在现代CPU上扩展BERT类模型推理——第一部分




1. 背景与动机
早在2019年10月,我的同事Lysandre Debut发布了一篇全面的(当时)推理性能基准测试博客 (1)。
自那时起,🤗 Transformers (2) 迎来了大量新架构,数千个新模型被添加到 🤗 Hub (3),截至2021年第一季度,模型数量已超过9,000个。
随着NLP领域越来越多地使用BERT类模型进行生产部署,高效地部署和运行这些架构仍然充满挑战。
这就是我们最近推出🤗 推理API的原因:让您专注于为用户和客户创造价值,而不是深究运行这些模型的所有高度技术性细节。
这篇博客文章是系列文章的第一部分,将涵盖大部分硬件和软件优化,以更好地利用CPU进行BERT模型推理。
在这篇初始博客文章中,我们将涵盖硬件部分:
- 设置基线——开箱即用结果
- 利用现代CPU处理CPU密集型任务时的实际和技术考量
- 核心数扩展——增加核心数是否真的能带来更好的性能?
- 批量大小扩展——通过多个并行独立模型实例提高吞吐量
我们决定专注于最著名的Transformer模型架构,BERT (Delvin & al. 2018) (4)。虽然本博客文章主要关注BERT类模型以保持文章简洁,但所有描述的技术都适用于Hugging Face模型中心上的任何架构。
在这篇博客文章中,我们不会详细描述Transformer架构——如果您想了解这方面的内容,我强烈推荐Jay Alammar的《图解Transformer》博客文章 (5)。
今天的目标是让您了解从开源角度来看,在PyTorch和TensorFlow上使用BERT类模型进行推理的现状,以及您可以轻松利用哪些方法来加速推理。
2. 基准测试方法
当涉及到利用Hugging Face模型中心的BERT类模型时,有许多参数可以调整以加快速度。
此外,为了量化“更快”的含义,我们将依赖广泛采用的指标:
- 延迟:模型单次执行(即前向调用)所需的时间
- 吞吐量:在固定时间内执行的次数
这两个指标将帮助我们理解这篇博客文章中讨论的优点和权衡。
基准测试方法已从头开始重新实现,以便集成transformers提供的最新功能,并让社区以**希望能更简单的方式**运行和共享基准测试。
整个框架现在基于Facebook AI & Research的Hydra配置库,使我们能够轻松报告和跟踪运行基准测试所涉及的所有项目,从而提高整体可复现性。
您可以在此处找到项目的整体结构
在2021年版本中,我们保留了通过PyTorch和TensorFlow运行推理工作负载的能力,就像之前的博客(1)中那样,同时支持它们的追踪对应物TorchScript (6)和Google加速线性代数 (XLA) (7)。
此外,我们决定支持ONNX Runtime (8),因为它提供了许多专门针对基于Transformer模型的优化,这使其成为在讨论性能时需要考虑的强有力候选。
最后但同样重要的是,这个新的统一基准测试环境将允许我们轻松地运行不同场景下的推理,例如使用精度较低的数字表示(float16, int8, int4)的量化模型 (Zafrir & al.) (9)。
这种被称为**量化**的方法在所有主要硬件供应商中得到了越来越多的采用。在不久的将来,我们希望集成Hugging Face正在积极研究的其他方法,即蒸馏、剪枝和稀疏化。
3. 基线
以下所有结果均在Amazon Web Services (AWS) c5.metal 实例上运行,该实例使用Intel Xeon Platinum 8275 CPU(48核心/96线程)。选择此实例可提供所有有用的CPU功能,以加速深度学习工作负载,例如:
- AVX512指令集(可能不会被各种框架开箱即用)
- Intel深度学习加速(也称为向量神经网络指令——VNNI),它为运行量化网络(使用int8数据类型)提供专用CPU指令
选择使用metal实例是为了避免使用云提供商时可能出现的任何虚拟化问题。这使我们能够完全控制硬件,特别是在针对NUMA(非统一内存访问架构)控制器时,我们将在本文后面介绍这一点。
