使用PyTorch实现策略梯度

Hugging Face 🤗 深度强化学习课程的第五单元
⚠️ **本文的新更新版本可在此处获取** 👉 https://huggingface.co/deep-rl-course/unit1/introduction
本文是深度强化学习课程的一部分。这是一个从初学者到专家的免费课程。在此处查看课程大纲 here. 
⚠️ **本文的新更新版本可在此处获取** 👉 https://huggingface.co/deep-rl-course/unit1/introduction
本文是深度强化学习课程的一部分。这是一个从入门到精通的免费课程。请在此处查看课程大纲 here.
在上一单元中,我们学习了深度Q学习。在这个基于价值的深度强化学习算法中,我们**使用深度神经网络来近似某个状态下每个可能动作的不同Q值。**
事实上,从课程开始,我们只研究了基于价值的方法,**我们通过估计一个价值函数作为找到最优策略的中间步骤。**

因为在基于价值的方法中,**π只存在于动作价值估计中,因为策略只是一个函数**(例如,贪婪策略),它将选择给定状态下价值最高的动作。
但是,使用基于策略的方法,我们希望**直接优化策略,而无需学习价值函数的中间步骤。**
所以今天,**我们将研究我们的第一个基于策略的方法**:强化。我们将使用PyTorch从头开始实现它。然后使用CartPole-v1、PixelCopter和Pong测试其鲁棒性。

让我们开始吧,
什么是策略梯度方法?
策略梯度是基于策略方法的一个子类,这类算法**旨在不使用价值函数的情况下直接优化策略,采用不同的技术。**与基于策略方法不同的是,策略梯度方法是一系列旨在**通过使用梯度上升估计最优策略的权重**来直接优化策略的算法。
策略梯度概述
为什么我们在策略梯度方法中通过使用梯度上升估计最优策略的权重来直接优化策略?
请记住,强化学习的目的是**找到最优行为策略(policy)以最大化其预期累积奖励。**
我们还需要记住,策略是一个函数,**给定一个状态,它会输出一个动作分布**(在我们的例子中,使用随机策略)。

我们使用策略梯度的目标是通过调整策略来控制动作的概率分布,从而使**好的动作(最大化回报的动作)在未来被更频繁地采样。**
举一个简单的例子
我们通过让我们的策略与环境交互来收集一个回合。
然后我们查看该回合的奖励总和(预期回报)。如果这个总和是正的,我们**认为在该回合中采取的动作是好的**:因此,我们希望增加每个状态-动作对的P(a|s)(在该状态下采取该动作的概率)。
策略梯度算法(简化版)如下:

但是深度Q学习很棒!为什么要使用策略梯度方法呢?
策略梯度方法的优点
与深度Q学习方法相比,有许多优点。让我们来看看其中一些:
集成的简易性:**我们可以直接估计策略而无需存储额外数据(动作值)。**
策略梯度方法**可以学习随机策略,而价值函数不能**。
这有两点影响:
a. 我们**不需要手动实现探索/利用权衡**。由于我们输出的是动作的概率分布,因此代理会**探索状态空间,而不会总是采取相同的轨迹。**
b. 我们也摆脱了**感知混叠**问题。感知混叠是指两个状态看起来(或确实是)相同,但需要不同的动作。
举个例子:我们有一个智能吸尘器,它的目标是吸尘并避免杀死仓鼠。

