训练和微调 Sentence Transformers 模型







本指南仅适用于 v3.0 之前的 Sentence Transformers。请阅读 使用 Sentence Transformers v3 训练和微调嵌入模型 以获取更新的指南。
查看此教程和配套 Notebook: ![]()
训练或微调 Sentence Transformers 模型高度依赖于可用数据和目标任务。关键在于两点
- 了解如何将数据输入模型并相应地准备数据集。
- 了解不同的损失函数以及它们与数据集的关系。
在本教程中,您将
- 通过“从零开始”创建或从 Hugging Face Hub 微调 Sentence Transformers 模型来了解其工作原理。
- 学习数据集可能具有的不同格式。
- 根据数据集格式回顾可以选择的不同损失函数。
- 训练或微调您的模型。
- 将您的模型分享到 Hugging Face Hub。
- 了解何时 Sentence Transformers 模型可能不是最佳选择。
Sentence Transformers 模型的工作原理
在 Sentence Transformer 模型中,您将可变长度的文本(或图像像素)映射到固定大小的嵌入,该嵌入表示输入的含义。要开始使用嵌入,请查看我们的之前的教程。本文主要关注文本。
Sentence Transformers 模型的工作原理如下
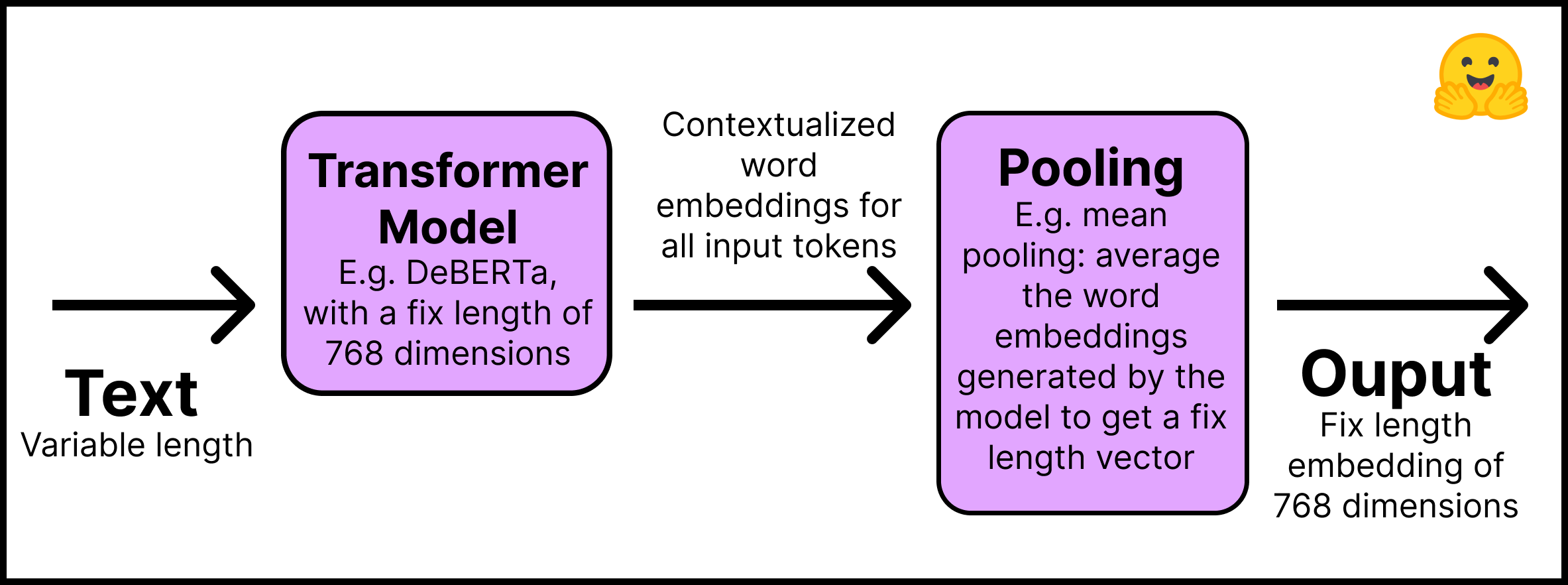
- 第一层 – 输入文本通过预训练的 Transformer 模型,该模型可以直接从 Hugging Face Hub 获取。本教程将使用“distilroberta-base”模型。Transformer 的输出是所有输入 token 的语境化词嵌入;想象一下文本中每个 token 的嵌入。
- 第二层 - 嵌入通过池化层,以获取所有文本的单个固定长度嵌入。例如,均值池化(mean pooling)对模型生成的嵌入进行平均。
此图总结了该过程
请记住使用 pip install -U sentence-transformers 安装 Sentence Transformers 库。在代码中,这个两步过程很简单
from sentence_transformers import SentenceTransformer, models
## Step 1: use an existing language model
word_embedding_model = models.Transformer('distilroberta-base')
## Step 2: use a pool function over the token embeddings
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension())
## Join steps 1 and 2 using the modules argument
model = SentenceTransformer(modules=[word_embedding_model, pooling_model])
从上面的代码可以看出,Sentence Transformers 模型由模块组成,即一系列按顺序执行的层。输入文本进入第一个模块,最终输出来自最后一个组件。正如它看起来一样简单,上述模型是 Sentence Transformers 模型的典型架构。如有必要,可以添加额外的层,例如密集层、词袋层和卷积层。
为什么不直接使用像 BERT 或 Roberta 这样的 Transformer 模型来为整个句子和文本创建嵌入呢?至少有两个原因。
