📄 Hugging Face 数据集查看器中的 PDF 支持
社区文章 发布于2025年6月25日



PDF 是一种常见的非结构化内容共享格式,包括法律文件、研究论文、数字化书籍和扫描报告。到目前为止,在 Hub 上使用基于 PDF 的数据集需要下载文件并依赖外部工具进行检查或处理。
Hugging Face 数据集查看器现已支持原生 PDF 渲染,允许用户直接在浏览器中预览和与文档交互。
🔧 新的查看器功能
- 缩略图预览:查看器现在会为每个 PDF 文件生成并显示缩略图(封面页)。

- 内联渲染:PDF 文件可以直接在查看器中打开和浏览,无需本地下载。

- 按模态可搜索:PDF 数据集可以通过 Hub 中的文档模态过滤器进行发现。
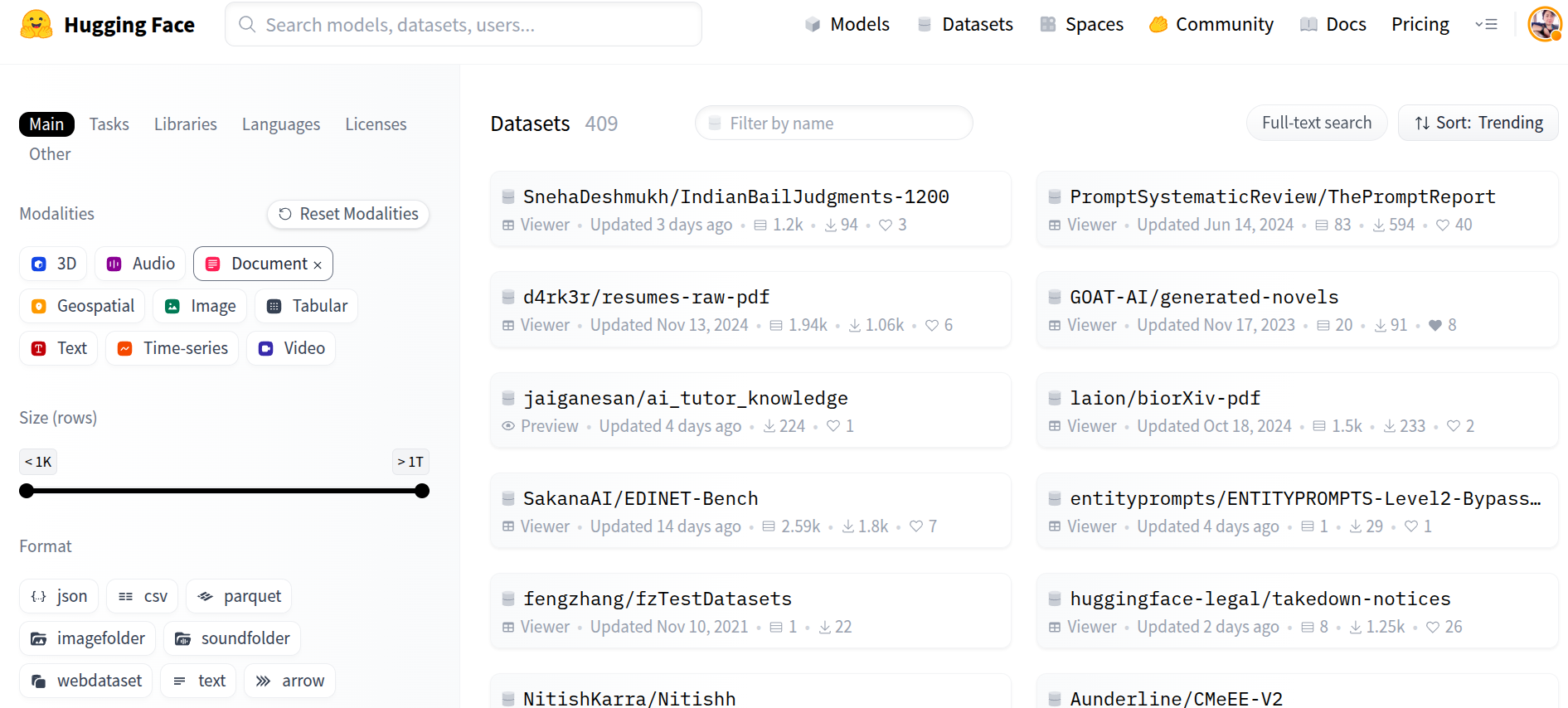
这些功能提高了透明度、可复现性和早期数据集检查的效率,尤其是在文档密集型领域。
🐍 使用 datasets 和 pdfplumber 进行程序化 PDF 处理
从 datasets 3.5.0 版本开始,PDF 内容可以使用 Pdf 特性加载为类型化对象。
每个条目都表示为一个 PdfDocument,支持:
- 页面级导航
- 文本提取
- 表格检测
- 嵌入图像访问
- 缩略图渲染
低级操作由 pdfplumber 提供支持,它在内部处理 PDF 解析。
▶️ 示例
from datasets import load_dataset
# Load a dataset with PDF files
dataset = load_dataset("GOAT-AI/generated-novels", split="train")
# Access the first PDF document
first_pdf = dataset['pdf'][0]
# Check total number of pages
print(f"Total pages: {len(first_pdf.pages)}")
# Generate a thumbnail image
cover_image = first_pdf.pages[0].to_image()
# Optionally save: cover_image.save("cover.png")
# Extract text from the second page
if len(first_pdf.pages) > 1:
page_text = first_pdf.pages[1].extract_text()
print("Page 2 text:", page_text)
✅ 结论
在数据集查看器和 datasets 库中支持 PDF 简化了基于文档的数据集的探索和程序化处理。这对于涉及法律文档、OCR 管道、大规模报告挖掘或研究论文分析的工作流程特别有用。
更多信息和工具: