通过 DeepSpeed 和 FairScale 使用 ZeRO: 塞下更多数据,训练速度更快





Hugging Face 研究员 Stas Bekman 的客座博文
由于近年来机器学习模型的增长速度远快于新发布显卡的 GPU 显存增长速度,许多用户无法在自己的硬件上训练,甚至无法加载一些大型模型。虽然目前正在努力将这些大型模型蒸馏成更易于管理的大小,但这项工作的进展还不够快,产出的模型也不够小。
2019 年秋,Samyam Rajbhandari、Jeff Rasley、Olatunji Ruwase 和 Yuxiong He 发表了一篇论文:ZeRO: 面向万亿参数模型训练的显存优化技术,其中包含了大量巧妙的新思想,阐述了如何让硬件发挥出远超以往想象的性能。不久之后,DeepSpeed 发布了,它向世界提供了该论文中大部分思想的开源实现(一些思想仍在开发中)。与此同时,Facebook 的一个团队发布了 FairScale,它也实现了 ZeRO 论文中的一些核心思想。
如果你使用 Hugging Face Trainer,从 transformers v4.2.0 版本开始,你将获得对 DeepSpeed 和 FairScale 的 ZeRO 功能的实验性支持。新的 --sharded_ddp 和 --deepspeed 命令行 Trainer 参数分别提供了 FairScale 和 DeepSpeed 的集成。这里是完整的文档。
这篇博文将介绍如何利用 ZeRO,无论你拥有一块 GPU 还是多块 GPU。
多 GPU 设置下的巨大加速
让我们用 t5-large 模型和 finetune_trainer.py 脚本做一个小型的翻译任务微调实验,你可以在 transformers GitHub 仓库的 examples/seq2seq 目录下找到这个脚本。
我们有 2 块 24GB (Titan RTX) GPU 用于测试。
这只是一个概念验证的基准测试,所以肯定还有进一步优化的空间。我们将在一个包含 2000 个训练样本和 500 个评估样本的小数据集上进行基准测试,以便进行比较。评估默认使用大小为 4 的束搜索 (beam search),所以它比同样样本数量的训练要慢,这就是为什么这些测试中评估样本数量少了 4 倍。
以下是我们基准测试的关键命令行参数:
export BS=16
python -m torch.distributed.launch --nproc_per_node=2 ./finetune_trainer.py \
--model_name_or_path t5-large --n_train 2000 --n_val 500 \
--per_device_eval_batch_size $BS --per_device_train_batch_size $BS \
--task translation_en_to_ro [...]
对于基准测试,我们只使用了 DistributedDataParallel (DDP) 来提升性能,没有使用其他任何技术。在出现内存不足 (OOM) 错误之前,我能够将批处理大小 (BS) 设为 16。
注意,为了简单和易于理解,我只展示了对这次演示重要的命令行参数。你可以在这篇文章中找到完整的命令行。
接下来,我们将每次添加以下一项重新运行基准测试:
--fp16--sharded_ddp(fairscale)--sharded_ddp --fp16(fairscale)--deepspeed(不带 CPU 卸载)--deepspeed(带 CPU 卸载)
由于这里的关键优化是每种技术都更有效地利用了 GPU RAM,我们将尝试不断增加批处理大小,并期望训练和评估能够更快地完成(同时保持指标稳定甚至有所改善,但我们在这里不关注这些)。
请记住,训练和评估阶段彼此非常不同,因为在训练期间,模型权重会被修改,梯度会被计算,优化器状态会被存储。而在评估期间,这些都不会发生,但在翻译这个特定任务中,模型会尝试搜索最佳假设,因此在满意之前实际上需要进行多次运行。这就是为什么它不快,尤其是在模型很大的情况下。
让我们看看这六次测试运行的结果:
| 方法 | 最大批处理大小 (BS) | 训练时间 | 评估时间 |
|---|---|---|---|
| 基准 | 16 | 30.9458 | 56.3310 |
| fp16 | 20 | 21.4943 | 53.4675 |
| sharded_ddp | 30 | 25.9085 | 47.5589 |
| sharded_ddp+fp16 | 30 | 17.3838 | 45.6593 |
| deepspeed (无 cpu 卸载) | 40 | 10.4007 | 34.9289 |
| deepspeed (有 cpu 卸载) | 50 | 20.9706 | 32.1409 |
很容易看出,FairScale 和 DeepSpeed 在总训练和评估时间以及批处理大小方面都比基准有了很大的改进。截至本文撰写之时,DeepSpeed 实现了更多的“魔法”,似乎是短期的赢家,但 Fairscale 更容易部署。对于 DeepSpeed,你需要编写一个简单的配置文件并更改命令行的启动器;而对于 Fairscale,你只需要添加 --sharded_ddp 命令行参数,所以你可能想先尝试它,因为这是最容易实现的优化。
遵循 80:20 法则,我只在这些基准测试上花了几小时,并没有试图通过优化命令行参数和配置来榨干每一MB显存和每一秒时间,因为从这个简单的表格中可以很清楚地看出你接下来想尝试什么。当你面对一个将要运行数小时甚至数天的真实项目时,一定要花更多时间来确保你使用最优的超参数,以更快、成本最低的方式完成工作。
如果你想自己试验这个基准测试,或者想了解更多关于运行它所使用的硬件和软件的细节,请参考这篇文章。
将巨大模型装入单个 GPU
虽然 Fairscale 只有在多 GPU 的情况下才能给我们带来性能提升,但 DeepSpeed 即使对我们这些只有一个 GPU 的人来说也是一份礼物。
让我们来尝试一件不可能的事——在一张 24GB 的 RTX-3090 显卡上训练 t5-3b。
首先,让我们尝试使用正常的单 GPU 设置来微调巨大的 t5-3b 模型。
export BS=1
CUDA_VISIBLE_DEVICES=0 ./finetune_trainer.py \
--model_name_or_path t5-3b --n_train 60 --n_val 10 \
--per_device_eval_batch_size $BS --per_device_train_batch_size $BS \
--task translation_en_to_ro --fp16 [...]
