少样本学习实践:GPT-Neo 和 🤗 加速推理 API







在许多机器学习应用程序中,可用标记数据的数量是生成高性能模型的障碍。NLP 的最新发展表明,您可以通过在推理时提供少量示例来克服此限制,这是一种称为少样本学习的技术,利用大型语言模型。在本博客文章中,我们将解释什么是少样本学习,并探讨如何使用大型语言模型 GPT-Neo 和 🤗 加速推理 API 来生成您自己的预测。
什么是少样本学习?
少样本学习是指通过极少量训练数据(例如在推理时提供几个示例)来指导机器学习模型的预测,这与需要相对大量训练数据才能使预训练模型准确适应所需任务的标准微调技术相反。
该技术主要用于计算机视觉领域,但随着一些最新的语言模型,如 EleutherAI GPT-Neo 和 OpenAI GPT-3,我们现在可以在自然语言处理(NLP)中使用它。
在自然语言处理中,少样本学习可以与大型语言模型一起使用,这些模型在大型文本数据集上进行预训练时已经学会了隐式执行大量任务。这使得模型能够通过少量示例来泛化,即理解相关但以前未见过的任务。
少样本 NLP 示例由三个主要组成部分构成:
- 任务描述:模型应该做什么的简短描述,例如“将英语翻译成法语”
- 示例:一些示例,展示模型预期会预测什么,例如“sea otter => loutre de mer”
- 提示:新示例的开头,模型应通过生成缺失文本来完成,例如“cheese => ”

图片来源:《语言模型是少样本学习器》
创建这些少样本示例可能很棘手,因为您需要通过它们来阐明模型应该执行的“任务”。一个常见的问题是,模型,尤其是小型模型,对示例的编写方式非常敏感。
在生产中优化少样本学习的一种方法是学习任务的通用表示,然后在此表示之上训练任务特定的分类器。
OpenAI 在 GPT-3 论文中表明,少样本提示能力随着语言模型参数的数量而提高。
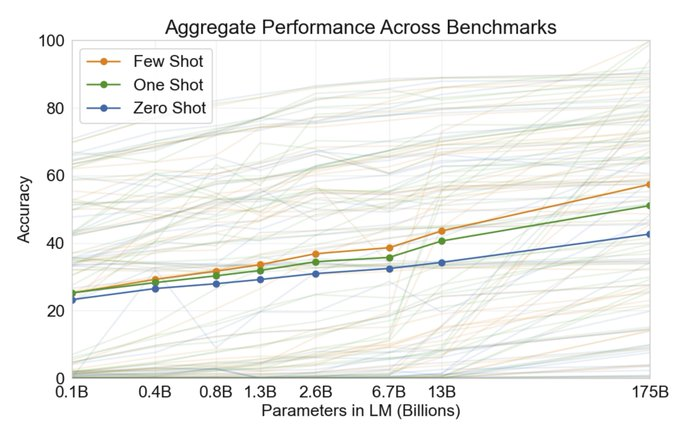
图片来源:《语言模型是少样本学习器》
现在,让我们看看如何使用 GPT-Neo 和 🤗 Accelerated Inference API 来生成您自己的少样本学习预测!
什么是 GPT-Neo?
