用AI搜索网络





本文基于 PrAIvateSearch
v2.0-beta.0,这是一个隐私优先、AI 驱动、以用户为中心且数据安全的应用程序,旨在提供一个本地开源的替代方案,以取代像 SearchGPT 或 Perplexity AI 这样的大型 AI 搜索引擎。
1. 引言
在上一篇博客文章中,我们介绍了 PrAIvateSearch v1.0-beta.0,一个数据安全且隐私的 AI 驱动搜索引擎:尽管它是一个功能完善的解决方案,但仍然存在使其性能不佳的麻烦,具体来说:
- 从网络搜索结果中的 URL 抓取内容不可靠,有时无法产生正确的结果。
- 我们从基于网络的内容中提取了一系列关键词:然后将关键词格式化为 JSON 并作为上下文注入到用户提示中。尽管这是一种减轻提示负担的可行解决方案,但它只为 LLM 提供了部分上下文信息。
- 我们使用 RAG 进行上下文增强,但它通常效率低下,因为检索到的上下文直接传递到用户的提示中,使得推理计算密集且耗时。
- 我们的界面基础且简洁,缺乏其他网络应用程序的动态和现代流程。
- 从隐私角度来看,使用 Google Search API 搜索网络并非最佳选择。
因此,我们决定采用一种更简单直接的工作流程,如下图所示:
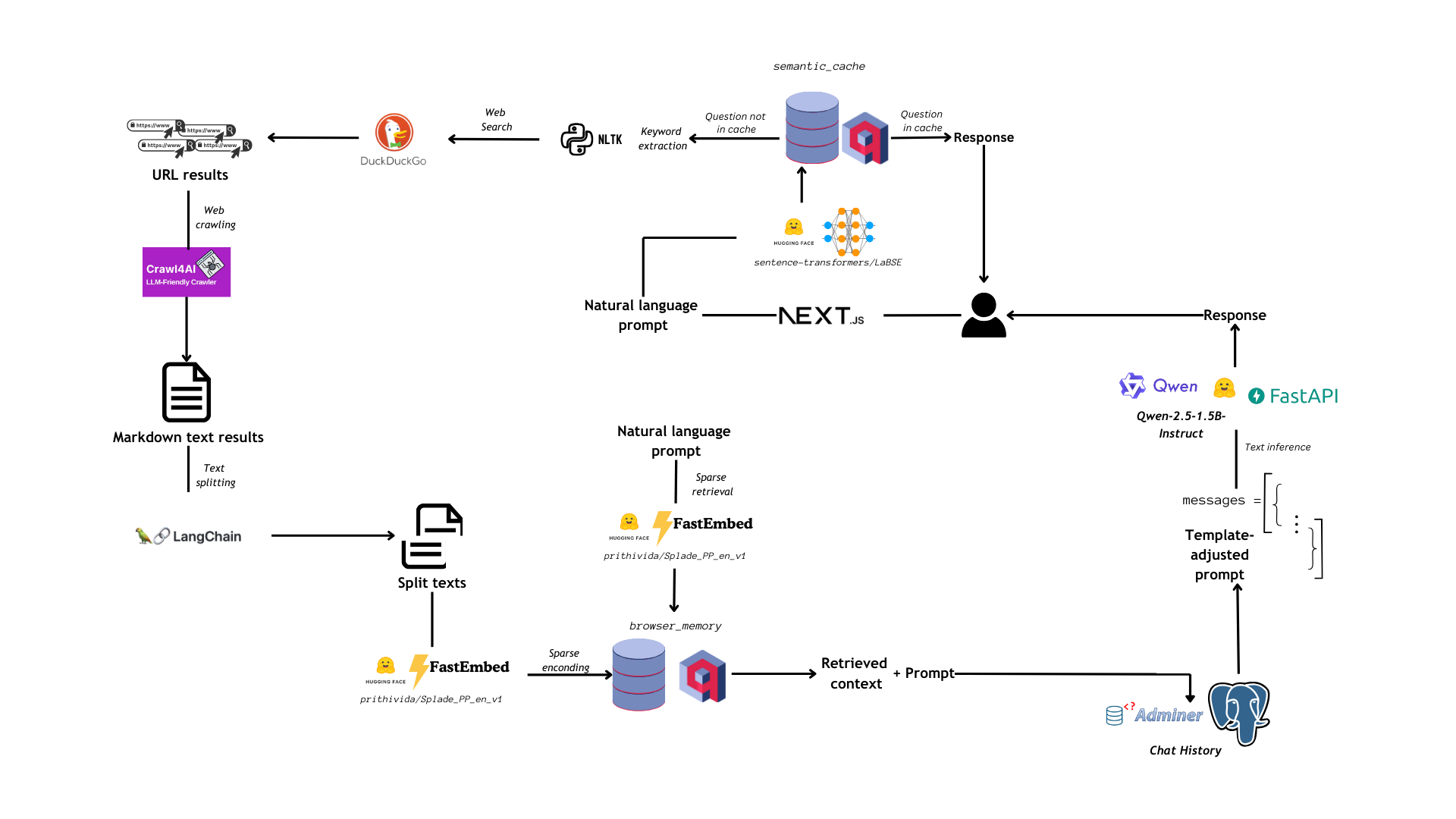
2. 构建模块
该应用程序由三个重要的构建模块组成:
- 一个动态的、类似聊天的用户界面,使用 NextJS 构建(通过 docker compose 启动)
- 第三方本地数据库服务:Postgres 和 Qdrant(通过 docker compose 启动)
- 一个 API 服务,使用 FastAPI 构建并由 Uvicorn 提供服务(在独立的 conda 环境中启动):此服务负责连接前端与后端第三方服务、网络搜索以及所有与查找用户查询答案相关的功能。
我们将逐一介绍这些构建模块,但首先让我们看看构建 PrAIvateSearch v2.0-beta.0 的先决条件和第一步。
2a. 第一步
要获取必要的代码并构建运行环境,您需要:
git工具集,用于从 GitHub 仓库获取代码conda包管理器,用于构建将启动 API 的环境docker和docker compose,用于提供用户界面和第三方本地数据库服务。
现在,要获取代码,您只需运行
git clone https://github.com/AstraBert/PrAIvateSearch.git
cd PrAIvateSearch
首先,将 .env.example 移动到 .env...
mv .env.example .env
...并指定 PostgreSQL 相关变量
# .env file
pgql_db="postgres"
pgql_user="localhost"
pgql_psw="
然后,您需要使用以下命令构建 API 环境:
# create the environment
conda env create -f conda_environment.yaml
# activate the environment
conda activate praivatesearch
# run crawl4ai post-installation setup
crawl4ai-setup
# run crawl4ai health checks
crawl4ai-doctor
# deactivate the environment
conda deactivate
最后,您将能够使用以下命令启动前端和数据库:
