🤗量化入门,💗🧑🍳烹制








量化是一组技术,用于降低深度学习模型的精度,使模型更小,训练更快。如果你不理解这句话,别担心,在这篇博客文章的最后你会明白。在这篇博客文章中,我们将介绍...
- 什么是精度,为什么我们需要量化,以及一个简单的量化示例;
- GPTQ 量化;
- 4/8 位(bitsandbytes)量化。
冲呀!
精度
精度可以定义为表示一个数字所使用的有效数字或位数。它是衡量一个数字可以被**精确**表示的程度,或者在表示中可以保留多少细节(在我们的例子中,是二进制表示)。
在这篇博客文章中,我不会详细介绍用于精度的二进制表示如何工作,但你可以查看这篇直观的博客文章来了解它的工作原理。
我们根据数字本身的不同,以不同的数据类型表示数字。每种数据类型都有其可以表示的数字范围。常见的数据类型包括:
| 数据类型 | 范围 | 精度 |
|---|---|---|
| FP32(单精度) | 约 ±1.4013 x 10^-45 到 ±3.4028 x 10^38 | 7 位小数 |
| FP16(半精度) | 约 ±5.96 x 10^-8 到 ±6.55 x 10^4 | 3-4 位小数 |
| FP8(自定义 8 位浮点) | 动态 | 动态 |
| Int8(8 位整数) | -128 到 127(有符号)或 0 到 255(无符号) | 无小数 |
一个数字需要表示得越精确,它所占用的内存就越多。在深度学习中,我们使用浮点表示(FP32/16/8...)来表示权重。虽然 FP32 表示能提供更高的精度和准确性,但模型大小会变得更大,并且训练或推理(取决于量化类型)期间的计算会变慢。因此,需要降低精度,这也被称为量化。它是一种有损压缩形式,我们压缩的信息越多,性能损失就越大。
一种非常简单的量化技术是将较大范围的量化类型缩放/投影到较小的尺度,例如(FP32 到 int8)。这看起来如下图所示 👇
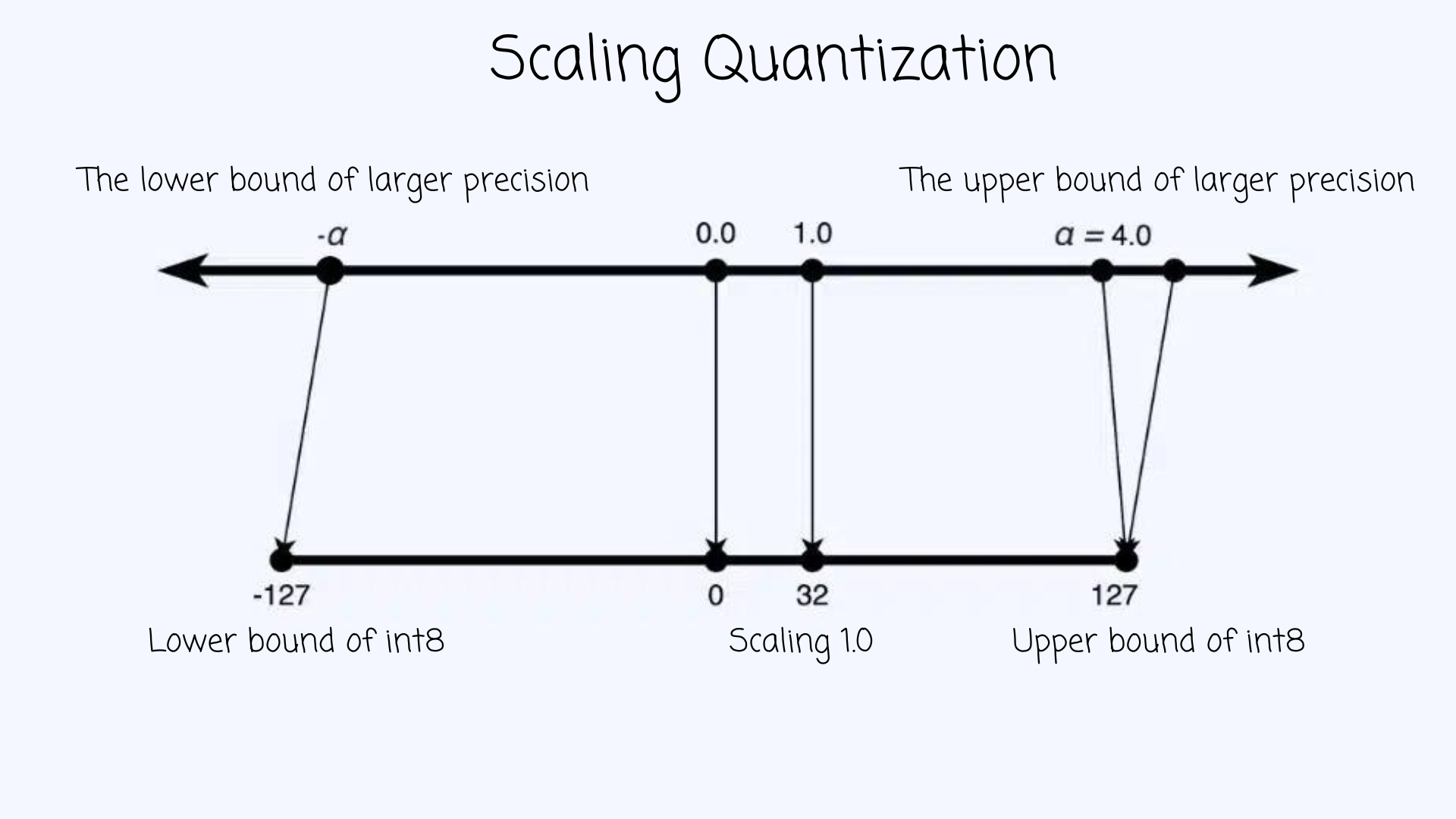
对于给定数据类型范围 [-α, α],我们可以使用以下公式投影给定值
然而,这种方法有不同的缺点,例如在训练和推理过程中引入开销,降低性能,并且对数据中的分布变化敏感。尽管它非常简单,但在不同的混合精度训练方法中被大量使用。
主要有两种量化方法 👇
- 训练后量化:这些方法侧重于在模型训练后降低精度。由于它更容易理解,我们将在本博客文章中主要介绍这种方法,尽管它的性能不如量化感知训练。
- 量化感知训练:这种方法允许量化模型,然后对模型进行微调,以减少量化引起的性能下降,或者量化可以在训练期间进行。
最先进的方法正试图克服上述问题。我们现在将讨论它们以及如何通过 🤗 生态系统中的工具(transformers、TGI、optimum 和 PEFT)使用它们。
GPTQ 量化
GPTQ 是一种训练后量化方法,通过校准数据集使模型更小。GPTQ 的核心思想非常简单:它通过找到权重的压缩版本来量化每个权重,以使均方误差最小,如下图所示 👇
给定一个层 及其权重矩阵 和层输入 ,找到量化权重
