我训练了一个语言模型来使用 GRPO 安排事件!







2025年,在 DeepSeek 热潮之后,每个人都想用 GRPO 训练自己的推理模型。
作为一名核心实践者,我也想这样做:让语言模型仅从提示和奖励中学习是件很有趣的事情——与监督微调不同,它不需要完成。
你可以在网上找到的大多数例子都训练模型来解决 GSM8K 或倒计时游戏。我想尝试一些原创的东西,并亲自动手。
所以我想:我能让模型从事件和优先级列表中创建日程安排吗?
我的第一次实验表明,ChatGPT 通常可以解决这类问题,而小型语言模型(14B以下)则难以应付。这是一个很好的挑战!
我没有意识到的是,选择一个原创问题会迫使我思考问题设置、生成数据、选择基础模型、设计奖励函数,并进行多轮训练,希望我的模型能学到一些东西。
有很多东西要学,这正是我想在这篇文章中与你分享的。
你可以在 👑 🗓️ Qwen Scheduler GRPO 仓库中找到所有代码。
跟着我一起做吧!
本文主要讲述我的实践经验。具备一些 GRPO 的理论知识可能会有所帮助。你可以在网上找到许多资源,例如 DeepSeekMath 论文和 Hugging Face 推理课程。
问题定义
我们来描述一下我们希望语言模型解决的问题。
我们给模型一个事件列表(包含开始/结束时间),并告诉它哪些是高优先级事件。目标是创建一个日程表,使所选事件的总加权持续时间最大化。
在此设置中,优先事件的权重为 2,普通事件的权重为 1。
📌 您可能会注意到,问题定义清晰合理,但有些随意。也许您更愿意最大化利润,或者甚至不希望日程安排得满满的。这完全没问题。那只是一个不同的问题,您也可以尝试用 GRPO 训练一个模型来解决它。
我想说,一旦您能清晰地通过提示向模型解释任务,弄清楚如何奖励好的输出,并有时识别模型中可鼓励的行为以进行训练,您就可以很好地尝试使用 GRPO 了。稍后我将对此进行详细说明。
我们来看一个问题示例。
输入示例
这是提示的缩短版本(完整提示可以在文章下方找到)。
Task: create an optimized schedule based on the given events.
Rules: ...
You must use this format:
<think>...</think>
<schedule>
<event>
<name>...</name>
<start>...</start>
<end>...</end>
</event>
...
</schedule>
---
Events:
- Event A (01:27 - 01:42)
- Event B (01:15 - 02:30)
- Event C (15:43 - 17:43)
Priorities:
- Event B
输出示例
<think>A detailed reasoning</think>
<schedule>
<event>
<name>Event B</name>
<start>01:15</start>
<end>02:30</end>
</event>
<event>
<name>Event C</name>
<start>15:43</start>
<end>17:43</end>
</event>
</schedule>
经过一番调查,我发现这类问题属于区间调度。
这个具体问题是加权区间调度问题的一个变体,可以通过动态规划高效解决。
这太棒了,因为它允许我们轻松计算任何给定输入可能获得的最佳分数,这是我们模型在训练期间的目标。
数据集生成
现在问题已经明确,我们可以开始构建用于训练和评估模型的数据集了。
数据集中每一行的核心只是一个包含事件列表和模型要安排的优先级的提示。
与监督微调不同,我们不需要提供模型应该遵循的参考完成。这也是为什么在数学等可验证领域,为 GRPO 构建数据集通常更容易的原因之一。
我们还在每行中包含了最佳分数(最大可能的加权持续时间)。模型在训练期间不会看到这个分数,但我们用它来计算奖励,以将模型推向正确的方向。
鉴于这些要求,编写数据集生成脚本相对容易。
- 我们使用来自不同类别(🎶 音乐节,🎓 大学,🧑💻 科技大会,...)的事件名称。
- 每个示例都包含随机数量的事件(4到8个),持续时间各不相同。
- 我们确保某些事件重叠。
- 我们随机将一些事件标记为优先级。
我们为训练集生成了 500 个示例,为测试集生成了 100 个示例。
您可以在这里找到数据集生成脚本。
生成的数据集可在 Hugging Face 上获取。
训练
完整的📓 训练笔记本在此。
如今,有几个训练库支持 GRPO。
Hugging Face TRL 是一个不错的选择,它还支持使用 vLLM 以在训练期间更快地生成样本。
就我而言,我决定使用 Unsloth。这是一个打补丁的 TRL 库,可以大幅减少 GPU 内存使用量。我使用了一块 NVIDIA A6000 GPU (48GB 显存),但稍作调整并耐心等待,您可以在拥有 16GB 显存的免费 Colab/Kaggle 实例上重复相同的实验。
如果您 GPU 资源匮乏,Unsloth 可以很好地用于实验,但它也带有一些令人沮丧的 bug,我们稍后会看到。
选择并加载要训练的模型
我决定训练 Qwen2.5-Coder-7B-Instruct,这是一个 Qwen 系列的代码专用语言模型。
这个决定有点经验性,主要基于两个考量:
我首先尝试了更小的模型(0.5B 和 1.5B)。观察这些小型模型对我的调度提示的完成情况,我注意到它们生成的推理几乎没有意义。这是我的第一个学习:如果基础模型的预训练或大小使其能力与期望相去甚远,GRPO 无法创造奇迹。
我使用代码模型而不是通用模型,部分原因在于这在数学任务中很常见,部分原因在于我注意到该模型已经非常擅长遵循所需格式(
<think>、<schedule>等)。
现在我们可以使用 Unsloth 加载模型了。我们将使用 QLoRA 进行训练以节省 GPU 资源。
from unsloth import FastLanguageModel
max_seq_length = 2048
lora_rank = 32
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "Qwen/Qwen2.5-Coder-7B-Instruct",
max_seq_length = max_seq_length,
load_in_4bit = True,
fast_inference = True,
max_lora_rank = lora_rank,
gpu_memory_utilization = 0.85, # Reduce if out of memory
)
model = FastLanguageModel.get_peft_model(
model,
r = lora_rank,
target_modules = [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
], # Remove QKVO if out of memory
lora_alpha = lora_rank,
use_gradient_checkpointing = "unsloth", # Enable long context finetuning
random_state = 3407,)
如果您的显存小于 48GB,您可以调整几个参数:gpu_memory_utilization、lora_rank 和 target_modules;后两者影响模型可以学习的程度。
数据集准备
我们的数据集中每个示例都包含事件和优先级。
我们对数据集进行预处理,以系统和用户消息的形式添加通用任务描述和指令。
import datasets
SYSTEM_PROMPT = """You are a precise event scheduler.
1. First, reason through the problem inside <think> and </think> tags. Here you can create drafts,
compare alternatives, and check for mistakes.
2. When confident, output the final schedule inside <schedule> and </schedule> tags.
Your schedule must strictly follow the rules provided by the user."""
USER_PROMPT ="""Task: create an optimized schedule based on the given events.
Rules:
- The schedule MUST be in strict chronological order.
Do NOT place priority events earlier unless their actual start time is earlier.
- Event start and end times are ABSOLUTE. NEVER change, shorten, adjust, or split them.
- Priority events (weight = 2) carry more weight than normal events (weight = 1),
but they MUST still respect chronological order.
- Maximize the sum of weighted event durations.
- No overlaps allowed. In conflicts, include the event with the higher weighted time.
- Some events may be excluded if needed to meet these rules.
You must use this format:
<think>...</think>
<schedule>
<event>
<name>...</name>
<start>...</start>
<end>...</end>
</event>
...
</schedule>
---
"""
ds = datasets.load_dataset("anakin87/events-scheduling", split="train")
ds = ds.map(
lambda x: {
"prompt": [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": USER_PROMPT + x["prompt"]},
]
}
)
奖励函数
GRPO 是一种强化学习算法,对于每个提示,都会从模型生成多个样本(我们这里是 8 个)。在训练过程中,模型的参数会更新,以生成高奖励的响应。
因此,虽然我们不需要数据集中的完成结果,但奖励函数的设计至关重要。
在像 GSM8K 这样的简单问题中,常见的选择是定义多个奖励函数并将其求和
- 一个检查输出格式是否正确。
- 另一个检查最终答案是否与已知解决方案匹配。
有关从 GSM8K 学习的绝佳示例,请参阅William Brown 的这份 gist。有关为 TRL/Unsloth 创建自定义奖励函数的指导,请参阅文档。
在我们的实验中,我们可以轻松设计一个**格式奖励函数**。
import re
overall_pattern = (r"<think>.+</think>.*<schedule>.*(<event>.*<name>.+</name>.*<start>\d{2}:\d{2}</start>.*"
r"<end>\d{2}:\d{2}</end>.*</event>)+.*</schedule>")
overall_regex = re.compile(overall_pattern, re.DOTALL)
def format_reward(prompts, completions, **kwargs):
responses = [completion[0]['content'] for completion in completions]
return [0.0 if not overall_regex.match(response) else 10.0 for response in responses]
现在,奖励调度本身的质量就更难了。
有效的日程安排具有以下特点:
- 事件来自原始提示(没有虚构的事件或更改的时间)。
- 事件按时间顺序排序。
- 没有重叠事件。
- 事件至少有两个。