# The use of the -d option is not mandatory
docker compose up [-d]
3. 用户界面
用户界面现在基于 NextJS 实现,采用现代、动态的聊天界面。该界面受到 ChatGPT 启发,旨在为用户提供与使用 OpenAI 产品相似的体验。
每当用户通过发送消息与 UI 交互时,NextJS 应用程序后端会向 https://:8000/messages/ 发送 GET 请求,我们的 FastAPI/Uvicorn 管理的 API 在那里运行(见下文)。一旦请求得到满足,应用程序就会显示其返回的消息,即用户查询的答案。
NextJS 应用程序在 https://:3000 上运行,并通过 docker compose 启动。
4. 数据库服务
数据库服务通过 docker compose 在本地运行:它们完全由用户管理,并且可以轻松监控。这让用户可以完全控制应用程序内部的数据流。
4a. Qdrant
Qdrant 是一个向量数据库服务,在 PrAIvateSearch 中扮演着核心角色。借助 Qdrant,我们:
- 创建并管理一个语义缓存,其中存储用户已经问过的问题以及 LLM 给出的答案,以便在用户输入相同或类似问题时使用相同的答案。我们使用语义搜索来查找类似问题,并使用 75% 的相似度阈值来过滤掉不相关的结果:这就是为什么我们的缓存不仅仅是缓存,它还是语义的。
- 在网络搜索和爬取步骤中存储从网络抓取的内容:我们为此目的使用稀疏集合。然后,我们使用 Splade 执行稀疏检索,通过 FastEmbed(由 Qdrant 本身管理的 Python 库)加载:这第一步检索会在从网络抓取的内容数据库中为用户提示生成前 5 个最相关的命中。
Qdrant 可通过其完整且易于使用的界面在 https://:6333/dashboard 上进行监控。
4b. Postgres
Postgres 是一个关系型数据库,主要在此处用作聊天内存管理器。
借助基于 SQLAlchemy 的自定义客户端,我们可以将对话期间发送的所有消息加载到 messages 表中:此表的结构与我们为 LLM 设置的聊天模板兼容,因此在推理时检索聊天历史记录已经为语言模型提供了完整的先前发送消息数量。
Postgres 可以通过 Adminer 轻松监控,这是一个简单直观的数据库管理工具:您只需提供数据库类型 (PostgreSQL)、数据库名称、用户名和密码(这些变量将传递给 Docker,您可以在 您的 .env 文件中定义)。Adminer 也在本地运行,并通过 docker compose 提供服务:可在 https://:8080 访问。
5. API 服务
如前所述,我们借助 FastAPI 和 Uvicorn 构建了一个本地 API 服务,这两个工具直观易用,使 API 开发变得轻松。
API 端点位于 https://:8000/messages/,并接收来自 NextJS 应用程序的用户消息。从接收消息到返回响应的工作流程非常直接:
- 我们通过语义缓存检查用户的提示是否与已问过的问题相对应:此缓存基本上是一个密集的 Qdrant 集合,具有 LaBSE 生成的 768 维向量。如果语义缓存中有显著匹配,我们返回该匹配所使用的相同答案,否则我们继续处理请求。
- 如果用户的查询未从语义缓存中产生显著匹配,我们将使用 RAKE(快速自动关键词提取)算法从用户的自然语言提示中提取关键词。这些关键词将用于网络搜索。
- 我们通过 DuckDuckGo Search API 搜索网络:使用 DuckDuckGo 比利用 Google 更能确保网络冲浪的隐私。这是 PrAIvateSearch 努力确保用户数据安全,不被大型科技公司出于次要(并非总是透明)目的进行索引的一部分。