- 预训练的 Transformers 模型执行语义搜索任务需要大量计算。例如,在 10,000 个句子的集合中找到最相似的对 使用 BERT 大约需要 5000 万次推理计算(约 65 小时)。相比之下,BERT Sentence Transformers 模型将时间缩短到大约 5 秒。
- 一旦训练,Transformers 模型开箱即用地创建的句子表示很差。BERT 模型将其 token 嵌入平均以创建句子嵌入 性能不如 2014 年开发的 GloVe 嵌入。
在本节中,我们正在从头开始创建一个 Sentence Transformers 模型。如果您想微调现有的 Sentence Transformers 模型,可以跳过上面的步骤并从 Hugging Face Hub 导入它。您可以在 “句子相似度” 任务中找到大多数 Sentence Transformers 模型。这里我们加载“sentence-transformers/all-MiniLM-L6-v2”模型
from sentence_transformers import SentenceTransformer
model_id = "sentence-transformers/all-MiniLM-L6-v2"
model = SentenceTransformer(model_id)
现在是最关键的部分:数据集格式。
如何准备数据集以训练 Sentence Transformers 模型
要训练 Sentence Transformers 模型,您需要以某种方式告知它两个句子具有一定的相似度。因此,数据中的每个示例都需要一个标签或结构,以使模型能够理解两个句子是相似还是不同。
不幸的是,没有一种方法可以准备数据来训练 Sentence Transformers 模型。这在很大程度上取决于您的目标和数据结构。如果您没有明确的标签(这是最可能的情况),您可以从获取句子的文档设计中推断出来。例如,同一报告中的两个句子可能比不同报告中的两个句子更具可比性。相邻的句子可能比不相邻的句子更具可比性。
此外,数据结构将影响您可以使用哪种损失函数。这将在下一节中讨论。
请记住,本帖的 配套 Notebook 已实现所有代码。
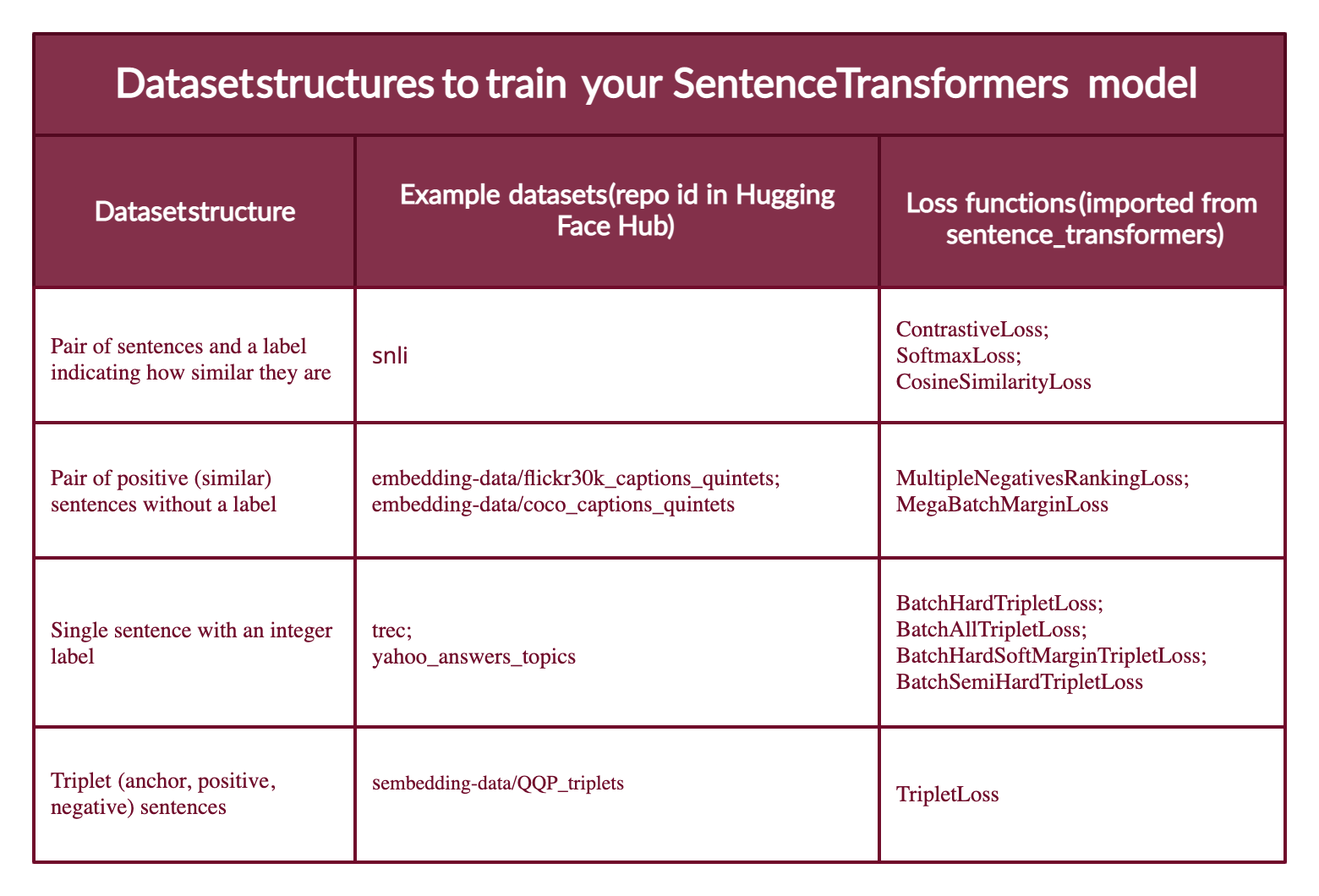
大多数数据集配置将采用以下四种形式之一(下面您将看到每个案例的示例)
- 案例 1:示例是一对句子和一个指示它们相似程度的标签。标签可以是整数或浮点数。此案例适用于最初为自然语言推理(NLI)准备的数据集,因为它们包含带有标签的句子对,指示它们是否相互推断。
- 案例 2:示例是一对正(相似)句子,没有标签。例如,释义对、全文及其摘要对、重复问题对、(
查询,响应) 对,或 (源语言,目标语言) 对。自然语言推理数据集也可以通过配对推断句子来以此方式格式化。将数据采用这种格式非常有用,因为您可以使用MultipleNegativesRankingLoss,它是 Sentence Transformers 模型最常用的损失函数之一。 - 案例 3:示例是一个带整数标签的句子。这种数据格式可以很容易地通过损失函数转换为三个句子(三元组),其中第一个是“锚点”,第二个是与锚点相同类别的“正例”,第三个是不同类别的“负例”。每个句子都有一个整数标签,指示其所属的类别。
- 案例 4:示例是一个三元组(锚点、正例、负例),没有句子的类别或标签。
例如,在本教程中,您将使用第四种情况下的数据集训练 Sentence Transformer。然后,您将使用第二种情况下的数据集配置对其进行微调(请参阅此博客的 配套 Notebook)。
