在 🤗 Transformers 中使用 Wav2Vec2 处理大文件实现自动语音识别







Tl;dr: This post explains how to use the specificities of the Connectionist
Temporal Classification (CTC) architecture in order to achieve very good
quality automatic speech recognition (ASR) even on arbitrarily long files or
during live inference.
Wav2Vec2 是一种流行的预训练语音识别模型。该模型由 Meta AI Research 于 2020 年 9 月 发布,其新颖的架构推动了语音识别自监督预训练的进展,例如 G. Ng 等人,2021、Chen 等人,2021、Hsu 等人,2021 和 Babu 等人,2021。在 Hugging Face Hub 上,Wav2Vec2 最受欢迎的预训练检查点目前每月下载量超过 25 万次。
Wav2Vec2 本质上是一个 transformers 模型,而 transformers 的一个缺点是它通常只能处理有限的序列长度。这可能是因为它使用 位置编码(这里不是这种情况),或者仅仅是因为 transformers 中注意力的成本实际上是序列长度的 O(n²),这意味着使用非常大的序列长度会导致复杂性/内存爆炸。因此,你无法在有限的硬件(即使是像 A100 这样非常大的 GPU)上,直接对一小时长的文件运行 Wav2Vec2。你的程序会崩溃。让我们来试试看!
pip install transformers
from transformers import pipeline
# This will work on any of the thousands of models at
# https://huggingface.co/models?pipeline_tag=automatic-speech-recognition
pipe = pipeline(model="facebook/wav2vec2-base-960h")
# The Public Domain LibriVox file used for the test
#!wget https://ia902600.us.archive.org/8/items/thecantervilleghostversion_2_1501_librivox/thecantervilleghostversion2_01_wilde_128kb.mp3 -o very_long_file.mp3
pipe("very_long_file.mp3")
# Crash out of memory !
pipe("very_long_file.mp3", chunk_length_s=10)
# This works and prints a very long string !
# This whole blogpost will explain how to make things work
简单分块
在超长文件上进行推理的最简单方法是将原始音频简单地分块成更短的样本,比如说每个 10 秒,然后对这些样本进行推理,最后进行最终的重建。这种方法计算效率高,但通常会导致次优结果,原因是模型为了进行良好的推理需要一些上下文,所以在分块边界附近,推理质量往往较差。
请看下图:
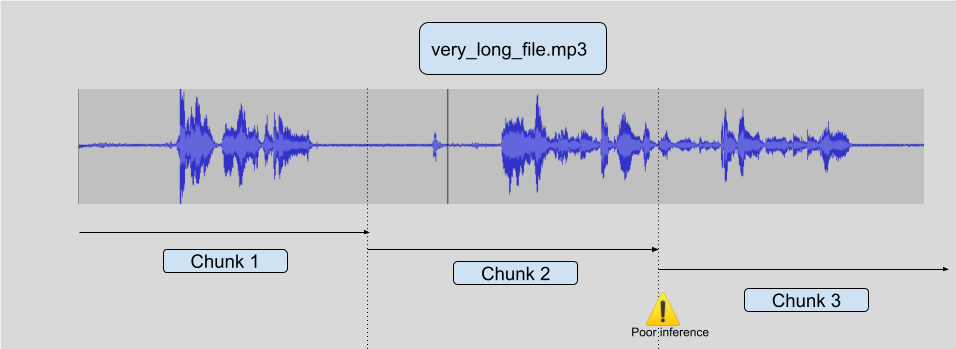
有一些方法可以尝试普遍解决这个问题,但它们从来都不是完全可靠的。你可以尝试只在遇到静音时进行分块,但你可能会长时间遇到非静音音频(一首歌,或嘈杂的咖啡馆音频)。你也可以尝试只在没有语音时进行切割,但这需要另一个模型,而且这不是一个完全解决的问题。你也可能会长时间持续发声。
事实证明,Wav2Vec2 所使用的 CTC 结构可以被利用,以实现在超长文件上也非常强大的语音识别,而不会陷入这些陷阱。
带步长的分块
Wav2Vec2 使用 CTC 算法,这意味着音频的每一帧都映射到一个字母预测(logit)。
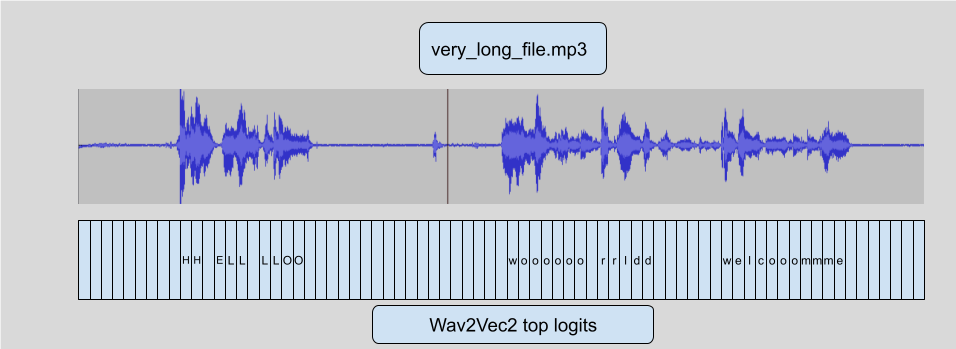
这是我们将用于添加 `stride` 的主要功能。这个 链接 在图像上下文中解释了它,但对于音频来说是相同的概念。由于这个特性,我们可以:
- 开始对**重叠**的块进行推理,以便模型在中心实际具有适当的上下文。
- **丢弃**侧面的推理 logits。
- 链接**logits**,不包含它们丢弃的侧面,以恢复与模型在完整长度音频上预测的结果极其相似的内容。

这在**技术上**与在整个文件上运行模型不完全相同,因此默认情况下未启用,但正如您在前面的示例中看到的,您只需在 `pipeline` 中添加 `chunk_length_s` 即可使其工作。
在实践中,我们观察到大多数不良推理都保留在步长内,这些步长在推理之前被丢弃,从而导致对完整文本的正确推理。
请注意,您可以选择此技术的所有参数
from transformers import pipeline
pipe = pipeline(model="facebook/wav2vec2-base-960h")
# stride_length_s is a tuple of the left and right stride length.
# With only 1 number, both sides get the same stride, by default
# the stride_length on one side is 1/6th of the chunk_length_s
output = pipe("very_long_file.mp3", chunk_length_s=10, stride_length_s=(4, 2))
在 LM 增强模型上带步长的分块
在 transformers 中,我们还增加了对 Wav2Vec2 添加 LM 的支持,以在不进行微调的情况下提高模型的 WER 性能。请参阅这篇出色的博客文章,了解其工作原理。
事实证明,LM 直接作用于 logits 本身,因此我们可以不加任何修改地应用与之前完全相同的技术!因此,在这些 LM 增强模型上对大文件进行分块仍然可以直接使用。
实时推理
使用 Wav2vec2 这样的 CTC 模型有一个非常好的优点,那就是它是一个单程模型,所以速度**非常**快。尤其是在 GPU 上。我们可以利用这一点进行实时推理。
原理与常规步进完全相同,但这次我们可以**在数据传入时**将数据馈送到管道,并简单地对长度为 10 秒的完整块使用步进,例如 1 秒的步进,以获得适当的上下文。
这需要比简单的文件分块运行更多的推理步骤,但它可以大大改善实时体验,因为模型可以在您说话时打印内容,而无需等待 X 秒才能看到显示内容。