在 GPTQ 中,我们一次性进行后量化,这既能节省内存又能加快推理速度(与我们稍后将介绍的 4/8 位量化不同)。AutoGPTQ 是一个支持 GPTQ 量化的库。它已集成到 🤗 生态系统中的各种库中,用于量化模型、使用/服务已量化模型或进一步微调模型。让我们看看如何做到这些。
首先,安装 AutoGPTQ
pip install auto-gptq # for cuda versions other than 11.7, refer to installation guide in above link
pip install transformers optimum peft
- 你可以在 Hugging Face Hub 上运行给定的 GPTQ 模型,如下所示(在此处查找它们:这里)👇
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("TheBloke/Llama-2-7b-Chat-GPTQ", torch_dtype=torch.float16, device_map="auto")
你可以像下面这样量化任何 transformer 模型 👇
from transformers import AutoModelForCausalLM, AutoTokenizer, GPTQConfig
model_id = "facebook/opt-125m"
tokenizer = AutoTokenizer.from_pretrained(model_id)
quantization_config = GPTQConfig(bits=4, dataset = "c4", tokenizer=tokenizer)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", quantization_config=quantization_config)
- 你可以使用 PEFT 在这个gist中进一步微调给定的 GPTQ 模型。
- 你可以使用 text-generation-inference 量化和提供已经用 GPTQ 方法量化的模型。它在底层不使用 AutoGPTQ 库。按照此处的说明安装 TGI 后,你可以像下面这样运行你在 hub 上找到的 GPTQ 模型 👇
docker run --gpus all --shm-size 1g -p 8080:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:latest --model-id $model --quantize gptq
要仅使用校准数据集运行量化,只需运行
text-generation-server quantize tiiuae/falcon-40b /data/falcon-40b-gptq
您可以通过运行 text-generation-server quantize --help 了解更多量化选项。
使用 bitsandbytes 进行 4/8 位量化
bitsandbytes 是一个用于对模型进行 8 位和 4 位量化的库。它可以在训练期间用于混合精度训练,也可以在推理前使用,以使模型更小。
8 位量化使数十亿参数规模的模型能够适应更小的硬件,而不会降低性能。8 位量化工作原理如下 👇
