在 Vertex AI 中部署 🤗 Hub 模型







TL;DR Vertex AI 是 Google Cloud 的一项服务,可通过统一的 AI 平台中的预训练 API 更快地构建和部署 ML 模型。Hugging Face Hub 是一个包含 50 多万个模型、10 万个数据集和 15 万个演示应用程序(Spaces)的平台,所有这些都是开源和公开可用的,人们可以在一个在线平台中轻松协作并共同构建 ML。本文展示了如何在 Vertex AI 中使用 Hub 中的几乎任何模型运行在线预测,以简单、可扩展和灵活的方式将模型作为端点运行。
在这篇文章中,我们将介绍如何使用 Google Cloud Vertex AI 服务以及如何轻松地从 HuggingFace Hub 部署模型以进行在线预测。我们将从自定义预测例程 (CPR) 的定义开始,构建一个由 🤗 `transformers.pipeline` 支持的 HuggingFace 模型 CPR,并展示如何在 Vertex AI 中注册和部署这些模型,以运行在线预测。
要求
需要安装 **gcloud** CLI 并登录到将要使用的项目。请参阅安装说明:https://cloud.google.com/sdk/docs/install
**docker** 需要在本地安装并运行,因为它将用于在将 CPR 镜像推送到容器注册表之前构建这些镜像。请参阅安装说明:https://docs.container.net.cn/engine/install/
需要 **google-cloud-aiplatform** Python SDK,用于以编程方式构建 CPR 镜像,通过自定义 Predictor 定义自定义预测代码,在 Vertex AI 中注册和部署模型到端点,以及在其上运行在线预测。
pip install google-cloud-aiplatform --upgrade需要安装 **git lfs** 才能从 HuggingFace Hub 拉取/克隆模型。请参阅安装说明:https://git-lfs.com/。
自定义预测例程 (CPR)
自定义预测例程 (CPR) 允许您轻松构建带有预处理/后处理代码的自定义容器,而无需处理设置 HTTP 服务器或从头开始构建容器的细节。您可以使用预处理来标准化/转换输入或调用外部服务以获取额外数据,并使用后处理来格式化模型预测或运行业务逻辑。

更多信息请访问:Google Cloud Vertex AI - 自定义预测例程。
自定义预测代码
为了成功地在 HuggingFace 模型上运行推理,我们需要定义一个继承自 `google-cloud-aiplatform` 中 `Predictor` 类的自定义类。
为了运行推理,我们将使用 🤗 `transformers` 中的 `pipeline` 方法,该方法将作为由环境变量 `HF_TASK` 控制的 `Predictor.load` 方法的一部分加载;然后管道将在预测方法中运行,并将输出生成为 Python 字典。
因此,包含自定义预测代码的 `predictor.py` 文件将是以下内容
import os
import logging
import tarfile
from typing import Any, Dict
from transformers import pipeline
from google.cloud.aiplatform.prediction.predictor import Predictor
from google.cloud.aiplatform.utils import prediction_utils
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
class HuggingFacePredictor(Predictor):
def __init__(self) -> None:
pass
def load(self, artifacts_uri: str) -> None:
"""Loads the preprocessor and model artifacts."""
logger.info(f"Downloading artifacts from {artifacts_uri}")
prediction_utils.download_model_artifacts(artifacts_uri)
logger.info("Artifacts successfully downloaded!")
os.makedirs("./model", exist_ok=True)
with tarfile.open("model.tar.gz", "r:gz") as tar:
tar.extractall(path="./model")
logger.info(f"HF_TASK value is {os.getenv('HF_TASK')}")
self._pipeline = pipeline(os.getenv("HF_TASK", ""), model="./model", device_map="auto")
logger.info("`pipeline` successfully loaded!")