我们还希望鼓励模型生成一个能最大化总加权持续时间的日程。
在确定下面所示的解决方案之前,我尝试了不同数量的奖励函数。我还得到了一些观察结果。
我尝试使用一个单一的分数奖励函数,如果日程有效(满足上述所有标准),则返回 `schedule_score/optimal_score`,否则返回 0。结果表明这是一个坏主意,因为它过于不连续,并且大部分时间返回 0,无法提供足够的信号来指导模型的学习。
另一方面,我尝试使用多个奖励函数,每个上述要求各一个:现有事件、时间顺序、无重叠等。在这种情况下,我发现即使模型学到了一些东西,训练在生成良好日程方面也无效。使用过多的奖励函数也可能适得其反。
在“奖励过多”阶段,我遇到了一个经典的强化学习问题:奖励作弊。我最初忘记丢弃事件少于两个的日程。突然,我的奖励开始看起来很棒!模型在格式、时间顺序、无重叠等方面都获得了高分……我查看了实际输出,发现它找到了一个漏洞:它只是生成只有一个事件(通常是高优先级事件)的日程。这完美地满足了我大多数单个奖励函数的要求。这不是模型聪明,而是我的奖励设置可被利用。一次不错的经历。🙃
我最终使用了一个奖励函数来鼓励生成按时间顺序排列的日程,另一个奖励函数来最大化分数。正如您在下面看到的,我试图将其他要求包含并偏爱地纳入这两个奖励函数中。
def sorted_events_reward(completions, **kwargs):
scores = []
responses = [completion[0]['content'] for completion in completions]
for response in responses:
scheduled_events = get_events(response)
# not a valid schedule: should be discarded
if len(scheduled_events) < 2:
scores.append(0.0)
continue
scheduled_events_minutes = [(ev[0], time_to_minutes(ev[1]), time_to_minutes(ev[2]))
for ev in scheduled_events]
if all(scheduled_events_minutes[i][1] < scheduled_events_minutes[i+1][1]
for i in range(len(scheduled_events_minutes)-1)):
scores.append(20.0)
else:
scores.append(0)
return scores
def score_reward(prompts, completions, events, priority_events, optimal_score, **kwargs):
scores = []
responses = [completion[0]['content'] for completion in completions]
for content, valid_events, priorities, opt_score in zip(responses, events, priority_events, optimal_score):
scheduled_events = get_events(content)
# Get valid scheduled events
existing_events = {ev for ev in scheduled_events if [ev[0], ev[1], ev[2]] in valid_events}
# penalize choosing nonexistent events or less than 2 events (not a valid schedule)
if len(existing_events)<len(scheduled_events) or len(existing_events) < 2:
scores.append(0.0)
continue
# Convert to minutes
existing_events_minutes = [(ev[0], time_to_minutes(ev[1]), time_to_minutes(ev[2]))
for ev in existing_events]
# remove overlapping events and remove both events - to penalize overlaps
overlapping_events = set()
for j in range(len(existing_events_minutes)):
for k in range(j + 1, len(existing_events_minutes)):
if (existing_events_minutes[j][1] <= existing_events_minutes[k][2] and
existing_events_minutes[j][2] >= existing_events_minutes[k][1]):
overlapping_events.add(existing_events_minutes[j])
overlapping_events.add(existing_events_minutes[k])
existing_events_minutes = [ev for ev in existing_events_minutes
if ev not in overlapping_events]
# Calculate score
score = sum(2 * (ev[2] - ev[1]) if ev[0] in priorities
else ev[2] - ev[1] for ev in existing_events_minutes)
scores.append((score/opt_score) * 70)
return scores
简而言之,在我的实验中,我使用了以下奖励函数:
- 格式 (0-10)
- 排序事件 (0-20)
- 分数 (0-70)。
累积奖励可以在0到100之间变化。
我在此步骤上迭代了很多次。正如我们所见,它仍然不完美,但它让模型开始学习了。
设置训练配置并训练!
