使用《太空侵略者》进行深度 Q 学习


《使用 Hugging Face 🤗 的深度强化学习课程》第三单元
⚠️ 本文的最新更新版本可在此处获取 👉 https://huggingface.co/deep-rl-course/unit1/introduction
本文是深度强化学习课程的一部分。这是一个从入门到精通的免费课程。请在此处查看课程大纲 here.

⚠️ 本文的最新更新版本可在此处获取 👉 https://huggingface.co/deep-rl-course/unit1/introduction
本文是深度强化学习课程的一部分。这是一个从入门到精通的免费课程。请在此处查看课程大纲 here.
在上一单元中,我们学习了第一个强化学习算法:Q 学习,并从头开始实现它,然后在 FrozenLake-v1 ☃️ 和 Taxi-v3 🚕 两个环境中对其进行了训练。
我们使用这个简单的算法取得了优异的成绩。但这些环境相对简单,因为状态空间是离散且小的(FrozenLake-v1 有 14 种不同状态,Taxi-v3 有 500 种)。
但正如我们将看到的,在大型状态空间环境中,生成和更新 Q 表可能会变得效率低下。
所以今天,我们将研究我们的第一个深度强化学习智能体:深度 Q 学习。深度 Q 学习不是使用 Q 表,而是使用神经网络,该神经网络以状态为输入,并根据该状态近似每个动作的 Q 值。
我们将使用 RL-Zoo 训练它玩《太空侵略者》和其他 Atari 环境。RL-Zoo 是一个基于 Stable-Baselines 的 RL 训练框架,提供用于训练、评估智能体、调整超参数、绘制结果和录制视频的脚本。

那么,我们开始吧!🚀
为了理解本单元,您需要首先理解 Q 学习。
从 Q 学习到深度 Q 学习
我们了解到,Q 学习是我们用来训练 Q 函数的算法,Q 函数是一个动作值函数,它确定处于特定状态并在该状态下采取特定动作的价值。
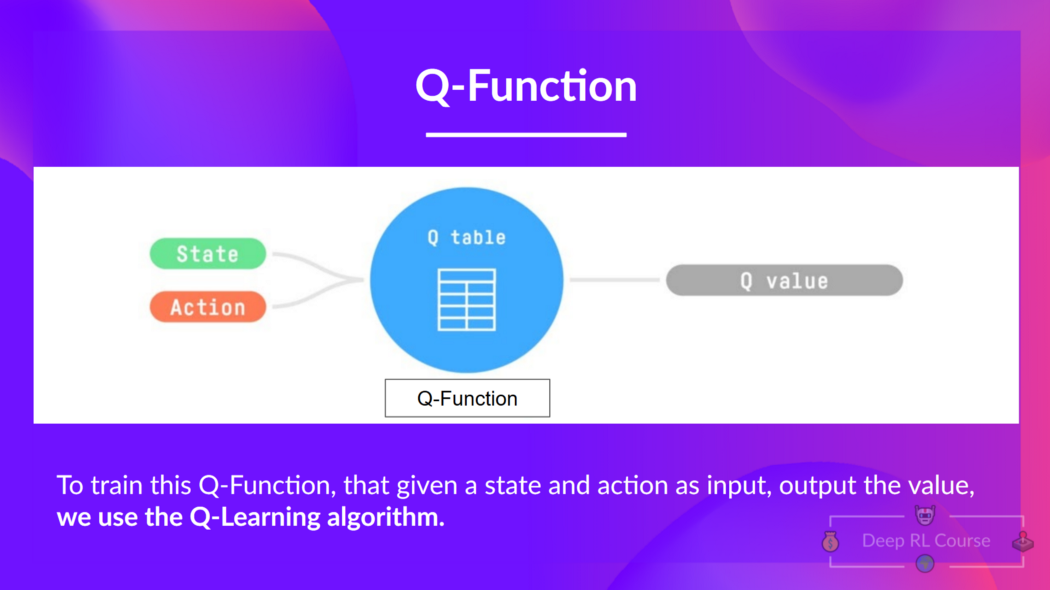
Q 来自该动作在该状态下的“质量”。
在内部,我们的 Q 函数有一个 Q 表,一个表格,其中每个单元格对应一个状态-动作对值。将这个 Q 表视为我们 Q 函数的记忆或作弊表。