logger.info(f"`pipeline` is using device={self._pipeline.device}")
def predict(self, instances: Dict[str, Any]) -> Dict[str, Any]:
return self._pipeline(**instances)
除了自定义 `Predictor` 的代码,我们还需要在与 `predictor.py` 文件相同的目录中包含 `requirements.txt` 文件中的要求。
torch==2.2.0
transformers==4.38.1
accelerate==0.27.0
注意:`predictor.py` 和 `requirements.txt` 文件都需要在同一个目录中,因为在后续步骤中构建 Docker 镜像时,它们将被复制到 Dockerfile 中。
自定义 Docker 镜像
在构建自定义 Docker 镜像之前,我们需要在 Google Artifact Registry 中创建一个 Docker 存储库,并配置我们的 Docker 以授权将镜像推送到该存储库。
因此,应安装并运行 `docker`,以便运行以下命令并构建 Docker 镜像。
gcloud artifacts repositories create <REPOSITORY> --repository-format docker --location <REGION>
gcloud auth configure-docker <REGION>-docker.pkg.dev
然后,我们将使用 `google-cloud-aiplatform` 中的 `LocalModel.build_cpr_model` 方法来创建和构建 Docker 镜像,该镜像将包含自定义预测代码,并将在提供的 `base_image` 中安装所需的环境。
