利用英特尔技术加速 PyTorch 分布式微调


尽管最先进的深度学习模型性能惊人,但其训练时间通常很长。为了加快训练作业,工程团队依赖分布式训练,这是一种分而治之的技术,其中集群中的服务器各保留一份模型副本,在训练集的子集上进行训练,并交换结果以收敛到最终模型。
图形处理单元 (GPU) 长期以来一直是训练深度学习模型的“事实标准”选择。然而,迁移学习的兴起正在改变这一局面。模型现在很少从零开始在庞大数据集上进行训练。相反,它们经常在特定(和更小)的数据集上进行微调,以构建比基础模型在特定任务上更准确的专用模型。由于这些训练作业要短得多,使用基于 CPU 的集群可能是一种有趣的选择,可以同时控制训练时间和成本。
本文内容
在本文中,您将学习如何通过在搭载 Ice Lake 架构和性能优化软件库的 Intel Xeon 可扩展 CPU 服务器集群上分发训练作业来加速 PyTorch 训练作业。我们将从零开始使用虚拟机构建集群,您应该能够轻松地在自己的基础设施上复制此演示,无论是在云端还是在本地。
通过运行文本分类作业,我们将在 MRPC 数据集(GLUE 基准测试中包含的任务之一)上微调 BERT 模型。MRPC 数据集包含从新闻来源提取的 5,800 对句子,并带有一个标签,告诉我们每对句子中的两个句子是否语义等效。我们选择这个数据集是因为它的训练时间合理,而尝试其他 GLUE 任务只需更改一个参数即可。
集群启动并运行后,我们将在单个服务器上运行基线作业。然后,我们将将其扩展到 2 台服务器和 4 台服务器,并测量加速比。
在此过程中,我们将涵盖以下主题:
- 列出所需的基础设施和软件构建模块,
- 设置我们的集群,
- 安装依赖项,
- 运行单节点作业,
- 运行分布式作业。
我们开始工作吧!
使用英特尔服务器
为了获得最佳性能,我们将使用基于 Ice Lake 架构的英特尔服务器,该架构支持 Intel AVX-512 和 Intel Vector Neural Network Instructions (VNNI) 等硬件功能。这些功能可加速深度学习训练和推理中常见的操作。您可以在此演示文稿 (PDF) 中了解更多信息。
所有三家主要云提供商都提供由英特尔 Ice Lake CPU 驱动的虚拟机:
- 亚马逊网络服务:Amazon EC2 M6i 和 C6i 实例。
- Azure:Dv5/Dsv5 系列、Ddv5/Ddsv5 系列 和 Edv5/Edsv5 系列 虚拟机。
- Google Cloud Platform:N2 Compute Engine 虚拟机。
当然,您也可以使用自己的服务器。如果它们基于 Cascade Lake 架构(Ice Lake 的前身),那么它们也可以使用,因为 Cascade Lake 也包含 AVX-512 和 VNNI。
使用英特尔性能库
为了在 PyTorch 中利用 AVX-512 和 VNNI,英特尔设计了 PyTorch 英特尔扩展。该软件库为训练和推理提供了开箱即用的加速,因此我们绝对应该安装它。
在分布式训练中,主要的性能瓶颈通常是网络。事实上,集群中的不同节点需要定期交换模型状态信息以保持同步。由于转换器是具有数十亿参数(有时更多)的大型模型,因此信息量很大,并且随着节点数量的增加,情况只会变得更糟。因此,使用为深度学习优化的通信库很重要。
事实上,PyTorch 包含 torch.distributed 包,它支持不同的通信后端。在这里,我们将使用英特尔 oneAPI 集体通信库 (oneCCL),它是深度学习中使用的通信模式(all-reduce 等)的高效实现。您可以在这篇 PyTorch 博客文章中了解 oneCCL 与其他后端相比的性能。
现在我们已经清楚了构建模块,接下来我们谈谈训练集群的整体设置。
设置我们的集群
在此演示中,我使用运行 Amazon Linux 2 的 Amazon EC2 实例(c6i.16xlarge,64 vCPU,128GB RAM,25Gbit/s 网络)。在其他环境中设置会有所不同,但步骤应该非常相似。
请记住,您将需要 4 个相同的实例,因此您可能需要规划某种自动化以避免重复运行相同的设置 4 次。在这里,我将手动设置一个实例,从该实例创建新的 Amazon Machine Image (AMI),然后使用此 AMI 启动三个相同的实例。