请注意,Sentence Transformers 模型可以通过人工标注(案例 1 和 3)或通过文本格式自动推断标签(主要是案例 2;尽管案例 4 不需要标签,但除非您像 MegaBatchMarginLoss 函数那样处理它,否则很难找到三元组数据)。
Hugging Face Hub 上有针对上述每种情况的数据集。此外,Hub 中的数据集具有数据集预览功能,允许您在下载数据集之前查看其结构。以下是每个案例的示例数据集
案例 1:如果您有(或制造)一个指示两个句子之间相似程度的标签,例如 {0,1,2},其中 0 表示矛盾,2 表示蕴涵,则可以使用与自然语言推理相同的设置。请查看 SNLI 数据集 的结构。
案例 2:句子压缩数据集 包含由正向对组成的示例。如果您的数据集中每个示例有超过两个正向句子,例如 COCO 标题 或 Flickr30k 标题 数据集中的五元组,您可以将示例格式化为具有不同的正向对组合。
案例 3:TREC 数据集 具有指示每个句子类别的整数标签。Yahoo Answers Topics 数据集 中的每个示例都包含三个句子和一个指示其主题的标签;因此,每个示例可以分为三部分。
案例 4:Quora Triplet 数据集 包含没有标签的三元组(锚点、正例、负例)。
下一步是将数据集转换为 Sentence Transformers 模型可以理解的格式。模型不能接受原始字符串列表。每个示例都必须转换为 sentence_transformers.InputExample 类,然后转换为 torch.utils.data.DataLoader 类以批量处理和打乱示例。
使用 pip install datasets 安装 Hugging Face Datasets。然后使用 load_dataset 函数导入数据集
from datasets import load_dataset
dataset_id = "embedding-data/QQP_triplets"
dataset = load_dataset(dataset_id)
本指南使用了一个无标签的三元组数据集,即上述第四种情况。
使用 datasets 库,您可以探索数据集
print(f"- The {dataset_id} dataset has {dataset['train'].num_rows} examples.")
print(f"- Each example is a {type(dataset['train'][0])} with a {type(dataset['train'][0]['set'])} as value.")
print(f"- Examples look like this: {dataset['train'][0]}")
输出
- The embedding-data/QQP_triplets dataset has 101762 examples.
- Each example is a <class 'dict'> with a <class 'dict'> as value.
- Examples look like this: {'set': {'query': 'Why in India do we not have one on one political debate as in USA?', 'pos': ['Why can't we have a public debate between politicians in India like the one in US?'], 'neg': ['Can people on Quora stop India Pakistan debate? We are sick and tired seeing this everyday in bulk?'...]
