在 GCP 上使用第 5 代至强处理器对语言模型性能进行基准测试








TL;DR: 我们在两个基于 Google Cloud Compute Engine Xeon 的 CPU 实例(N2 和 C4)上,对两种代表性的代理 AI 工作负载组件(文本嵌入和文本生成)进行了基准测试。结果一致表明,在文本嵌入方面,C4 的吞吐量比 N2 高 10 到 24 倍;在文本生成方面,C4 的吞吐量比 N2 高 2.3 到 3.6 倍。考虑到价格,C4 的每小时价格约为 N2 的 1.3 倍,从这个意义上讲,在文本嵌入方面,C4 在总拥有成本 (TCO) 上比 N2 具有 7 到 19 倍的优势,在文本生成方面具有 1.7 到 2.9 倍的 TCO 优势。结果表明,可以将轻量级代理 AI 解决方案完全部署在 CPU 上。
引言
人们相信人工智能的下一个前沿是代理 AI。这种新范式使用 感知-推理-行动 管道,将 LLM 复杂的推理和迭代规划能力与强大的上下文理解增强功能相结合。上下文理解能力由向量数据库和传感器输入等工具提供,以创建更具上下文感知能力的 AI 系统,这些系统可以自主解决复杂的多步骤问题。此外,LLM 的函数调用能力使得 AI 代理能够直接采取行动,远远超出了聊天机器人提供的聊天功能。代理 AI 为提高各行业的生产力和运营带来了令人兴奋的前景。
人们正在将越来越多的工具引入代理 AI 系统,其中大多数工具现在都在 CPU 上运行,这带来了一个担忧,即在这种范式中,主机-加速器之间的流量开销将不可忽略。与此同时,模型构建者和供应商正在构建更小但功能强大的小型语言模型 (SLM),最新的例子是 Meta 的 1B 和 3B llama3.2 模型,它们具有先进的多语言文本生成和工具调用能力。此外,CPU 正在发展并开始提供更多的 AI 支持,英特尔在其第四代至强 CPU 中引入了新的 AI 张量加速器——英特尔高级矩阵扩展 (AMX)。将这三条线索结合起来,看看 CPU 承载整个代理 AI 系统(尤其是当它使用 SLM 时)的潜力将是很有趣的。
在这篇文章中,我们将对代理 AI 的两个代表性组件进行基准测试:文本嵌入和文本生成,并比较 CPU 在这两个组件上的代际性能提升。我们选择了 Google Cloud Compute Engine C4 实例和 N2 实例进行比较。其背后的逻辑是:C4 采用 第 5 代英特尔至强处理器(代号 Emerald Rapids),这是 Google Cloud 上可用的最新一代至强 CPU,它集成了英特尔 AMX 以提升 AI 性能;而 N2 采用 第 3 代英特尔至强处理器(代号 Ice Lake),这是 Google Cloud 上上一代至强 CPU,它只有 AVX-512 而没有 AMX。我们将展示 AMX 的优势。