问题在于 Q 学习是一种表格方法。也就是说,当状态和动作空间足够小,可以通过数组和表格表示价值函数时,它才有效。这不具备可扩展性。
Q 学习在小状态空间环境中表现良好,例如:
- FrozenLake,我们有 14 个状态。
- Taxi-v3,我们有 500 个状态。
但想想我们今天要做的:我们将训练一个智能体使用帧作为输入来学习玩《太空侵略者》。
正如尼基塔·梅尔科泽罗夫(Nikita Melkozerov)所说,Atari 环境的观察空间形状为 (210, 160, 3),包含 0 到 255 的值,因此这给我们带来了 256^(210x160x3) = 256^100800(作为比较,我们可观测宇宙中大约有 10^80 个原子)。
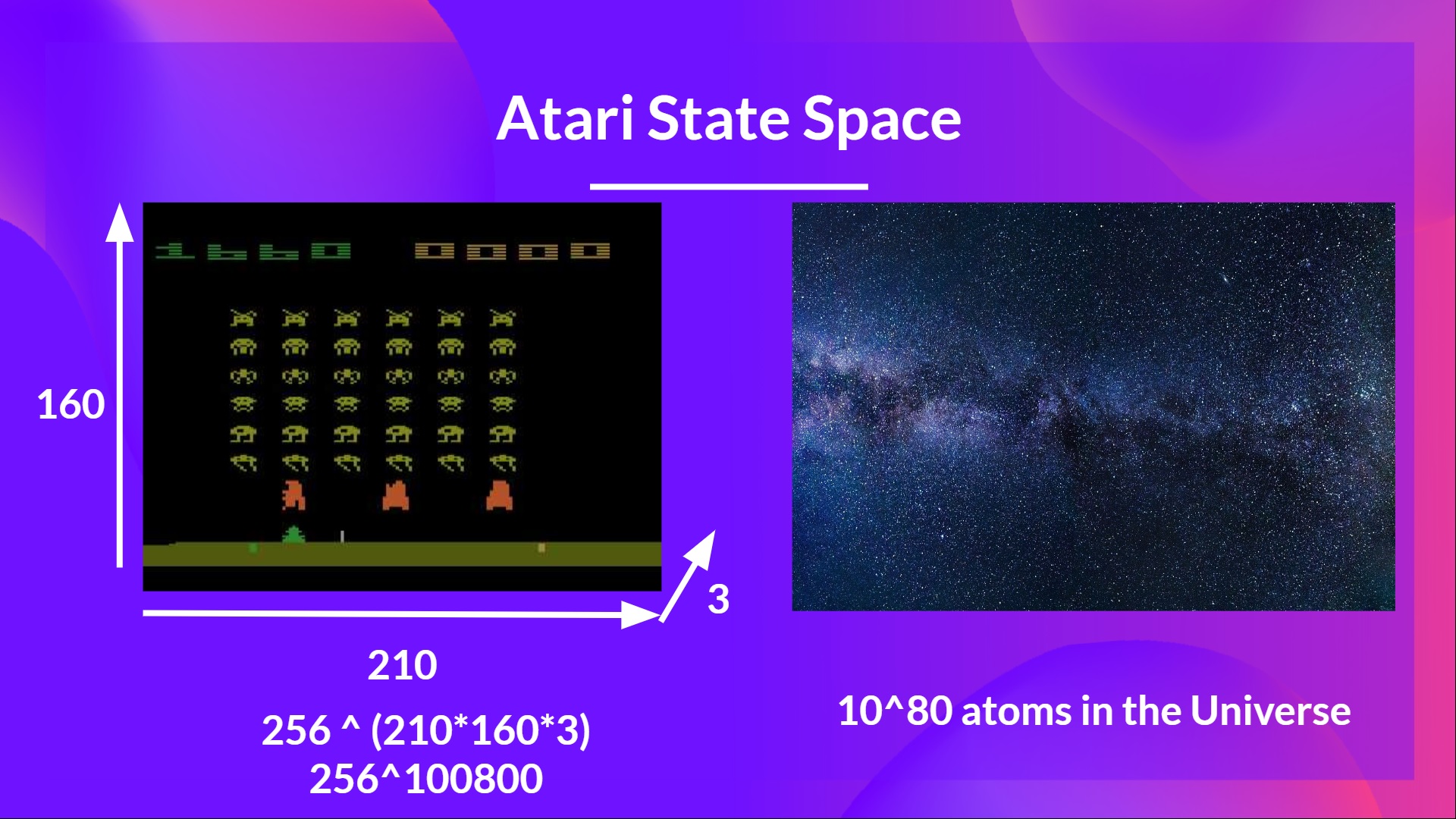
因此,状态空间是巨大的;因此,为该环境创建和更新 Q 表将效率低下。在这种情况下,最好的方法是使用参数化的 Q 函数 来近似 Q 值,而不是使用 Q 表。