由于在这种情况下我们需要确保镜像包含所需的 CUDA 库,我们将使用 Docker Hub 中的 `alvarobartt/torch-gpu`,该镜像已安装 `torch 2.2.0` 和 CUDA 12.3。或者,也可以构建和上传自己的 Docker 镜像,或使用 Docker Hub 或 NVIDIA 容器注册表等授权容器注册表中的任何镜像。
import os
from google.cloud.aiplatform.prediction import LocalModel
from <PATH>.predictor import HuggingFacePredictor
local_model = LocalModel.build_cpr_model(
"<PATH>",
"<REGION>-docker.pkg.dev/<PROJECT_ID>/<REPOSITORY>/<IMAGE>:<TAG>",
predictor=HuggingFacePredictor,
requirements_path="<PATH>/requirements.txt",
base_image="--platform=linux/amd64 alvarobartt/torch-gpu:py310-cu12.3-torch-2.2.0 AS build",
)
local_model.push_image()
因此,上述 Docker 镜像将被推送到 REGION-docker.pkg.dev/PROJECT_ID/REPOSITORY/IMAGE:TAG。
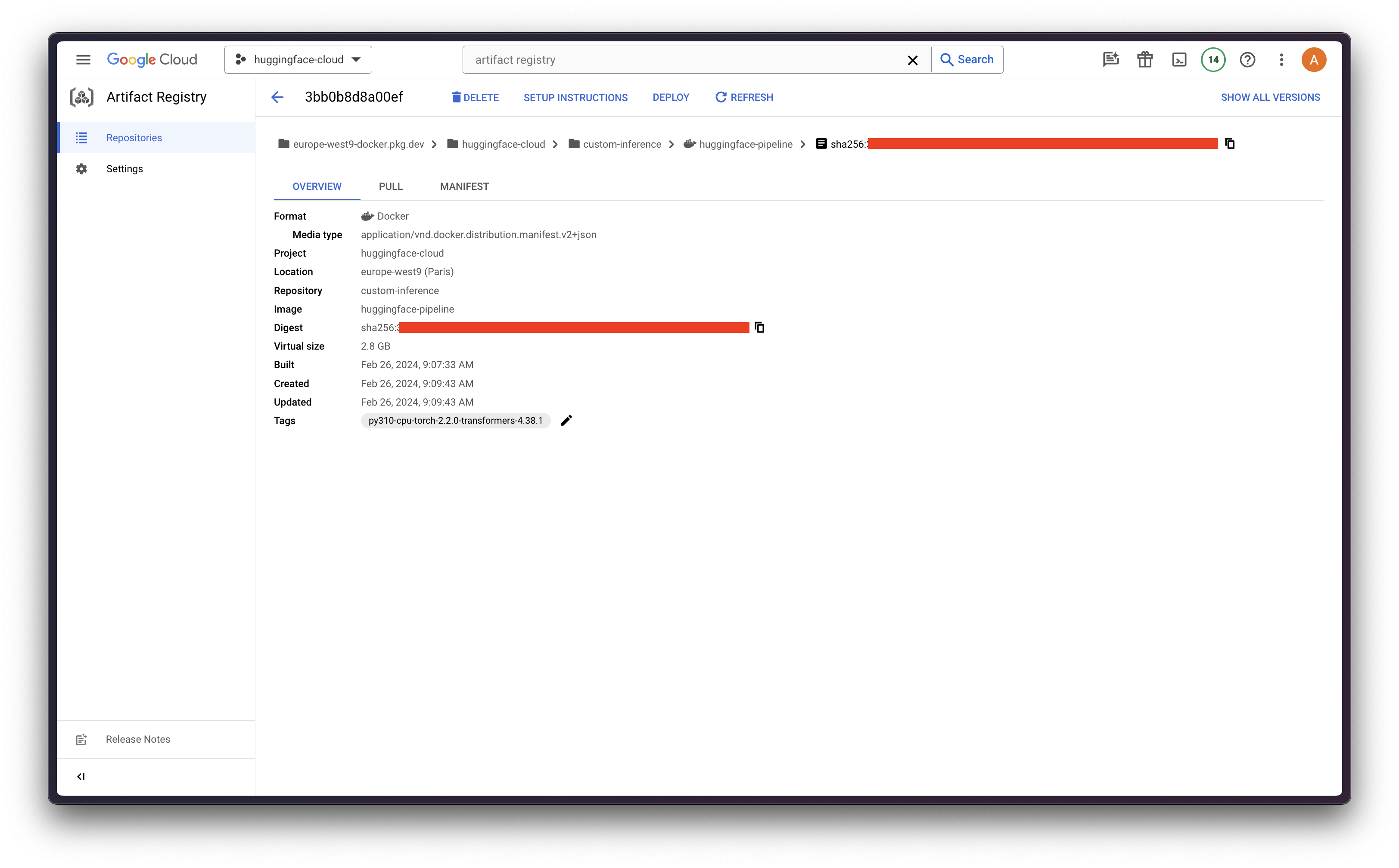
模型上传
首先,我们需要决定要使用 HuggingFace Hub 中的哪个模型,在本例中,我们将使用 `facebook/bart-large-mnli`,这是一个零样本分类模型。
为了做到这一点,我们将使用 `git pull` 从 HuggingFace Hub 中拉取模型,这需要提前安装 `git lfs`,以便也从存储库中拉取大文件。