from trl import GRPOConfig, GRPOTrainer
tokenized_prompts = [tokenizer.apply_chat_template(prompt, tokenize=True, add_generation_prompt=True)
for prompt in ds['prompt']]
exact_max_prompt_length = max([len(tokenized_prompt) for tokenized_prompt in tokenized_prompts])
max_prompt_length = 448 # manually adjusted
new_model_id="anakin87/qwen-scheduler-7b-grpo"
training_args = GRPOConfig(
learning_rate = 8e-6,
adam_beta1 = 0.9,
adam_beta2 = 0.99,
weight_decay = 0.1,
warmup_ratio = 0.01,
lr_scheduler_type = "cosine",
optim = "paged_adamw_8bit",
logging_steps = 1,
per_device_train_batch_size = 8,
gradient_accumulation_steps = 1,
num_generations = 8, # Decrease if out of memory
max_prompt_length = max_prompt_length,
max_completion_length = max_seq_length - max_prompt_length,
max_grad_norm = 0.1,
output_dir = "outputs",
overwrite_output_dir = True,
push_to_hub = True,
hub_model_id=new_model_id,
hub_strategy="every_save",
save_strategy="steps",
save_steps=50,
save_total_limit=1,
num_train_epochs=3,
)
trainer = GRPOTrainer(
model = model,
processing_class = tokenizer,
reward_funcs=[
format_reward,
sorted_events_reward,
score_reward,
],
args = training_args,
train_dataset = ds,
)
trainer.train()
max_prompt_length是提示的最大长度。更长的提示将被截断。我们可以轻松计算此值,然后手动调整。
num_generations 是 GRPO 的一个关键参数,表示每个提示要生成的样本数量。该算法基于比较不同样本进行学习,并引导模型生成更高奖励的样本。更多样本可以提供更多信息供模型学习,从而可能带来更好的结果,但生成它们需要更多时间和内存。
有关其他 GRPOConfig 参数的详细信息,请查阅 TRL API 参考。
结果
训练图表
让我们看看训练曲线。
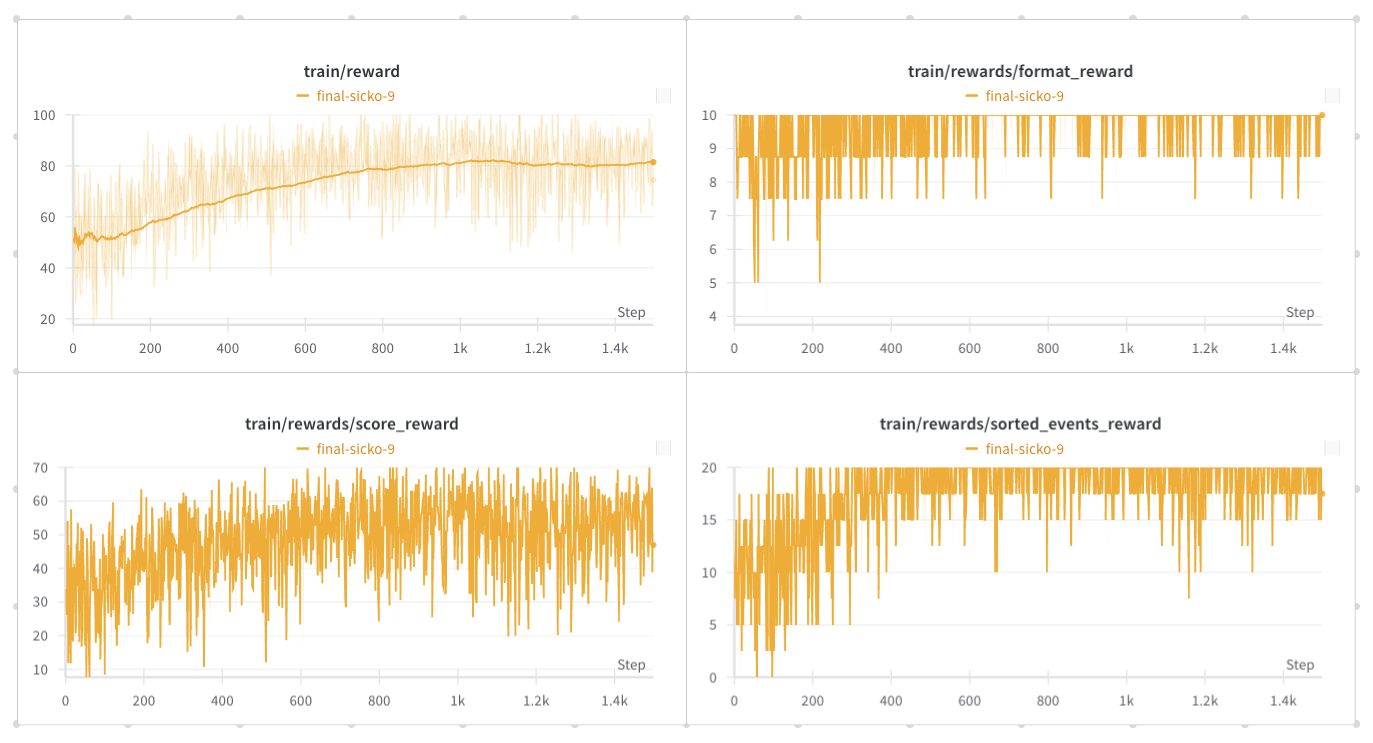
关注奖励方面,我们看到模型在训练过程中有所改进。从一开始,样本在格式对齐方面就获得了不错的评分。随着时间的推移,对时间顺序的遵守和对日程安排的良好评分都有所提高,这表明模型确实学会了奖励函数中形式化的行为。
其他记录的指标,例如 `reward_std`(奖励组内的平均标准差)和 `kl`(模型与参考模型之间的平均 KL 散度)显示出可接受的值。
您可以在此 Weight and Biases 报告中探索所有训练曲线和指标。
检查样本
在训练过程中,我们会记录生成的样本的随机子集。你可以在这里浏览完整的日志。
检查这些完成情况既有趣又富有洞察力。通过这种方式,我才意识到较小的模型根本无法理解:随着时间的推移,它们的推理并没有显著改善。
这是不同训练阶段相同输入提示的示例:
Events:
- Analyzing product performance (04:33 - 06:03)
- One-on-one with manager (08:41 - 08:56)
- Client call with Acme Corp (09:13 - 10:58)
- Meeting with Lisa at café (10:14 - 11:14)
- Updating website content (12:21 - 13:36)
- Preparing PTO handover (16:07 - 17:37)
- Marketing standup on Zoom (17:58 - 19:43)
- Brainstorming with Luke and Patrick (19:11 - 19:56)
Priorities:
- Analyzing product performance
- Meeting with Lisa at café
第473/1500步
<think>
At first glance, the events overlap in the time slot from 10:14 to 11:14. The priority event
"Meeting with Lisa at café" is higher in weight compared to "Client call with Acme Corp", so we must
include it. However, this will exclude the client call if we want to prioritize "Meeting with Lisa
at café". To resolve this, we need to decide whether to exclude the client call or the brainstorming
session (19:11 - 19:56) which is a normal event.
Since "Meeting with Lisa at café" is a priority event and it overlaps with the client call, we should