从网络角度来看,我们需要以下设置:
- 在所有实例上打开端口 22 以进行
ssh访问,用于设置和调试。 - 配置主实例(您将从该实例启动训练)与所有其他实例(**包括主实例**)之间的无密码
ssh。 - 在所有实例上打开所有 TCP 端口,用于集群内部的 oneCCL 通信。**请确保不要将这些端口向外部世界开放**。AWS 提供了一种方便的方法,即只允许来自运行特定安全组的实例的连接。这是我的设置:

现在,让我们手动配置第一个实例。我首先创建实例本身,附加上面的安全组,并添加 128GB 存储。为了优化成本,我将其作为竞价型实例启动。
实例启动后,我通过 ssh 连接到它以安装依赖项。
安装依赖项
我们将遵循以下步骤:
- 安装 Intel 工具包,
- 安装 Anaconda 分发版,
- 创建新的
conda环境, - 安装 PyTorch 和 PyTorch 的 Intel 扩展,
- 编译并安装 oneCCL,
- 安装
transformers库。
看起来很多,但一点也不复杂。我们开始吧!
安装英特尔工具包
首先,我们下载并安装英特尔 OneAPI 基础工具包 和 AI 工具包。您可以在英特尔网站上了解更多信息。
wget https://registrationcenter-download.intel.com/akdlm/irc_nas/18236/l_BaseKit_p_2021.4.0.3422_offline.sh
sudo bash l_BaseKit_p_2021.4.0.3422_offline.sh
wget https://registrationcenter-download.intel.com/akdlm/irc_nas/18235/l_AIKit_p_2021.4.0.1460_offline.sh
sudo bash l_AIKit_p_2021.4.0.1460_offline.sh
安装 Anaconda
然后,我们下载并安装 Anaconda 发行版。
wget https://repo.anaconda.com/archive/Anaconda3-2021.05-Linux-x86_64.sh
sh Anaconda3-2021.05-Linux-x86_64.sh
创建新的 conda 环境
我们注销并重新登录以刷新路径。然后,我们创建一个新的 conda 环境以保持整洁。
yes | conda create -n transformer python=3.7.9 -c anaconda
eval "$(conda shell.bash hook)"
conda activate transformer
yes | conda install pip cmake
安装 PyTorch 和 PyTorch 的英特尔扩展
接下来,我们安装 PyTorch 1.9 和英特尔扩展工具包。**版本必须匹配**。
yes | conda install pytorch==1.9.0 cpuonly -c pytorch
pip install torch_ipex==1.9.0 -f https://software.intel.com/ipex-whl-stable
编译并安装 oneCCL
然后,我们安装编译 oneCCL 所需的一些原生依赖项。
sudo yum -y update
sudo yum install -y git cmake3 gcc gcc-c++
接下来,我们克隆 oneCCL 存储库,构建库并安装它。**再次强调,版本必须匹配**。
source /opt/intel/oneapi/mkl/latest/env/vars.sh
git clone https://github.com/intel/torch-ccl.git
cd torch-ccl
git checkout ccl_torch1.9
git submodule sync
git submodule update --init --recursive
python setup.py install
cd ..
