使用机器学习增强客户服务


在这篇博文中,我们将模拟一个真实的客户服务用例,并使用 Hugging Face 生态系统中的机器学习工具来解决它。
我们强烈建议使用此笔记本来作为模板/示例,以解决 你自己的 真实世界用例。
定义任务、数据集和模型
在进入实际编码部分之前,清楚地定义你希望自动化或部分自动化的用例非常重要。一个清晰的用例定义有助于确定最合适的任务、要使用的数据集以及要应用的模型。
定义你的 NLP 任务
好了,让我们深入研究一个我们希望使用自然语言处理模型解决的假设性问题。假设我们正在销售一种产品,我们的客户支持团队每天会收到数千条信息,包括反馈、投诉和问题,理想情况下这些信息都应该得到回复。
很快,我们就会发现客户支持团队根本无法回复每一条消息。因此,我们决定只回应那些最不满意的客户,并力求 100% 回复这些消息,因为与中性或积极的消息相比,这些消息可能更紧急。
假设 a) 非常不满意的客户消息只占所有消息的一小部分,并且 b) 我们可以通过自动化的方式筛选出不满意的消息,那么客户支持团队应该能够实现这个目标。
为了以自动化的方式筛选出不满意的消息,我们计划应用自然语言处理技术。
第一步是将我们的用例—— 筛选出不满意的消息 ——映射到一个机器学习任务。
Hugging Face Hub 上的任务页面 是一个很好的起点,可以帮助你了解哪个任务最适合特定的场景。每个任务都有详细的描述和潜在的用例。
寻找最不满意客户消息的任务可以被建模为文本分类任务:将一条消息分类为以下 5 个类别之一: 非常不满意 、 不满意 、 中性 、 满意 或 非常满意 。
寻找合适的数据集
在确定了任务之后,接下来我们应该找到模型训练所需的数据。对于你的用例性能而言,这通常比选择正确的模型架构更重要。请记住,一个模型的性能 取决于它所训练的数据 。因此,我们在整理和/或选择数据集时应该非常小心。
鉴于我们考虑的是 筛选出不满意消息 的假设性用例,让我们看看有哪些可用的数据集。
对于你的真实世界用例,你 很可能 拥有最能代表你的 NLP 系统实际需要处理的数据的内部数据。因此,你应该使用这些内部数据来训练你的 NLP 系统。不过,为了提高模型的泛化能力,包含一些公开可用的数据也可能是有帮助的。
让我们看一下 Hugging Face Hub 上所有可用的数据集。在左侧,你可以根据 任务类别 以及更具体的 任务 来筛选数据集。我们的用例对应于 文本分类 -> 情感分析,所以我们选择 这些筛选条件 。在撰写此笔记本时,我们筛选出了大约 80 个数据集。在选择数据集时,应评估两个方面:
- 质量 :数据集是否高质量?具体来说:数据是否与你用例中预期处理的数据相符?数据是否多样化、无偏见……?
- 规模 :数据集有多大?通常,我们可以肯定地说数据集越大越好。
高效地评估一个数据集是否高质量是相当棘手的,而了解数据集是否存在偏见以及偏见的程度则更具挑战性。一个高效且合理的判断高质量的经验法则是查看下载统计数据。下载次数越多,使用率越高,数据集质量高的可能性就越大。数据集的大小很容易评估,因为它通常可以快速查到。让我们看看下载量最多的几个数据集:
现在我们可以通过阅读数据集卡片来更详细地检查这些数据集,理想情况下,数据集卡片应该提供所有相关和重要的信息。此外,数据集查看器 是一个非常强大的工具,可以用来检查数据是否适合你的用例。
让我们快速浏览一下上述模型的数据集卡片:
- GLUE 是一组小型数据集的集合,主要用于研究人员比较新的模型架构。这些数据集规模太小,且与我们的用例不够匹配。
- Amazon polarity 是一个非常适合客户反馈的大型数据集,因为数据涉及客户评论。然而,它只有二元标签(正面/负面),而我们正在寻找更细粒度的情感分类。
- Tweet eval 使用不同的表情符号作为标签,这些标签不容易映射到一个从不满意到满意的量表上。
- Amazon reviews multi 似乎是这里最合适的数据集。我们有从 1 到 5 的情感标签,对应于亚马逊上的 1 到 5 星。这些标签可以映射到 非常不满意、不满意、中性、满意、非常满意 。我们在 数据集查看器 上检查了一些示例,以验证评论看起来与实际的客户反馈评论非常相似,所以这似乎是一个非常好的数据集。此外,每个评论都有一个
product_category标签,所以我们甚至可以只使用与我们工作领域相对应的产品类别的评论。这个数据集是多语言的,但我们目前只对英文版本感兴趣。 - Yelp review full 看起来是一个非常合适的数据集。它规模大,包含产品评论和从 1 到 5 的情感标签。遗憾的是,这里的数据集查看器无法使用,而且数据集卡片也相对稀疏,需要更多时间来检查数据集。此时,我们应该阅读相关论文,但考虑到这篇博文的时间限制,我们选择使用 Amazon reviews multi 。综上所述,让我们专注于 Amazon reviews multi 数据集,并考虑所有训练样本。