include "Meeting with Lisa at café" and exclude the client call. This will give us more time for
"Updating website content" (12:21 - 13:36) and "Preparing PTO handover" (16:07 - 17:37), which are
also normal events.
Here is the adjusted schedule:
[...]
This schedule maximizes the sum of weighted event durations while respecting all the rules provided.
</think>
<schedule>
<event>
<name>Analyzing product performance</name>
<start>04:33</start>
<end>06:03</end>
</event>
<event>
<name>One-on-one with manager</name>
<start>08:41</start>
<end>08:56</end>
</event>
<event>
<name>Client call with Acme Corp</name>
<start>09:13</start>
<end>10:14</end>
</event>
<event>
<name>Meeting with Lisa at café</name>
<start>10:14</start>
<end>11:14</end>
</event>
<event>
<name>Updating website content</name>
<start>12:21</start>
<end>13:36</end>
</event>
<event>
<name>Preparing PTO handover</name>
<start>16:07</start>
<end>17:37</end>
</event>
<event>
<name>Marketing standup on Zoom</name>
<start>17:58</start>
<end>19:43</end>
</event>
<event>
<name>Brainstorming with Luke and Patrick</name>
<start>19:11</start>
<end>19:56</end>
</event>
</schedule>
在此阶段,模型显示出有希望的反思给定约束的能力,但它错误地更改了一些事件的时间以最大化花费的时间。
第973/1500步
<think>
To create an optimized schedule, I need to prioritize events based on provided weights and ensure
no overlaps. The priority events are "Analyzing product performance" and "Meeting with Lisa at
café". Let\'s evaluate the schedule step-by-step.
1. **Analyzing product performance (04:33 - 06:03)** - This is a priority event (weight = 2).
2. **One-on-one with manager (08:41 - 08:56)** - This is a normal event (weight = 1).
3. **Client call with Acme Corp (09:13 - 10:58)** - This is a normal event (weight = 1). It conflicts
with "Meeting with Lisa at café", which is also a priority event. Since "Meeting with Lisa at café"
has higher priority, we exclude this event.
4. **Meeting with Lisa at café (10:14 - 11:14)** - This is a priority event (weight = 2). However,
it conflicts with "Client call with Acme Corp" as discussed. We need to decide whether to exclude
this event or find another slot.
5. **Updating website content (12:21 - 13:36)** - This is a normal event (weight = 1).
6. **Preparing PTO handover (16:07 - 17:37)** - This is a normal event (weight = 1).
7. **Marketing standup on Zoom (17:58 - 19:43)** - This is a normal event (weight = 1). It conflicts
with "Preparing PTO handover" as they overlap. We need to decide whether to exclude one of them.
8. **Brainstorming with Luke and Patrick (19:11 - 19:56)** - This is a normal event (weight = 1).
It conflicts with "Marketing standup on Zoom" as they overlap. We need to decide whether to exclude
one of them.
To maximize the sum of weighted event durations, we should exclude conflicts with the highest priority
events first.