安装 transformers 库
接下来,我们安装 transformers 库以及运行 GLUE 任务所需的依赖项。
pip install transformers datasets
yes | conda install scipy scikit-learn
最后,我们克隆包含将要运行的示例的 transformers 存储库的分支。
git clone https://github.com/kding1/transformers.git
cd transformers
git checkout dist-sigopt
大功告成!让我们运行一个单节点作业。
启动单节点作业
为了获得基线,让我们启动一个单节点作业,运行 transformers/examples/pytorch/text-classification 中的 run_glue.py 脚本。这应该适用于任何实例,并且在进行分布式训练之前是一个很好的健全性检查。
python run_glue.py \
--model_name_or_path bert-base-cased --task_name mrpc \
--do_train --do_eval --max_seq_length 128 \
--per_device_train_batch_size 32 --learning_rate 2e-5 --num_train_epochs 3 \
--output_dir /tmp/mrpc/ --overwrite_output_dir True
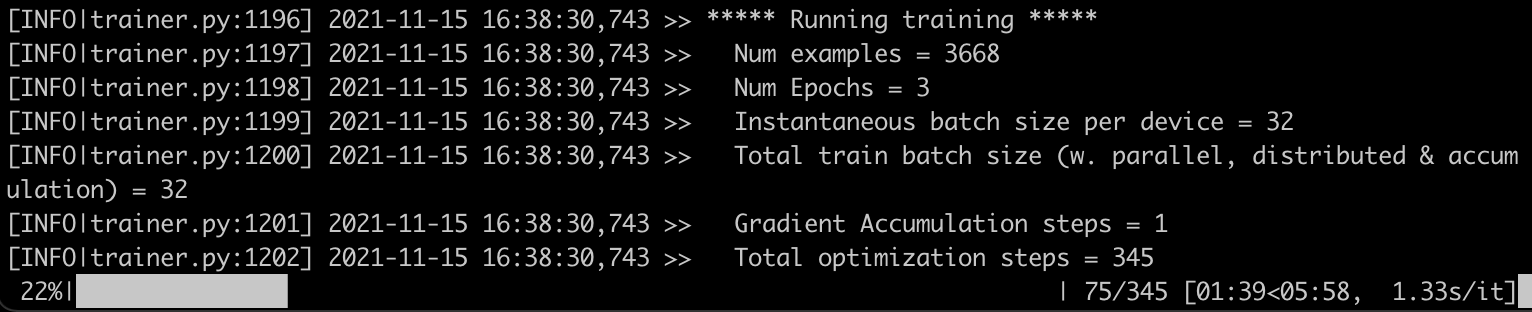
此作业耗时**7 分 46 秒**。现在,让我们使用 oneCCL 设置分布式作业并加快速度!
使用 oneCCL 设置分布式作业
运行分布式训练作业需要三个步骤:
- 列出训练集群的节点,
- 定义环境变量,
- 修改训练脚本。
列出训练集群的节点
在主实例上,在 transformers/examples/pytorch/text-classification 中,我们创建一个名为 hostfile 的文本文件。该文件存储集群中节点的名称(IP 地址也可以)。第一行应指向主实例。
这是我的文件
ip-172-31-28-17.ec2.internal
ip-172-31-30-87.ec2.internal
ip-172-31-29-11.ec2.internal
ip-172-31-20-77.ec2.internal
定义环境变量
接下来,我们需要在主节点上设置一些环境变量,最重要的是其 IP 地址。您可以在文档中找到有关 oneCCL 变量的更多信息。
for nic in eth0 eib0 hib0 enp94s0f0; do
master_addr=$(ifconfig $nic 2>/dev/null | grep netmask | awk '{print $2}'| cut -f2 -d:)
if [ "$master_addr" ]; then
break
fi
done
export MASTER_ADDR=$master_addr
source /home/ec2-user/anaconda3/envs/transformer/lib/python3.7/site-packages/torch_ccl-1.3.0+43f48a1-py3.7-linux-x86_64.egg/torch_ccl/env/setvars.sh
export LD_LIBRARY_PATH=/home/ec2-user/anaconda3/envs/transformer/lib/python3.7/site-packages/torch_ccl-1.3.0+43f48a1-py3.7-linux-x86_64.egg/:$LD_LIBRARY_PATH
export LD_PRELOAD="${CONDA_PREFIX}/lib/libtcmalloc.so:${CONDA_PREFIX}/lib/libiomp5.so"
export CCL_WORKER_COUNT=4
export CCL_WORKER_AFFINITY="0,1,2,3,32,33,34,35"
export CCL_ATL_TRANSPORT=ofi
export ATL_PROGRESS_MODE=0
修改训练脚本
以下更改已应用于我们的训练脚本 (run_glue.py),以启用分布式训练。在使用您自己的训练代码时,您需要应用类似的更改。
- 导入
torch_ccl包。 - 接收主节点的地址和节点在集群中的本地排名。