最后一点,我们建议即使在处理私有数据集时也利用 Hub 的数据集功能。Hugging Face Hub、Transformers 和 Datasets 实现了无缝集成,这使得在训练模型时将它们结合使用变得非常简单。
此外,Hugging Face Hub 还提供:
寻找合适的模型
在确定了任务和最能描述我们用例的数据集之后,我们现在可以开始选择要使用的模型了。
很可能你需要为自己的用例微调一个预训练模型,但值得检查一下 Hub 上是否已经有合适的、经过微调的模型。在这种情况下,你或许可以通过继续在你自己的数据集上微调这样的模型来获得更高的性能。
让我们看一下所有在 Amazon Reviews Multi 数据集上微调过的模型。你可以在右下角找到模型列表——点击 浏览在该数据集上训练的模型,你可以看到 所有在该数据集上微调过的公开可用模型的列表。请注意,我们只对该数据集的英文版本感兴趣,因为我们的客户反馈将只使用英文。大多数下载量最高的模型都是在多语言版本的数据集上训练的,而那些看起来不是多语言的模型信息很少或性能较差。在这种情况下,微调一个纯粹的预训练模型可能比使用上面链接中显示的那些已经微调过的模型更为明智。
好了,下一步是找到一个合适的预训练模型用于微调。考虑到 Hugging Face Hub 上有大量的预训练和微调模型,这实际上比看起来要困难。最好的选择通常是简单地尝试各种不同的模型,看看哪个表现最好。在 Hugging Face,我们还没有找到比较不同模型检查点的完美方法,但我们提供了一些值得研究的资源:
然而,以上两种资源目前都并非最佳选择。模型摘要并非总能被作者及时更新。新模型架构发布的速度以及旧模型架构过时的速度使得要有一个包含所有模型架构的最新摘要变得极其困难。同样地,下载次数最多的模型检查点并不一定就是最好的。例如,bert-base-cased 是下载次数最多的模型检查点之一,但它已不再是性能最佳的检查点了。
最好的方法是尝试各种模型架构,通过关注该领域的专家来了解最新的模型架构,并查看知名的排行榜。
对于文本分类,需要关注的重要基准是 GLUE 和 SuperGLUE。这两个基准都在多种文本分类任务上评估预训练模型,例如语法正确性、自然语言推理、是/否问答等,这些任务与我们的目标任务——情感分析非常相似。因此,为我们的任务选择这些基准中的领先模型是合理的。
在撰写这篇博文时,性能最佳的模型都是参数超过 100 亿的非常大的模型,其中大多数并未开源,例如 ST-MoE-32B、Turing NLR v5 或 ERNIE 3.0。排名靠前且易于获取的模型之一是 DeBERTa。因此,让我们尝试一下 DeBERTa 最新的基础版本——即 microsoft/deberta-v3-base。
使用 🤗 Transformers 和 🤗 Datasets 训练/微调模型
在本节中,我们将深入探讨如何端到端地微调一个模型,以便能够自动筛选出非常不满意的客户反馈消息。
太棒了!让我们先安装所有必要的 pip 包并设置我们的代码环境,然后研究如何预处理数据集,最后开始训练模型。
以下笔记本可以在启用 GPU 运行时环境的 Google Colab Pro 中在线运行。
安装所有必要的软件包
首先,让我们安装 git-lfs,这样我们就可以在训练过程中自动将训练好的检查点上传到 Hub。
apt install git-lfs
此外,我们安装 🤗 Transformers 和 🤗 Datasets 库来运行这个笔记本。由于我们将在本博文中使用 DeBERTa,我们还需要为其分词器安装 sentencepiece 库。
pip install datasets transformers[sentencepiece]
接下来,让我们登录我们的 Hugging Face 账户,以便模型能以你的用户名正确上传。
from huggingface_hub import notebook_login
notebook_login()
输出
Login successful
Your token has been saved to /root/.huggingface/token
Authenticated through git-credential store but this isn't the helper defined on your machine.
