笔记本上的聊天机器人:Intel Meteor Lake 上的 Phi-2












大型语言模型 (LLM) 因其令人印象深刻的能力而需要大量的计算能力,这在个人电脑上很少能得到。因此,我们别无选择,只能将它们部署在本地或云中托管的强大定制 AI 服务器上。
为什么本地 LLM 推理是可取的
如果我们能在普通的个人电脑上运行最先进的开源 LLM 会怎么样?我们难道不能享受到以下好处吗?
- 提高隐私性:我们的数据不会被发送到外部 API 进行推理。
- 更低的延迟:我们可以节省网络往返时间。
- 离线工作:我们可以脱机工作(常旅客的梦想!)。
- 更低的成本:我们不会在 API 调用或模型托管上花费任何费用。
- 可定制性:每个用户都可以找到最适合他们日常工作的模型,甚至可以对它们进行微调或使用本地检索增强生成(RAG)来提高相关性。
这一切听起来确实令人兴奋。那我们为什么还没有开始呢?回到我们最初的声明,您的典型价格合理的笔记本电脑没有足够的计算能力来以可接受的性能运行 LLM。看不到数千核 GPU,也没有闪电般快速的高带宽内存。
那是不是就没戏了?当然不是。
为什么本地 LLM 推理现在成为可能
没有什么人类思维无法做得更小、更快、更优雅、更具成本效益。近几个月来,人工智能社区一直在努力缩小模型,同时不损害其预测质量。以下三个领域令人兴奋:
硬件加速:现代 CPU 架构嵌入了专门用于加速最常见的深度学习算子的硬件,例如矩阵乘法或卷积,从而在 AI PC 上实现了新的生成式 AI 应用程序,并显著提高了它们的速度和效率。
小型语言模型(SLM):得益于创新的架构和训练技术,这些模型与大型模型不相上下甚至更优。由于参数更少,推理所需的计算和内存更少,使其成为资源受限环境的绝佳选择。
量化:量化是通过减少模型权重和激活的位宽(例如,从 16 位浮点(`fp16`)到 8 位整数(`int8`))来降低内存和计算需求的过程。减少位数意味着生成的模型在推理时所需的内存更少,从而加快了内存密集型步骤(如文本生成时的解码阶段)的延迟。此外,当权重和激活都进行量化时,由于整数运算,矩阵乘法等操作可以更快地执行。
在本文中,我们将利用上述所有技术。我们将从 Microsoft Phi-2 模型开始,借助我们 Optimum Intel 库中集成的 Intel OpenVINO,对模型权重应用 4 位量化。然后,我们将在搭载 Intel Meteor Lake CPU 的中端笔记本电脑上运行推理。
注意:如果您有兴趣对权重和激活都进行量化,您可以在我们的 文档 中找到更多信息。
开始工作吧。
英特尔 Meteor Lake
英特尔 Meteor Lake 于 2023 年 12 月发布,现已更名为 酷睿 Ultra,这是一种为高性能笔记本电脑优化的新 架构。
作为英特尔首款采用芯片组架构的客户端处理器,Meteor Lake 包含:
一个高能效 CPU,最多拥有 16 个核心,
一个集成 GPU (iGPU),最多拥有 8 个 Xe 核心,每个核心配备 16 个 Xe 向量引擎 (XVE)。顾名思义,XVE 可以对 256 位向量执行向量操作。它还实现了 DP4a 指令,该指令计算两个 4 字节值向量的点积,将结果存储在 32 位整数中,并将其添加到第三个 32 位整数中。
神经网络处理单元(NPU),这是英特尔架构的首次尝试。NPU 是专为高效客户端 AI 设计的专用 AI 引擎。它经过优化,可高效处理要求苛刻的 AI 计算,从而为主 CPU 和图形处理器腾出资源,用于其他任务。与使用 CPU 或 iGPU 执行 AI 任务相比,NPU 的设计更加节能。
为了运行下面的演示,我们选择了一款搭载 酷睿 Ultra 7 155H CPU 的 中端笔记本电脑。现在,让我们选择一个可爱的小型语言模型在这台笔记本电脑上运行。
注意:要在 Linux 上运行此代码,请按照 这些说明 安装 GPU 驱动程序。
微软 Phi-2 模型
Phi-2 于 2023 年 12 月发布,是一个拥有 27 亿参数的模型,用于文本生成。
根据已报告的基准测试,Phi-2 尽管规模较小,但其性能超越了一些最佳的 70 亿和 130 亿 LLM,甚至与更大的 Llama-2 70B 模型旗鼓相当。
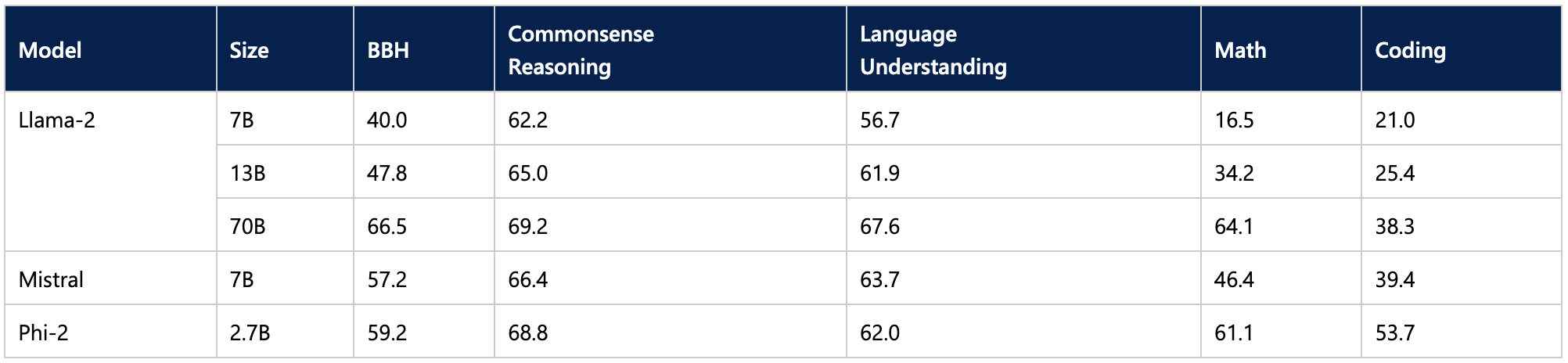
这使得它成为笔记本电脑推理的一个令人兴奋的候选模型。好奇的读者可能还想尝试使用 11 亿参数的 TinyLlama 模型。
现在,让我们看看如何缩小模型,使其更小更快。
使用 Intel OpenVINO 和 Optimum Intel 进行量化
Intel OpenVINO 是一个开源工具包,用于在许多 Intel 硬件平台(Github、文档)上优化 AI 推理,特别是通过模型量化。
