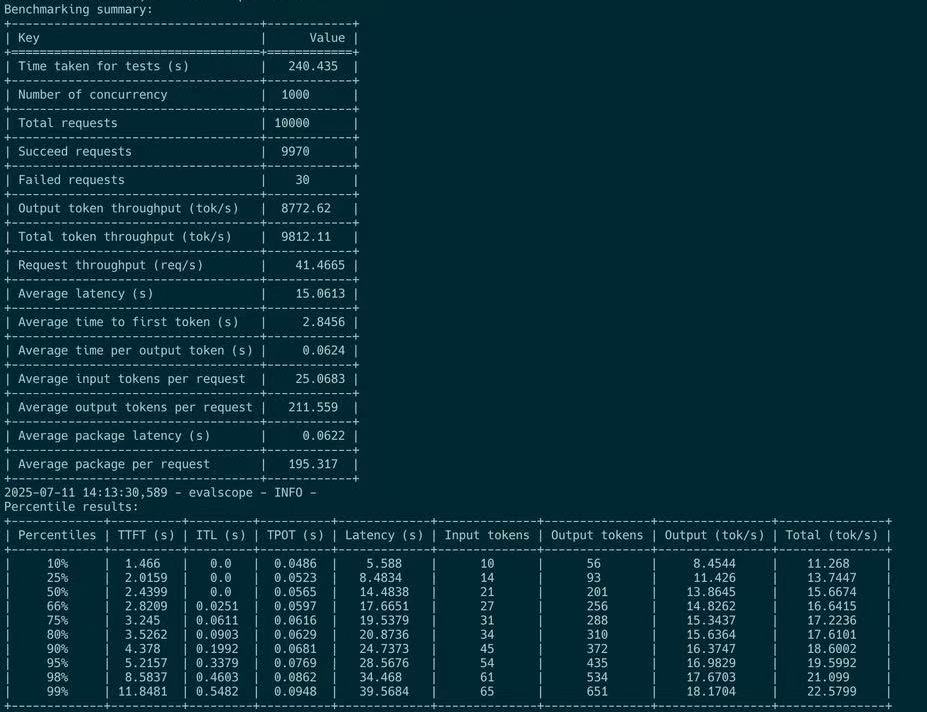
对于长查询,用户端(用户 SDK)仅观察到最大 400 toks/秒
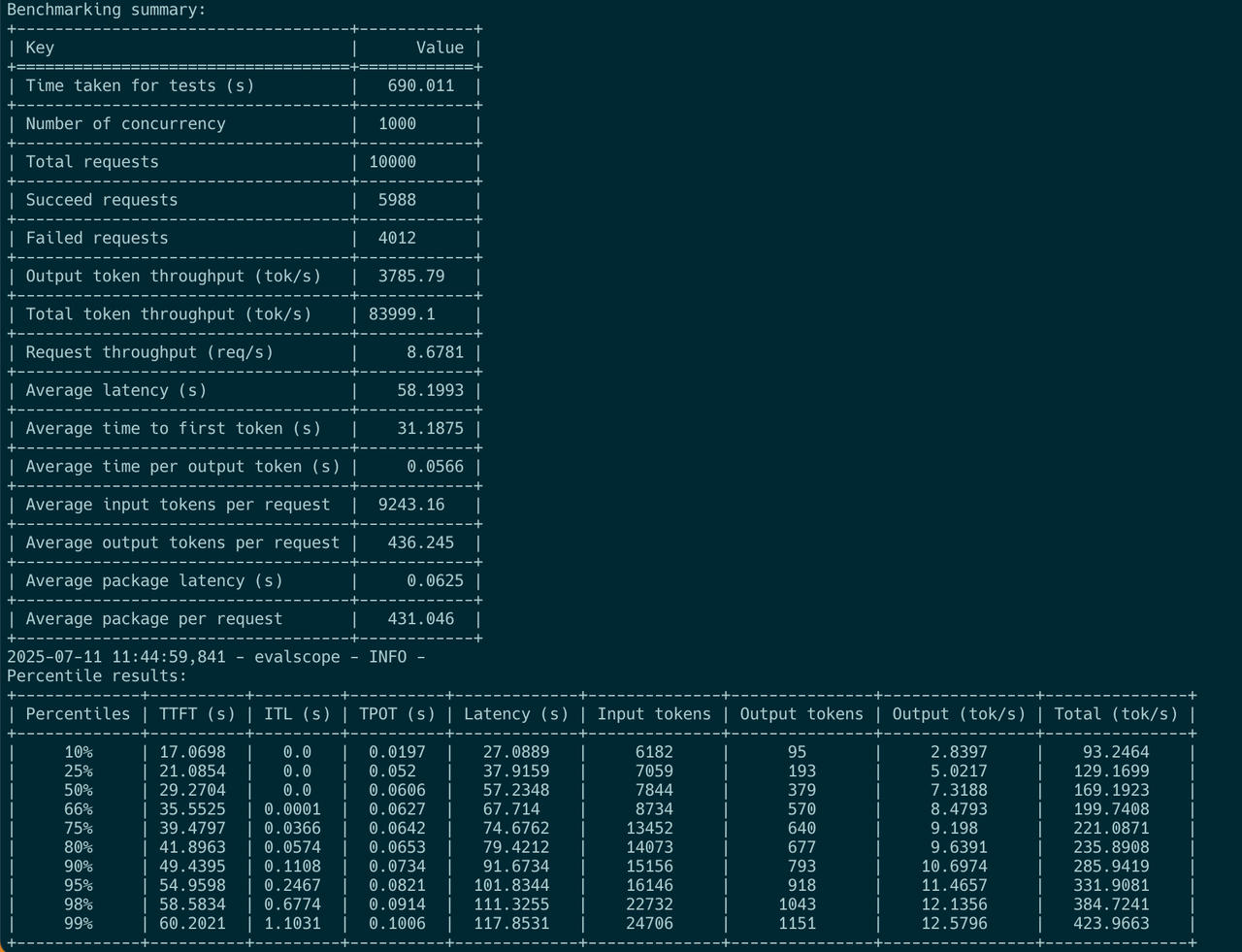
结论
我们对在 SGLang V0.4.8 中使用 13x8 H800 SuperNodes 的解耦服务架构中托管 DeepSeek V3 671 B 类似模型进行了全面研究。
我们首先得出结论并验证,更大的预填充组(最好预填充与解码组的比例为 3:1)和更小的 TP 大小(最好预填充与解码节点的总比例为 1:1),能够生成更好的 TTFT 和更高的良好吞吐量。
我们其次验证了大型 MoE 模型的 P/D 设置,当 input length * batch size 超过一定数量时,TTFT 会急剧增长,在实际部署中,我们应该限制 max_running_request_size。
为了提高 TTFT 和预填充节点的计算效率,我们选择了更小的分块预填充大小。
此配置在用户端针对短查询实现了近 80k tokens/秒的整体良好吞吐量和 8k tokens/秒的观察吞吐量,与每个 2xH800 共置部署单元最大 10k 的整体良好吞吐量相比,吞吐量限制小得多。
未来工作
解耦服务架构将多个节点作为部署单元暴露。它利用预填充和解码阶段独特的计算特性,与传统的共置服务架构相比,可提供显著更好的整体良好吞吐量。
然而,更大的部署单元也引入了更大的风险——即使只有一张卡需要维修,整个单元也可能受到影响。因此,在保持有竞争力的良好吞吐量的同时选择合理的单元大小对于该解决方案在实际部署中的成功至关重要。
接下来,我们将重点关注通信层库,以充分释放预填充节点的潜力并进一步降低 TTFT。
致谢
感谢王怡雯先生(yepmanwong@hkgai.org)和薛伟教授(weixue@ust.hk)对本文的支持和建议,感谢郭安迪(guozhenhua@hkgai.org)的用户端测试,感谢蒲玉洁(yujiepu@hkgai.org)的部署以验证 MTP 和 (P3x3)D4 的有效性,以及巢弋(chao.yi@hkgai.org)对资源安排的帮助。
附录
预填充解码节点共置 H800 X 2 测试完整参考
| 批量大小 | 输入长度 | 输出长度 | 延迟 (秒) | 输入吞吐量 (tokens/秒) | 输出吞吐量 (tokens/秒) | 首次生成令牌时间 (秒) | 最后令牌生成 (tokens/秒) |
|---|---|---|---|---|---|---|---|