- Exclude "Client call with Acme Corp" since it conflicts with "Meeting with Lisa at café"
(higher priority).
- Exclude "Marketing standup on Zoom" since it conflicts with "Preparing PTO handover" and does not
interfere with any higher priority events.
Thus, the optimized schedule is as follows:
</think>
<schedule>
<event>
<name>Analyzing product performance</name>
<start>04:33</start>
<end>06:03</end>
</event>
<event>
<name>One-on-one with manager</name>
<start>08:41</start>
<end>08:56</end>
</event>
<event>
<name>Updating website content</name>
<start>12:21</start>
<end>13:36</end>
</event>
<event>
<name>Preparing PTO handover</name>
<start>16:07</start>
<end>17:37</end>
</event>
<event>
<name>Brainstorming with Luke and Patrick</name>
<start>19:11</start>
<end>19:56</end>
</event>
</schedule>
好多了!在这里,模型明确地考虑了权重并生成了一个有效的日程安排。
第1470/1500步
<think>
The goal is to create a schedule that maximizes the sum of weighted event durations while respecting
the chronological order, priorities, and non-overlapping constraints. Let\'s analyze the events and
prioritize them:
1. **Analyzing product performance**: Start time: 04:33, End time: 06:03, Priority: 2
2. **One-on-one with manager**: Start time: 08:41, End time: 08:56, Priority: 1
3. **Client call with Acme Corp**: Start time: 09:13, End time: 10:58, Priority: 1
4. **Meeting with Lisa at café**: Start time: 10:14, End time: 11:14, Priority: 2
5. **Updating website content**: Start time: 12:21, End time: 13:36, Priority: 1
6. **Preparing PTO handover**: Start time: 16:07, End time: 17:37, Priority: 1
7. **Marketing standup on Zoom**: Start time: 17:58, End time: 19:43, Priority: 1
8. **Brainstorming with Luke and Patrick**: Start time: 19:11, End time: 19:56, Priority: 1
Given the priorities, we must ensure that "Analyzing product performance" and "Meeting with Lisa
at café" are included. Let\'s try to fit the rest while avoiding overlaps:
1. **Analyzing product performance**: 04:33 - 06:03 (Priority 2)
2. **One-on-one with manager**: 08:41 - 08:56 (Priority 1)
3. **Client call with Acme Corp**: 09:13 - 10:58 (Priority 1)
4. **Meeting with Lisa at café**: 10:14 - 11:14 (Priority 2)
5. **Updating website content**: 12:21 - 13:36 (Priority 1)
6. **Preparing PTO handover**: 16:07 - 17:37 (Priority 1)
The next event, "Marketing standup on Zoom", starts at 17:58, but the availability is only until
19:43. We can fit "Brainstorming with Luke and Patrick" from 19:11 to 19:56 before the standup.
1. **Analyzing product performance**: 04:33 - 06:03 (Priority 2)
2. **One-on-one with manager**: 08:41 - 08:56 (Priority 1)
3. **Client call with Acme Corp**: 09:13 - 10:58 (Priority 1)
4. **Meeting with Lisa at café**: 10:14 - 11:14 (Priority 2)
5. **Updating website content**: 12:21 - 13:36 (Priority 1)
6. **Preparing PTO handover**: 16:07 - 17:37 (Priority 1)
7. **Brainstorming with Luke and Patrick**: 19:11 - 19:56 (Priority 1)
Final schedule:
- Analyzing product performance: 04:33 - 06:03
- One-on-one with manager: 08:41 - 08:56
- Client call with Acme Corp: 09:13 - 10:58
- Meeting with Lisa at café: 10:14 - 11:14
- Updating website content: 12:21 - 13:36
- Preparing PTO handover: 16:07 - 17:37
- Brainstorming with Luke and Patrick: 19:11 - 19:56
This schedule respects the chronological order, includes the high-priority events, and avoids
any overlaps.
</think>
<schedule>
<event>
<name>Analyzing product performance</name>
<start>04:33</start>
<end>06:03</end>
</event>
<event>
<name>One-on-one with manager</name>
<start>08:41</start>
<end>08:56</end>
</event>
<event>
<name>Client call with Acme Corp</name>
<start>09:13</start>
<end>10:58</end>
</event>
<event>
<name>Meeting with Lisa at café</name>
<start>10:14</start>
<end>11:14</end>
</event>
<event>
<name>Updating website content</name>
<start>12:21</start>
<end>13:36</end>
</event>
<event>
<name>Preparing PTO handover</name>
<start>16:07</start>
<end>17:37</end>
</event>
<event>
<name>Brainstorming with Luke and Patrick</name>
<start>19:11</start>
<end>19:56</end>
</event>
</schedule>
有意思……在这个样本中,尽管推理过程很长,模型在最终的日程中还是安排了两个重叠事件。
查看样本固然不错,但我们需要系统性评估。
那“顿悟时刻”呢?