git lfs install
git clone https://huggingface.co/facebook/bart-large-mnli
然后我们将分词器和模型所需的所有文件压缩到 `model.tar.gz` 文件中
cd bart-large-mnli/
tar zcvf model.tar.gz --exclude flax_model.msgpack --exclude pytorch_model.bin --exclude rust_model.ot *
最后将其上传到 Google Cloud Storage (GCS)
gcloud config set storage/parallel_composite_upload_enabled True
gcloud storage cp model.tar.gz gs://<BUCKET_NAME>
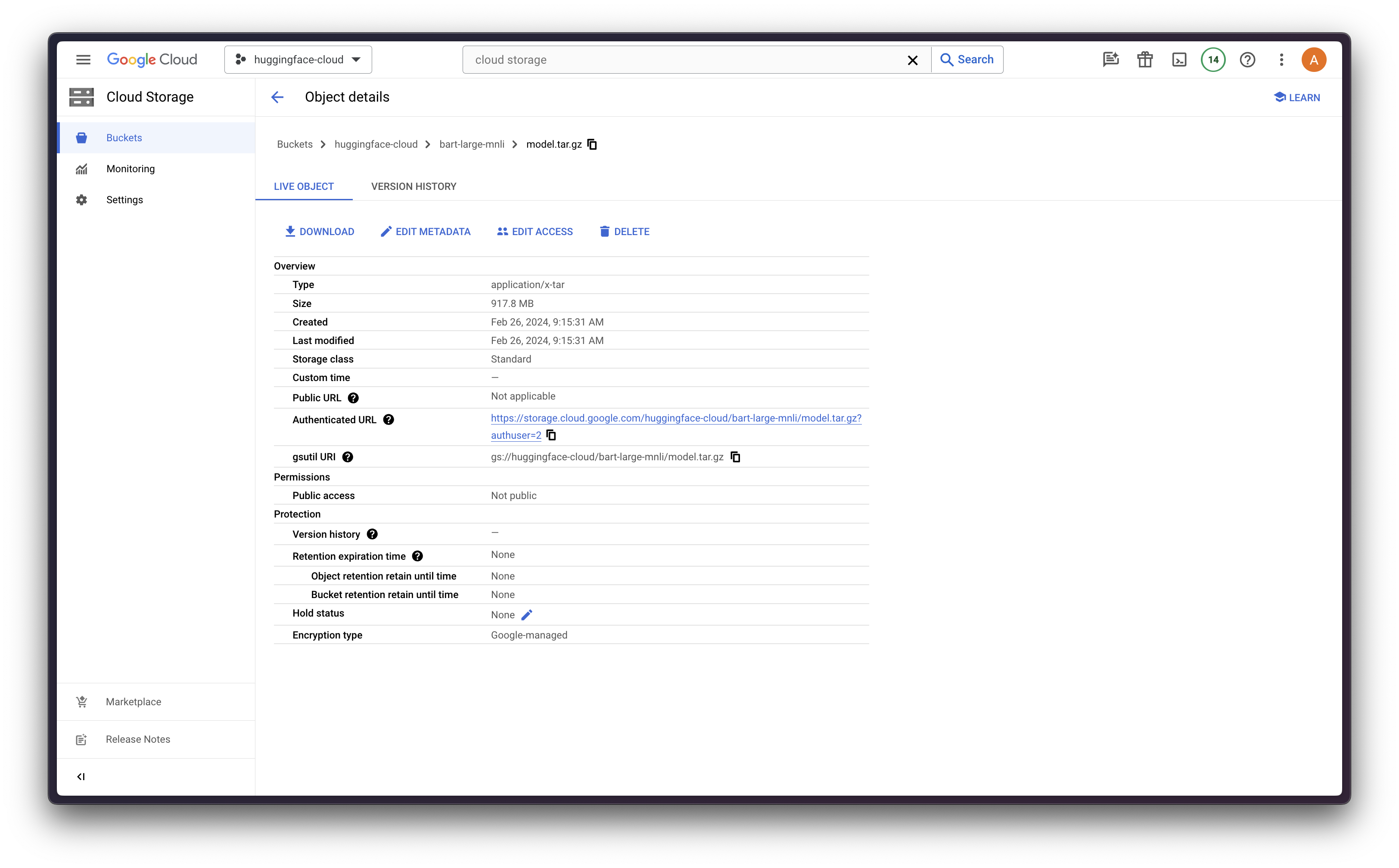
模型注册
一旦模型上传到 GCS 并且 CPR 镜像已推送到 Google 的 Docker Artifact Registry,我们就可以在 Vertex AI 中注册模型了。
确保您已通过 `gcloud` 提前登录
gcloud auth login
gcloud auth application-default login
然后运行以下代码将模型注册(上传)到 Vertex AI
from google.cloud import aiplatform
aiplatform.init(project="<PROJECT_ID>", location="<REGION>")
model = aiplatform.Model.upload(
display_name="bart-large-mnli",
artifact_uri="gs://<BUCKET_NAME>",
serving_container_image_uri="<REGION>-docker.pkg.dev/<PROJECT_ID>/<REPOSITORY>/<IMAGE>:<TAG>",