您可以看到 `query` (锚点) 只有一个句子,`pos` (正例) 是一个句子列表 (我们打印的只有一个句子),`neg` (负例) 有多个句子列表。
将示例转换为 InputExample。为简单起见,(1) 在 embedding-data/QQP_triplets 数据集中将只使用一个正例和一个负例。(2) 我们将只使用可用示例的 1/2。通过增加示例数量,您可以获得更好的结果。
from sentence_transformers import InputExample
train_examples = []
train_data = dataset['train']['set']
# For agility we only 1/2 of our available data
n_examples = dataset['train'].num_rows // 2
for i in range(n_examples):
example = train_data[i]
train_examples.append(InputExample(texts=[example['query'], example['pos'][0], example['neg'][0]]))
将训练示例转换为 Dataloader。
from torch.utils.data import DataLoader
train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=16)
下一步是选择与数据格式兼容的合适损失函数。
训练 Sentence Transformers 模型的损失函数
还记得您的数据可能有四种不同格式吗?每种格式都将对应一个不同的损失函数。
案例 1:句子对和一个指示它们相似程度的标签。损失函数进行优化,使得 (1) 标签最接近的句子在向量空间中距离较近,(2) 标签最远的句子距离尽可能远。损失函数取决于标签的格式。如果它是整数,使用 ContrastiveLoss 或 SoftmaxLoss;如果它是浮点数,您可以使用 CosineSimilarityLoss。
案例 2:如果只有两个相似的句子(两个正例)且没有标签,则可以使用 MultipleNegativesRankingLoss 函数。MegaBatchMarginLoss 也可以使用,它会将您的示例转换为三元组 (anchor_i, positive_i, positive_j),其中 positive_j 用作负例。
案例 3:当您的样本是 [锚点, 正例, 负例] 形式的三元组,并且每个样本都有一个整数标签时,损失函数会优化模型,使锚点和正例句子在向量空间中比锚点和负例句子更接近。您可以使用 BatchHardTripletLoss,它要求数据用整数标记(例如,标签 1、2、3),假设相同标签的样本是相似的。因此,锚点和正例必须具有相同的标签,而负例必须具有不同的标签。或者,您可以使用 BatchAllTripletLoss、BatchHardSoftMarginTripletLoss 或 BatchSemiHardTripletLoss。它们之间的区别超出了本教程的范围,但可以在 Sentence Transformers 文档中查看。
案例 4:如果三元组中的每个句子都没有标签,则应使用 TripletLoss。此损失函数旨在最小化锚点和正例句子之间的距离,同时最大化锚点和负例句子之间的距离。
此图总结了不同类型的数据集格式、Hub 中的示例数据集及其合适的损失函数。
最困难的部分是概念上选择合适的损失函数。在代码中,只有两行