没戏,即使批处理大小 (BS) 为 1,我们还是会得到
RuntimeError: CUDA out of memory. Tried to allocate 64.00 MiB (GPU 0; 23.70 GiB total capacity;
21.37 GiB already allocated; 45.69 MiB free; 22.05 GiB reserved in total by PyTorch)
注意,和之前一样,我只展示了重要的部分,完整的命令行参数可以在这里找到。
现在将你的 transformers 更新到 v4.2.0 或更高版本,然后安装 DeepSpeed
pip install deepspeed
然后我们再试一次,这次在命令行中加入 DeepSpeed
export BS=20
CUDA_VISIBLE_DEVICES=0 deepspeed --num_gpus=1 ./finetune_trainer.py \
--model_name_or_path t5-3b --n_train 60 --n_val 10 \
--per_device_eval_batch_size $BS --per_device_train_batch_size $BS \
--task translation_en_to_ro --fp16 --deepspeed ds_config_1gpu.json [...]
瞧!我们成功地训练了一个批处理大小为 20 的模型。我或许还能把它推得更高。程序在 BS=30 时因内存不足 (OOM) 而失败。
以下是相关的结果:
2021-01-12 19:06:31 | INFO | __main__ | train_n_objs = 60
2021-01-12 19:06:31 | INFO | __main__ | train_runtime = 8.8511
2021-01-12 19:06:35 | INFO | __main__ | val_n_objs = 10
2021-01-12 19:06:35 | INFO | __main__ | val_runtime = 3.5329
我们无法将这些与基准进行比较,因为基准甚至无法启动,并立即因内存不足 (OOM) 而失败。
简直太神奇了!
我只使用了一个非常小的样本,因为我主要感兴趣的是能够用这个通常无法装入 24GB GPU 的巨大模型进行训练和评估。
如果你想自己试验这个基准测试,或者想了解更多关于运行它所使用的硬件和软件的细节,请参考这篇文章。
ZeRO 背后的魔法
由于 transformers 只是集成了这些出色的解决方案,而不是参与了它们的发明,我将分享一些资源,你可以从中发现所有细节。但这里有几个快速的见解,可能有助于理解 ZeRO 如何实现这些惊人的壮举。
ZeRO 的关键特性是在大家非常熟悉的数据并行训练概念中加入了分布式数据存储。
每个 GPU 上的计算与数据并行训练完全相同,但参数、梯度和优化器状态以分布式/分区的方式存储在所有 GPU 上,并且仅在需要时才获取。
下图来自这篇博文,说明了其工作原理。
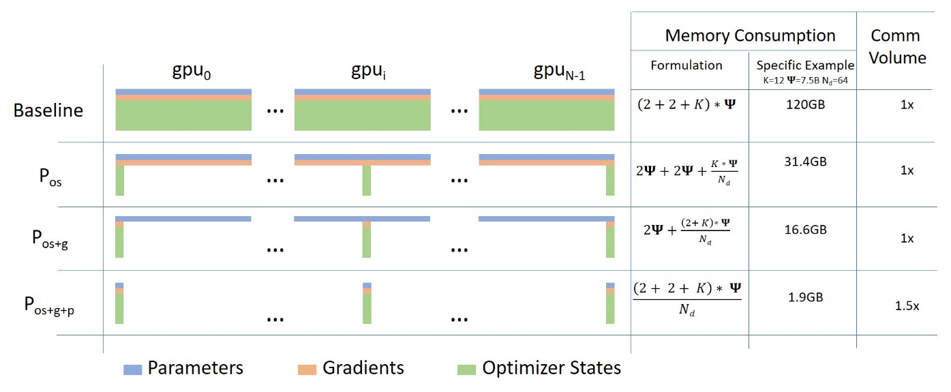
ZeRO 的巧妙方法是将参数、梯度和优化器状态平均分配到所有 GPU 上,并给每个 GPU 仅一个分区(也称为分片)。这导致 GPU 之间的数据存储零重叠。在运行时,每个 GPU 通过请求其他参与的 GPU 发送其缺少的信息来动态构建每一层的数据。
这个想法可能很难理解,你可以在这里找到我对此的解释尝试。
截至本文撰写之时,FairScale 和 DeepSpeed 仅对优化器状态和梯度进行分区(分片)。模型参数分片据说很快将在 DeepSpeed 和 FairScale 中推出。
另一个强大的功能是 ZeRO-Offload (论文)。此功能将部分处理和内存需求卸载到主机的 CPU,从而允许将更多内容装入 GPU。您在成功在 24GB GPU 上运行 t5-3b 的案例中看到了它的巨大影响。
