SeeMoE:从零开始实现一个MoE视觉语言模型







TL;DR: 在这篇博客中,我将从零开始实现一个由图像编码器、多模态投影模块和专家混合(MoE)解码器语言模型组成的专家混合视觉语言模型,全部使用纯 PyTorch 实现。因此,所实现的模型可以被视为 Grok 1.5 Vision 和 GPT-4 Vision 的缩小版(两者都通过一个投影模块将视觉编码器连接到 MoE 解码器模型)。“SeeMoE”这个名字是我向 Andrej Karpathy 的“makemore”项目致敬的方式,因为这里使用的解码器实现了一个字符级别的自回归语言模型,很像他的 nanoGPT/makemore 实现,但有一个不同之处。这个不同之处在于它是一个专家混合解码器(很像 DBRX、Mixtral 和 Grok)。我的目标是让大家直观地理解这种看似最先进的实现是如何工作的,以便大家可以在此基础上进行改进或利用关键点构建更有用的系统。
完整的实现代码可在以下仓库的 seeMoE_from_Scratch.ipynb 中找到:https://github.com/AviSoori1x/seemore

如果你读过我关于从零开始实现专家混合大型语言模型(https://huggingface.co/blog/AviSoori1x/makemoe-from-scratch)和从零开始实现视觉语言模型(https://huggingface.co/blog/AviSoori1x/seemore-vision-language-model)的其他博客,你就会发现我在这里是将两者结合起来实现 seeMoE 的。本质上,我所做的就是将解码器中每个 Transformer 块的前馈神经网络替换为一个带有噪声 Top-K 门控的专家混合模块。关于如何实现这一点的更多信息,请参阅这里:https://huggingface.co/blog/AviSoori1x/makemoe-from-scratch。我强烈建议你在深入阅读本文之前,先阅读这两篇博客并仔细查看其中链接的仓库。
在“seeMoE”中,我简单实现了专家混合视觉语言模型(VLM),它包含3个主要组件。

图像编码器,用于从图像中提取视觉特征。在这里,我从头开始实现了 CLIP 中使用的原始视觉 Transformer。这实际上是许多现代 VLM 的流行选择。一个值得注意的例外是 Adept 的 Fuyu 系列模型,它将分块后的图像直接传递到投影层。
视觉-语言投影器——图像嵌入的形状与解码器使用的文本嵌入不同。因此,我们需要“投影”,即改变图像编码器提取的图像特征的维度,以匹配文本嵌入空间中的维度。这样,图像特征就变成了解码器的“视觉标记”。这可以是一个单层或一个多层感知机(MLP)。我使用了 MLP,因为它值得展示。
一个只有解码器的语言模型,采用专家混合架构。这是最终生成文本的组件。在我的实现中,我通过将投影模块整合到解码器中,与 LLaVA 中的做法有所不同。通常情况下,解码器(通常是一个已经预训练好的模型)的架构不会被修改。这里最大的改变是,如前所述,每个 Transformer 块中的前馈神经网络/MLP 被一个带有噪声 top-k 门控机制的专家混合块所取代。基本上,每个标记(文本标记+已映射到与文本标记相同嵌入空间的视觉标记)只由每个 Transformer 块中 n 个专家中的 top-k 个专家处理。因此,如果是一个有 8 个专家和 top-2 门控的 MoE 架构,那么只有 2 个专家会被激活。
由于图像编码器和视觉语言投影器与seemore(链接如上。仓库在此:https://github.com/AviSoori1x/seemore)保持不变,我鼓励大家阅读该博客/查看笔记本以获取详细信息。
现在我们重新审视稀疏专家混合模块的组件
- 专家——即n个普通的MLP
- 门控/路由机制
- 根据路由机制对激活的专家进行加权求和
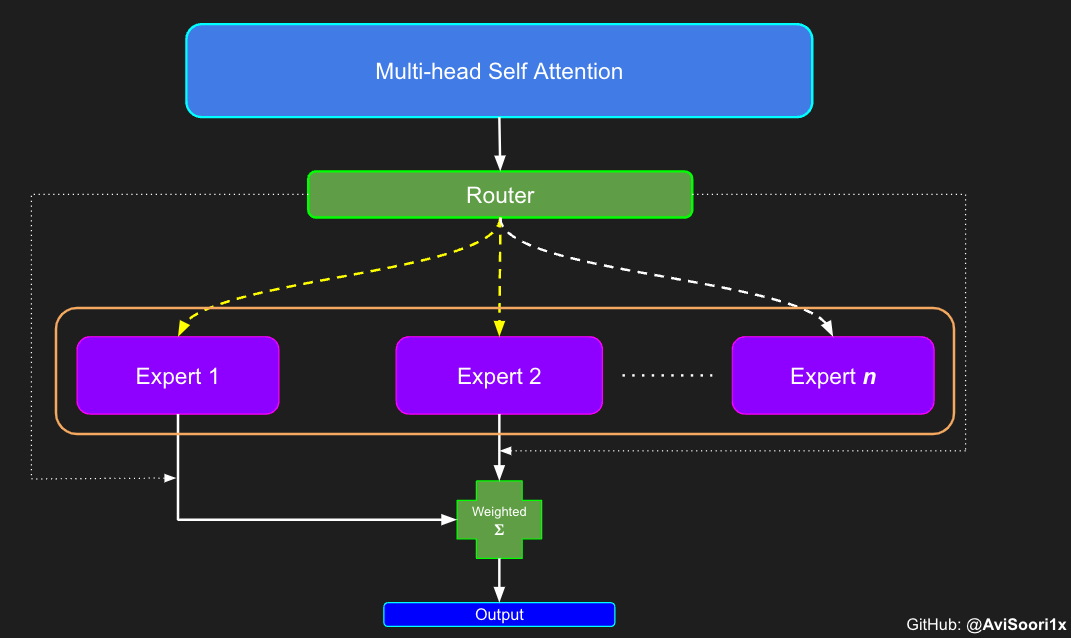
首先,是“专家”,它只是一个MLP,就像我们之前在实现编码器时看到的那样。
#Expert module
class Expert(nn.Module):
""" An MLP is a simple linear layer followed by a non-linearity i.e. each Expert """
def __init__(self, n_embed):
super().__init__()
self.net = nn.Sequential(
nn.Linear(n_embed, 4 * n_embed),
nn.ReLU(),
nn.Linear(4 * n_embed, n_embed),
nn.Dropout(dropout),
)