GPT-Neo 是 EleutherAI 开发的一系列基于 GPT 架构的转换器语言模型。EleutherAI 的主要目标是训练一个与 GPT-3 大小相当的模型,并以开放许可协议向公众提供。
目前所有可用的 GPT-Neo 检查点都使用 Pile 数据集进行训练,Pile 数据集是一个大型文本语料库,在(Gao et al., 2021)中有详细记载。因此,它有望在与其训练文本分布相匹配的文本上表现更好;我们建议您在设计示例时牢记这一点。
🤗 加速推理 API
加速推理 API 是我们托管的服务,通过简单的 API 调用,您可以在 🤗 模型中心上运行 10,000 多个公开可用的模型,或您自己的私有模型。与开箱即用的 Transformers 部署相比,该 API 在 CPU 和 GPU 上提供了加速,速度提升高达 100 倍。
要在您自己的应用程序中集成使用 GPT-Neo 进行少样本学习预测,您可以使用下面的代码片段和 🤗 Accelerated Inference API。您可以在此处找到您的 API 令牌,如果您还没有帐户,可以从此处开始。
import json
import requests
API_TOKEN = ""
def query(payload='',parameters=None,options={'use_cache': False}):
API_URL = "https://api-inference.huggingface.co/models/EleutherAI/gpt-neo-2.7B"
headers = {"Authorization": f"Bearer {API_TOKEN}"}
body = {"inputs":payload,'parameters':parameters,'options':options}
response = requests.request("POST", API_URL, headers=headers, data= json.dumps(body))
try:
response.raise_for_status()
except requests.exceptions.HTTPError:
return "Error:"+" ".join(response.json()['error'])
else:
return response.json()[0]['generated_text']
parameters = {
'max_new_tokens':25, # number of generated tokens
'temperature': 0.5, # controlling the randomness of generations
'end_sequence': "###" # stopping sequence for generation