- 我们使用网络搜索返回的 URL 抓取内容:为此,我们使用 Crawl4AI 异步网络爬虫,并以 Markdown 格式返回所有抓取的内容。
- 我们使用 LangChain
MarkdownTextSplitter拆分上一步的 Markdown 文本:在此步骤之后,我们将得到 1000 个字符长度的文本块。 - 这些块使用 Splade 编码成稀疏向量,并上传到 Qdrant 稀疏集合。
- 我们使用用户的原始查询搜索稀疏集合,并检索前 5 个最相关的文档。
- 然后,这些 5 个相关文档会重新排名:我们使用 LaBSE 将相关文档编码成密集向量,并评估它们与向量化用户提示的余弦相似度。最相似的文档被检索作为上下文。
- 上下文作为用户消息传递,提示也紧随其后作为用户消息传递。在这种情况下,LLM 只需回复用户的提示,但可以通过聊天内存访问其基于网络的上下文。
- Qwen-2.5-1.5B-Instruct 对用户的提示执行推理并生成答案:然后该答案作为 API 的最终响应返回,并将显示在用户界面中。
6. 用法
6a. 使用说明
NextJS 应用程序已在 Ubuntu 22.04.3 机器上成功开发和测试,该机器配备 32GB RAM、22 核 CPU 和 Nvidia GEFORCE RTX4050 GPU(6GB,CUDA 版本 12.3),Python 版本为 3.11.11(由 conda 24.11.0 打包)。
尽管应用程序处于良好的开发阶段,但它仍处于 beta 版本,可能仍然包含错误,并存在操作系统/硬件/Python 版本不兼容的问题。
6b. 启动并运行 PrAIvateSearch
要启动并运行 PrAIvateSearch,您需要先执行 第一步。
一旦我们(在 PrAIVateSearch 文件夹中)通过此命令使用 docker compose 启动了数据库后端服务和前端应用程序,
docker compose up
我们可以前往我们在第一步中设置的 conda 环境,并启动 API
# activate the environment
conda activate praivatesearch
# head over to the qwen-on-api folder
cd qwen-on-api/
# launch the application
uvicorn main:app --host 0.0.0.0 --port 8000
加载应用程序开发中涉及的多个 AI 模型后,您将看到 API 已启动并准备好接收请求。
如果您想在通过前端发送请求之前测试 API,只需使用此 curl 命令:
curl "http://0.0.0.0:8000/messages/What%20is%20the%20capital%20of%20France"
如果一切顺利,您应该收到如下响应:
{"response": "The capital of France is **Paris**."}
就是这样!现在前往 https://:3000,开始使用 PrAIvateSearch 玩转吧!🪿
7. 结论
PrAIvateSearch 的目标是提供一个开源、隐私且数据安全的替代大型科技解决方案的产品。该应用程序仍处于测试阶段,因此,尽管其工作流程可能看似稳健,但仍可能存在小问题、未解决的错误和不精确之处。如果您想为项目做出贡献、报告问题并帮助发展 OSS AI 社区和环境,请随时在 GitHub 上这样做,并通过 资助 提供帮助。
谢谢!🤗