google-cloud 文档
在 Cloud Run 上使用 TGI DLC 部署 Gemma2 9B
并获得增强的文档体验
开始使用
在 Cloud Run 上使用 TGI DLC 部署 Gemma2 9B
Gemma 2 是一款先进、轻量级的开放模型,它在继承其前身和 Google DeepMind 及 Google 其他团队开发的 Gemini 模型研究和技术的基础上,提升了性能和效率。Text Generation Inference (TGI) 是 Hugging Face 开发的用于部署和提供 LLM 服务、实现高性能文本生成的工具包。Google Cloud Run 是一个无服务器容器平台,允许开发者部署和管理容器化应用程序,而无需管理基础设施,从而实现自动伸缩并按使用量计费。
本示例展示了如何在 Google Cloud Run 上,利用 Hugging Face Hub 中使用 AWQ 量化为 INT4 的 Gemma2 9B Instruct 模型,通过 Hugging Face TGI DLC 部署,并支持 GPU (处于预览阶段)。
要在 Cloud Run 上访问 GPU,请针对 `Total Nvidia L4 GPU allocation, per project per region` 申请配额增加。在编写本示例时,NVIDIA L4 GPU (24GiB VRAM) 是 Cloud Run 上唯一可用的 GPU;默认情况下可自动扩缩到最多 7 个实例(通过配额可获得更多实例),并在没有请求时缩减到零个实例。
设置/配置
首先,您需要按照Cloud SDK 文档 - 安装 gcloud CLI中的说明,在本地计算机上安装 Google Cloud 的命令行工具 gcloud。
或者,为了简化本教程中命令的使用,您需要为 GCP 设置以下环境变量
export PROJECT_ID=your-project-id
export LOCATION=us-central1 # or any location where Cloud Run offers GPUs: https://cloud.google.com/run/docs/locations#gpu
export CONTAINER_URI=us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-text-generation-inference-cu124.2-3.ubuntu2204.py311
export SERVICE_NAME=gemma2-tgi然后您需要登录您的 Google Cloud 账户并设置您要用于部署 Cloud Run 的项目 ID。
gcloud auth login
gcloud auth application-default login # For local development
