在Hugging Face上推出决策Transformer 🤗








在Hugging Face,我们正在为深度强化学习的研究人员和爱好者做出贡献。最近,我们集成了深度强化学习框架,例如 Stable-Baselines3。
今天我们很高兴地宣布,我们将离线强化学习方法 决策Transformer 集成到 🤗 transformers 库和 Hugging Face Hub 中。我们有一些激动人心的计划,旨在提高深度强化学习领域的可访问性,我们期待在未来几周和几个月内与大家分享这些计划。
什么是离线强化学习?
深度强化学习(RL)是一个用于构建决策代理的框架。这些代理旨在通过试错与环境互动,并接收奖励作为独特反馈来学习最优行为(策略)。
代理的目标是最大化其**累积奖励,称为回报。**因为强化学习是基于奖励假设的:**所有目标都可以描述为最大化预期累积奖励。**
深度强化学习代理**通过批次经验学习。**问题是,它们如何收集经验?
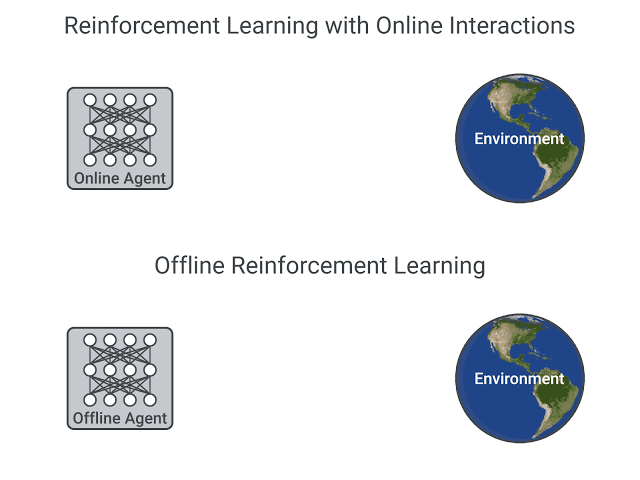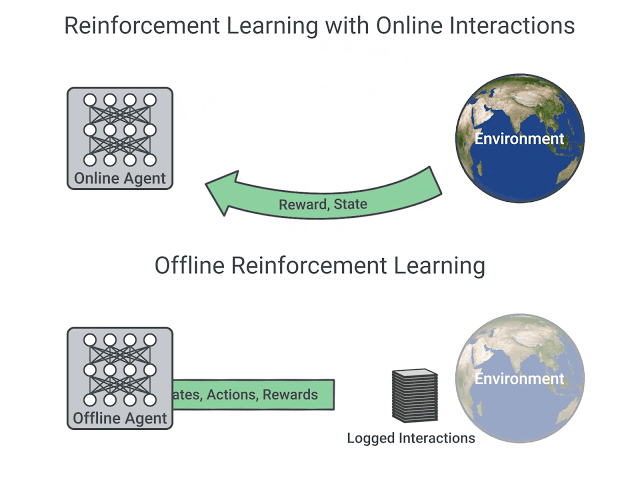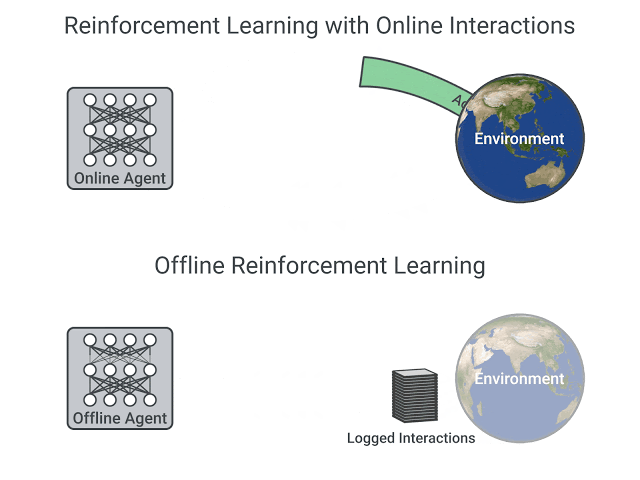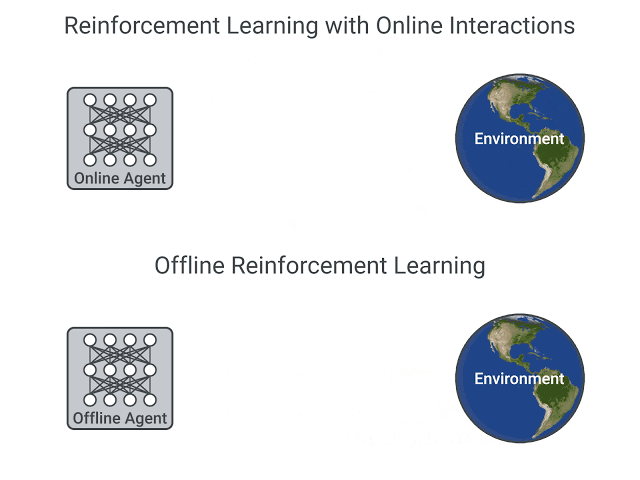
在线和离线强化学习的比较,图片摘自 这篇文章
在线强化学习中,**代理直接收集数据**:它通过与环境交互收集一批经验。然后,它立即(或通过某些回放缓冲区)使用这些经验从中学习(更新其策略)。
但这暗示着您要么直接在现实世界中训练您的代理,要么拥有一个模拟器。如果您没有模拟器,则需要构建一个,这可能非常复杂(如何在一个环境中反映现实世界的复杂性?),昂贵且不安全,因为如果模拟器有缺陷,代理会利用这些缺陷以获得竞争优势。
另一方面,在离线强化学习中,代理只使用从其他代理或人类演示中收集的数据。**它不与环境交互**。
过程如下:
- 使用一个或多个策略和/或人类交互创建数据集。
- 在此数据集上运行离线强化学习以学习策略
这种方法有一个缺点:反事实查询问题。如果我们的代理决定做一些我们没有数据的事情怎么办?例如,在十字路口右转,但我们没有这条轨迹数据。
关于这个主题已经存在一些解决方案,但如果你想了解更多关于离线强化学习的信息,你可以观看 这个视频
介绍决策Transformer
决策Transformer模型由L. Chen等人发表的《决策Transformer:通过序列建模进行强化学习》一文引入。它将强化学习抽象为**条件序列建模问题**。