我们将使用 Hugging Face 的统一基准测试库 optimum-benchmark 来测量性能,该库支持多后端和多设备。基准测试在 optimum-intel 后端运行。optimum-intel 是 Hugging Face 的加速库,用于加速英特尔架构(CPU、GPU)上的端到端管道。我们的基准测试用例如下:
- 对于文本嵌入,我们使用
WhereIsAI/UAE-Large-V1模型,输入序列长度为 128,批量大小从 1 扫到 128 - 对于文本生成,我们使用
meta-llama/Llama-3.2-3模型,输入序列长度为 256,输出序列长度为 32,批量大小从 1 扫到 64
创建实例
N2
访问 Google Cloud 控制台,并在您的项目下点击 创建虚拟机。然后,按照以下步骤创建一个 96 核的实例,它对应一个英特尔 Ice Lake CPU 插槽。
- 在
机器配置选项卡中选择 N2,并将机器类型指定为n2-standard-96。然后您需要按以下图片设置CPU 平台: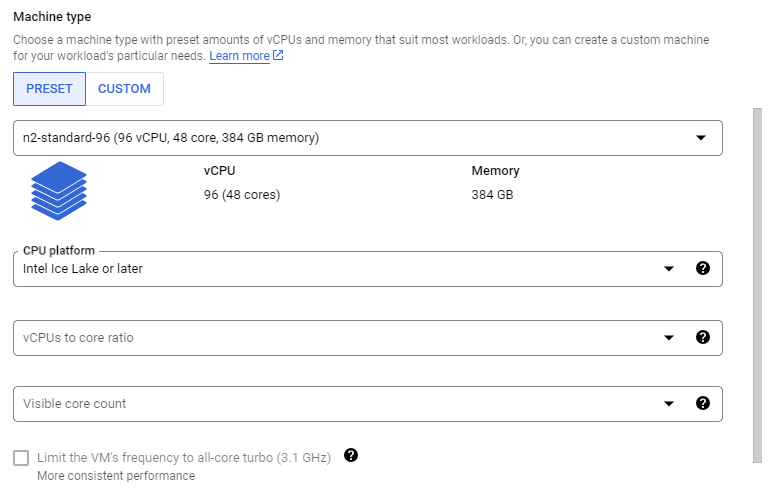
- 将
操作系统和存储选项卡配置如下: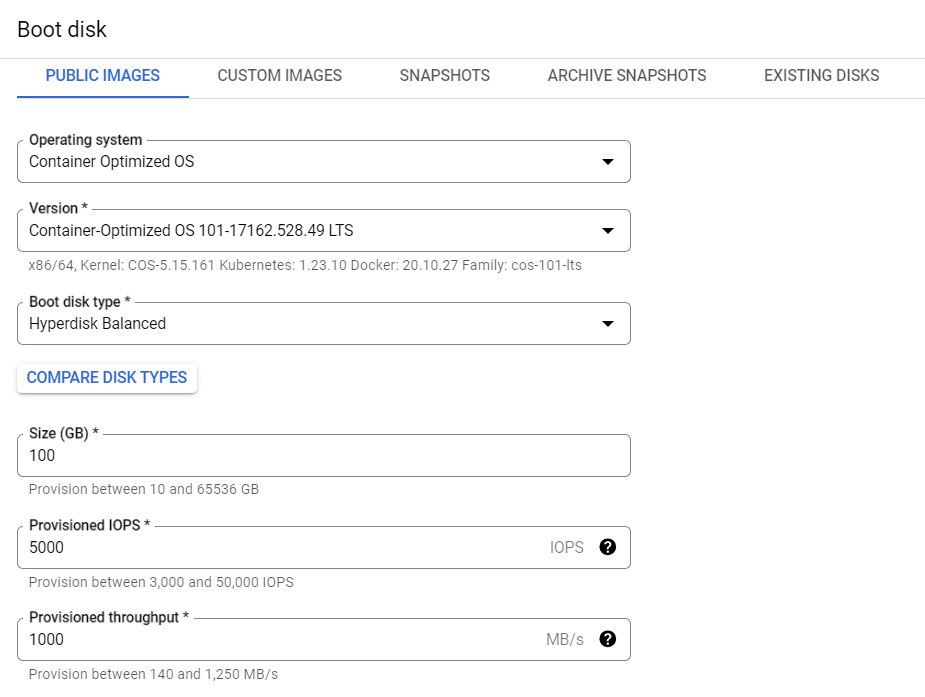
- 其他配置保持默认
- 点击
创建按钮
现在,您拥有一个 N2 实例。
C4
按照以下步骤创建一个 96 核的实例,它对应一个英特尔 Emerald Rapids 插槽。请注意,本文中我们使用 C4 和 N2 相同的 CPU 核心数,以确保进行同核数基准测试。
- 在
机器配置选项卡中选择 C4,并将机器类型指定为c4-standard-96。您还可以设置CPU 平台并开启全核睿频以使性能更稳定:
- 将
操作系统和存储配置与 N2 相同 - 其他配置保持默认
- 点击
创建按钮
现在,您拥有一个 C4 实例。
设置环境
请按照以下步骤轻松设置环境。为确保可复现性,我们列出了命令中使用的版本和提交。
- SSH 连接到实例
$ git clone https://github.com/huggingface/optimum-benchmark.git$ cd ./optimum-benchmark$ git checkout d58bb2582b872c25ab476fece19d4fa78e190673$ cd ./docker/cpu$ sudo docker build . -t <your_docker_image_tag>$ sudo docker run -it --rm --privileged -v /home/<your_home_folder>:/workspace <your_docker_image_tag> /bin/bash