gcloud config set project $PROJECT_ID登录后,您需要启用 Cloud Run API,这是在 Cloud Run 上部署 Hugging Face TGI DLC 所必需的。
gcloud services enable run.googleapis.com在 Cloud Run 上部署 TGI
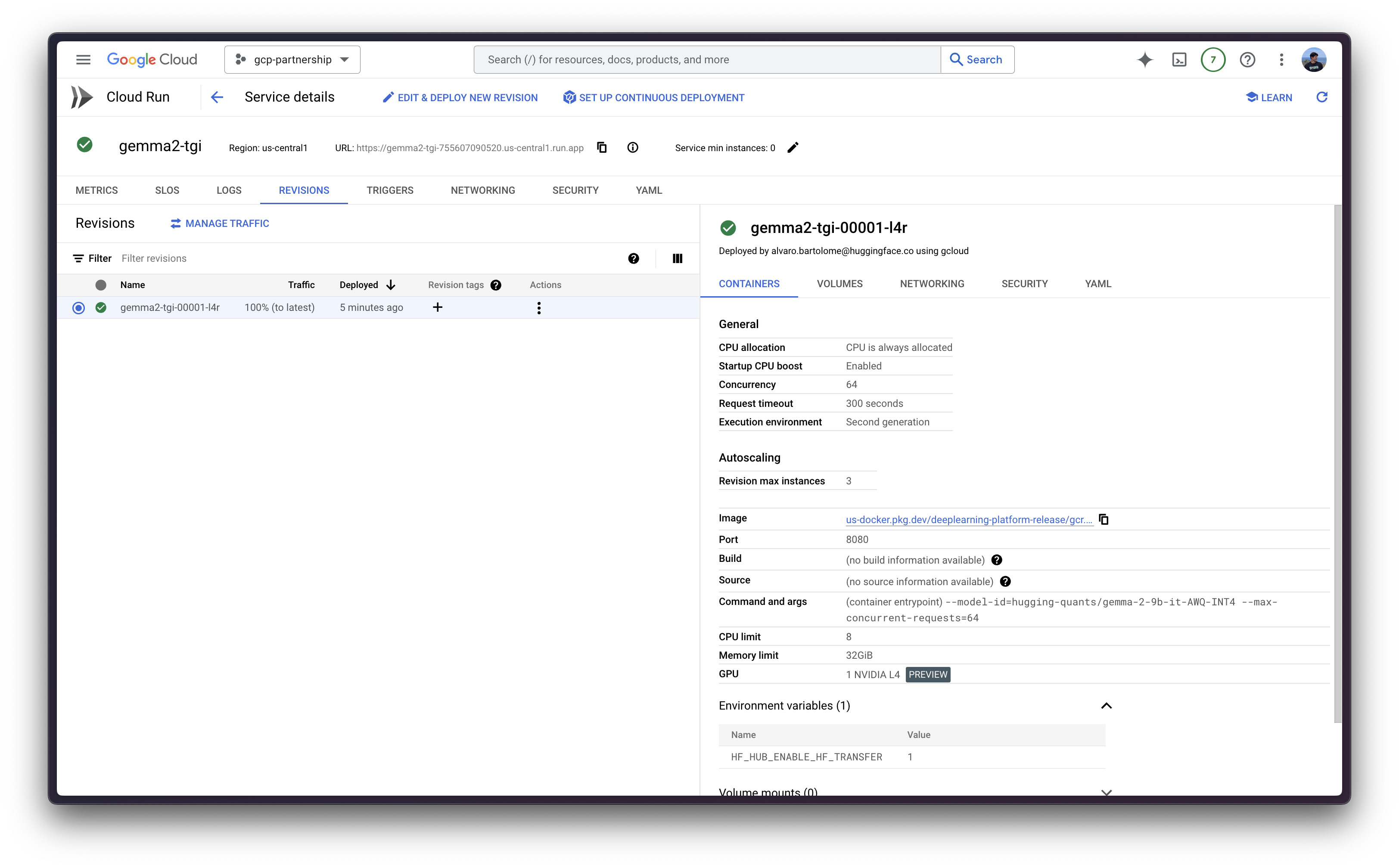
一切准备就绪后,您可以调用 gcloud beta run deploy 命令(由于 GPU 支持仍处于预览阶段,如上所述,该命令仍处于 beta 阶段)。
gcloud beta run deploy 命令需要您指定以下参数:
--image:要部署的容器镜像 URI。--args:要传递给容器入口点的参数,对于 Hugging Face TGI DLC,该参数为text-generation-launcher。有关支持的参数的更多信息,请参阅Text-generation-launcher 参数。--model-id:要使用的模型 ID,在本例中为hugging-quants/gemma-2-9b-it-AWQ-INT4。--quantize:要使用的量化方法,在本例中为awq。如果未指定,将从config.json文件中的quantization_config->quant_method中检索。--max-concurrent-requests:此特定部署的最大并发请求数。设置较低的限制将拒绝客户端请求,而不是让它们等待太长时间,通常有利于正确处理背压。设置为 64,但默认值为 128。
--port:容器监听的端口。--cpu和--memory:分配给容器的 CPU 数量和内存量。需要分别设置为 4 和 16Gi (16 GiB);因为这是使用 GPU 的最低要求。--no-cpu-throttling:禁用 CPU 节流,这是使用 GPU 所必需的。--gpu和--gpu-type:要使用的 GPU 数量和 GPU 类型。必须分别设置为 1 和nvidia-l4;因为在编写本教程时,这些是 Cloud Run on GPUs 仍处于预览阶段的唯一可用选项。--max-instances:要运行的最大实例数,设置为 3,但默认最大值为 7。或者,也可以将其设置为 1,但这最终可能导致基础设施迁移期间的停机,因此建议任何大于 1 的值。--concurrency:每个实例的最大并发请求数,设置为 64。该值不是任意的,而是在运行和评估text-generation-benchmark的结果后确定的,作为吞吐量和延迟之间的最佳平衡;其中 TGI 的当前默认值 128 有点太多。请注意,该值也与 TGI 中的--max-concurrent-requests参数对齐。--region:部署 Cloud Run 服务的区域。--no-allow-unauthenticated:禁用对服务的未经身份验证的访问,这是一个很好的做法,因为它添加了由 Google Cloud IAM 管理的身份验证层。