操作系统是Ubuntu 20.04 (LTS),所有实验均使用Hugging Face transformers 4.5.0版本、PyTorch 1.8.1和Google TensorFlow 2.4.0进行。
4. 开箱即用结果


直截了当地说,在所有测试配置中,PyTorch 在推理结果上均优于 TensorFlow。
需要注意的是,开箱即用的结果可能无法反映 PyTorch 和 TensorFlow 的“最优”设置,因此此处看起来可能具有误导性。
解释这两种框架之间差异的一种可能方式是执行操作符内部并行部分的底层技术。
PyTorch内部使用OpenMP (10)以及Intel MKL (现在是oneDNN) (11)进行高效的线性代数计算,而TensorFlow则依赖于Eigen和其自己的线程实现。
5. 扩展BERT推理以提高现代CPU的整体吞吐量
5.1. 简介
有多种方法可以提高BERT推理等任务的延迟和吞吐量。改进和调整可以在各个层面进行,从启用操作系统功能、将依赖库替换为性能更好的库、仔细调整框架属性,到最后但同样重要的是,利用CPU上的所有核心进行并行化逻辑。
在这篇博客文章的剩余部分,我们将专注于后者,也称为**多推理流**。
这个想法很简单:分配**同一个模型的多个实例**,并将每个实例的执行分配给**专门的、不重叠的CPU核心子集**,以实现真正的并行实例。
5.2. 现代CPU上的核心和线程
在优化CPU推理以更好地利用CPU核心的过程中,您可能已经看到——至少在过去20年中——现代CPU规格报告“核心”和“硬件线程”或“物理”和“逻辑”数字。这些概念指的是一种称为**同步多线程**(SMT)或英特尔平台上的**超线程**机制。
为了说明这一点,假设有两个任务**A**和**B**并行执行,每个任务都在自己的软件线程上。
在某个时候,这两个任务很有可能不得不等待从主内存、SSD、HDD甚至网络中获取一些资源。
如果线程调度在不同的物理核心上,并且没有超线程,那么在这些期间,执行任务的核心处于**空闲**状态,等待资源到来,实际上什么也没做......因此没有得到充分利用
现在,有了**SMT**,**任务A和B的两个软件线程**可以被调度在同一个**物理核心**上,这样它们的执行就在该物理核心上交错进行。
任务A和任务B将在物理核心上同时执行,当一个任务暂停时,另一个任务仍然可以在核心上继续执行,从而提高该核心的利用率。
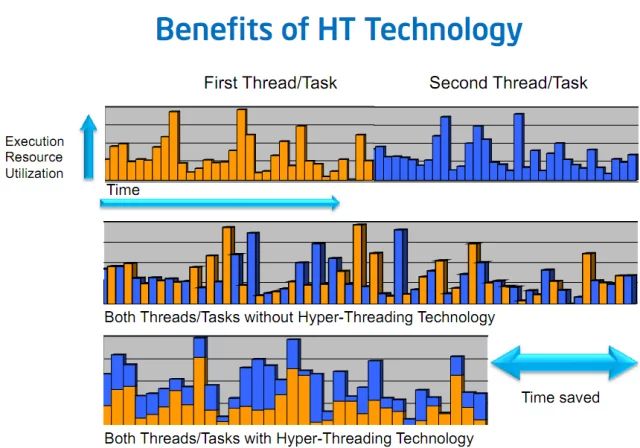
上图 3 简化了情况,假设是单核设置。如果您想了解更多关于 SMT 在多核 CPU 上如何工作的详细信息,请参阅以下两篇对该行为进行非常深入技术解释的文章:
回到我们的模型推理工作负载……如果你仔细思考,在一个完美优化的世界里,计算占据了大部分时间。
在这种情况下,使用逻辑核心不应该给我们带来任何性能优势,因为两个逻辑核心(硬件线程)都会争夺核心的执行资源。
结果,这些任务主要是通用矩阵乘法(gemms (14)),它们本质上是CPU密集型任务,因此**无法**从SMT中受益。
5.3. 利用多插槽服务器和CPU亲和性
如今的服务器拥有许多核心,其中一些甚至支持多插槽设置(即主板上有多个CPU)。
在Linux上,lscpu命令报告系统中所有CPU的规格和拓扑结构
ubuntu@some-ec2-machine:~$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 96
On-line CPU(s) list: 0-95
Thread(s) per core: 2
Core(s) per socket: 24
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Platinum 8275CL CPU @ 3.00GHz
Stepping: 7
CPU MHz: 1200.577