- 从输入隐藏状态中按列提取较大的值(离群值)。
- 对 FP16 中的离群值和 int8 中的非离群值进行矩阵乘法。
- 将非离群值结果放大以将值拉回到 FP16,并将其添加到 FP16 中的离群值结果中。

所以本质上,我们执行矩阵乘法以节省精度,然后将非离群值结果拉回 FP16,而不会在非离群值的初始值和缩放回的值之间产生很大的差异。您可以在下面看到一个示例 👇
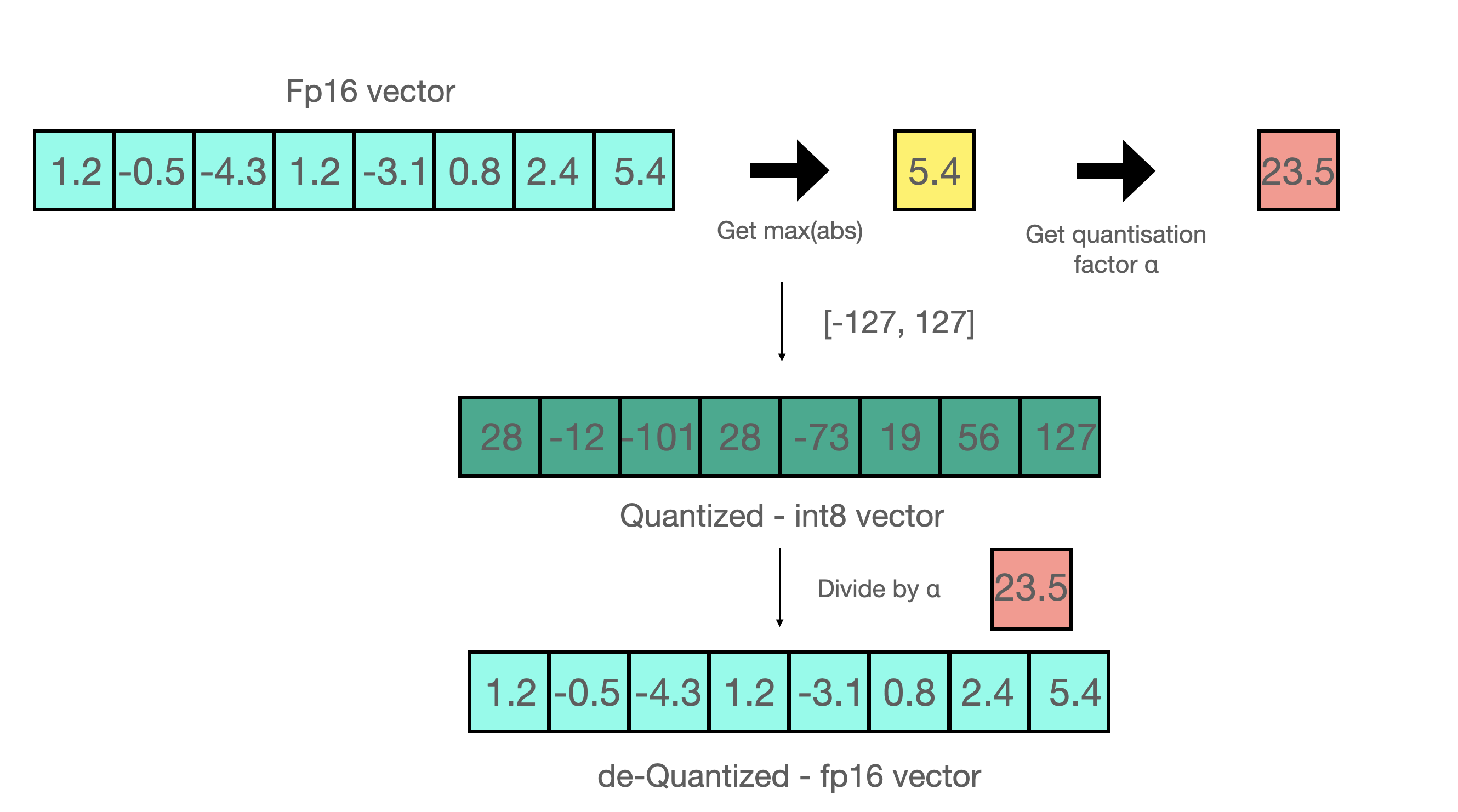
您可以像下面这样安装 bitsandbytes 👇
pip install bitsandbytes
要在 transformers 中以 8 位加载模型,只需运行 👇
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_8bit = AutoModelForCausalLM.from_pretrained(name, device_map="auto", load_in_8bit=True)
tokenizer = AutoTokenizer.from_pretrained(name)
encoded_input = tokenizer(text, return_tensors='pt')
output_sequences = model.generate(input_ids=encoded_input['input_ids'].cuda())
print(tokenizer.decode(output_sequences[0], skip_special_tokens=True))
bitsandbytes 8 位量化的一个缺点是推理速度比 GPTQ 慢。
4 位浮点(FP4)和 4 位 NormalFloat(NF4)是两种与 QLoRA 技术(一种参数高效微调技术)一起使用的数据类型。这些数据类型也可以用于在不使用 QLoRA 的情况下减小预训练模型的大小。TGI 基本上在推理前使用这些数据类型进行训练后量化。
与 8 位加载类似,您可以在 4 位中加载 transformers 模型,如下所示 👇
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_4bit=True, device_map="auto")
在 TGI 中,您可以通过将 --quantize 与以下值一起传递来使用 bitsandbytes 量化技术,以实现不同的量化方法
- 用于 8 位量化的 bitsandbytes
- 用于 4 位 NormalFloat 的 bitsandbytes-nf4
- 用于 4 位的 bitsandbytes-fp4,如下所示 👇
docker run --gpus all --shm-size 1g -p 8080:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:latest --model-id $model --quantize bitsandbytes
有用资源
您可以通过以下链接了解更多上述概念。