核心思想是,我们不使用RL方法(例如拟合价值函数)来训练策略,从而告诉我们采取什么行动才能最大化回报(累积奖励),而是使用序列建模算法(Transformer)。该算法在给定期望回报、过去状态和行动的情况下,生成未来的行动以实现期望回报。它是一个自回归模型,以期望回报、过去状态和行动为条件,生成实现期望回报的未来行动。
这完全改变了强化学习的范式,因为我们使用生成轨迹建模(建模状态、动作和奖励序列的联合分布)来取代传统的RL算法。这意味着在决策Transformer中,我们不最大化回报,而是生成一系列未来动作以实现期望的回报。
这个过程是这样的
- 我们向决策Transformer输入最后 K 个时间步,包含 3 种输入:
- 剩余回报
- 状态
- 行动
- 如果状态是向量,则使用线性层嵌入token;如果是帧,则使用CNN编码器。
- 输入由GPT-2模型处理,该模型通过自回归建模预测未来的动作。
 决策Transformer架构。状态、动作和回报被输入到特定模态的线性嵌入层,并添加位置性剧集时间步编码。Token被送入GPT架构,该架构使用因果自注意力掩码自回归地预测动作。图片来自[1]。
决策Transformer架构。状态、动作和回报被输入到特定模态的线性嵌入层,并添加位置性剧集时间步编码。Token被送入GPT架构,该架构使用因果自注意力掩码自回归地预测动作。图片来自[1]。
在 🤗 Transformers 中使用决策Transformer
决策Transformer模型现已作为 🤗 transformers 库的一部分提供。此外,我们还分享了 Gym 环境中连续控制任务的九个预训练模型检查点。
一个“专家”决策Transformer模型,使用离线强化学习在Gym Walker2d环境中学习。
安装包
pip install git+https://github.com/huggingface/transformers
加载模型
使用决策Transformer相对容易,但由于它是一个自回归模型,因此在每个时间步准备模型输入时需要注意。我们准备了 Python 脚本 和 Colab Notebook 来演示如何使用此模型。
在 🤗 transformers 库中加载预训练的决策Transformer非常简单
from transformers import DecisionTransformerModel
model_name = "edbeeching/decision-transformer-gym-hopper-expert"
model = DecisionTransformerModel.from_pretrained(model_name)
创建环境
我们为 Gym Hopper、Walker2D 和 Halfcheetah 提供了预训练的检查点。Atari 环境的检查点也将很快提供。
import gym
env = gym.make("Hopper-v3")