+import torch_ccl
+
import datasets
import numpy as np
from datasets import load_dataset, load_metric
@@ -47,7 +49,7 @@ from transformers.utils.versions import require_version
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.13.0.dev0")
+# check_min_version("4.13.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/text-classification/requirements.txt")
@@ -191,6 +193,17 @@ def main():
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
+ # add local rank for cpu-dist
+ sys.argv.append("--local_rank")
+ sys.argv.append(str(os.environ.get("PMI_RANK", -1)))
+
+ # ccl specific environment variables
+ if "ccl" in sys.argv:
+ os.environ["MASTER_ADDR"] = os.environ.get("MASTER_ADDR", "127.0.0.1")
+ os.environ["MASTER_PORT"] = "29500"
+ os.environ["RANK"] = str(os.environ.get("PMI_RANK", -1))
+ os.environ["WORLD_SIZE"] = str(os.environ.get("PMI_SIZE", -1))
+
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
现在设置完成。让我们将训练作业扩展到 2 个节点和 4 个节点。
使用 oneCCL 运行分布式作业
在**主节点**上,我使用 mpirun 启动一个 2 节点作业:-np(进程数)设置为 2,-ppn(每节点进程数)设置为 1。因此,将选择 hostfile 中的前两个节点。
mpirun -f hostfile -np 2 -ppn 1 -genv I_MPI_PIN_DOMAIN=[0xfffffff0] \
-genv OMP_NUM_THREADS=28 python run_glue.py \
--model_name_or_path distilbert-base-uncased --task_name mrpc \
--do_train --do_eval --max_seq_length 128 --per_device_train_batch_size 32 \
--learning_rate 2e-5 --num_train_epochs 3 --output_dir /tmp/mrpc/ \
--overwrite_output_dir True --xpu_backend ccl --no_cuda True
几秒钟内,作业在最初的两个节点上开始。作业在**4 分 39 秒**内完成,加速比为 **1.7 倍**。

将 -np 设置为 4 并启动新作业后,我现在看到集群中的每个节点上都运行着一个进程。

训练在**2 分 36 秒**内完成,加速比为**3 倍**。
最后一件事。将 --task_name 更改为 qqp,我还运行了 Quora Question Pairs GLUE 任务,该任务基于更大的数据集(超过 400,000 个训练样本)。微调时间如下:
- 单节点:11 小时 22 分钟,
- 2 个节点:6 小时 38 分钟 (1.71x),
- 4 个节点:3 小时 51 分钟 (2.95x)。
看来加速效果相当一致。您可以随意继续尝试不同的学习率、批量大小和 oneCCL 设置。我相信您能更快!
结论
在本文中,您学习了如何构建基于英特尔 CPU 和性能库的分布式训练集群,以及如何使用该集群来加速微调作业。事实上,迁移学习正在使 CPU 训练重新回到人们的视野中,在设计和构建下一个深度学习工作流时,您绝对应该考虑它。
感谢您阅读这篇长文。希望您觉得它信息丰富。欢迎将反馈和问题发送至 julsimon@huggingface.co。下次再见,继续学习!
朱利安

