Q-Learning 简介 第 2/2 部分


Hugging Face 🤗 深度强化学习课程第二单元第 2 部分
⚠️ 本文的最新更新版本在此处提供 👉 https://huggingface.co/deep-rl-course/unit1/introduction
本文是深度强化学习课程的一部分。这是一个从入门到精通的免费课程。请在此处查看课程大纲 here.
⚠️ 本文的最新更新版本在此处提供 👉 https://huggingface.co/deep-rl-course/unit1/introduction
本文是深度强化学习课程的一部分。这是一个从入门到精通的免费课程。请在此处查看课程大纲 here.
在本单元的第一部分,我们学习了基于值的方法以及蒙特卡罗学习与时序差分学习之间的区别。
因此,在第二部分中,我们将学习 Q-Learning,并从头开始实现我们的第一个强化学习代理,一个 Q-Learning 代理,并将在两个环境中对其进行训练
- 冰冻湖 v1 ❄️:我们的代理需要通过只在冰冻砖块 (F) 上行走并避开洞 (H) 来从起始状态 (S) 到达目标状态 (G)。
- 一辆自动出租车 🚕:代理将需要学习如何在一座城市中导航,将乘客从 A 点运送到 B 点。
如果您想学习深度 Q-Learning(第三单元),本单元至关重要。
那么,我们开始吧!🚀
Q-Learning 介绍
什么是 Q-Learning?
Q-Learning 是一种离策略的基于值的方法,它使用 TD 方法来训练其动作-值函数:
- 离策略:我们将在本章末尾讨论。
- 基于值的方法:通过训练一个值函数或动作-值函数间接找到最优策略,该函数将告诉我们每个状态或每个状态-动作对的值。
- 使用 TD 方法:在每一步而不是在情节结束时更新其动作-值函数。
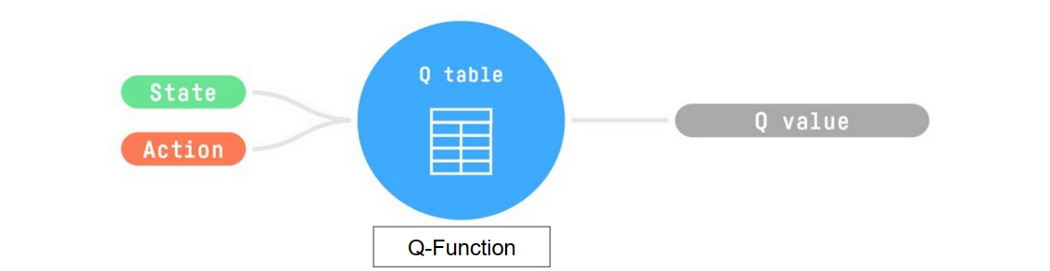
Q-Learning 是我们用来训练 Q-函数(一种动作-值函数)的算法,它确定了在特定状态下采取特定动作的价值。
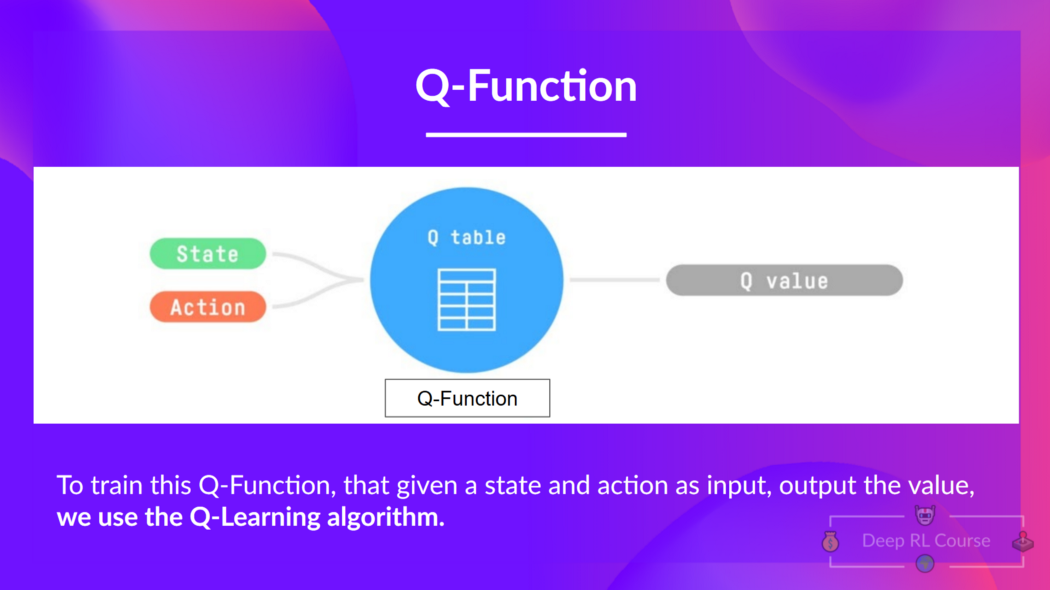
Q 来自于该动作在该状态下的“质量”。
在内部,我们的 Q-函数有一个 Q-表,其中每个单元格对应一个状态-动作值对。 将此 Q-表视为我们 Q-函数的记忆或备忘录。
如果我们以这个迷宫为例