这个神经网络将近似地给出给定状态下每个可能动作的不同 Q 值。这正是深度 Q 学习所做的。
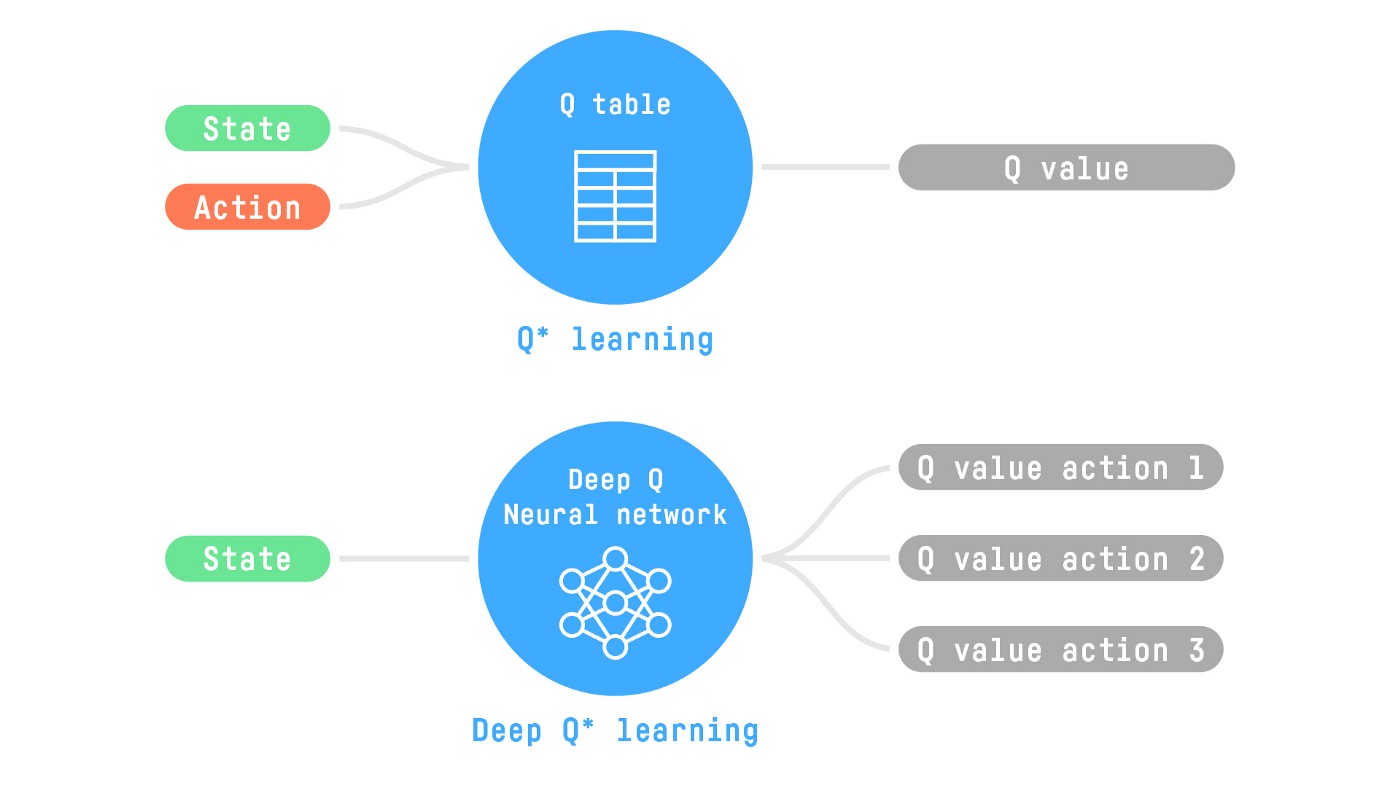
现在我们了解了深度 Q 学习,让我们深入了解深度 Q 网络。
深度 Q 网络 (DQN)
这是我们的深度 Q 学习网络的架构
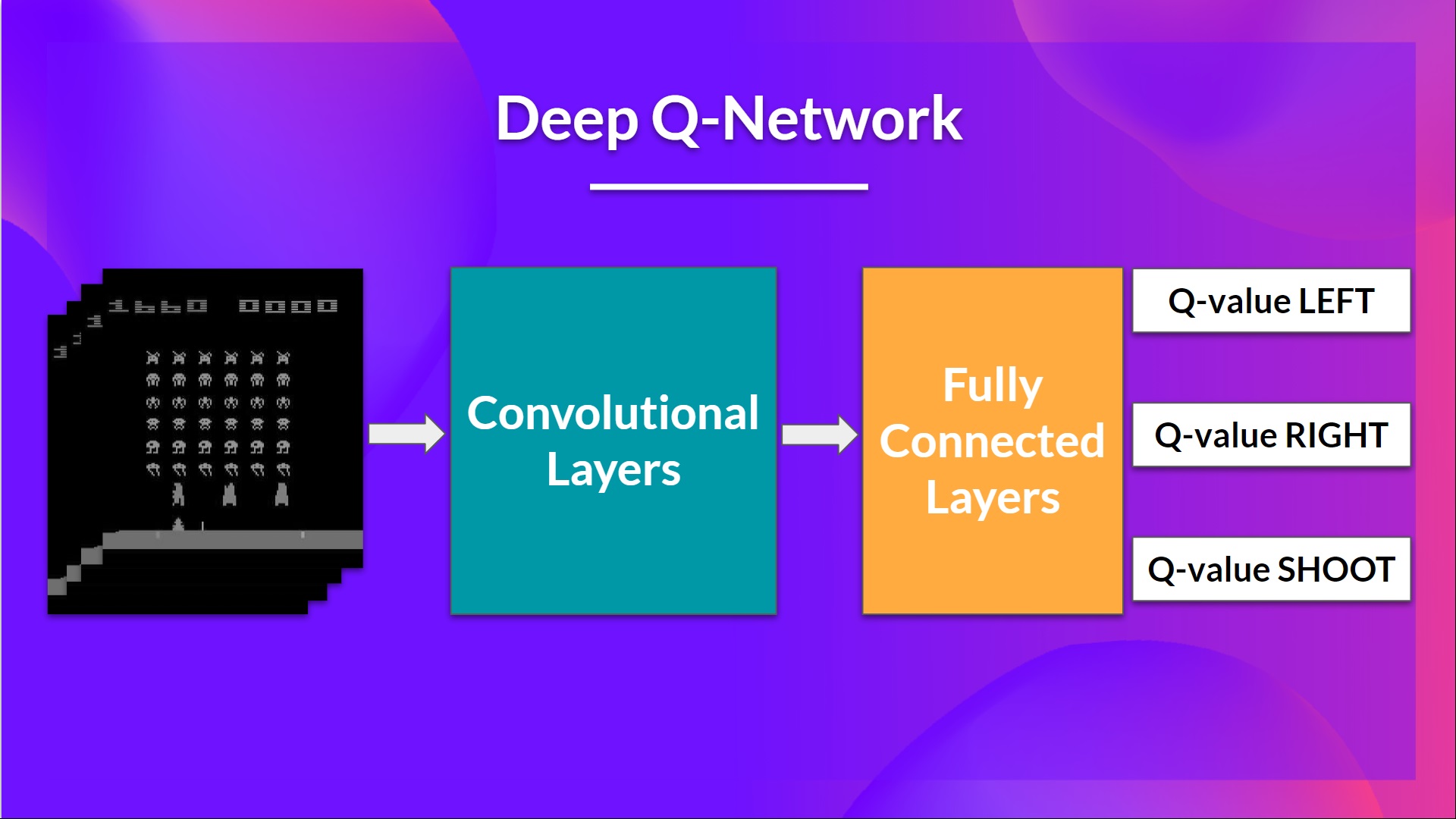
作为输入,我们获取4 帧的堆栈作为状态通过网络,并输出一个向量,其中包含该状态下每个可能动作的 Q 值。然后,像 Q 学习一样,我们只需使用 epsilon-greedy 策略来选择要执行的动作。
当神经网络初始化时,Q 值估计很糟糕。但在训练期间,我们的深度 Q 网络智能体将把情况与适当的动作关联起来,并学会很好地玩游戏。
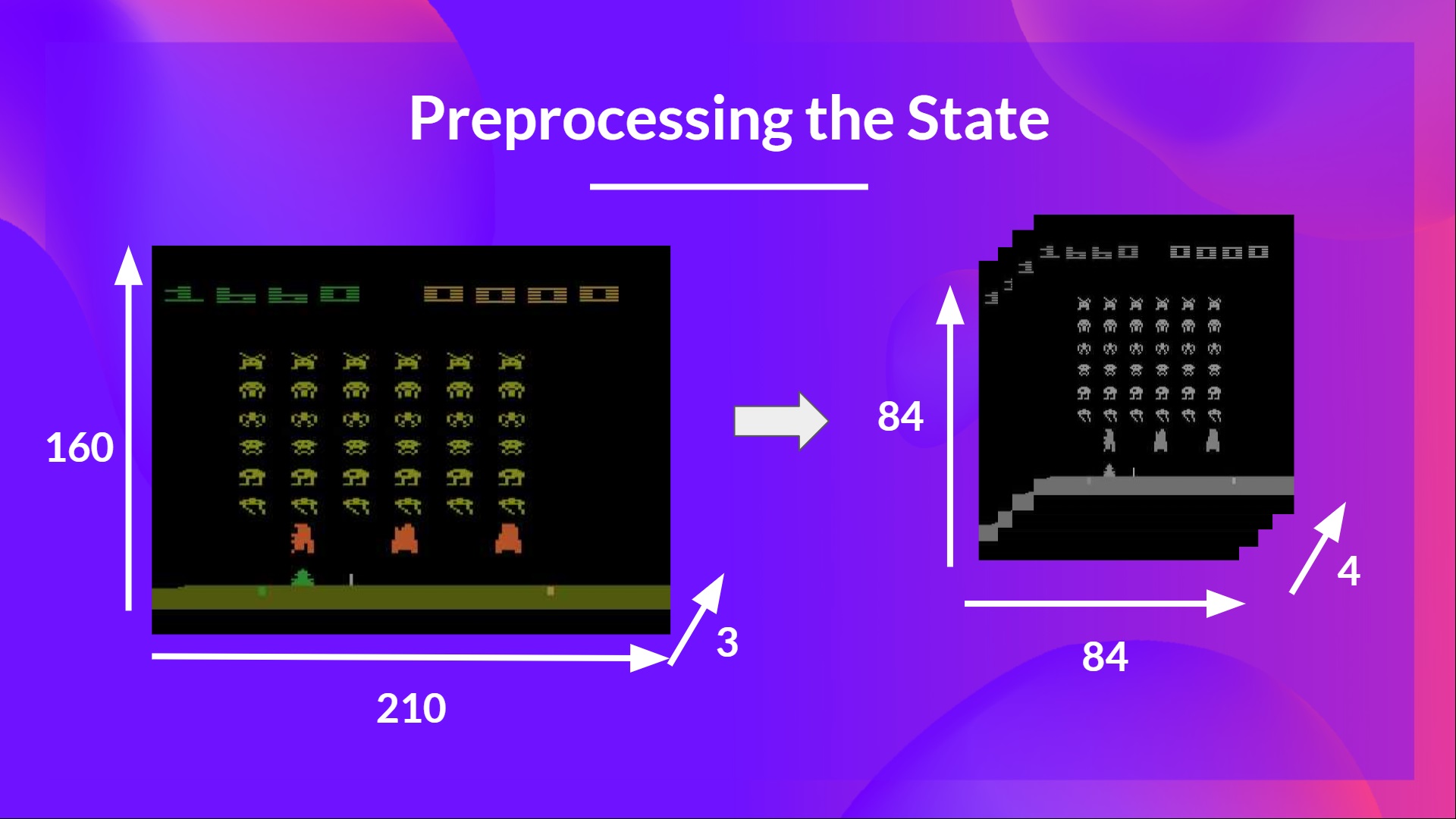
输入预处理和时间限制
我们提到我们预处理输入。这是一个重要的步骤,因为我们希望降低状态的复杂性,以减少训练所需的计算时间。
所以我们所做的是将状态空间缩小到 84x84 并进行灰度处理(因为 Atari 环境中的颜色没有增加重要信息)。这是一个重要的节省,因为我们将三个颜色通道(RGB)减少到 1 个。
在某些游戏中,如果屏幕的某个部分不包含重要信息,我们还可以裁剪它。然后我们将四帧堆叠在一起。
我们为什么要将四帧堆叠在一起?我们将帧堆叠在一起有助于我们处理时间限制问题。我们以 Pong 游戏为例。当您看到这一帧时:

你能告诉我球的走向吗?不能,因为一帧不足以感知运动!但如果我再添加三帧呢?现在你可以看到球正向右边移动。
 这就是为什么,为了捕捉时间信息,我们将四帧堆叠在一起。
这就是为什么,为了捕捉时间信息,我们将四帧堆叠在一起。然后,堆叠的帧由三个卷积层处理。这些层允许我们捕获和利用图像中的空间关系。此外,由于帧是堆叠在一起的,您可以利用这些帧之间的一些空间属性。
最后,我们有几个全连接层,它们输出该状态下每个可能动作的 Q 值。
因此,我们看到深度 Q 学习使用神经网络来近似给定状态下每个可能动作的不同 Q 值。现在让我们研究深度 Q 学习算法。
深度 Q 学习算法
我们了解到,深度 Q 学习使用深度神经网络来近似给定状态下每个可能动作的不同 Q 值(值函数估计)。
不同之处在于,在训练阶段,我们不是像 Q 学习那样直接更新状态-动作对的 Q 值,

在深度 Q 学习中,我们创建了一个损失函数,用于衡量我们的 Q 值预测与 Q 目标之间的差异,并使用梯度下降来更新深度 Q 网络的权重,以更好地近似我们的 Q 值。

深度 Q 学习训练算法有两个阶段
- 采样:我们执行动作并将观察到的经验元组存储在重放记忆中。
- 训练:随机选择一小批元组,并使用梯度下降更新步骤从中学习。

但是,这并不是与 Q 学习相比的唯一变化。深度 Q 学习训练可能会受到不稳定性困扰,主要是由于结合了非线性 Q 值函数(神经网络)和自举(当我们用现有估计而不是实际完整回报更新目标时)。
为了帮助我们稳定训练,我们实施了三种不同的解决方案:
- 经验回放,以更有效地利用经验。
- 固定 Q 目标以稳定训练。
- 双重深度 Q 学习,以处理 Q 值过高估计的问题。
经验回放以更有效地利用经验
我们为什么创建重放记忆?