You might have to re-authenticate when pushing to the Hugging Face Hub. Run the following command in your terminal in case you want to set this credential helper as the default
git config --global credential.helper store
预处理数据集
在我们开始训练模型之前,我们应该将数据集转换成模型可以理解的格式。
幸运的是,正如你将在接下来的单元格中看到的, 🤗 Datasets 库使这一切变得极其简单。
load_dataset 函数会加载数据集,将其整齐地组织成预定义的属性,如 review_body 和 stars,最后使用 Arrow 格式 将新整理的数据保存在磁盘上。Arrow 格式允许快速且内存高效的数据读写。
让我们加载并准备 amazon_reviews_multi 数据集的英文版本。
from datasets import load_dataset
amazon_review = load_dataset("amazon_reviews_multi", "en")
输出
Downloading and preparing dataset amazon_reviews_multi/en (download: 82.11 MiB, generated: 58.69 MiB, post-processed: Unknown size, total: 140.79 MiB) to /root/.cache/huggingface/datasets/amazon_reviews_multi/en/1.0.0/724e94f4b0c6c405ce7e476a6c5ef4f87db30799ad49f765094cf9770e0f7609...
Dataset amazon_reviews_multi downloaded and prepared to /root/.cache/huggingface/datasets/amazon_reviews_multi/en/1.0.0/724e94f4b0c6c405ce7e476a6c5ef4f87db30799ad49f765094cf9770e0f7609. Subsequent calls will reuse this data.
太棒了,速度真快 🔥。让我们看一下数据集的结构。
print(amazon_review)
输出
{.output .execute_result execution_count="5"}
DatasetDict({
train: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 200000
})
validation: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 5000
})
test: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 5000
})
})
我们有 200,000 个训练样本,以及 5000 个验证和测试样本。这对于训练来说听起来很合理!我们真正感兴趣的只是将 "review_body" 列作为输入,"stars" 列作为目标。
让我们来看一个随机的例子。
random_id = 34
print("Stars:", amazon_review["train"][random_id]["stars"])
print("Review:", amazon_review["train"][random_id]["review_body"])
输出
Stars: 1
Review: This product caused severe burning of my skin. I have used other brands with no problems
数据集是人类可读的格式,但现在我们需要将其转换为“机器可读”的格式。让我们定义模型仓库,其中包含预处理和微调我们所选检查点所需的所有工具。
model_repository = "microsoft/deberta-v3-base"
接下来,我们加载模型仓库的分词器,它是一个 DeBERTa 的分词器。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_repository)
如前所述,我们将使用 "review_body" 作为模型的输入,"stars" 作为模型的目标。接下来,我们利用分词器将输入转换为模型可以理解的词元 ID 序列。分词器正是做这个的,它还可以帮助你将输入数据限制在一定的长度内,以避免内存问题。在这里,我们将最大长度限制为 128 个词元,对于 DeBERTa 来说,这大约对应 100 个单词,也就是大约 5-7 个句子。再次查看 数据集查看器,我们可以看到这几乎覆盖了所有的训练样本。重要提示:这并不意味着我们的模型不能处理更长的输入序列,只是意味着我们在训练时使用 128 的最大长度,因为它覆盖了 99% 的训练数据,而且我们不想浪费内存。Transformer 模型在训练后已被证明能够很好地泛化到更长的序列。
如果你想了解更多关于分词的知识,请查看 分词器文档。
标签很容易转换,因为它们在原始形式下已经对应于数字,即从 1 到 5 的范围。在这里,我们只是将标签移到 0 到 4 的范围内,因为索引通常从 0 开始。
很好,让我们把想法写成代码。我们将定义一个 preprocess_function,并将其应用于每个数据样本。
def preprocess_function(example):
output_dict = tokenizer(example["review_body"], max_length=128, truncation=True)
output_dict["labels"] = [e - 1 for e in example["stars"]]
return output_dict
要将此函数应用于我们数据集中的所有数据样本,我们使用我们之前创建的 amazon_review 对象的 map 方法。这将在 amazon_review 中所有拆分的所有元素上应用该函数,因此我们的训练、验证和测试数据将通过一个命令进行预处理。我们在 batched=True 模式下运行映射函数以加快处理速度,并删除所有列,因为我们不再需要它们进行训练。