现在我们进入容器,执行以下步骤
$ pip install "optimum-intel[ipex]"@git+https://github.com/huggingface/optimum-intel.git@6a3b1ba5924b0b017b0b0f5de5b10adb77095b$ pip install torch==2.3.1 torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu$ python -m pip install intel-extension-for-pytorch==2.3.10$ cd /workspace/optimum-benchmark$ pip install .[ipex]$ export OMP_NUM_THREADS=48$ export KMP_AFFINITY=granularity=fine,compact,1,0$ export KMP_BLOCKTIME=1$ pip install huggingface-hub$ huggingface-cli login,然后输入您的 Hugging Face token 以访问 llama 模型
基准测试
文本嵌入
您需要将 optimum-benchmark 目录中的 examples/ipex_bert.yaml 更新如下,以基准测试 WhereIsAI/UAE-Large-V1。我们将 numa 绑定更改为 0,1,因为 N2 和 C4 每个插槽都有 2 个 NUMA 域,您可以使用 lscpu 再次检查。
--- a/examples/ipex_bert.yaml
+++ b/examples/ipex_bert.yaml
@@ -11,8 +11,8 @@ name: ipex_bert
launcher:
numactl: true
numactl_kwargs:
- cpunodebind: 0
- membind: 0
+ cpunodebind: 0,1
+ membind: 0,1
scenario:
latency: true
@@ -26,4 +26,4 @@ backend:
no_weights: false
export: true
torch_dtype: bfloat16
- model: bert-base-uncased
+ model: WhereIsAI/UAE-Large-V1
然后,运行基准测试:$ optimum-benchmark --config-dir examples/ --config-name ipex_bert