state_dim = env.observation_space.shape[0] # state size
act_dim = env.action_space.shape[0] # action size
自回归预测函数
该模型执行自回归预测;也就是说,当前时间步**t**的预测会依次依赖于前一时间步的输出。这个函数相当复杂,所以我们将在注释中进行解释。
# Function that gets an action from the model using autoregressive prediction
# with a window of the previous 20 timesteps.
def get_action(model, states, actions, rewards, returns_to_go, timesteps):
# This implementation does not condition on past rewards
states = states.reshape(1, -1, model.config.state_dim)
actions = actions.reshape(1, -1, model.config.act_dim)
returns_to_go = returns_to_go.reshape(1, -1, 1)
timesteps = timesteps.reshape(1, -1)
# The prediction is conditioned on up to 20 previous time-steps
states = states[:, -model.config.max_length :]
actions = actions[:, -model.config.max_length :]
returns_to_go = returns_to_go[:, -model.config.max_length :]
timesteps = timesteps[:, -model.config.max_length :]
# pad all tokens to sequence length, this is required if we process batches
padding = model.config.max_length - states.shape[1]
attention_mask = torch.cat([torch.zeros(padding), torch.ones(states.shape[1])])
attention_mask = attention_mask.to(dtype=torch.long).reshape(1, -1)
states = torch.cat([torch.zeros((1, padding, state_dim)), states], dim=1).float()
actions = torch.cat([torch.zeros((1, padding, act_dim)), actions], dim=1).float()
returns_to_go = torch.cat([torch.zeros((1, padding, 1)), returns_to_go], dim=1).float()
timesteps = torch.cat([torch.zeros((1, padding), dtype=torch.long), timesteps], dim=1)
# perform the prediction
state_preds, action_preds, return_preds = model(
states=states,
actions=actions,
rewards=rewards,
returns_to_go=returns_to_go,
timesteps=timesteps,
attention_mask=attention_mask,
return_dict=False,)
return action_preds[0, -1]
评估模型
为了评估模型,我们需要一些额外的信息;训练期间使用的状态的均值和标准差。幸运的是,这些信息可以在Hugging Face Hub上每个检查点的模型卡中找到!
我们还需要一个模型的目标回报。这就是回报条件离线强化学习的强大之处:我们可以使用目标回报来控制策略的性能。这在多人设置中可能非常有用,我们可以根据玩家的难度调整对手机器人的性能。作者在他们的论文中展示了一个很好的图表!
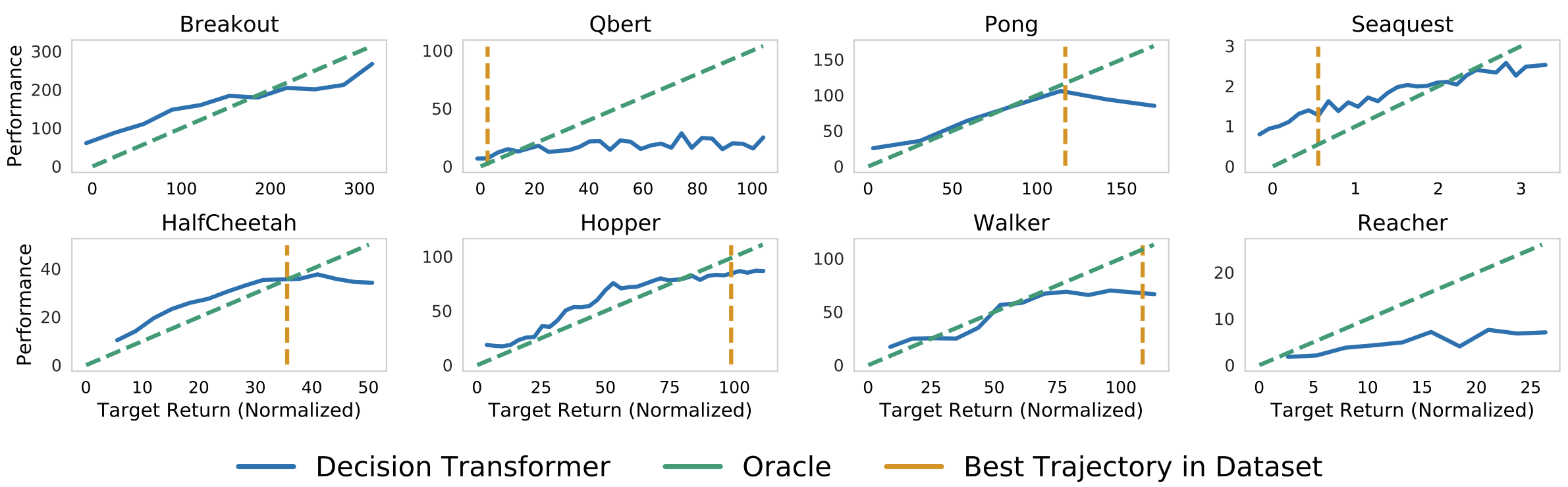 决策Transformer在给定目标(期望)回报条件下的采样(评估)回报。上图:Atari。下图:D4RL medium-replay数据集。图片来自[1]。
决策Transformer在给定目标(期望)回报条件下的采样(评估)回报。上图:Atari。下图:D4RL medium-replay数据集。图片来自[1]。
TARGET_RETURN = 3.6 # This was normalized during training