我们的吸尘器只能感知墙壁的位置。
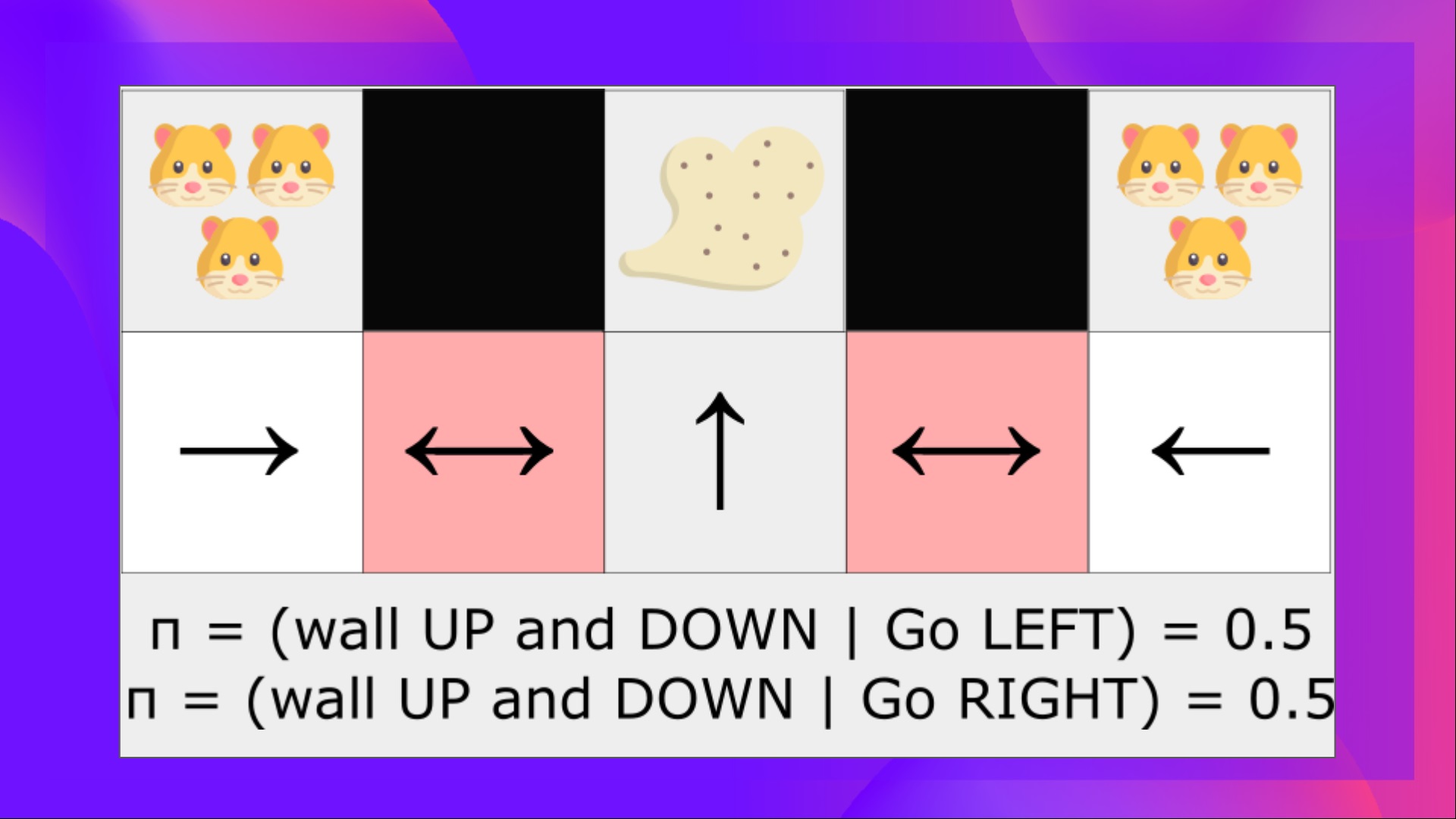
问题是这两个红色方框是混叠状态,因为代理在每个方框中都感知到上方和下方的墙壁。
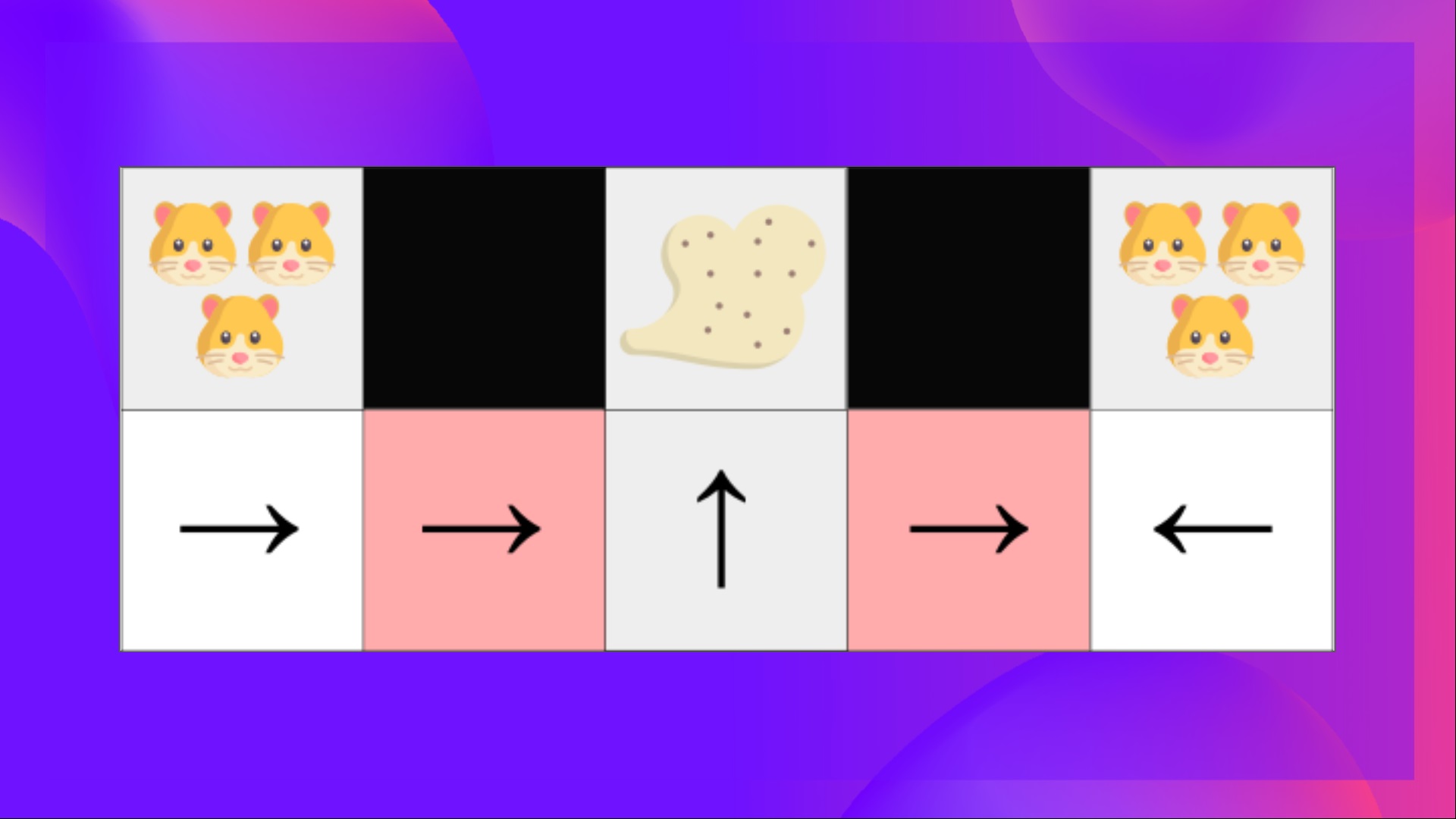
在确定性策略下,策略将在处于红色状态时向右移动或向左移动。**无论哪种情况都会导致我们的代理卡住,永远无法吸到灰尘。**
在基于价值的强化学习算法下,我们学习了一个准确定性策略(“贪婪 ε 策略”)。因此,我们的代理在找到灰尘之前可能会花费大量时间。
另一方面,最优随机策略将在灰色状态下随机向左或向右移动。因此,**它不会卡住,并且以高概率达到目标状态。**
- 策略梯度在**高维动作空间和连续动作空间中更有效**。
事实上,深度Q学习的问题在于,它们的**预测为每个可能的动作分配一个分数(最大预期未来奖励)**,在每个时间步,给定当前状态。
但是如果我们有无限的行动可能性呢?
例如,对于自动驾驶汽车,在每个状态下,你可能(几乎)有无限的动作选择(方向盘转15°、17.2°、19.4°、鸣笛等)。我们需要为每个可能的动作输出一个Q值!而从连续输出中选择最大动作本身就是一个优化问题!
相反,使用策略梯度,我们输出一个**动作的概率分布。**
策略梯度方法的缺点
当然,策略梯度方法也有一些缺点:
- 策略梯度很多时候会收敛到局部最大值而不是全局最优。
- 策略梯度进展更快,**一步一步地:训练可能需要更长时间(效率低下)。**
- 策略梯度可能具有高方差(解决方案基线)。
👉 如果你想深入了解策略梯度方法的优点和缺点,你可以查看这个视频。
现在我们已经了解了策略梯度的大致情况及其优缺点,**让我们研究并实现其中一个**:强化。
强化(蒙特卡洛策略梯度)
强化,也称为蒙特卡洛策略梯度,**使用整个回合的估计回报来更新策略参数** 。
我们有一个策略π,它有一个参数θ。这个π在给定一个状态下,**输出一个动作的概率分布**。

其中 是代理在给定策略下从状态st选择动作at的概率。
**但我们如何知道我们的策略是好是坏呢?**我们需要有一种方法来衡量它。为此,我们定义了一个称为 的分数/目标函数。
评分函数J是预期回报

请记住,策略梯度可以看作是一个优化问题。因此,我们必须找到最佳参数(θ)来最大化评分函数J(θ)。
为此,我们将使用策略梯度定理。我不会深入数学细节,如果你感兴趣,请查看此视频
强化算法的工作原理如下:循环
- 使用策略 收集一个回合
- 使用该回合估算梯度

- 更新策略的权重:
我们可以这样解释:
- 是从状态st选择动作at的**(对数)概率增加最陡峭的方向**。这意味着它告诉我们,如果我们想增加/减少在状态st选择动作at的对数概率,**我们应该如何改变策略的权重**。
- :是评分函数。
- 如果回报高,它将提高(状态,动作)组合的概率。
- 反之,如果回报低,它将降低(状态,动作)组合的概率。
既然我们已经学习了强化背后的理论,**你就可以用 PyTorch 编写你的强化智能体了**。你将使用 CartPole-v1、PixelCopter 和 Pong 来测试它的鲁棒性。
从这里开始教程 👉 https://colab.research.google.com/github/huggingface/deep-rl-class/blob/main/unit5/unit5.ipynb
与同学比较结果的排行榜 🏆 👉 https://huggingface.co/spaces/chrisjay/Deep-Reinforcement-Learning-Leaderboard
恭喜你完成了这一章!有很多信息。恭喜你完成了教程。你刚刚使用 PyTorch 从零开始编写了你的第一个深度强化学习智能体,并将其分享到 Hub 🥳。
**如果你仍然对所有这些元素感到困惑,这是正常的**。**我和所有学习 RL 的人都一样。**
花时间真正掌握这些材料,然后再继续。
不要犹豫,在其他环境中训练你的 Agent。最好的学习方式是自己动手尝试!
如果你想深入了解,我们在大纲中发布了额外的阅读材料👉**https://github.com/huggingface/deep-rl-class/blob/main/unit5/README.md**
在下一单元中,我们将学习策略基于价值方法和基于价值方法相结合的方法,称为 Actor Critic 方法。
别忘了与想要学习的朋友分享 🤗!
最后,我们希望**通过您的反馈不断改进和更新本课程**。如果您有任何反馈,请填写此表格 👉**https://forms.gle/3HgA7bEHwAmmLfwh9**