CPU max MHz: 3900.0000
CPU min MHz: 1200.0000
BogoMIPS: 6000.00
Virtualization: VT-x
L1d cache: 1.5 MiB
L1i cache: 1.5 MiB
L2 cache: 48 MiB
L3 cache: 71.5 MiB
NUMA node0 CPU(s): 0-23,48-71
NUMA node1 CPU(s): 24-47,72-95
在我们的例子中,我们有一台机器,它有**2个插槽**,每个插槽提供**24个物理核心**,每个核心有**2个线程**(SMT)。
另一个有趣的特性是**NUMA**节点(0, 1)的概念,它表示核心和内存如何在系统中映射。
非统一内存访问 (NUMA) 是统一内存访问 (UMA) 的对立面,在 UMA 中,整个内存池通过插槽和主内存之间的一条单一统一总线供所有核心访问。而 NUMA 则将内存池分割,每个 CPU 插槽负责寻址一部分内存,从而减少总线上的拥堵。
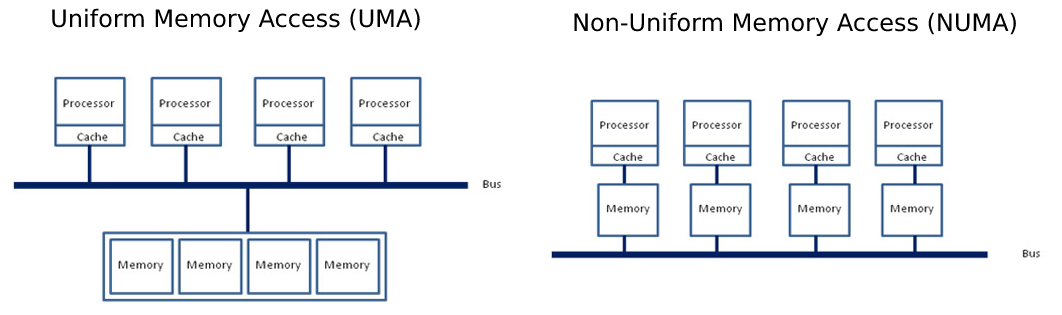
为了充分利用这种强大机器的潜力,我们需要确保我们的模型实例正确地分配到所有插槽上的所有**物理**核心,并强制内存分配“NUMA感知”。
在 Linux 中,NUMA 的进程配置可以通过 numactl 进行调整,它提供了一个接口来将进程绑定到一组 CPU 核心(称为**线程亲和性**)。
此外,它还允许调整内存分配策略,确保为进程分配的内存尽可能靠近核心的内存池(称为**显式内存分配指令**)。
注意:设置核心和内存亲和性在这里都很重要。如果计算在插槽0上进行,而内存分配在插槽1上,系统将需要通过插槽共享总线进行内存交换,从而导致不必要的开销。
5.4. 调整线程亲和性与内存分配策略
现在我们已经掌握了控制模型实例资源分配所需的所有参数,我们将进一步探讨如何有效地部署它们,并观察其对延迟和吞吐量的影响。
让我们逐步进行,以了解每个命令和参数的影响。
首先,我们不进行任何调整就启动推理模型,并观察计算如何在CPU核心上分配(左侧)。
python3 src/main.py model=bert-base-cased backend.name=pytorch batch_size=1 sequence_length=128
然后,我们通过 numactl 指定核心和内存亲和性,使用所有**物理**核心,每个核心只使用一个线程(线程0)(右侧)。
numactl -C 0-47 -m 0,1 python3 src/main.py model=bert-base-cased backend.name=pytorch batch_size=1 sequence_length=128

如您所见,在没有任何特定调整的情况下,PyTorch和TensorFlow将工作分配到单个插槽上,使用该插槽中的所有逻辑核心(24个核心上的两个线程)。
此外,正如我们前面强调的,在我们的例子中,我们不希望利用**SMT**功能,因此我们将进程的线程亲和性设置为仅 targeting 1 个硬件线程。
请注意,这仅适用于本次运行,并且可能因个人设置而异。因此,建议针对每个具体用例检查线程亲和性设置。
让我们花点时间来强调一下我们用 numactl 做了什么
-C 0-47指示numactl线程亲和性(核心 0 到 47)。-m 0,1指示numactl在两个CPU插槽上分配内存
如果您想知道我们为什么要将进程绑定到核心 [0...47],您需要回到 lscpu 的输出。
从那里您会找到 NUMA node0 和 NUMA node1 部分,其形式为 NUMA node<X> <logical ids>
在我们的例子中,每个插槽是一个NUMA节点,共有2个NUMA节点。每个插槽或每个NUMA节点有24个物理核心,每个核心有2个硬件线程,因此有48个逻辑核心。对于NUMA节点0,0-23是插槽0中24个物理核心上的硬件线程0,24-47是硬件线程1。同样,对于NUMA节点1,48-71是插槽1中24个物理核心上的硬件线程0,72-95是硬件线程1。