def forward(self, x):
return self.net(x)
路由模块决定哪些专家将被激活。带有噪声的 top-k 门控/路由会添加一些高斯噪声,以确保在为每个标记选择 top-k 专家时,探索和利用之间取得良好的平衡。这降低了每次都选择相同 n 个专家的可能性,从而违背了通过稀疏激活来增加参数数量以提高泛化能力的初衷。
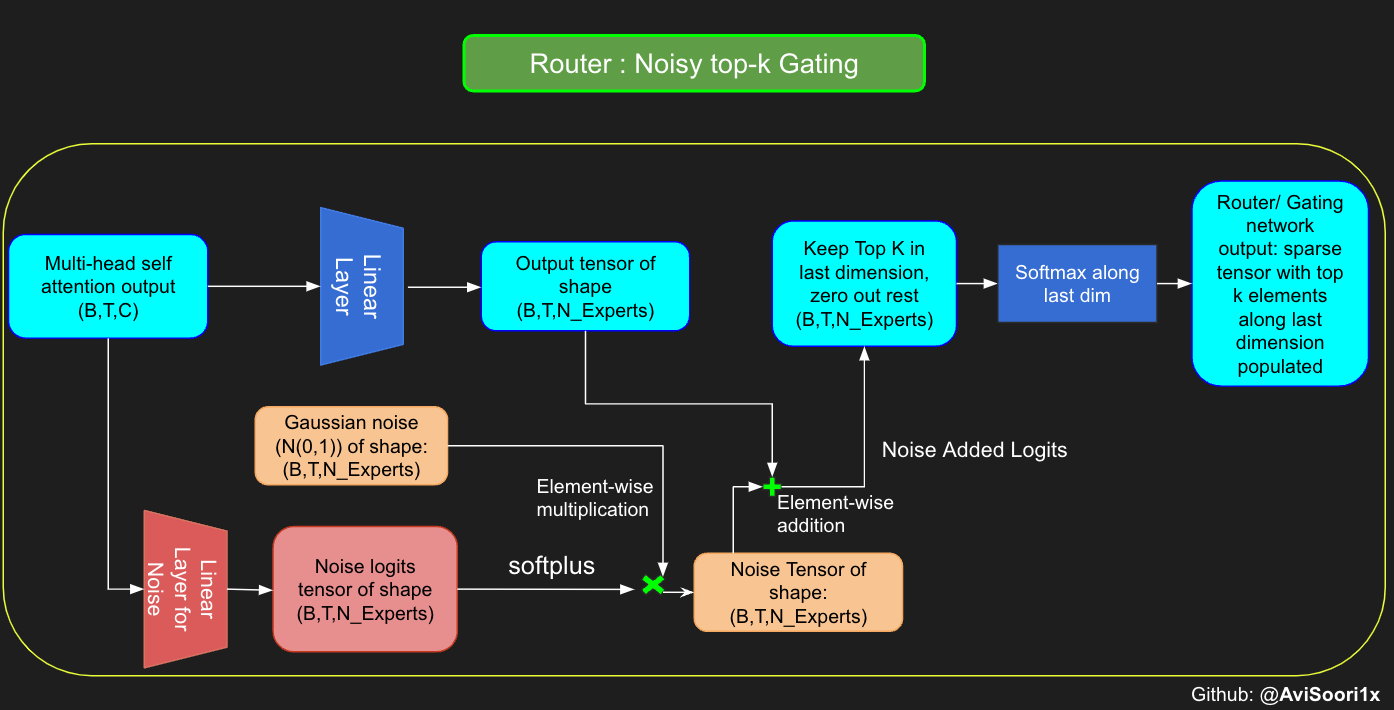
#noisy top-k gating
class NoisyTopkRouter(nn.Module):
def __init__(self, n_embed, num_experts, top_k):
super(NoisyTopkRouter, self).__init__()
self.top_k = top_k
#layer for router logits
self.topkroute_linear = nn.Linear(n_embed, num_experts)
self.noise_linear =nn.Linear(n_embed, num_experts)
def forward(self, mh_output):
# mh_ouput is the output tensor from multihead self attention block
logits = self.topkroute_linear(mh_output)
#Noise logits
noise_logits = self.noise_linear(mh_output)
#Adding scaled unit gaussian noise to the logits
noise = torch.randn_like(logits)*F.softplus(noise_logits)
noisy_logits = logits + noise
top_k_logits, indices = noisy_logits.topk(self.top_k, dim=-1)
zeros = torch.full_like(noisy_logits, float('-inf'))
sparse_logits = zeros.scatter(-1, indices, top_k_logits)
router_output = F.softmax(sparse_logits, dim=-1)
return router_output, indices
现在,可以将噪声-top-k门控和专家结合起来,创建一个稀疏的专家混合模块。请注意,已纳入加权求和计算,以在正向传播中为每个标记生成输出。
#Now create the sparse mixture of experts module
class SparseMoE(nn.Module):
def __init__(self, n_embed, num_experts, top_k):
super(SparseMoE, self).__init__()
self.router = NoisyTopkRouter(n_embed, num_experts, top_k)
self.experts = nn.ModuleList([Expert(n_embed) for _ in range(num_experts)])
self.top_k = top_k
def forward(self, x):
gating_output, indices = self.router(x)
final_output = torch.zeros_like(x)
# Reshape inputs for batch processing
flat_x = x.view(-1, x.size(-1))
flat_gating_output = gating_output.view(-1, gating_output.size(-1))
# Process each expert in parallel
for i, expert in enumerate(self.experts):
# Create a mask for the inputs where the current expert is in top-k
expert_mask = (indices == i).any(dim=-1)
flat_mask = expert_mask.view(-1)
if flat_mask.any():
expert_input = flat_x[flat_mask]
expert_output = expert(expert_input)