tokenized_datasets = amazon_review.map(preprocess_function, batched=True, remove_columns=amazon_review["train"].column_names)
我们来看看新的结构。
tokenized_datasets
输出
DatasetDict({
train: Dataset({
features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],
num_rows: 200000
})
validation: Dataset({
features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],
num_rows: 5000
})
test: Dataset({
features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],
num_rows: 5000
})
})
我们可以看到,结构的外层保持不变,但列的命名发生了变化。让我们看一下我们之前看过的同一个随机样本,只不过现在是预处理过的。
print("Input IDS:", tokenized_datasets["train"][random_id]["input_ids"])
print("Labels:", tokenized_datasets["train"][random_id]["labels"])
输出
Input IDS: [1, 329, 714, 2044, 3567, 5127, 265, 312, 1158, 260, 273, 286, 427, 340, 3006, 275, 363, 947, 2]
Labels: 0
好的,输入文本被转换成了一个整数序列,这个序列可以被模型转换成词嵌入,而标签索引则简单地减去了 1。
微调模型
预处理完数据集后,我们接下来可以微调模型。我们将使用广受欢迎的 Hugging Face Trainer,它让我们只需几行代码就能开始训练。Trainer 几乎可以用于 PyTorch 中的所有任务,并且通过处理大量训练所需的样板代码而极其方便。
让我们开始使用便捷的 AutoModelForSequenceClassification 来加载模型检查点。由于模型仓库的检查点只是一个预训练的检查点,我们应该通过传递 num_labels=5 (因为我们有 5 个情感类别) 来定义分类头的大小。
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(model_repository, num_labels=5)
Some weights of the model checkpoint at microsoft/deberta-v3-base were not used when initializing DebertaV2ForSequenceClassification: ['mask_predictions.classifier.bias', 'mask_predictions.LayerNorm.bias', 'mask_predictions.dense.weight', 'mask_predictions.dense.bias', 'mask_predictions.LayerNorm.weight', 'lm_predictions.lm_head.dense.bias', 'lm_predictions.lm_head.bias', 'lm_predictions.lm_head.LayerNorm.weight', 'lm_predictions.lm_head.dense.weight', 'lm_predictions.lm_head.LayerNorm.bias', 'mask_predictions.classifier.weight']
- This IS expected if you are initializing DebertaV2ForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing DebertaV2ForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of DebertaV2ForSequenceClassification were not initialized from the model checkpoint at microsoft/deberta-v3-base and are newly initialized: ['pooler.dense.bias', 'classifier.weight', 'classifier.bias', 'pooler.dense.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
接下来,我们加载一个数据整理器(data collator)。数据整理器 负责确保在训练过程中每个批次都得到正确的填充,这应该是动态发生的,因为训练样本在每个周期之前都会被重新打乱。
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
在训练过程中,监控模型在留出的验证集上的性能非常重要。为此,我们应该向 Trainer 传递一个 compute_metrics 函数,该函数将在训练期间的每个验证步骤被调用。
文本分类任务最简单的度量标准是 准确率,它简单地表示被正确分类的训练样本的百分比。然而,如果验证或测试数据非常不平衡,使用 准确率 度量标准可能会有问题。让我们通过计算每个标签的出现次数来快速验证情况是否如此。
from collections import Counter
print("Validation:", Counter(tokenized_datasets["validation"]["labels"]))
print("Test:", Counter(tokenized_datasets["test"]["labels"]))
输出
Validation: Counter({0: 1000, 1: 1000, 2: 1000, 3: 1000, 4: 1000})
Test: Counter({0: 1000, 1: 1000, 2: 1000, 3: 1000, 4: 1000})
验证集和测试集尽可能地平衡,所以我们在这里可以安全地使用准确率!