| 1 | 128 | 1 | 13.94 | 9.18 | 不适用 | 13.94 | 不适用 |
| 1 | 128 | 128 | 24.85 | 74.75 | 5.53 | 1.71 | |
| 2 | 128 | 128 | 27.45 | 242.48 | 9.7 | 1.06 | 5.05 |
| 8 | 128 | 128 | 29.41 | 464.39 | 37.64 | 2.21 | 37.64 |
| 64 | 128 | 128 | 31.33 | 5558.27 | 274.38 | 1.47 | 150.97 |
| 128 | 128 | 128 | 30.1 | 10645.87 | 573.56 | 1.54 | 297.73 |
| 256 | 128 | 128 | 59.03 | 1035.6 | 1196.2 | 31.64 | 300.72 |
| 512 | 128 | 128 | 118.87 | 728.24 | 2269.65 | 89.99 | 293.69 |
| 1024 | 128 | 128 | 232.41 | 638.05 | 4857.73 | 205.42 | 302.01 |
| 2048 | 128 | 128 | 463.71 | 604.48 | 8727.43 | 433.67 | 284.32 |
| 256 | 128 | 64 | 32.05 | 1888.49 | 1114.7 | 17.35 | 262.18 |
| 256 | 128 | 32 | 17.94 | 2996.34 | 1169.3 | 10.94 | 17.57 |
| 256 | 128 | 16 | 9.85 | 4944.47 | 1269.26 | 6.63 | 17.57 |
| 256 | 128 | 8 | 6.3 | 6804.99 | 1376.58 | 4.82 | 17.57 |
| 256 | 128 | 4 | 4.54 | 9268.11 | 1014.83 | 3.54 | 17.57 |
| 256 | 128 | 2 | 3.27 | 11221.3 | 1483.17 | 2.92 | 17.57 |
| 256 | 128 | 1 | 3.67 | 8931.5 | 不适用 | 3.67 | 17.57 |
参考
[1]: 使用大规模 PD 和 EP 运行 DeepSeek 的说明,https://github.com/sgl-project/sglang/issues/6017,2025 年 7 月 12 日检索。