# Extract and apply gating scores
gating_scores = flat_gating_output[flat_mask, i].unsqueeze(1)
weighted_output = expert_output * gating_scores
# Update final output additively by indexing and adding
final_output[expert_mask] += weighted_output.squeeze(1)
return final_output
现在可以将其与多头自注意力结合,创建一个稀疏的MoE Transformer块。
class SparseMoEBlock(nn.Module):
def __init__(self, n_embd, num_heads, num_experts, top_k, dropout=0.1, is_decoder=False):
super().__init__()
# Layer normalization for the input to the attention layer
self.ln1 = nn.LayerNorm(n_embd)
# Multi-head attention module
self.attn = MultiHeadAttention(n_embd, num_heads, dropout, is_decoder)
# Layer normalization for the input to the FFN
self.ln2 = nn.LayerNorm(n_embd)
# Feed-forward neural network (FFN)
self.sparseMoE = SparseMoE(n_embd, num_experts, top_k)
def forward(self, x):
original_x = x # Save the input for the residual connection
# Apply layer normalization to the input
x = self.ln1(x)
# Apply multi-head attention
attn_output = self.attn(x)
# Add the residual connection (original input) to the attention output
x = original_x + attn_output
# Apply layer normalization to the input to the FFN
x = self.ln2(x)
# Apply the FFN
sparseMoE_output = self.sparseMoE(x)
# Add the residual connection (input to FFN) to the FFN output
x = x + sparseMoE_output
return x
现在我们将稀疏 MoE Transformer 架构语言解码器模型与修改后的模块结合起来,以适应由视觉-语言投影器模块创建的“视觉标记”。通常,解码器语言模型(稀疏 MoE 或密集)将保持不变并接收嵌入,我已将视觉-语言投影器整合到模型架构中以简化操作。详细的说明可在本博客中找到:https://huggingface.co/blog/AviSoori1x/seemore-vision-language-model
class MoEDecoderLanguageModel(nn.Module):
def __init__(self, n_embd, image_embed_dim, vocab_size, num_heads, n_layer, num_experts, top_k, use_images=False):
super().__init__()
self.use_images = use_images
# Token embedding table
self.token_embedding_table = nn.Embedding(vocab_size, n_embd)
# Position embedding table
self.position_embedding_table = nn.Embedding(1000, n_embd)
if use_images:
# Image projection layer to align image embeddings with text embeddings
self.image_projection = MultiModalProjector(n_embd, image_embed_dim)