您可以选择包含参数 --vpc-egress=all-traffic 和 --subnet=default,因为有外部流量发送到公共互联网,因此为了加速网络,您需要通过设置这些标志将所有流量路由通过 VPC 网络。请注意,除了设置标志之外,您还需要设置 Google Cloud NAT 才能访问公共互联网,这是一项付费产品。更多信息请参见Cloud Run 文档 - 网络最佳实践。
gcloud compute routers create nat-router --network=default --region=$LOCATION
gcloud compute routers nats create vm-nat --router=nat-router --region=$LOCATION --auto-allocate-nat-external-ips --nat-all-subnet-ip-ranges最后,您可以运行 gcloud beta run deploy 命令以在 Cloud Run 上部署 TGI,如下所示:
gcloud beta run deploy $SERVICE_NAME \
--image=$CONTAINER_URI \
--args="--model-id=hugging-quants/gemma-2-9b-it-AWQ-INT4,--max-concurrent-requests=64" \
--set-env-vars=HF_HUB_ENABLE_HF_TRANSFER=1 \
--port=8080 \
--cpu=8 \
--memory=32Gi \
--no-cpu-throttling \
--gpu=1 \
--gpu-type=nvidia-l4 \
--max-instances=3 \
--concurrency=64 \
--region=$LOCATION \
--no-allow-unauthenticated如果您创建了 Cloud NAT,则如下所示
gcloud beta run deploy $SERVICE_NAME \
--image=$CONTAINER_URI \
--args="--model-id=hugging-quants/gemma-2-9b-it-AWQ-INT4,--max-concurrent-requests=64" \
--set-env-vars=HF_HUB_ENABLE_HF_TRANSFER=1 \
--port=8080 \
--cpu=8 \
--memory=32Gi \
--no-cpu-throttling \
--gpu=1 \