Q 表已初始化。这就是为什么所有值都 = 0。此表包含每个状态的四个状态-动作值。

这里我们看到,初始状态并向上移动的状态-动作值为 0:

因此,Q-函数包含一个 Q-表,其中包含每个状态-动作对的值。 给定一个状态和动作,我们的 Q-函数将在其 Q-表中搜索并输出该值。
回顾一下,Q-Learning 是强化学习算法,它:
- 训练Q-函数(一个动作-值函数),它内部是一个Q-表,包含所有状态-动作对的值。
- 给定一个状态和动作,我们的 Q 函数将在其 Q-表中搜索相应的值。
- 训练完成后,我们拥有一个最优的 Q 函数,这意味着我们拥有一个最优的 Q 表。
- 如果我们拥有最优的 Q 函数,我们就拥有最优策略,因为我们知道在每个状态下应该采取的最佳动作。

但是,在训练开始时,我们的 Q 表是无用的,因为它为每个状态-动作对提供了任意值(大多数情况下,我们将 Q 表初始化为 0)。但是,随着我们探索环境并更新 Q 表,它将为我们提供越来越好的近似值。

现在我们已经了解了 Q-Learning、Q-Function 和 Q-Table 是什么,让我们深入了解 Q-Learning 算法。
Q-Learning 算法
这是 Q-Learning 的伪代码;让我们研究每个部分,并通过一个简单的例子来看看它是如何工作的,然后再实现它。 不要被它吓倒,它比看起来简单!我们将逐步介绍每个步骤。