# Stack of transformer decoder blocks
self.sparseMoEBlocks = nn.Sequential(*[SparseMoEBlock(n_embd, num_heads, num_experts, top_k, is_decoder=True) for _ in range(n_layer)])
# Final layer normalization
self.ln_f = nn.LayerNorm(n_embd)
# Language modeling head
self.lm_head = nn.Linear(n_embd, vocab_size)
def forward(self, idx, image_embeds=None, targets=None):
# Get token embeddings from the input indices
tok_emb = self.token_embedding_table(idx)
if self.use_images and image_embeds is not None:
# Project and concatenate image embeddings with token embeddings
img_emb = self.image_projection(image_embeds).unsqueeze(1)
tok_emb = torch.cat([img_emb, tok_emb], dim=1)
# Get position embeddings
pos_emb = self.position_embedding_table(torch.arange(tok_emb.size(1), device=device)).unsqueeze(0)
# Add position embeddings to token embeddings
x = tok_emb + pos_emb
# Pass through the transformer decoder blocks
x = self.sparseMoEBlocks(x)
# Apply final layer normalization
x = self.ln_f(x)
# Get the logits from the language modeling head
logits = self.lm_head(x)
if targets is not None:
if self.use_images and image_embeds is not None:
# Prepare targets by concatenating a dummy target for the image embedding
batch_size = idx.size(0)
targets = torch.cat([torch.full((batch_size, 1), -100, dtype=torch.long, device=device), targets], dim=1)
# Compute the cross-entropy loss
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-100)
return logits, loss
return logits
def generate(self, idx, image_embeds, max_new_tokens):
# The autoregressive character level generation function is just like in any other decoder model implementation
return generated
现在我们有了三个关键组件,可以将它们组合成一个稀疏专家混合视觉语言模型。完整的实现如下。如果去除用于错误处理的 assert 语句,这会非常简单。回到博客开头我给出的概述,这里发生的一切只是:
从视觉编码器获取图像特征(这里是视觉 Transformer,但也可以是任何能够从图像输入生成特征的模型,例如 ResNet 或传统卷积神经网络(毋庸置疑,性能可能会受到影响))
一个投影模块,用于将图像标记投影到与解码器文本嵌入相同的嵌入空间(此实现中,该投影器已与解码器集成)
一个带有 sparseMoE 架构的解码器语言模型,用于在先行图像的条件下生成文本。
class VisionMoELanguageModel(nn.Module):
def __init__(self, n_embd, image_embed_dim, vocab_size, n_layer, img_size, patch_size, num_heads, num_blks, emb_dropout, blk_dropout, num_experts, top_k):
super().__init__()
# Set num_hiddens equal to image_embed_dim
num_hiddens = image_embed_dim
# Assert that num_hiddens is divisible by num_heads
assert num_hiddens % num_heads == 0, "num_hiddens must be divisible by num_heads"
# Initialize the vision encoder (ViT)
self.vision_encoder = ViT(img_size, patch_size, num_hiddens, num_heads, num_blks, emb_dropout, blk_dropout)
# Initialize the language model decoder (DecoderLanguageModel)
self.decoder = MoEDecoderLanguageModel(n_embd, image_embed_dim, vocab_size, num_heads, n_layer,num_experts, top_k, use_images=True)
def forward(self, img_array, idx, targets=None):
# Get the image embeddings from the vision encoder
image_embeds = self.vision_encoder(img_array)
# Check if the image embeddings are valid
if image_embeds.nelement() == 0 or image_embeds.shape[1] == 0:
raise ValueError("Something is wrong with the ViT model. It's returning an empty tensor or the embedding dimension is empty.")
if targets is not None:
# If targets are provided, compute the logits and loss
logits, loss = self.decoder(idx, image_embeds, targets)
return logits, loss
else:
# If targets are not provided, compute only the logits
logits = self.decoder(idx, image_embeds)
return logits
def generate(self, img_array, idx, max_new_tokens):
# Get the image embeddings from the vision encoder
image_embeds = self.vision_encoder(img_array)
# Check if the image embeddings are valid
if image_embeds.nelement() == 0 or image_embeds.shape[1] == 0:
raise ValueError("Something is wrong with the ViT model. It's returning an empty tensor or the embedding dimension is empty.")
# Generate new tokens using the language model decoder
generated_tokens = self.decoder.generate(idx, image_embeds, max_new_tokens)
return generated_tokens
现在回到我们开始的地方。上面的 VisionMoELanguageModel 类将我们打算组合的所有组件完美地封装起来。
训练循环与顶部链接的原始视觉语言博客中的完全相同。请查看以下仓库中的 seeMoE_from_Scratch.ipynb:https://github.com/AviSoori1x/seemore
PS:还有一些更新的方法,例如混合模态早期融合模型,例如 https://arxiv.org/abs/2405.09818。我计划将来实现一个简单的版本。
感谢阅读!