--gpu-type=nvidia-l4 \
--max-instances=3 \
--concurrency=64 \
--region=$LOCATION \
--no-allow-unauthenticated \
--vpc-egress=all-traffic \
--subnet=default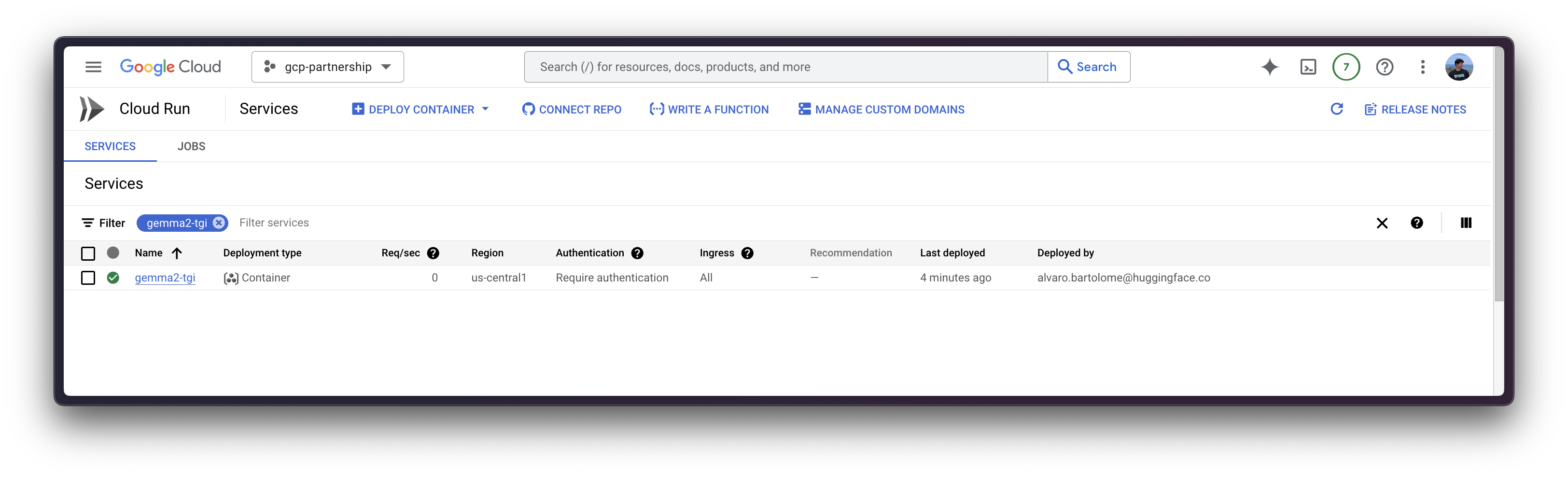
首次在 Cloud Run 上部署新容器时,由于需要从 Google Cloud Artifact Registry 导入,大约需要 5 分钟,但后续部署时间会缩短,因为镜像已提前导入。
在 Cloud Run 上推理
部署后,您可以通过任何支持的 TGI 端点向服务发送请求,请查看TGI 的 OpenAPI 规范以查看所有可用的端点及其各自的参数。
所有 Cloud Run 服务默认私有部署,这意味着在请求头中不提供身份验证凭据就无法访问它们。这些服务由 IAM 保护,只有项目所有者、项目编辑者以及 Cloud Run 管理员和 Cloud Run 调用者才能调用。
在这种情况下,将展示几种启用开发者访问的替代方案;而其他用例超出了本示例的范围,因为它们要么由于身份验证被禁用而不安全(针对公共访问场景),要么需要额外的设置才能用于生产就绪场景(服务到服务身份验证,终端用户访问)。
以下提到的替代方案适用于开发场景,不应直接用于生产就绪场景。以下方法遵循Cloud Run 文档 - 开发者身份验证中定义的指南;但您可以在Cloud Run 文档 - 身份验证概述中找到所有其他指南。
通过 Cloud Run 代理
Cloud Run 代理在本地主机上运行一个服务器,该服务器将请求代理到指定的 Cloud Run 服务并附加凭据;这对于测试和实验很有用。
gcloud run services proxy $SERVICE_NAME --region $LOCATION然后,您可以使用 https://:8080 URL 向 Cloud Run 上部署的服务发送请求,无需身份验证,如以下示例所示,由代理公开。
请注意,以下示例使用 /v1/chat/completions TGI 端点,该端点与 OpenAI 兼容,这意味着 cURL 和 Python 只是几种建议,但可以使用任何 OpenAI 兼容客户端代替。
cURL
要使用 `cURL` 向 TGI 服务发送 POST 请求,您可以运行以下命令:
curl https://:8080/v1/chat/completions \
-X POST \
-H 'Content-Type: application/json' \
-d '{
"model": "tgi",
"messages": [
{
"role": "user",
"content": "What is Deep Learning?"