很多人在 PyTorch 论坛上抱怨的另一个问题是 GPU 显存碎片化。人们经常会遇到类似这样的 OOM 错误:
RuntimeError: CUDA out of memory. Tried to allocate 1.48 GiB (GPU 0; 23.65 GiB total capacity;
16.22 GiB already allocated; 111.12 MiB free; 22.52 GiB reserved in total by PyTorch)
程序想要分配约 1.5GB 的内存,而 GPU 仍有约 6-7GB 的未使用内存,但它报告只有约 100MB 的连续可用内存,并因此出现 OOM 错误。这种情况发生是因为不同大小的内存块被反复分配和释放,随着时间的推移,会产生空洞,导致内存碎片化,即有很多未使用的内存,但没有所需大小的连续内存块。在上面的例子中,程序可能可以分配 100MB 的连续内存,但显然无法获得 1.5GB 的单个内存块。
DeepSpeed 通过自行管理 GPU 内存来解决这个问题,并确保长期内存分配不与短期内存分配混合,从而大大减少了碎片化。虽然论文没有详细说明,但源代码是可用的,因此可以了解 DeepSpeed 是如何实现这一点的。
由于 ZeRO 代表零冗余优化器 (Zero Redundancy Optimizer),很容易看出它名副其实。
未来
除了 DeepSpeed 即将推出的对模型参数分片的支持外,它已经发布了我们尚未探索的新功能。这些功能包括 DeepSpeed 稀疏注意力和 1-bit Adam,它们应该能减少内存使用并显著降低 GPU 间的通信开销,从而实现更快的训练并支持更大的模型。
我相信我们也会看到 FairScale 团队的新礼物。我想他们也在开发 ZeRO 第三阶段。
更令人兴奋的是,ZeRO 正在被集成到 PyTorch 中。
部署
如果您觉得这篇博文中分享的结果很吸引人,请访问这里,了解如何将 DeepSpeed 和 FairScale 与 transformers Trainer 结合使用的详细信息。
当然,你也可以根据每个项目的说明修改你自己的训练器来集成 DeepSpeed 和 FairScale,或者你可以“抄作业”,看看我们是如何在 transformers Trainer 中实现的。如果你选择后者,可以在源代码中用 grep 搜索 deepspeed 和/或 sharded_ddp 来找到相关代码。
好消息是 ZeRO 不需要修改模型。唯一需要的修改是在训练代码中。
问题
如果您在集成这两个项目时遇到任何问题,请在 transformers 中提交一个 Issue。
但是,如果您在 DeepSpeed 和 FairScale 的安装、配置和部署方面遇到问题,您需要向其领域的专家求助,因此,请改用 DeepSpeed Issue 或 FairScale Issue。
资源
虽然您并不真的需要了解这些项目的工作原理,可以直接通过 transformers Trainer 来部署它们,但如果您想弄清楚其中的原因和方式,请参考以下资源。
论文:ZeRO: 面向万亿参数模型训练的显存优化技术。这篇论文非常有趣,但非常简洁。
这是一个很好的视频讨论,带有图示,对论文进行了解释
论文:ZeRO-Offload: 让十亿级模型训练大众化。刚刚发表 - 这篇论文详细介绍了 ZeRO Offload 功能。
DeepSpeed 配置和教程
除了论文,我强烈推荐阅读以下带有图表的详细博文
DeepSpeed GitHub 上的示例
致谢
在我们致力于将这些项目集成到 transformers 的过程中,FairScale 和 DeepSpeed 开发团队给予了我们惊人水平的支持,我们对此感到非常惊讶。
我特别想感谢
- Benjamin Lefaudeux @blefaudeux
- Mandeep Baines @msbaines
来自 FairScale 团队,以及
来自 DeepSpeed 团队,感谢你们慷慨而周到的支持,以及迅速解决我们遇到的问题。
并感谢 HuggingFace 提供了运行基准测试的硬件。