通过与英特尔合作,我们已将 OpenVINO 集成到 Optimum Intel 中,Optimum Intel 是我们专门用于加速英特尔平台上 Hugging Face 模型的开源库(Github、文档)。
首先,请确保您已安装最新版本的 optimum-intel 以及所有必要的库
pip install --upgrade-strategy eager optimum[openvino,nncf]
这种集成使得将 Phi-2 量化到 4 位变得非常简单。我们定义一个量化配置,设置优化参数,然后从 hub 加载模型。一旦模型被量化和优化,我们将其本地存储。
from transformers import AutoTokenizer, pipeline
from optimum.intel import OVModelForCausalLM, OVWeightQuantizationConfig
model_id = "microsoft/phi-2"
device = "gpu"
# Create the quantization configuration with desired quantization parameters
q_config = OVWeightQuantizationConfig(bits=4, group_size=128, ratio=0.8)
# Create OpenVINO configuration with optimal settings for this model
ov_config = {"PERFORMANCE_HINT": "LATENCY", "CACHE_DIR": "model_cache", "INFERENCE_PRECISION_HINT": "f32"}
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = OVModelForCausalLM.from_pretrained(
model_id,
export=True, # export model to OpenVINO format: should be False if model already exported
quantization_config=q_config,
device=device,
ov_config=ov_config,
)
# Compilation step : if not explicitly called, compilation will happen before the first inference
model.compile()
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
results = pipe("He's a dreadful magician and")
save_directory = "phi-2-openvino"
model.save_pretrained(save_directory)
tokenizer.save_pretrained(save_directory)
`ratio` 参数控制我们将量化为 4 位(此处为 80%)的权重比例,其余的量化为 8 位。`group_size` 参数定义了权重量化组的大小(此处为 128),每个组都有其缩放因子。减小这两个值通常会提高精度,但会牺牲模型大小和推理延迟。
您可以在我们的文档中找到有关仅权重量化的更多信息。
注意:包含文本生成示例的完整笔记本可在 Github 上找到。
那么,量化模型在我们的笔记本电脑上有多快呢?观看以下视频,亲眼看看。请记住选择 1080p 分辨率以获得最大清晰度。
第一个视频向我们的模型提出了一个高中物理问题:“莉莉有一个橡皮球,她从墙顶上扔下来。墙高 2 米。球需要多长时间才能落地?”
第二个视频向我们的模型提出了一个编码问题:“编写一个类,使用 numpy 实现一个具有前向和后向函数的全连接层。代码使用 markdown 标记。”
正如您在两个示例中看到的,生成的答案质量非常高。量化过程并未降低 Phi-2 的高质量,并且生成速度也足够。我很乐意每天使用此模型进行本地工作。
结论
感谢 Hugging Face 和 Intel,您现在可以在笔记本电脑上运行 LLM,享受本地推理的诸多好处,例如隐私、低延迟和低成本。我们希望看到更多为 Meteor Lake 平台及其后续产品 Lunar Lake 优化的优质模型。Optimum Intel 库使为 Intel 平台量化模型变得非常容易,所以为什么不尝试一下并在 Hugging Face Hub 上分享您的优秀模型呢?我们总是需要更多!
以下是一些资源可帮助您入门:
如果您有任何问题或反馈,我们很乐意在 Hugging Face 论坛上回答。
感谢阅读!