步骤 1:我们初始化 Q-表

我们需要为每个状态-动作对初始化 Q-表。大多数情况下,我们将其初始化为 0。
步骤 2:使用 Epsilon 贪婪策略选择动作
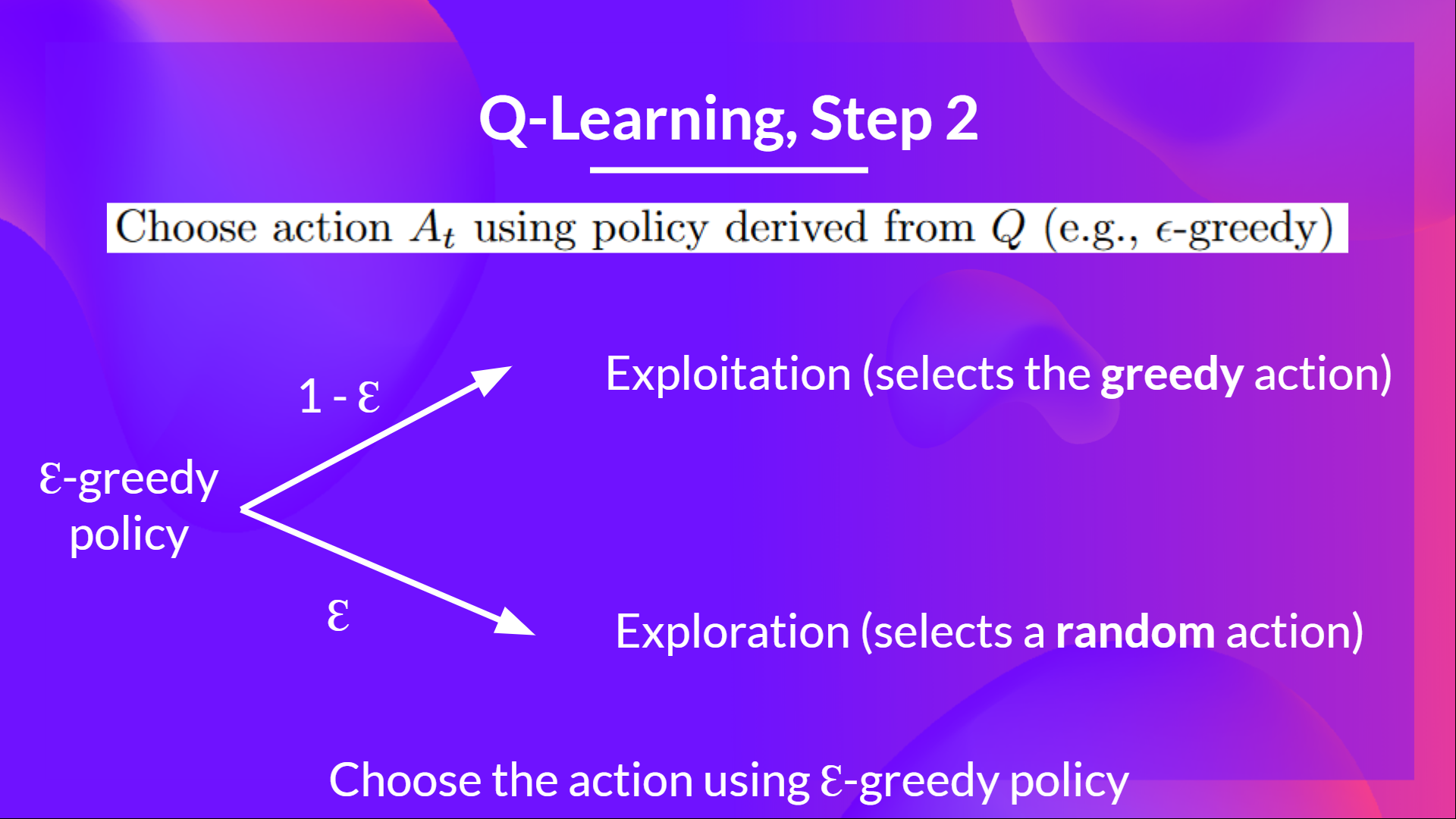
Epsilon Greedy 策略是一种处理探索/利用权衡的策略。
其思想是我们将 epsilon ɛ = 1.0
- 以 1 - ɛ 的概率:我们进行利用(即我们的代理选择具有最高状态-动作对值的动作)。
- 以 ɛ 的概率:我们进行探索(尝试随机动作)。
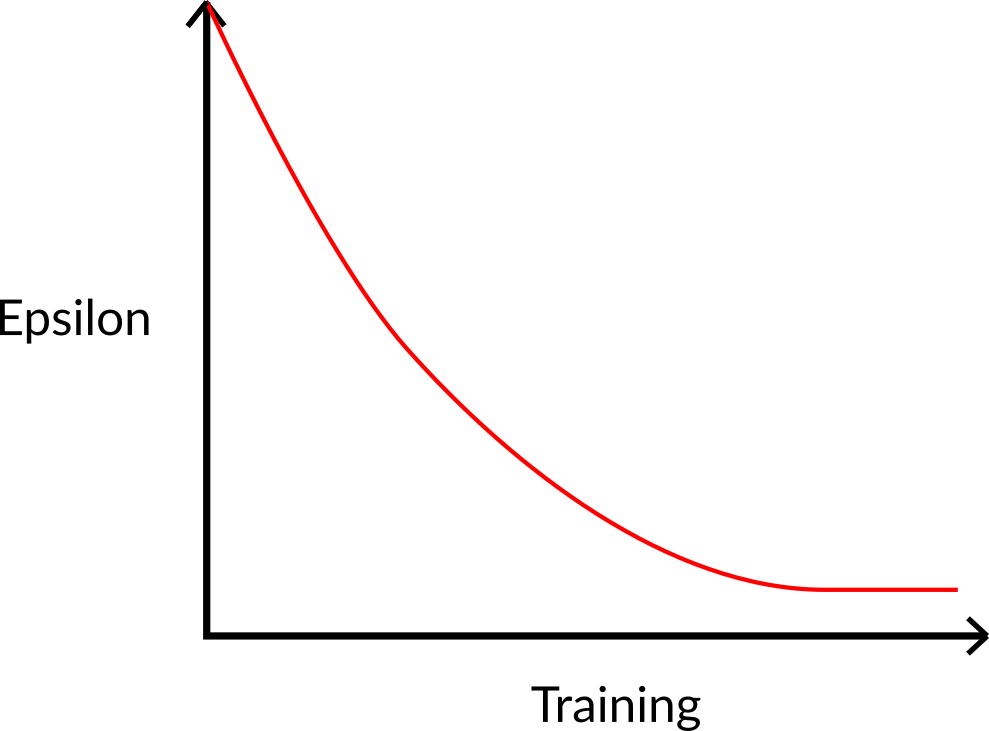
在训练开始时,探索的概率将非常大,因为 ɛ 值很高,所以大部分时间我们都会进行探索。 但是随着训练的进行,我们的 Q-表在估计方面变得越来越好,我们逐渐降低 epsilon 值,因为我们需要的探索越来越少,而利用越来越多。
步骤 3:执行动作 At,得到奖励 Rt+1 和下一个状态 St+1

步骤 4:更新 Q(St, At)
请记住,在 TD 学习中,我们在交互的每一步后更新我们的策略或值函数(取决于我们选择的强化学习方法)。
为了生成我们的 TD 目标,我们使用了即时奖励 加上下一个状态最佳状态-动作对的折扣值(我们称之为自举)。
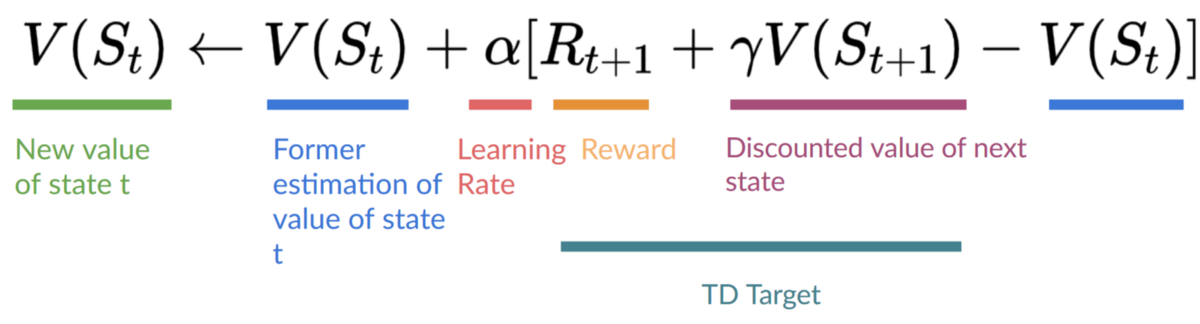
因此,我们的 更新公式如下:
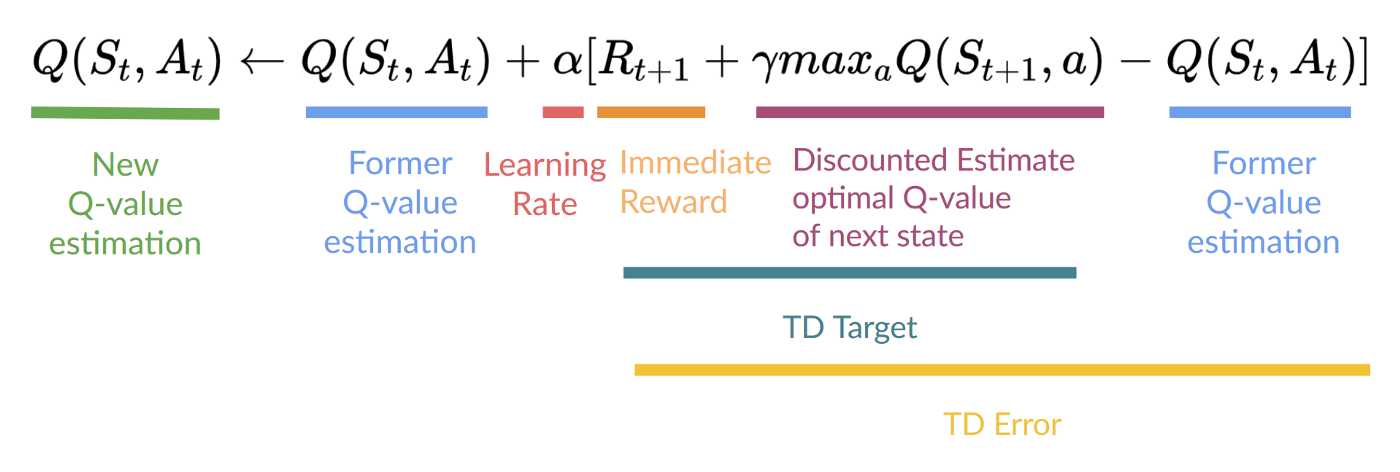
这意味着要更新我们的
- 我们需要 。
- 为了更新给定状态-动作对的 Q 值,我们使用 TD 目标。
我们如何形成 TD 目标?
- 在执行动作 后,我们获得了奖励。
- 为了获得最佳的下一个状态-动作对值,我们使用贪婪策略来选择下一个最佳动作。请注意,这不是 epsilon 贪婪策略,它总是选择具有最高状态-动作值的动作。
然后,当这个 Q 值的更新完成后。我们进入一个新状态,并再次使用我们的 epsilon-贪婪策略选择动作。
这就是为什么我们说这是一种离策略算法。
离策略 vs. 在策略
差异是微妙的
- 离策略:使用不同的策略进行行动和更新。
例如,对于 Q-Learning,Epsilon 贪婪策略(行动策略)与用于选择最佳下一个状态-动作值以更新我们的 Q 值(更新策略)的贪婪策略不同。
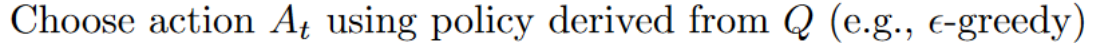
与训练过程中使用的策略不同
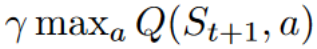
- 在策略:使用相同的策略进行行动和更新。
例如,对于另一种基于值的算法 Sarsa,Epsilon-Greedy 策略选择的是 next_state-action 对,而不是贪婪策略。


Q-Learning 示例
为了更好地理解 Q-Learning,我们来看一个简单的例子

- 你是一只迷宫里的小老鼠。你总是从同一个起点开始。
- 目标是吃到右下角的那一大堆奶酪,并避开毒药。毕竟,谁不喜欢奶酪呢?
- 如果吃毒药、吃一大堆奶酪或超过五步,情节就会结束。
- 学习率为 0.1
- 伽马(折扣率)为 0.99

- +0: 进入没有奶酪的状态。
- +1: 进入有少量奶酪的状态。
- +10: 进入有大量奶酪的状态。
- -10: 进入有毒药的状态,从而死亡。
- +0 如果我们花费超过五步。

为了训练我们的代理以获得最优策略(即向右、向右、向下移动的策略),我们将使用 Q-Learning 算法。
步骤 1:我们初始化 Q-表

所以,现在,我们的 Q-表毫无用处;我们需要使用 Q-Learning 算法来训练我们的 Q-函数。
让我们进行 2 次训练时间步
训练时间步 1
步骤 2:使用 Epsilon 贪婪策略选择动作
因为 epsilon 很大 = 1.0,我采取一个随机动作,在这种情况下,我向右移动。
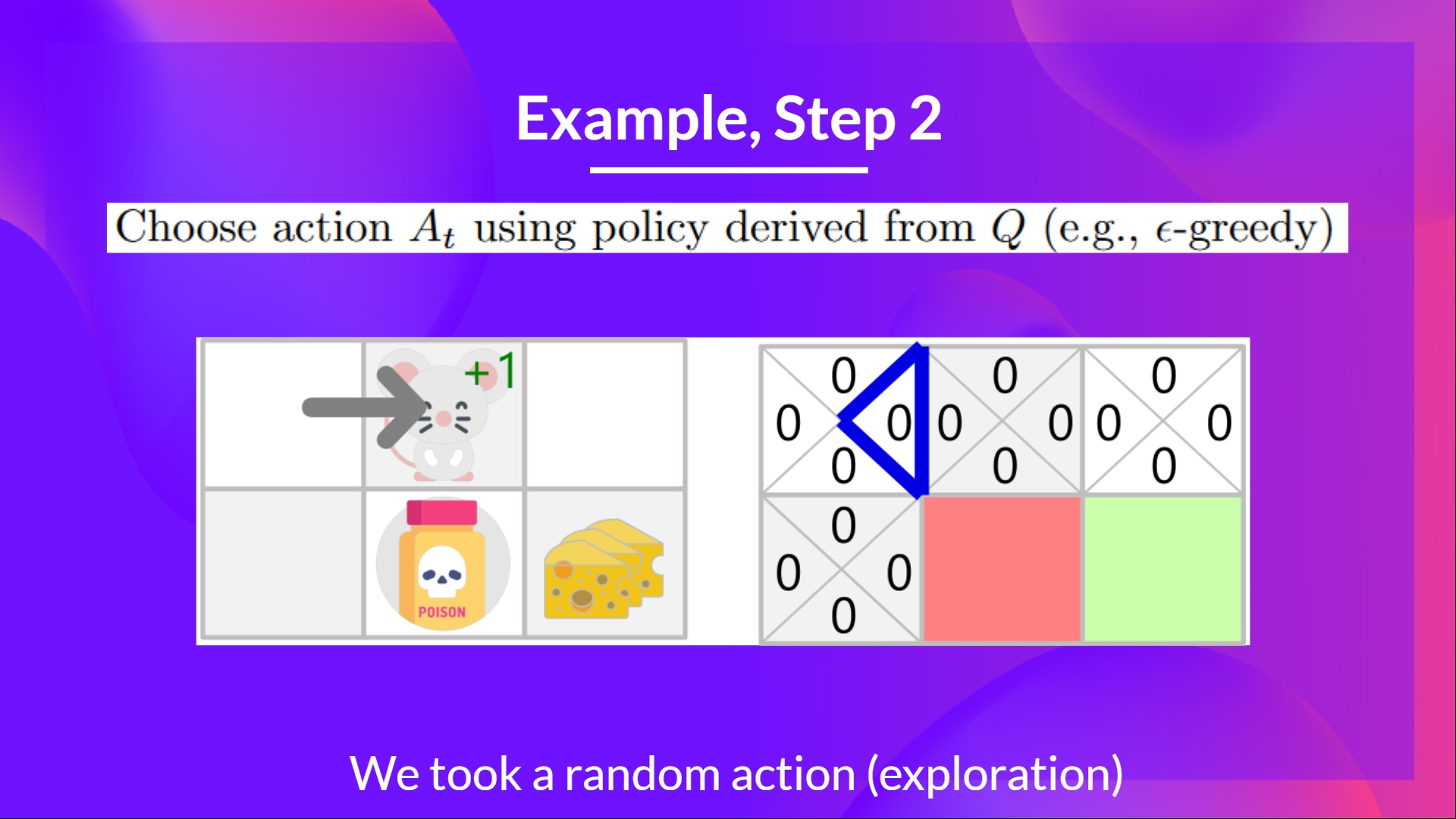
步骤 3:执行动作 At,得到 Rt+1 和 St+1
通过向右走,我得到了一小块奶酪,所以 ,然后我进入了一个新状态。
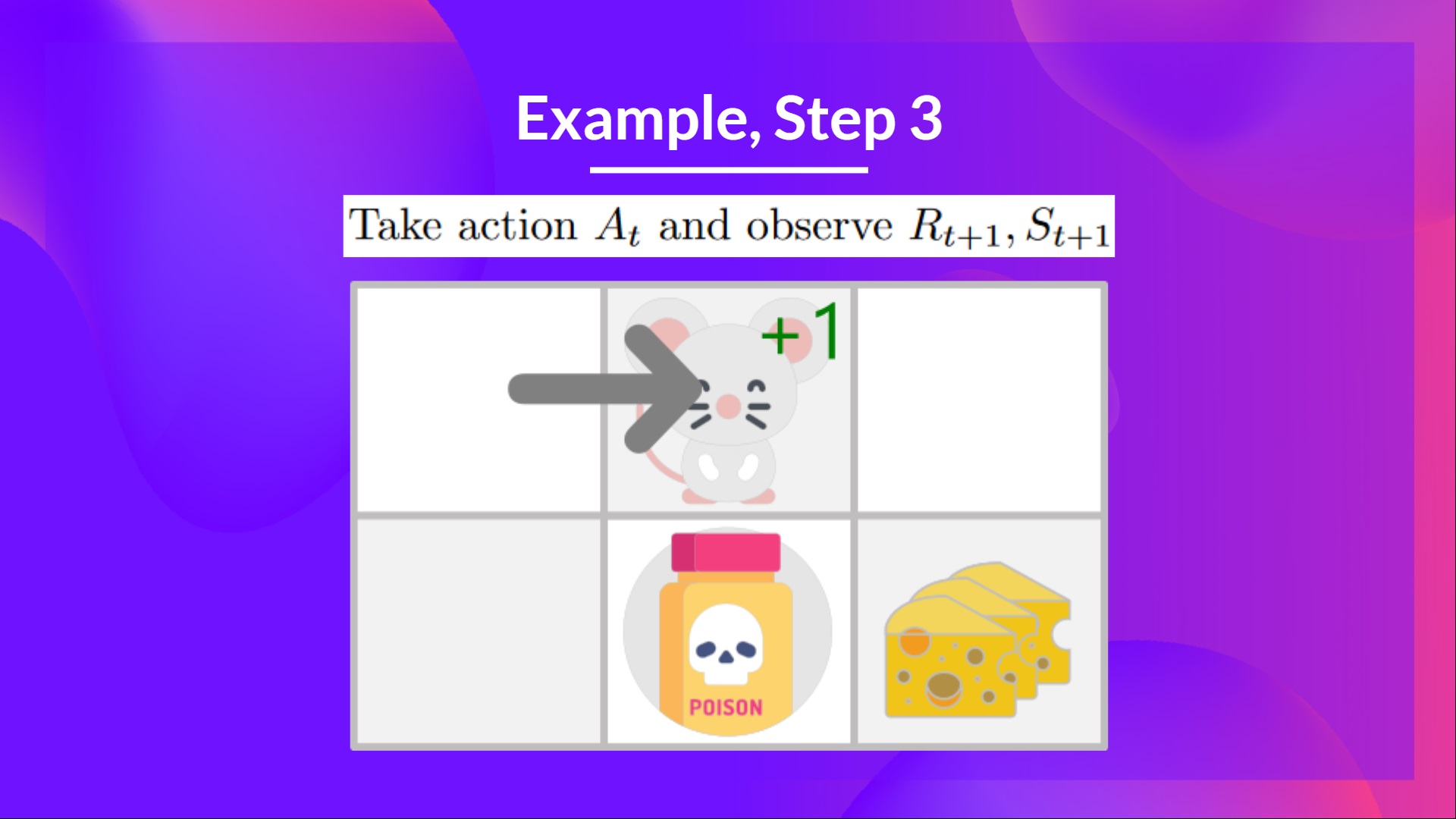
步骤 4:更新
我们现在可以使用我们的公式更新 。


训练时间步 2
步骤 2:使用 Epsilon 贪婪策略选择动作
我再次采取随机动作,因为 epsilon 仍然很大,为 0.99(因为我们稍微衰减了它,随着训练的进行,我们希望探索越来越少)。
我采取了向下移动的动作。这不是一个好的动作,因为它把我带到了毒药。
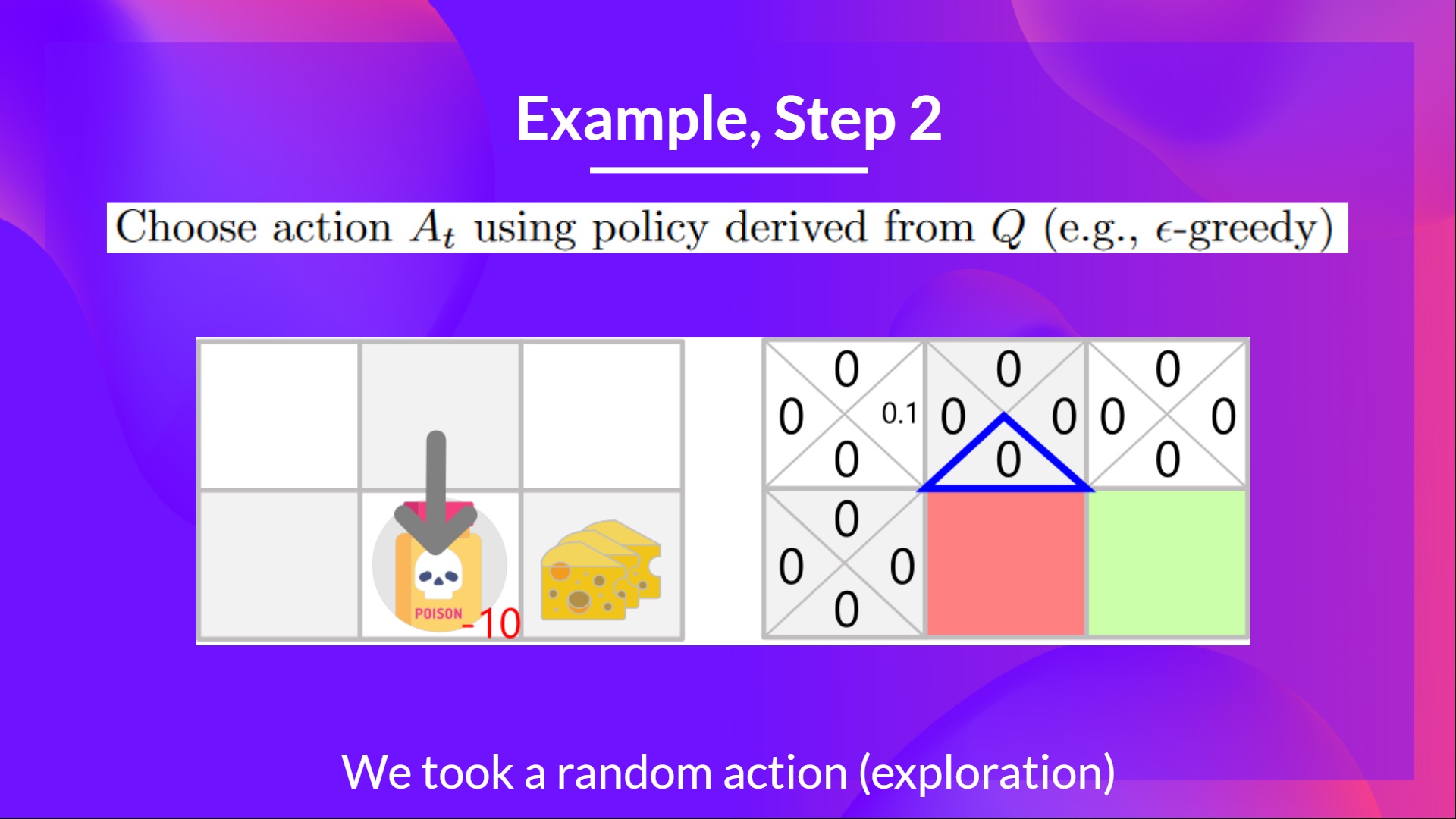
步骤 3:执行动作 At,得到 和 St+1
因为我到了毒药状态,我得到了 ,然后我就死了。
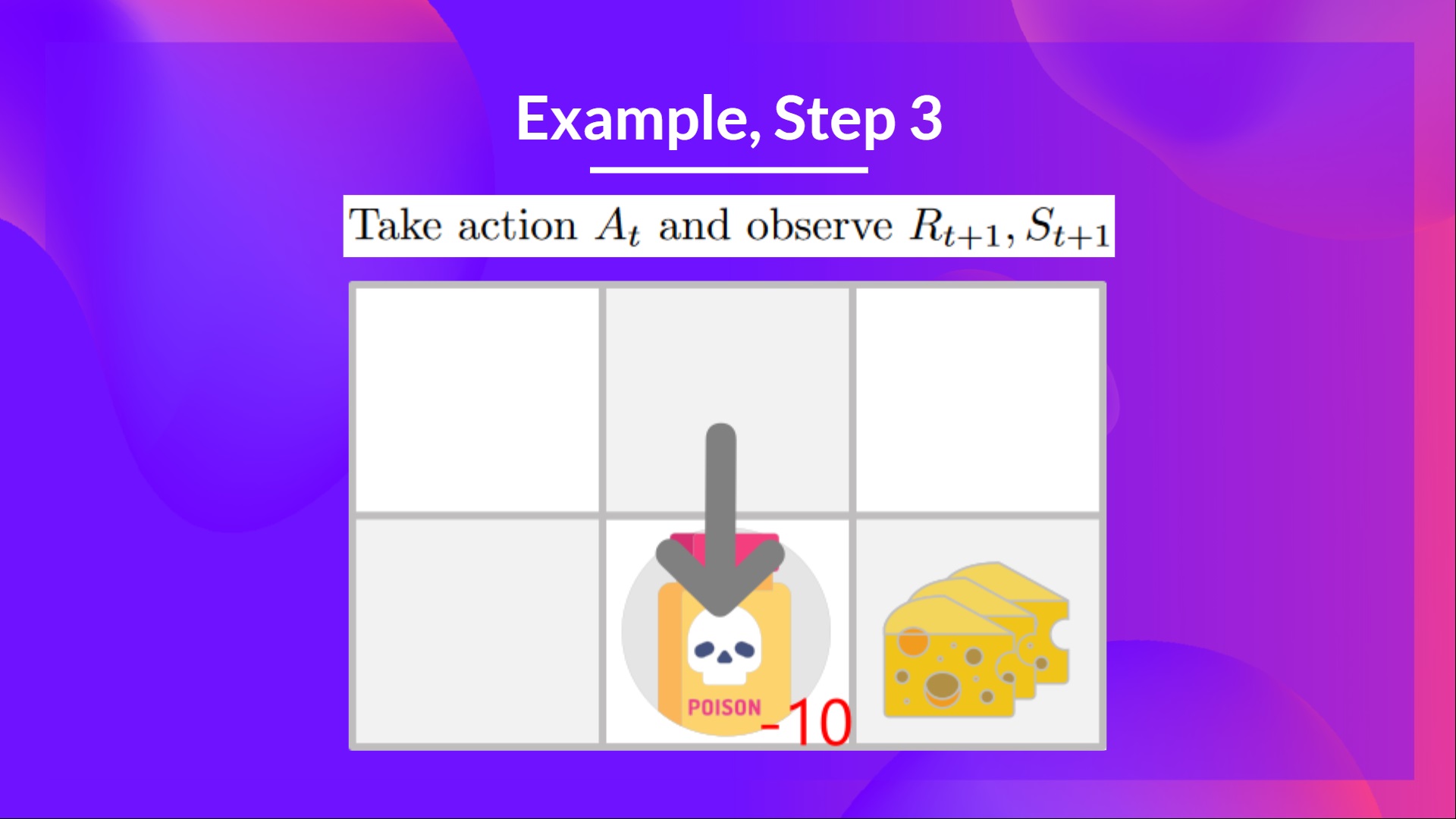
步骤 4:更新