正如我们前面解释的,由于我们每个物理核心只针对1个线程,因此我们只选择每个核心上的线程0,即逻辑处理器0-47。由于我们使用两个插槽,因此还需要相应地绑定内存分配(0,1)。
请注意,使用两个插槽可能并非总是能获得最佳结果,特别是对于小问题规模。跨插槽使用计算资源的优势可能会因跨插槽通信开销而降低甚至抵消。
6. 核心数扩展——使用更多核心是否真的能提高性能?
当考虑提高模型推理性能的可能方法时,第一个合理的解决方案可能是投入更多资源来完成相同的工作量。
在本博客系列的其余部分,我们将把这种设置称为**核心数扩展**,这意味着只有用于完成任务的系统核心数会发生变化。这在HPC领域通常也称为强扩展。
在此阶段,您可能想知道为什么要仅分配部分核心,而不是将所有资源都投入到任务中以实现最小延迟。
确实,根据问题规模,投入更多资源到任务中可能会带来更好的结果。对于小问题,投入更多CPU核心工作也可能不会改善最终延迟。
为了说明这一点,下面的图6展示了不同的问题大小(batch_size = 1, sequence length = {32, 128, 512}),并报告了PyTorch和TensorFlow在不同CPU核心数下运行计算的延迟。
限制参与计算的资源数量是通过限制参与**内部**操作(这里的**内部**指的是操作符内部进行计算,也称为“内核”)的CPU核心数量来实现的。
这可以通过以下API实现:
- PyTorch:
torch.set_num_threads(x) - TensorFlow:
tf.config.threading.set_intra_op_parallelism_threads(x)

如您所见,根据问题规模,参与计算的线程数对延迟测量有积极影响。
对于小规模和中等规模问题,只使用一个插槽将提供最佳性能。对于大规模问题,跨插槽通信的开销被计算成本所覆盖,因此受益于使用两个插槽上的所有可用核心。
7. 多流推理——并行使用多个实例
如果您仍在阅读本文,那么您现在应该能够很好地在 CPU 上设置并行推理工作负载了。
现在,我们将强调我们强大硬件提供的一些可能性,并通过调整之前描述的旋钮,尽可能线性地扩展我们的推理。
在下一节中,我们将探讨另一种可能的扩展解决方案**批量大小扩展**,但在深入探讨之前,让我们看看如何利用Linux工具来分配线程亲和性,从而实现有效的模型实例并行化。
与核心计数扩展设置中增加更多核心不同,现在我们将使用更多模型实例。每个实例将在其自己的硬件资源子集上独立运行,以真正的并行方式在CPU核心的子集上运行。
7.1. 如何分配多个独立实例
我们从简单的开始,如果我们想在每个插槽上生成2个实例,每个实例分配24个核心:
numactl -C 0-23 -m 0 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=128 backend.name=pytorch backend.num_threads=24
numactl -C 24-47 -m 1 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=128 backend.name=pytorch backend.num_threads=24
从这里开始,每个实例不与其他实例共享任何资源,并且从硬件角度来看,一切都以最高效率运行。
延迟测量与单个实例所能达到的结果相同,但吞吐量实际上高出2倍,因为这两个实例以真正的并行方式运行。
我们可以进一步增加实例数量,同时降低分配给每个实例的核心数量。
让我们运行4个独立实例,每个实例都有效地绑定到12个CPU核心。
numactl -C 0-11 -m 0 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=128 backend.name=pytorch backend.num_threads=12