}
prompt="...." # few-shot prompt
data = query(prompt,parameters,options)
实用见解
以下是一些实用见解,可帮助您开始使用 GPT-Neo 和 🤗 加速推理 API。
由于 GPT-Neo (2.7B) 比 GPT-3 (175B) 小约 60 倍,因此它在零样本问题上的泛化能力不如后者,需要 3-4 个示例才能获得良好的结果。当您提供更多示例时,GPT-Neo 会理解任务并考虑 end_sequence,这使得我们能够很好地控制生成的文本。
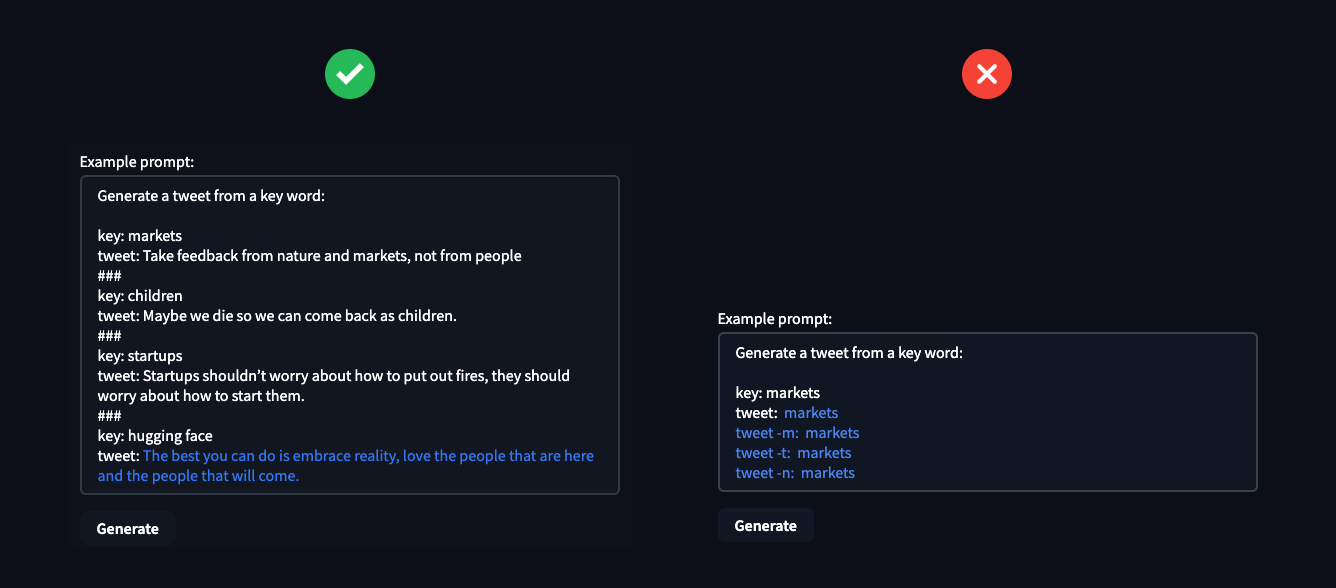
超参数 End Sequence、Token Length 和 Temperature 可用于控制模型的 text-generation,您可以利用它们来解决所需任务。Temperature 控制生成文本的随机性,较低的温度会导致较少的随机生成,而较高的温度会导致更多的随机生成。
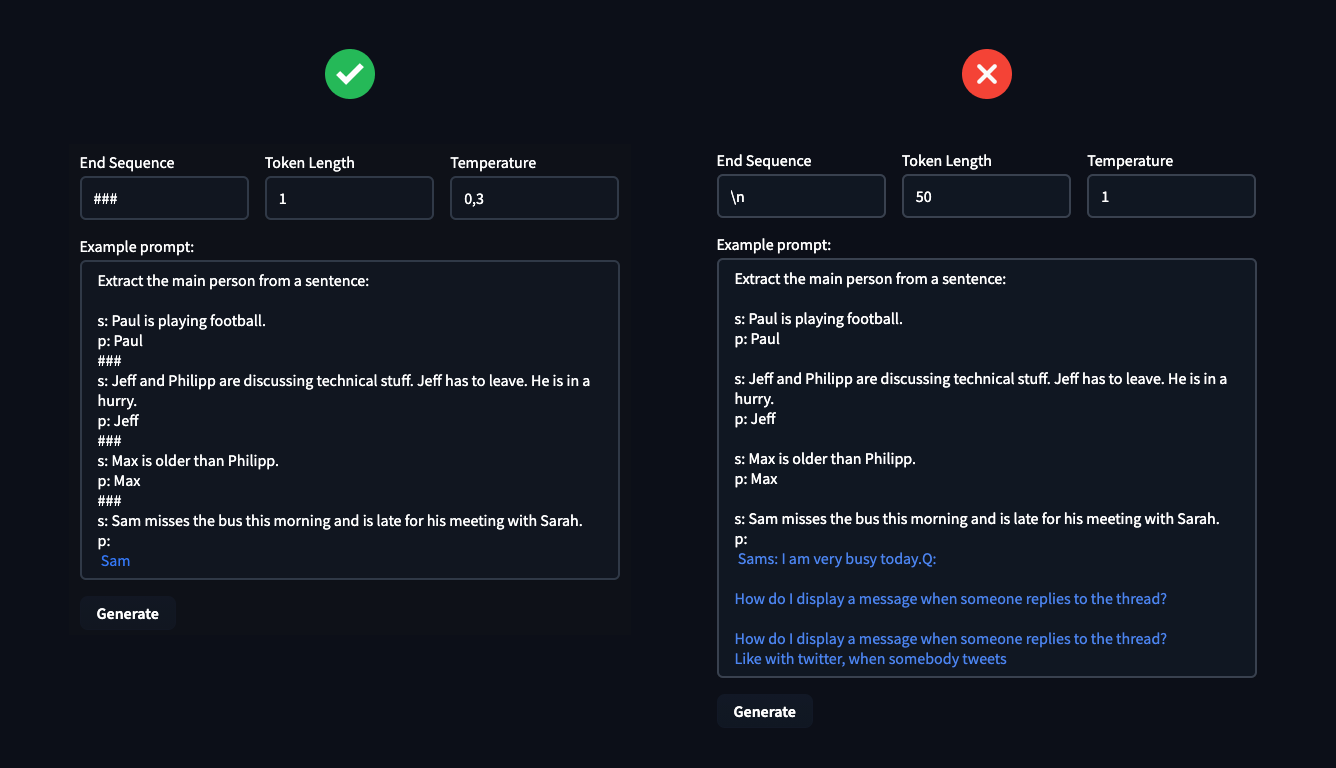
在示例中,您可以看到定义超参数的重要性。这些可以决定您是成功解决任务还是惨败。
负责任的使用
少样本学习是一种强大的技术,但也存在独特的陷阱,在设计用例时需要加以考虑。为了说明这一点,让我们考虑小部件中提供的默认 情感分析 设置。在看到三个情感分类示例后,模型在 temperature 设置为 0.1 时,在五次中预测了四次以下结果:
推文:“我是一个残疾的快乐的人”
情绪:消极
这可能会出什么问题?想象一下,您正在使用情感分析来汇总在线购物网站上的产品评论:一个可能的结果是,对残疾人有用物品可能会自动降级——这是一种自动化歧视。有关此特定问题的更多信息,我们推荐 ACL 2020 论文《NLP 模型中的社会偏见作为残疾人的障碍》。由于少样本学习更直接地依赖于从预训练中获取的信息和关联,因此它对此类故障更为敏感。
如何将伤害风险降至最低?以下是一些实用建议。
负责任使用的最佳实践
- 确保人们了解其用户体验的哪些部分依赖于机器学习系统的输出
- 如果可能,允许用户选择退出
- 提供一种机制,允许用户对模型决策提供反馈,并覆盖它
- 监控反馈,特别是模型故障,针对可能受到不成比例影响的用户群体
最需要避免的是,在没有人为干预或纠正输出的机会下,使用模型自动为用户或关于用户做出决策。欧洲的GDPR 等法规要求向用户提供对其做出的自动决策的解释。
要在您自己的应用程序中使用 GPT-Neo 或任何 Hugging Face 模型,您可以开始免费试用 🤗 Accelerated Inference API。如果您需要帮助缓解模型和人工智能系统中的偏差,或利用少样本学习,🤗 专家加速计划可以。