文本生成
您可以按如下所示更新 examples/ipex_llama.yaml 以对 meta-llama/Llama-3.2-3 进行基准测试。
--- a/examples/ipex_llama.yaml
+++ b/examples/ipex_llama.yaml
@@ -11,8 +11,8 @@ name: ipex_llama
launcher:
numactl: true
numactl_kwargs:
- cpunodebind: 0
- membind: 0
+ cpunodebind: 0,1
+ membind: 0,1
scenario:
latency: true
@@ -34,4 +34,4 @@ backend:
export: true
no_weights: false
torch_dtype: bfloat16
- model: TinyLlama/TinyLlama-1.1B-Chat-v1.0
+ model: meta-llama/Llama-3.2-3B
然后,运行基准测试:$ optimum-benchmark --config-dir examples/ --config-name ipex_llama
结果与结论
文本嵌入结果
在文本嵌入基准测试案例中,GCP C4 实例的吞吐量比 N2 高约 10 倍至 24 倍。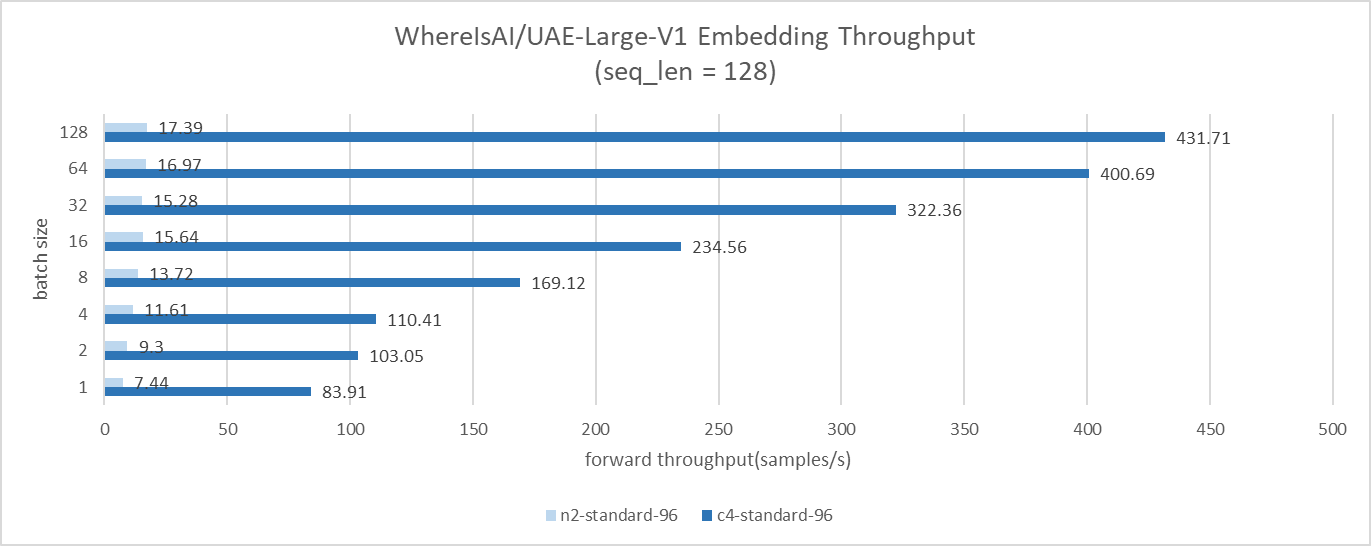
文本生成结果
C4 实例在文本生成基准测试中始终表现出比 N2 高约 2.3 倍至 3.6 倍的吞吐量。在批量大小为 1 到 16 的情况下,吞吐量提高了 13 倍,而延迟没有显著降低。这使得并发查询服务成为可能,而无需牺牲用户体验。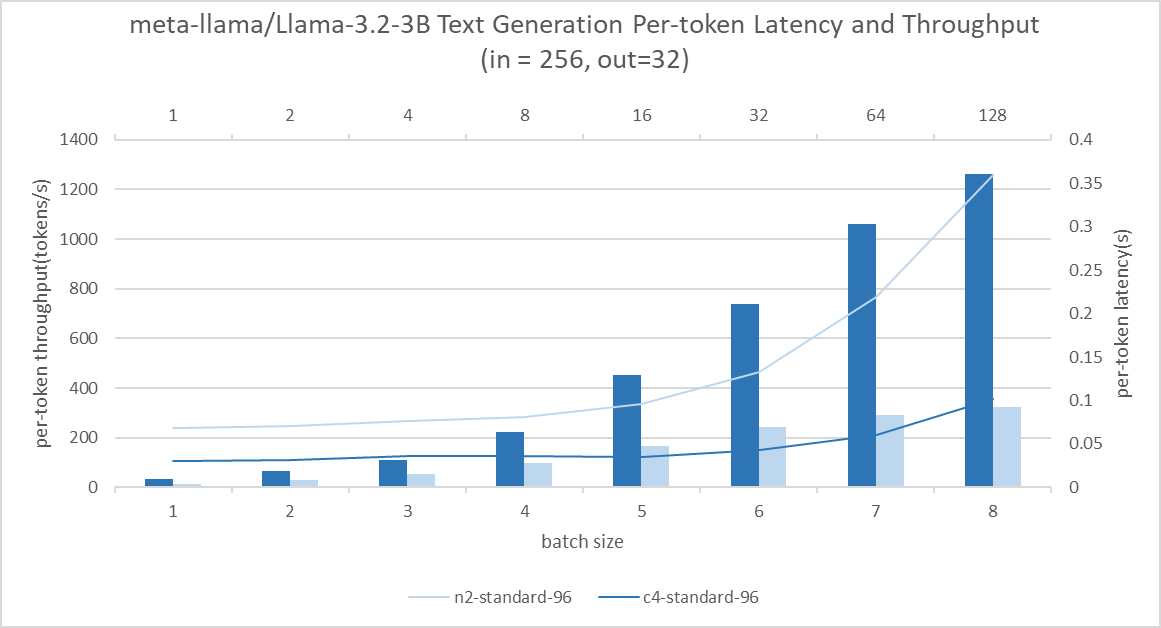
结论
在这篇文章中,我们对 Google Cloud Compute Engine CPU 实例(C4 和 N2)上的两个代表性代理 AI 工作负载进行了基准测试。结果显示,得益于 Intel Xeon CPU 上 AMX 和内存能力的改进,性能得到了显著提升。Intel 在一个月前发布了 带有 P 核的 Xeon 6 处理器(代号 Granite Rapids),它在 Llama 3 中提供了约 2 倍的性能提升。我们相信,有了新的 Granite Rapids CPU,我们可以探索将轻量级代理 AI 解决方案完全部署在 CPU 上,以避免密集的宿主-加速器流量开销。一旦 Google Cloud Compute Engine 提供 Granite Rapids 实例,我们将对其进行基准测试并报告结果。
感谢阅读!