numactl -C 12-23 -m 0 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=128 backend.name=pytorch backend.num_threads=12
numactl -C 24-35 -m 1 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=128 backend.name=pytorch backend.num_threads=12
numactl -C 36-47 -m 1 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=128 backend.name=pytorch backend.num_threads=12
结果保持不变,我们的4个实例有效地以真正的并行方式运行。
延迟会比上一个例子略高(使用的核心数减少2倍),但吞吐量将再次提高2倍。
7.2. 智能调度——为不同问题大小分配不同的模型实例
这种设置提供的另一种可能性是为各种问题大小精心调整多个实例。
通过智能调度方法,可以根据请求工作负载将传入请求重定向到提供最佳延迟的正确配置。
# Small-sized problems (sequence length <= 32) use only 8 cores (on socket 0 - 8/24 cores used)
numactl -C 0-7 -m 0 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=32 backend.name=pytorch backend.num_threads=8
# Medium-sized problems (32 > sequence <= 384) use remaining 16 cores (on socket 0 - (8+16)/24 cores used)
numactl -C 8-23 -m 0 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=128 backend.name=pytorch backend.num_threads=16
# Large sized problems (sequence >= 384) use the entire CPU (on socket 1 - 24/24 cores used)
numactl -C 24-37 -m 1 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=384 backend.name=pytorch backend.num_threads=24
8. 批量大小扩展——通过多个并行独立模型实例提高吞吐量和延迟
另一种非常有意思的扩展推理方向是:在池中放入更多模型实例,同时按比例减少每个实例实际接收的工作负载。
这种方法实际上改变了问题的大小(批量大小)和参与计算的资源(核心)。
为了说明这一点,想象你有一台拥有 C 个 CPU 核心的服务器,你想运行一个包含 B 个样本和 S 个令牌的工作负载。
您可以将此工作负载表示为形状为 [B, S] 的张量,其中 B 是批量大小,S 是 B 个样本中的最大序列长度。
对于所有实例(N),每个实例在 C / N 个核心上执行,并将接收任务的子集 [B / N, S]。
每个实例接收的不是全局批次,而是其子集 [B / N, S],因此得名**批量大小扩展**。
为了突出这种扩展方法的好处,下面的图表报告了在扩展模型实例时延迟和吞吐量的影响。
在查看结果时,让我们关注延迟和吞吐量方面:
一方面,我们取实例池中的最大延迟来反映处理批次中所有样本所需的时间。换句话说,由于实例以真正的并行方式运行,因此从所有实例中收集所有批次块所需的时间取决于池中单个实例完成其块所需的最长时间。