serving_container_environment_variables={
"HF_TASK": "zero-shot-classification",
"VERTEX_CPR_WEB_CONCURRENCY": 1,
},
)
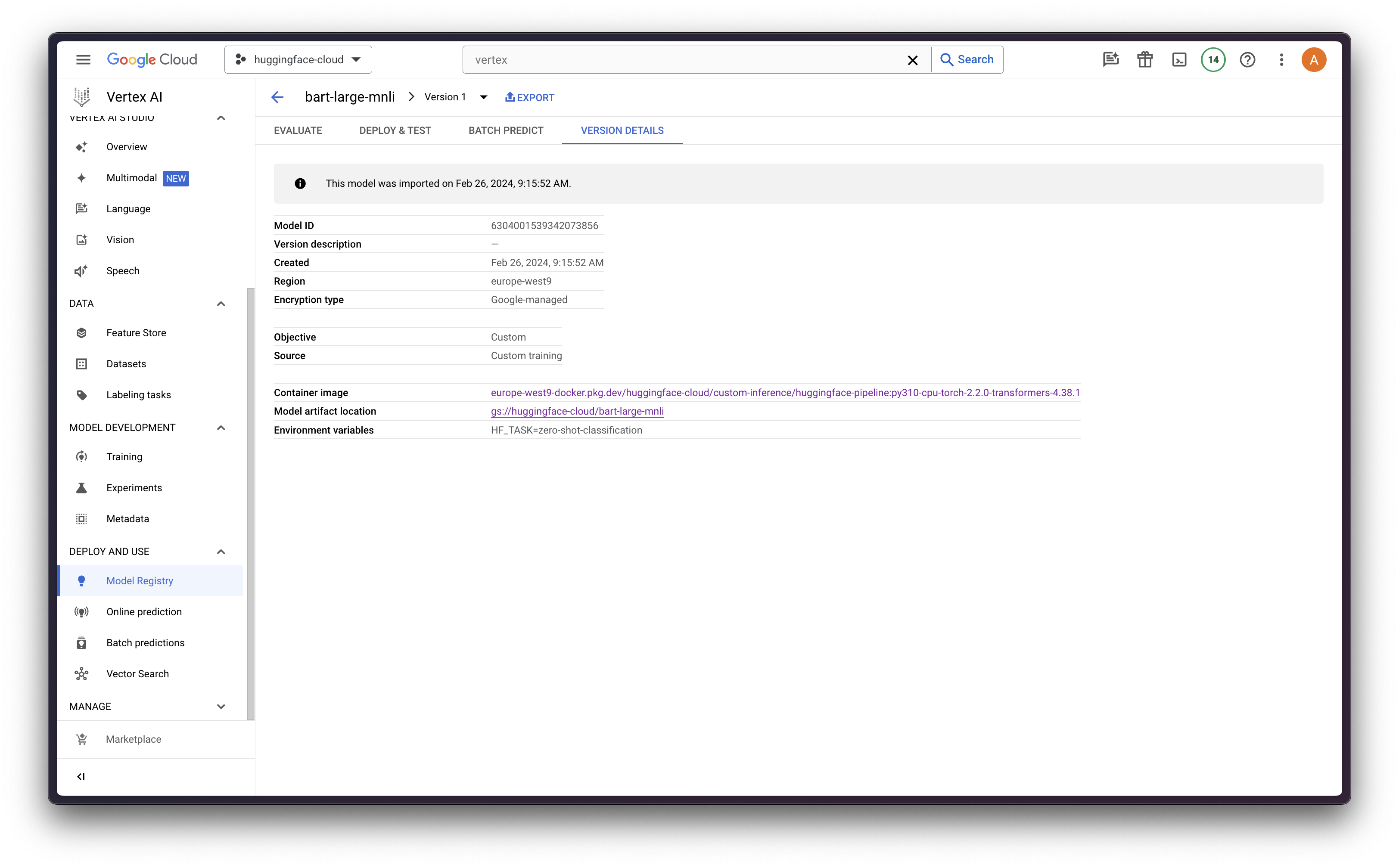
模型部署
最后,我们可以使用 `upload` 方法返回的 `aiplatform.Model` 对象调用 `deploy` 方法,该方法将部署一个使用 FastAPI(除非 CPR 中的处理程序被覆盖)在与 `machine_type` 参数匹配的机器上运行的端点。
在这种情况下,我们将使用 N1-系列中的 `n1-standard-4`,它配备了 NVIDIA Tesla T4 GPU 加速,4 个 vCPU 和 15 GB 内存。更多信息请参见 Google Cloud Compute Engine - GPU 平台。
endpoint = model.deploy(
machine_type="n1-standard-4",
accelerator_type="NVIDIA_TESLA_T4",
accelerator_count=1,
)
注意:`deploy` 方法需要大约 15-20 分钟才能将模型部署为 Vertex AI 中的端点。
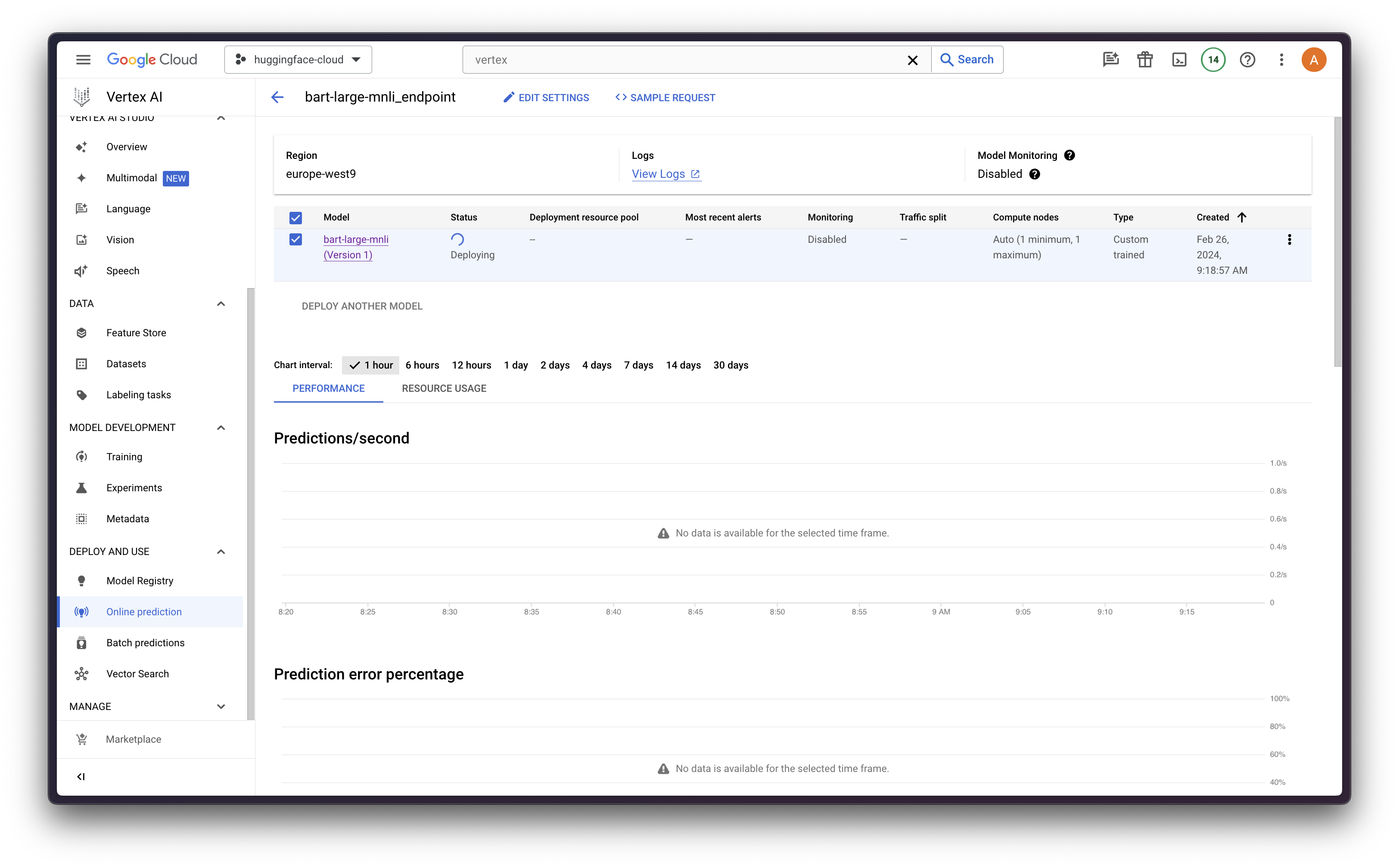
在线预测
最后,我们可以使用 Vertex AI 的 Python 客户端在 Vertex AI 上运行在线预测,它基本上会将请求发送到正在运行的端点,我们还可以通过 Google Cloud Logging 服务密切监控它。
import json
from google.api import httpbody_pb2
from google.cloud import aiplatform_v1
prediction_client = aiplatform_v1.PredictionServiceClient(
client_options={"api_endpoint": "<REGION>-aiplatform.googleapis.com"}
)
data = {
"sequences": "Last week I upgraded my iOS version and ever since then my phone has been overheating whenever I use your app.",
"candidate_labels": ["mobile", "website", "billing", "account access"],
}
json_data = json.dumps(data)
http_body = httpbody_pb2.HttpBody(
data=json_data.encode("utf-8"),
content_type="application/json",
)
request = aiplatform_v1.RawPredictRequest(
endpoint=endpoint.resource_name,
http_body=http_body,
)
response = prediction_client.raw_predict(request)
json.loads(response.data)
参考资料
所有代码和参考资料请参见 `alvarobartt/vertex-ai-huggingface/online-prediction/04-from-hub-to-vertex-ai-gpu.ipynb`。
如果您对如何使用 Vertex AI 服务训练、部署和监控 HuggingFace 模型的更多示例感兴趣,请查看存储库 `alvarobartt/vertex-ai-huggingface`。