让我们通过 datasets 库加载 准确率指标。
from datasets import load_metric
accuracy = load_metric("accuracy")
接下来,我们定义 compute_metrics 函数,该函数将应用于模型的预测输出,其类型为 EvalPrediction,因此可以访问模型的预测值和真实标签。我们通过取模型预测值的 argmax 来计算预测的标签类别,然后将其与真实标签一起传递给准确率指标。
import numpy as np
def compute_metrics(pred):
pred_logits = pred.predictions
pred_classes = np.argmax(pred_logits, axis=-1)
labels = np.asarray(pred.label_ids)
acc = accuracy.compute(predictions=pred_classes, references=labels)
return {"accuracy": acc["accuracy"]}
太好了,现在训练所需的所有组件都准备好了,剩下的就是定义 Trainer 的超参数。我们需要确保在训练期间将模型检查点上传到 Hugging Face Hub。通过设置 push_to_hub=True,这将在每个 save_steps 步骤通过方便的 push_to_hub 方法自动完成。
此外,我们还定义了一些标准的超参数,如学习率、预热步数和训练周期。我们将每 500 步记录一次损失,并每 5000 步进行一次评估。
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="deberta_amazon_reviews_v1",
num_train_epochs=2,
learning_rate=2e-5,
warmup_steps=200,
logging_steps=500,
save_steps=5000,
eval_steps=5000,
push_to_hub=True,
evaluation_strategy="steps",
)
将所有内容整合在一起,我们最终可以通过传递所有必需的组件来实例化 Trainer。我们将使用 "validation" 拆分作为训练期间的留出数据集。
from transformers import Trainer
trainer = Trainer(
args=training_args,
compute_metrics=compute_metrics,
model=model,
tokenizer=tokenizer,
data_collator=data_collator,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"]
)
训练器已准备就绪 🚀 你可以通过调用 trainer.train() 开始训练。
train_metrics = trainer.train().metrics
trainer.save_metrics("train", train_metrics)
输出
***** Running training *****
Num examples = 200000
Num Epochs = 2
Instantaneous batch size per device = 8
Total train batch size (w. parallel, distributed & accumulation) = 8
Gradient Accumulation steps = 1
Total optimization steps = 50000
输出
| 步骤 | 训练损失 | 验证损失 | 准确率 |
| 5000 | 0.931200 | 0.979602 | 0.585600 |
| 10000 | 0.931600 | 0.933607 | 0.597400 |
| 15000 | 0.907600 | 0.917062 | 0.602600 |
| 20000 | 0.902400 | 0.919414 | 0.604600 |
| 25000 | 0.879400 | 0.910928 | 0.608400 |
| 30000 | 0.806700 | 0.933923 | 0.609200 |
| 35000 | 0.826800 | 0.907260 | 0.616200 |
| 40000 | 0.820500 | 0.904160 | 0.615800 |
| 45000 | 0.795000 | 0.918947 | 0.616800 |
| 50000 | 0.783600 | 0.907572 | 0.618400 |
输出
***** Running Evaluation *****
Num examples = 5000
Batch size = 8
Saving model checkpoint to deberta_amazon_reviews_v1/checkpoint-50000
Configuration saved in deberta_amazon_reviews_v1/checkpoint-50000/config.json
Model weights saved in deberta_amazon_reviews_v1/checkpoint-50000/pytorch_model.bin
tokenizer config file saved in deberta_amazon_reviews_v1/checkpoint-50000/tokenizer_config.json
Special tokens file saved in deberta_amazon_reviews_v1/checkpoint-50000/special_tokens_map.json
added tokens file saved in deberta_amazon_reviews_v1/checkpoint-50000/added_tokens.json
Training completed. Do not forget to share your model on huggingface.co/models =)
酷,我们看到模型似乎学到了一些东西!训练损失和验证损失都在下降,准确率最终也远高于随机猜测(20%)。有趣的是,我们看到仅在 5000 步后准确率就达到了约 58.6 %,之后并没有太大提升。选择一个更大的模型或训练更长时间可能会得到更好的结果,但这对于我们假设的用例来说已经足够好了!