正如您在图7中看到的,随着实例数量的增加,实际的延迟增益确实取决于问题的大小。在所有情况下,我们都可以找到最优的资源分配(批量大小和实例数量)来最小化我们的延迟,但核心参与计算的数量没有特定的模式。
另外,需要注意的是,在其他系统(例如操作系统、内核版本、框架版本等)上,结果可能完全不同。
图8总结了旨在最小化延迟的最佳多实例配置,通过取所涉及实例数量的最小值。
例如,对于 {batch = 8, sequence length = 128},使用4个实例(每个实例 {batch = 2} 和12个核心)可获得最佳延迟测量结果。
图9报告了PyTorch和TensorFlow在各种问题规模下最小化延迟的所有设置。
**剧透**:在后续的博客文章中,我们将讨论许多其他优化,这些优化将显著影响此图表。


另一方面,我们将吞吐量视为所有并行执行模型实例的总和。它允许我们可视化系统在添加越来越多实例(每个实例资源更少但工作负载按比例分配)时的可扩展性。
在这里,结果显示出几乎线性的可伸缩性,从而实现了最佳的硬件利用率。

9. 结论
通过这篇博客文章,我们涵盖了PyTorch和TensorFlow开箱即用的BERT推理性能,这些性能是通过简单的PyPi安装,且无需进一步调整即可获得的。
需要强调的是,这里提供的数据反映了开箱即用的框架设置,因此可能无法提供绝对最佳的性能。
我们决定不在本博客文章中包含优化,以专注于硬件和效率。优化将在第二部分讨论!🚀
然后,我们涵盖并详细阐述了设置线程亲和性的影响和重要性,以及目标问题规模与完成任务所需核心数量之间的权衡。
此外,重要的是要定义优化部署时使用**哪些标准**(即延迟与吞吐量),因为由此产生的设置可能完全不同。
更普遍地说,小问题(短序列和/或小批量)可能需要更少的核心来获得最佳延迟,而大问题(非常长的序列和/或大批量)则需要更多核心。
在考虑最终部署平台时,涵盖所有这些方面是很有趣的,因为它可以大幅削减基础设施成本。
例如,我们这台48核机器每小时收费**4.848美元**,而一台只有8核的小型实例则将成本降至**0.808美元/小时**,从而实现**6倍的成本降低**。
最后但同样重要的是,本博客文章中讨论的许多参数都可以通过一个启动脚本自动调整,该脚本深受英特尔最初编写并可在此处获得的脚本的启发。
启动脚本能够自动启动您的Python进程,并设置正确的线程亲和性,有效地在实例之间分配资源,以及许多其他性能提示!我们将在第二部分详细介绍许多这些提示🧐。
在后续的博客文章中,将涉及更高级的设置和调整技术,以进一步降低模型延迟,例如:
- 启动脚本演练
- 调整内存分配库
- 使用Linux的透明巨页机制
- 使用供应商特定的数学/并行库
敬请期待!🤗
致谢
- Omry Yadan (Facebook FAIR) - OmegaConf & Hydra 的作者,感谢他提供正确设置 Hydra 的所有提示。
- 所有英特尔和英特尔实验室的自然语言处理同事们——感谢他们对transformers以及更广泛的自然语言处理领域所做的持续优化和研究努力。
- Hugging Face 的同事们——感谢他们在评审过程中提供的所有评论和改进。
参考文献
- Transformer基准测试:PyTorch与TensorFlow
- HuggingFace的Transformers:最先进的自然语言处理
- HuggingFace的模型中心
- BERT - 用于语言理解的深度双向Transformer预训练 (Devlin & al. 2018)
- Jay Alammar的图解Transformer博客文章
- PyTorch - TorchScript
- Google加速线性代数 (XLA)
- ONNX Runtime - 优化和加速机器学习推理和训练
- Q8BERT - 量化8位BERT (Zafrir & al. 2019)
- OpenMP
- Intel oneDNN
- 英特尔® 超线程技术——技术用户指南
- 超线程技术简介
- BLAS (基础线性代数子程序) - 维基百科
- 优化NUMA应用程序