MAX_EPISODE_LENGTH = 1000
state_mean = np.array(
[1.3490015, -0.11208222, -0.5506444, -0.13188992, -0.00378754, 2.6071432,
0.02322114, -0.01626922, -0.06840388, -0.05183131, 0.04272673,])
state_std = np.array(
[0.15980862, 0.0446214, 0.14307782, 0.17629202, 0.5912333, 0.5899924,
1.5405099, 0.8152689, 2.0173461, 2.4107876, 5.8440027,])
state_mean = torch.from_numpy(state_mean)
state_std = torch.from_numpy(state_std)
state = env.reset()
target_return = torch.tensor(TARGET_RETURN).float().reshape(1, 1)
states = torch.from_numpy(state).reshape(1, state_dim).float()
actions = torch.zeros((0, act_dim)).float()
rewards = torch.zeros(0).float()
timesteps = torch.tensor(0).reshape(1, 1).long()
# take steps in the environment
for t in range(max_ep_len):
# add zeros for actions as input for the current time-step
actions = torch.cat([actions, torch.zeros((1, act_dim))], dim=0)
rewards = torch.cat([rewards, torch.zeros(1)])
# predicting the action to take
action = get_action(model,
(states - state_mean) / state_std,
actions,
rewards,
target_return,
timesteps)
actions[-1] = action
action = action.detach().numpy()
# interact with the environment based on this action
state, reward, done, _ = env.step(action)
cur_state = torch.from_numpy(state).reshape(1, state_dim)
states = torch.cat([states, cur_state], dim=0)
rewards[-1] = reward
pred_return = target_return[0, -1] - (reward / scale)
target_return = torch.cat([target_return, pred_return.reshape(1, 1)], dim=1)
timesteps = torch.cat([timesteps, torch.ones((1, 1)).long() * (t + 1)], dim=1)
if done:
break
您可以在我们的 Colab Notebook 中找到一个更详细的示例,其中包括创建代理的视频。
结论
除了决策Transformer,我们还希望支持深度强化学习社区的更多用例和工具。因此,我们非常期待听到您对决策Transformer模型的反馈,以及更普遍地,我们可以与您一起构建的任何对RL有用的东西。请随时**与我们联系**。
接下来呢?
在未来几周和几个月内,我们计划支持生态系统中的其他工具
- 整合**RL-baselines3-zoo**
- 上传**RL-trained-agents模型**到Hub:使用stable-baselines3训练的强化学习代理的大量集合
- 集成其他深度强化学习库
- 实现用于Atari的卷积决策Transformer
- 更多精彩敬请期待🥳
保持联系的最佳方式是**加入我们的discord服务器**,与我们和社区交流。
参考文献
[1] Chen, Lili, et al. "决策Transformer:通过序列建模进行强化学习." 神经信息处理系统进展 34 (2021)。
[2] Agarwal, Rishabh, Dale Schuurmans, and Mohammad Norouzi. "离线强化学习的乐观展望." 国际机器学习会议. PMLR, 2020。
致谢
我们感谢论文的第一作者 Kevin Lu 和 Lili Chen 提供的建设性交流。