好了,最后让我们将模型检查点上传到 Hub。
trainer.push_to_hub()
输出
Saving model checkpoint to deberta_amazon_reviews_v1
Configuration saved in deberta_amazon_reviews_v1/config.json
Model weights saved in deberta_amazon_reviews_v1/pytorch_model.bin
tokenizer config file saved in deberta_amazon_reviews_v1/tokenizer_config.json
Special tokens file saved in deberta_amazon_reviews_v1/special_tokens_map.json
added tokens file saved in deberta_amazon_reviews_v1/added_tokens.json
Several commits (2) will be pushed upstream.
The progress bars may be unreliable.
评估/分析模型
现在我们已经微调了模型,我们需要非常仔细地分析它的性能。请注意,像 准确率 这样的标准指标对于了解模型的总体性能很有用,但可能不足以评估模型在你的实际用例中的表现。更好的方法是找到一个最能描述模型实际用例的指标,并在训练期间和之后精确地衡量这个指标。
让我们深入评估模型 🤿。
模型在训练后已经上传到了 Hub 的 deberta_v3_amazon_reviews 下,所以第一步,让我们再次从那里下载它。
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("patrickvonplaten/deberta_v3_amazon_reviews")
Trainer 不仅是训练模型的绝佳类,也是在数据集上评估模型的绝佳类。让我们用与之前相同的实例和函数来实例化 Trainer,但这次不需要传递训练数据集。
trainer = Trainer(
args=training_args,
compute_metrics=compute_metrics,
model=model,
tokenizer=tokenizer,
data_collator=data_collator,
)
我们使用 Trainer 的 predict 函数在测试数据集上使用相同的指标评估模型。
prediction_metrics = trainer.predict(tokenized_datasets["test"]).metrics
prediction_metrics
输出
***** Running Prediction *****
Num examples = 5000
Batch size = 8
输出
{'test_accuracy': 0.608,
'test_loss': 0.9637690186500549,
'test_runtime': 21.9574,
'test_samples_per_second': 227.714,
'test_steps_per_second': 28.464}
结果与在验证数据集上的表现非常相似,这通常是一个好迹象,因为它表明模型没有过拟合测试数据集。
然而,对于一个 5 分类问题来说,60% 的准确率远非完美,但我们是否需要对所有类别都有很高的准确率呢?
由于我们主要关注的是非常负面的客户反馈,让我们只关注模型在分类最不满意客户的评论方面的表现。我们还决定帮助模型一下——所有被分类为 非常不满意 或 不满意 的反馈都将由我们处理——以捕捉到接近 99% 的 非常不满意 的消息。同时,我们还衡量了通过这种方式我们能回答多少 不满意 的消息,以及我们通过回答中性、满意和非常满意的客户消息做了多少不必要的工作。
太好了,让我们写一个新的 compute_metrics 函数。
import numpy as np
def compute_metrics(pred):
pred_logits = pred.predictions
pred_classes = np.argmax(pred_logits, axis=-1)
labels = np.asarray(pred.label_ids)
# First let's compute % of very unsatisfied messages we can catch
very_unsatisfied_label_idx = (labels == 0)
very_unsatisfied_pred = pred_classes[very_unsatisfied_label_idx]
# Now both 0 and 1 labels are 0 labels the rest is > 0
very_unsatisfied_pred = very_unsatisfied_pred * (very_unsatisfied_pred - 1)
# Let's count how many labels are 0 -> that's the "very unsatisfied"-accuracy
true_positives = sum(very_unsatisfied_pred == 0) / len(very_unsatisfied_pred)
# Second let's compute how many satisfied messages we unnecessarily reply to
satisfied_label_idx = (labels > 1)
satisfied_pred = pred_classes[satisfied_label_idx]