[2]: 大型模型评估框架,ModelScope 团队,2024 年,https://github.com/modelscope/evalscope,2025 年 7 月 12 日检索。
[3]: Orca:基于 Transformer 的生成模型的分布式服务系统,https://www.usenix.org/conference/osdi22/presentation/yu, Gyeong-In Yu 和 Joo Seong Jeong 和 Geon-Woo Kim 和 Soojeong Kim 和 Byung-Gon Chun, OSDI 2022, https://www.usenix.org/conference/osdi22/presentation/yu
[4]: SARATHI:通过分块预填充结合解码实现高效 LLM 推理,https://arxiv.org/pdf/2308.16369
[5]: DistServe:通过预填充和解码解耦实现优化的LLM服务良好吞吐量,钟寅民,刘圣宇,陈俊达,胡建波,朱艺博,刘轩哲,金鑫,张昊,2024年6月6日,https://arxiv.org/pdf/2401.09670
[6]: 吞吐量并非你所需的一切:使用预填充-解码解耦最大化 LLM 服务中的良好吞吐量,陈俊达,钟寅民,刘圣宇,朱艺博,金鑫,张昊,2024 年 3 月 3 日,2025 年 7 月 12 日在线访问。
[7]: MoonCake 传输引擎性能:https://kvcache-ai.github.io/Mooncake/performance/sglang-benchmark-results-v1.html,2025 年 7 月 18 日在线访问
[8]: https://lmsys.org/blog/2025-05-05-large-scale-ep/,2025 年 7 月 12 日在线访问
[9]: DeepSeek OpenWeek:https://github.com/deepseek-ai/open-infra-index?tab=readme-ov-file
[10]: SGLang genai-bench:https://github.com/sgl-project/genai-bench,7 月 18 日在线访问
[11]: https://github.com/ai-dynamo/dynamo/blob/main/docs/images/dynamo_flow.png,7 月 18 日在线访问
{kind=link}
赞助来源
另请参阅 Github