深度 Q 学习中的经验回放有两个功能
- 在训练过程中更有效地利用经验.
- 经验回放帮助我们在训练过程中更有效地利用经验。通常,在在线强化学习中,我们在环境中进行交互,获取经验(状态、动作、奖励和下一个状态),从中学习(更新神经网络)并丢弃它们。
- 但是通过经验回放,我们创建了一个重放缓冲区,它保存了我们可以在训练期间重复使用的经验样本。

⇒ 这使我们能够从单个经验中多次学习。
- 避免遗忘过去的经验并减少经验之间的相关性.
- 如果我们向神经网络提供顺序的经验样本,就会出现一个问题:它倾向于遗忘过去的经验,因为新的经验会覆盖旧的经验。例如,如果我们在第一关,然后是第二关(不同),我们的智能体可能会忘记如何在第一关中行动和玩游戏。
解决方案是创建一个回放缓冲区,在与环境交互时存储经验元组,然后采样一小批元组。这可以防止网络只学习它立即做过的事情。
经验回放还有其他好处。通过随机采样经验,我们消除了观察序列中的相关性,并避免了动作值振荡或灾难性发散。
在深度 Q 学习的伪代码中,我们看到我们初始化一个容量为 N 的重放内存缓冲区 D(N 是您可以定义的超参数)。然后我们将经验存储在内存中,并采样一个经验小批量,在训练阶段将其馈送到深度 Q 网络。

固定 Q 目标以稳定训练
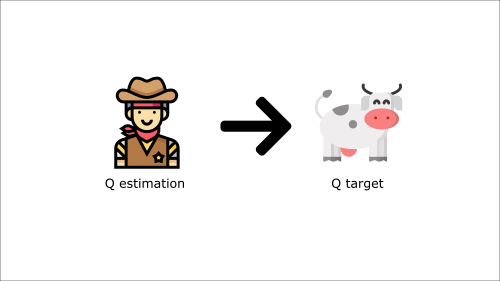
当我们要计算 TD 误差(即损失)时,我们计算TD 目标(Q 目标)与当前 Q 值(Q 的估计值)之间的差异。
但是,我们没有任何关于真实 TD 目标的想法。我们需要估计它。使用贝尔曼方程,我们看到 TD 目标只是在该状态下采取该动作的奖励加上下一个状态的折扣最高 Q 值。
然而,问题在于我们使用相同的参数(权重)来估计 TD 目标和 Q 值。因此,TD 目标和我们正在改变的参数之间存在显著相关性。
因此,这意味着在训练的每一步,我们的 Q 值都在变化,而目标值也在变化。这就像追逐一个移动的目标!这导致训练中出现显著的振荡。
这就像你是一个牛仔(Q 估计),你想抓住牛(Q 目标),你必须靠近(减少误差)。
在每个时间步,你都试图接近牛,而牛也在每个时间步移动(因为你使用相同的参数)。

 这导致了奇怪的追逐路径(训练中的显著振荡)。
这导致了奇怪的追逐路径(训练中的显著振荡)。 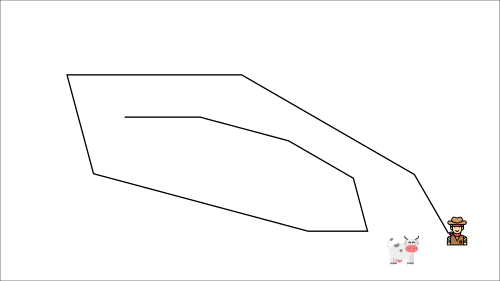
相反,我们在伪代码中看到的是:
- 使用一个具有固定参数的独立网络来估计 TD 目标。
- 每隔 C 步从我们的深度 Q 网络复制参数以更新目标网络。

双重 DQN
双重 DQN 或双重学习由 Hado van Hasselt 提出。这种方法解决了 Q 值高估的问题。
为了理解这个问题,请记住我们如何计算 TD 目标
通过计算 TD 目标,我们面临一个简单的问题:我们如何确定下一个状态的最佳动作是具有最高 Q 值的动作?