# how many predictions are labeled as unsatisfied over all satisfied messages?
false_positives = sum(satisfied_pred <= 1) / len(satisfied_pred)
return {"%_unsatisfied_replied": round(true_positives, 2), "%_satisfied_incorrectly_labels": round(false_positives, 2)}
我们再次实例化 Trainer 以便轻松运行评估。
trainer = Trainer(
args=training_args,
compute_metrics=compute_metrics,
model=model,
tokenizer=tokenizer,
data_collator=data_collator,
)
然后让我们用我们新的、更适合我们用例的指标计算方法再次运行评估。
prediction_metrics = trainer.predict(tokenized_datasets["test"]).metrics
prediction_metrics
输出
***** Running Prediction *****
Num examples = 5000
Batch size = 8
输出
{'test_%_satisfied_incorrectly_labels': 0.11733333333333333,
'test_%_unsatisfied_replied': 0.949,
'test_loss': 0.9637690186500549,
'test_runtime': 22.8964,
'test_samples_per_second': 218.375,
'test_steps_per_second': 27.297}
酷!这已经描绘出了一幅相当不错的图景。我们自动捕捉了大约 95% 的 非常不满意 的客户,代价是在 10% 的满意消息上浪费了我们的精力。
让我们快速计算一下。我们每天大约收到 10,000 条消息,其中我们预计约有 500 条是非常负面的。使用这种自动筛选,我们不再需要回复所有 10,000 条消息,而只需查看 500 + 0.12 * 10,000 = 1700 条消息,并且只需回复 475 条消息,同时错误地漏掉了 5% 的消息。相当不错——在只漏掉 5% 非常不满意的客户的情况下,人力减少了 83%!
显然,这些数字并不能代表一个实际用例所获得的价值,但只要有足够高质量的真实世界示例训练数据,我们就能接近这个目标!
让我们保存结果
trainer.save_metrics("prediction", prediction_metrics)
然后再次将所有内容上传到 Hub。
trainer.push_to_hub()
输出
Saving model checkpoint to deberta_amazon_reviews_v1
Configuration saved in deberta_amazon_reviews_v1/config.json
Model weights saved in deberta_amazon_reviews_v1/pytorch_model.bin
tokenizer config file saved in deberta_amazon_reviews_v1/tokenizer_config.json
Special tokens file saved in deberta_amazon_reviews_v1/special_tokens_map.json
added tokens file saved in deberta_amazon_reviews_v1/added_tokens.json
To https://huggingface.co/patrickvonplaten/deberta_amazon_reviews_v1
599b891..ad77e6d main -> main
Dropping the following result as it does not have all the necessary fields:
{'task': {'name': 'Text Classification', 'type': 'text-classification'}}
To https://huggingface.co/patrickvonplaten/deberta_amazon_reviews_v1
ad77e6d..13e5ddd main -> main
数据现在保存在 这里。
今天就到这里 😎。作为最后一步,在实际的真实世界数据上尝试这个模型也很有意义。这可以直接在 模型卡片 的推理小部件上完成。
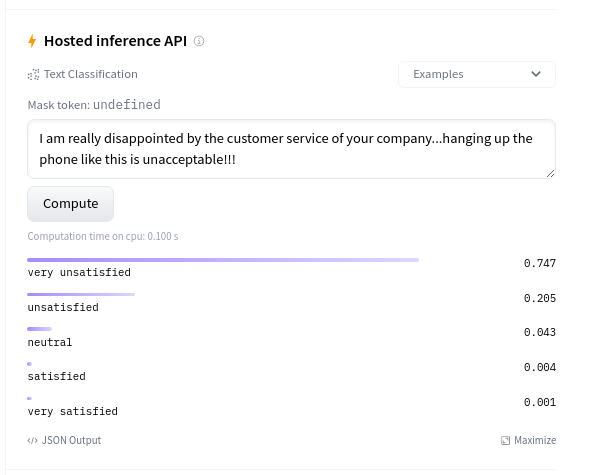
它似乎能很好地泛化到真实世界的数据 🔥
优化
一旦你认为模型的性能足够好可以投入生产,关键就在于让模型尽可能地节省内存并且运行得快。
有一些显而易见的解决方案,比如选择最合适的加速硬件,例如 更好的 GPU,确保在前向传播过程中不计算梯度,或者降低精度,例如 降至 float16。
更高级的优化方法包括使用开源加速器库,如 ONNX Runtime、量化,以及像 Triton 这样的推理服务器。
在 Hugging Face,我们一直在努力简化模型的优化,特别是通过我们的开源 Optimum 库。Optimum 使得优化大多数 🤗 Transformers 模型变得极其简单。
如果你正在寻找不需要任何技术知识的 高度优化 解决方案,你可能会对 推理 API 感兴趣,这是一个即插即用的解决方案,可以在生产环境中为各种机器学习任务提供服务,包括情感分析。
此外,如果你正在为 你的自定义用例寻求支持,Hugging Face 的专家团队可以帮助加速你的机器学习项目!我们的团队在你的机器学习之旅中,从研究到生产,随时回答问题并寻找解决方案。请访问 了解更多信息并索取报价。