因为我们死了,所以我们开始了一个新的回合。但我们在这里看到的是,经过两次探索步骤,我的代理变得更聪明了。
随着我们继续探索和利用环境,并使用 TD 目标更新 Q 值,Q-表将为我们提供越来越好的近似值。因此,在训练结束时,我们将得到最优 Q-函数的估计。
现在我们已经学习了 Q-Learning 的理论,接下来让我们从头开始实现它。我们将训练一个 Q-Learning 代理,并在两个环境中对其进行训练
- 冰冻湖 v1 ❄️(非光滑版):我们的代理需要通过只在冰冻砖块 (F) 上行走并避开洞 (H) 来从起始状态 (S) 到达目标状态 (G)。
- 一辆自动出租车 🚕 将需要学习如何在城市中导航,将乘客从 A 点运送到 B 点。
在此处开始教程 👉 https://colab.research.google.com/github/huggingface/deep-rl-class/blob/main/unit2/unit2.ipynb
排行榜 👉 https://huggingface.co/spaces/chrisjay/Deep-Reinforcement-Learning-Leaderboard
恭喜您完成本章!其中包含大量信息。也恭喜您完成了所有教程。您刚刚从头开始实现了您的第一个强化学习代理并将其分享到 Hub 上 🥳。
在学习新架构时,从头开始实现对于理解其工作原理至关重要。
如果所有这些元素让你**仍然感到困惑**,那是**正常现象**。**我和所有学习强化学习的人都经历过同样的感觉。**
花时间真正掌握这些材料,然后再继续。
因为学习和避免能力错觉的最佳方法是测试自己。我们编写了一个测验来帮助您找到需要加强学习的地方。在此处检查您的知识 👉 https://github.com/huggingface/deep-rl-class/blob/main/unit2/quiz2.md
掌握这些要素并打下坚实的基础对于进入有趣的部分至关重要。请毫不犹豫地修改实现,尝试改进它并更改环境,学习的最佳方式是自己尝试!
如果您想深入了解,我们在教学大纲中发布了其他阅读材料 👉 https://github.com/huggingface/deep-rl-class/blob/main/unit2/README.md
别忘了分享给你想学习的朋友 🤗!
最后,我们希望**根据你的反馈不断改进和更新课程**。如果你有任何反馈,请填写此表格 👉 https://forms.gle/3HgA7bEHwAmmLfwh9