在DeepSeek-R1 论文中,作者展示了在使用 GRPO 训练过程中“顿悟时刻”的出现,即“模型学会了用拟人化的语气重新思考”。
这是他们模型和 GRPO 的卖点之一,这促使从业者在训练期间寻找/重现这种行为。
最近的研究(1;2)对此提出了一些质疑。他们发现类似的“顿悟时刻”在任何 GRPO 训练开始之前就可以在基础模型中找到。
基于这些令人信服的理由,我没有花时间寻找“顿悟时刻”。
不过,我发现关于这个主题的研究非常有趣,尤其是区分从基础模型中引出预先存在的行为与教授全新行为的努力。
评估
为了评估,我们可以使用 我们的事件调度数据集 的测试集,这是我们的模型从未见过的。
我们将评估阶段分为两步:
- 推理:为每个测试提示生成一个日程表。
- 评分:根据我们的规则检查每个生成的日程表(格式正确,事件数量 ≥ 2,仅包含现有事件,按时间顺序,无重叠)。如果任何规则被违反,该日程表在该提示下得分为 0。如果有效,其得分为 `(加权持续时间/最佳加权持续时间) * 100`。
您可以在GitHub 仓库中找到这些脚本。
❌ Unsloth bug 在推理过程中,我遇到了一个问题。使用 Unsloth 训练的模型无法可靠地转换为标准 Hugging Face Transformers 模型;尝试这样做可能会得到一个不同的模型。这是一个已知问题。如果我需要将其用于生产工作,例如,用 vLLM 提供服务,这将是一个主要的障碍,并且令人非常沮丧。对于此实验,我只是使用 Unsloth 运行了评估推理。
由于Unsloth修补了TRL,因此很容易调整代码并使用TRL,后者更稳定。只需注意您将需要更多的GPU显存。
我想比较 qwen-scheduler-7b-grpo(我们的模型)、Qwen2.5-Coder-7B-Instruct(原始模型)和 Qwen2.5-Coder-14B-Instruct(同一系列中更大的模型)。
由于样本显示模型在第 2 个 epoch 和第 3 个 epoch 之间可能变差了,我还评估了第 2 个 epoch 结束时的检查点。
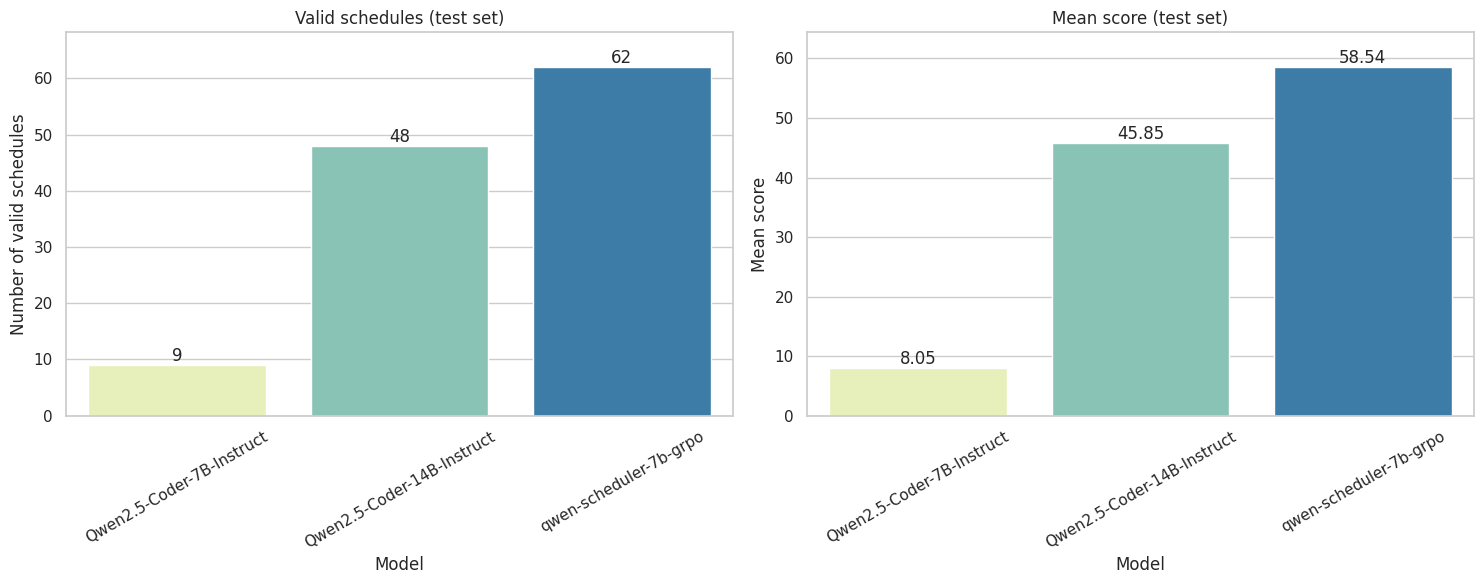
| 模型 | 格式错误 | 少于2个事件 | 重叠 | 未排序 | 不存在的 | 有效日程 | 平均分数 |
|---|---|---|---|---|---|---|---|
| Qwen2.5-Coder-7B-Instruct | 3 | 1 | 31 | 29 | 27 | 9 | 8.05 |
| Qwen2.5-Coder-14B-Instruct | 1 | 1 | 38 | 6 | 6 | 48 | 45.85 |
| qwen-scheduler-7b-grpo | 0 | 0 | 36 | 0 | 1 | 62 | 58.54 |
| qwen-scheduler-7b-grpo(第二代) | 0 | 0 | 30 | 2 | 1 | 67 | 62.25 |
快速观察
- GRPO 确实有效!它在从模型中引导出所需行为方面非常有效。
- 我们调优过的模型甚至在这个任务中超越了其两倍大小的模型。
