TRL 文档
TRL - Transformer 强化学习
加入 Hugging Face 社区
并获得增强的文档体验
开始使用

TRL - Transformer 强化学习
TRL 是一个全栈库,我们提供了一套工具,用于通过监督式微调 (SFT)、组相对策略优化 (GRPO)、直接偏好优化 (DPO)、奖励建模等方法训练 Transformer 语言模型。该库已与 🤗 transformers 集成。
🎉 最新动态
✨ 支持 OpenAI GPT OSS:TRL 现在完全支持微调最新的 OpenAI GPT OSS 模型!请查看
您还可以在 TRL Hugging Face 组织中探索与 TRL 相关的模型、数据集和演示。
学习
在 🤗 smol 课程中学习使用 TRL 和其他库进行后训练。
内容
文档分为以下几个部分
- 入门:安装和快速入门指南。
- 概念指南:数据集格式、训练常见问题解答和理解日志。
- 操作指南:减少内存使用、加速训练、分布式训练等。
- 集成:DeepSpeed、Liger Kernel、PEFT 等。
- 示例:示例概览、社区教程等。
- API:训练器、工具等。
博客文章

发布于 2025 年 6 月 3 日
不让任何 GPU 掉队:通过在 TRL 中共置 vLLM 解锁效率

发布于 2025 年 5 月 25 日
🐯 Liger GRPO 与 TRL 的相遇

发布于 2025 年 1 月 28 日
Open-R1:DeepSeek-R1 的完全开源复现

发布于 2024 年 7 月 10 日
使用 TRL 对视觉语言模型进行偏好优化

发布于 2024 年 6 月 12 日
让 RL 重回 RLHF

发布于 2023 年 9 月 29 日
通过 TRL 使用 DDPO 微调 Stable Diffusion 模型

发布于 2023 年 8 月 8 日
使用 DPO 微调 Llama 2

发布于 2023 年 4 月 5 日
StackLLaMA:使用 RLHF 训练 LLaMA 的实践指南

发布于 2023 年 3 月 9 日
在 24GB 消费级 GPU 上使用 RLHF 微调 20B LLM
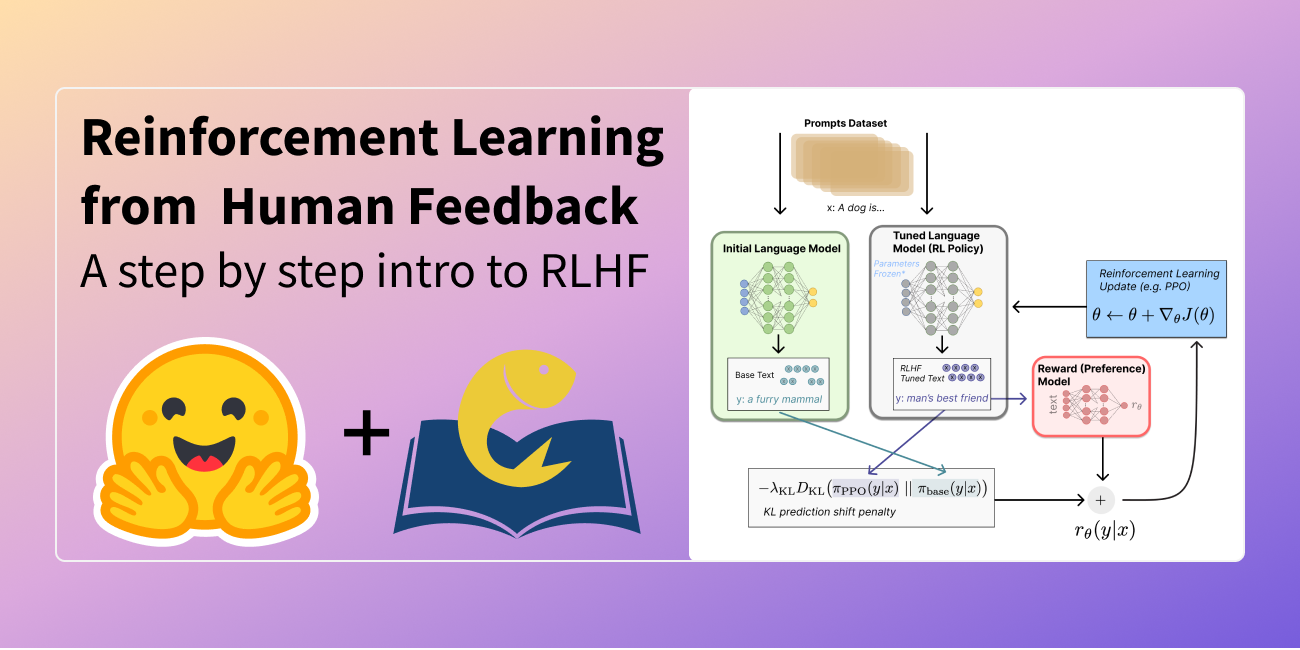
发布于 2022 年 12 月 9 日
图解人类反馈强化学习