from sentence_transformers import losses
train_loss = losses.TripletLoss(model=model)
一旦数据集采用所需格式并设置了合适的损失函数,拟合和训练 Sentence Transformers 就很简单了。
如何训练或微调 Sentence Transformer 模型
“SentenceTransformers 的设计宗旨是让您轻松地微调自己的句子/文本嵌入模型。它提供了大多数构建块,您可以将它们组合起来,为您的特定任务调整嵌入。” - Sentence Transformers 文档。
训练或微调过程如下所示
model.fit(train_objectives=[(train_dataloader, train_loss)], epochs=10)
请记住,如果您正在微调现有的 Sentence Transformers 模型(请参阅 配套 Notebook),您可以直接调用其 fit 方法。如果这是一个新的 Sentence Transformers 模型,您必须首先像在“Sentence Transformers 模型的工作原理”一节中那样定义它。
就是这样;您已经拥有了一个新的或改进的 Sentence Transformers 模型!您想将其分享到 Hugging Face Hub 吗?
首先,登录到 Hugging Face Hub。您需要在您的 账户设置 中创建一个 write 令牌。然后有两种登录方式
在终端中输入
huggingface-cli login并输入您的令牌。如果在 Python Notebook 中,您可以使用
notebook_login。
from huggingface_hub import notebook_login
notebook_login()
然后,您可以通过调用训练模型的 save_to_hub 方法来分享您的模型。默认情况下,模型将上传到您的帐户。但是,您可以通过在 organization 参数中传递组织名称来上传到组织。save_to_hub 会自动生成模型卡、推理小部件、示例代码片段和更多详细信息。您可以使用参数 train_datasets 自动将您用于训练模型的数据集列表添加到 Hub 的模型卡中
model.save_to_hub(
"distilroberta-base-sentence-transformer",
organization= # Add your username
train_datasets=["embedding-data/QQP_triplets"],
)
在 配套 Notebook 中,我使用 embedding-data/sentence-compression 数据集和 MultipleNegativesRankingLoss 损失函数微调了相同的模型。
Sentence Transformers 的局限性是什么?
Sentence Transformers 模型在语义搜索方面比简单的 Transformers 模型效果好得多。然而,Sentence Transformers 模型在哪些方面表现不佳呢?如果您的任务是分类,那么使用句子嵌入是错误的方法。在这种情况下,🤗 Transformers 库 将是更好的选择。
额外资源
- 嵌入式入门.
- 理解语义搜索.
- 开始您的第一个 Sentence Transformers 模型.
- 使用 Sentence Transformers 生成播放列表.
- Hugging Face + Sentence Transformers 文档.
感谢阅读!祝您嵌入愉快。