我们知道 Q 值的准确性取决于我们尝试的动作和我们探索的相邻状态。
因此,在训练开始时,我们没有足够的信息来判断要采取的最佳行动。因此,将最大 Q 值(有噪声)作为要采取的最佳行动可能会导致误报。如果非最优行动经常被赋予高于最优最佳行动的 Q 值,那么学习将变得复杂。
解决方案是:在计算 Q 目标时,我们使用两个网络将动作选择与目标 Q 值生成解耦。我们:
- 使用我们的 DQN 网络为下一个状态选择最佳动作(具有最高 Q 值的动作)。
- 使用我们的目标网络计算在下一个状态下执行该动作的目标 Q 值。
因此,双重 DQN 有助于我们减少 Q 值的过高估计,从而有助于我们更快地训练并获得更稳定的学习。
自深度 Q 学习这三个改进以来,又增加了许多改进,例如优先经验回放、对抗深度 Q 学习。这些超出了本课程的范围,但如果您感兴趣,请查看我们在阅读列表中列出的链接。👉 https://github.com/huggingface/deep-rl-class/blob/main/unit3/README.md
现在您已经学习了深度 Q 学习的理论,您已经准备好训练您的深度 Q 学习智能体来玩 Atari 游戏了。我们将从《太空侵略者》开始,但您可以使用任何您想玩的 Atari 游戏🔥
我们使用的是 RL-Baselines-3 Zoo 集成,它是深度 Q 学习的原始版本,没有双重 DQN、对战 DQN 和优先经验回放等扩展。
从这里开始教程 👉 https://colab.research.google.com/github/huggingface/deep-rl-class/blob/main/unit3/unit3.ipynb
与同学比较结果的排行榜 🏆 👉 https://huggingface.co/spaces/chrisjay/Deep-Reinforcement-Learning-Leaderboard
恭喜您完成本章!信息量很大。恭喜您完成本教程。您刚刚训练了您的第一个深度 Q 学习智能体并将其分享到 Hub 🥳。
如果所有这些元素让你**仍然感到困惑**,那是**正常现象**。**我和所有学习强化学习的人都经历过同样的感觉。**
花时间真正掌握这些材料,然后再继续。
不要犹豫,在其他环境(Pong、Seaquest、QBert、Ms Pac Man)中训练您的智能体。最好的学习方式是自己尝试!
如果您想深入了解,我们在教学大纲中发布了额外的阅读材料 👉 https://github.com/huggingface/deep-rl-class/blob/main/unit3/README.md
在下一单元中,我们将学习策略梯度方法。
别忘了分享给你想学习的朋友 🤗!
最后,我们希望根据您的反馈迭代改进和更新课程。如果您有任何反馈,请填写此表格 👉 https://forms.gle/3HgA7bEHwAmmLfwh9