- 模型几乎完美地学习了格式、时间顺序和只使用现有事件。
- 模型仍然在处理重叠方面遇到困难,这在测试集中相当一部分样本中表现出来。
如何改进?
我花在这个项目上的时间和计算资源都用完了,但以下是我接下来会尝试改进模型的方法。
主要问题肯定是重叠。我们看到模型未能有效地学会避免重叠。此外,第三个 Epoch 中性能的轻微下降可能表明模型正在学习次优策略。
奖励函数的想法:
- 更强的重叠惩罚:在`score_reward`函数中,我们从分数计算中移除了重叠事件。我们可以实施更严厉的惩罚……
- 专用重叠奖励:或者,添加一个只检查重叠的奖励函数。
我们还要记住,奖励函数默认是相加的,因此根据我们如何设计惩罚,这两种不同的方法在数学上可能是等价的。
结论和主要收获
在本文中,我们逐步介绍了如何使用 GRPO 对语言模型进行后训练,以完成一项新的可验证任务:从事件和优先级列表中创建日程安排。
我们涵盖了问题定义、数据集生成、基础模型选择、奖励函数设计、使用 Unsloth 进行训练和评估。
亲身实践让我学到了很多关于 GRPO 和将强化学习应用于 LLM 的知识。
GRPO 在可验证任务方面表现出色。
它简化了典型的强化学习设置(例如在 PPO 中使用):没有价值模型;奖励模型通常被确定性奖励函数取代(可验证奖励强化学习)。由于您的数据集只需要提示(不需要完成),因此数据收集比 SFT 变得更容易和更便宜。
启发
使用 GRPO 及类似算法更多的是从训练模型中引发期望行为,而不是向其教授全新的东西。如果您需要根本性的新技能,指令微调(和蒸馏)可能更有效(强化学习是否真的能激励 LLM 超越基础模型的推理能力?)。如果您对这些话题感兴趣,请关注 Nathan Lambert 和 Interconnects 博客。
基础模型很重要
如果基础模型在采样期间从未在任务上表现出有希望的行为,那么 GRPO 可能对您的问题无效。您可能首先需要一个更大或更好的基础模型。
“顿悟时刻”可能被过分炒作了
在 DeepSeek-R1 论文中,作者展示了 GRPO 训练过程中出现的“顿悟时刻”,即“模型学会了用拟人化的语气重新思考”。这是奇迹吗?最近的研究表明,基础模型中也存在类似的行为。
奖励函数设计至关重要
您的奖励应捕捉您的目标,提供可学习的信号(对模型的鼓励),并且稳健。如果它们不够稳健,您可能会遇到**奖励作弊**:模型会找到捷径来最大化奖励,而实际上并未解决您最初设想的问题。又好又令人沮丧 😅
Unsloth:省 GPU 的利器,但需注意
如果你没有多少 GPU 或者处于实验阶段,Unsloth 会很有帮助。这些家伙在 GPU 效率方面做得令人印象深刻。然而,该库目前存在难以解决的 bug,这使得它不适合严肃的用例。如果你有 VRAM,TRL 更稳定。
如果您喜欢这篇文章,请随意在 Hugging Face 和 LinkedIn 上关注我。如果您发现任何错误或不准确之处,请随时联系我。
资源和参考文献
Qwen 调度器 GRPO
- GitHub 仓库:您可以在此处找到我用于此实验的所有代码。
- Hugging Face 集合:数据集和模型。
GRPO 论文与资源
实用资源