}
],
"max_tokens": 128
}'Python
要使用 Python 进行推理,您可以使用 `huggingface_hub` Python SDK(推荐)或 `openai` Python SDK。
huggingface_hub
您可以通过 `pip install --upgrade --quiet huggingface_hub` 安装它,然后运行
from huggingface_hub import InferenceClient
client = InferenceClient(base_url="https://:8080", api_key="-")
chat_completion = client.chat.completions.create(
model="hugging-quants/gemma-2-9b-it-AWQ-INT4",
messages=[
{"role": "user", "content": "What is Deep Learning?"},
],
max_tokens=128,
)openai
您可以通过 `pip install --upgrade openai` 安装它,然后运行
from openai import OpenAI
client = OpenAI(
base_url="https://:8080/v1/",
api_key="-",
)
chat_completion = client.chat.completions.create(
model="tgi",
messages=[
{"role": "user", "content": "What is Deep Learning?"},
],
max_tokens=128,
)(推荐)通过 Cloud Run 服务 URL
Cloud Run 服务有一个唯一的 URL,可以用于从任何地方发送请求,使用具有 Cloud Run 调用服务访问权限的 Google Cloud 凭据;这是推荐的方法,因为它比使用 Cloud Run 代理更安全、更一致。
Cloud Run 服务的 URL 可以通过以下命令获取(为方便起见,分配给 SERVICE_URL 变量):
SERVICE_URL=$(gcloud run services describe $SERVICE_NAME --region $LOCATION --format 'value(status.url)')然后,您可以使用 `SERVICE_URL` 和任何具有 Cloud Run Invoke 访问权限的 Google Cloud 凭据向 Cloud Run 上部署的服务发送请求。设置凭据有多种方法,其中一些列在下面
使用 Google Cloud SDK 中的默认身份令牌
- 通过
gcloud命令:
gcloud auth print-identity-token
- 通过 Python 如下所示
import google.auth from google.auth.transport.requests import Request as GoogleAuthRequest auth_req = GoogleAuthRequest() creds, _ = google.auth.default() creds.refresh(auth_req) id_token = creds.id_token- 通过
使用具有 Cloud Run Invoke 访问权限的服务帐户,可以通过以下任何一种方法完成
- 在创建 Cloud Run 服务之前创建服务账号,然后在创建 Cloud Run 服务时将
--service-account标志设置为服务账号电子邮件。并且仅使用gcloud auth print-access-token --impersonate-service-account=SERVICE_ACCOUNT_EMAIL为该服务账号使用访问令牌。 - 在创建 Cloud Run 服务之后创建服务账号,然后更新 Cloud Run 服务以使用该服务账号。并且仅使用
gcloud auth print-access-token --impersonate-service-account=SERVICE_ACCOUNT_EMAIL为该服务账号使用访问令牌。
- 在创建 Cloud Run 服务之前创建服务账号,然后在创建 Cloud Run 服务时将
推荐的方法是使用服务账号(SA),因为这样可以更好地控制访问权限,并且权限更精细;由于 Cloud Run 服务未通过 SA 创建(这是另一个不错的选择),您现在需要创建 SA,授予必要的权限,更新 Cloud Run 服务以使用 SA,然后生成一个访问令牌作为请求中的身份验证令牌,该令牌在使用完毕后可以撤销。
为方便起见,设置
SERVICE_ACCOUNT_NAME环境变量export SERVICE_ACCOUNT_NAME=tgi-invoker创建服务帐户
gcloud iam service-accounts create $SERVICE_ACCOUNT_NAME授予服务帐户 Cloud Run 调用者角色
gcloud run services add-iam-policy-binding $SERVICE_NAME \ --member="serviceAccount:$SERVICE_ACCOUNT_NAME@$PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/run.invoker" \ --region=$LOCATION为服务帐户生成访问令牌
export ACCESS_TOKEN=$(gcloud auth print-access-token --impersonate-service-account=$SERVICE_ACCOUNT_NAME@$PROJECT_ID.iam.gserviceaccount.com)
访问令牌是短期的,默认情况下会在 1 小时后过期。如果您想延长令牌的生命周期,必须创建组织策略并在创建令牌时使用 --lifetime 参数。请参阅访问令牌生命周期了解更多信息。否则,您也可以通过再次运行相同的命令来生成新令牌。
现在,您已经可以深入研究向已部署的 Cloud Run 服务发送请求的不同替代方案,使用如上所述的 `SERVICE_URL` 和 `ACCESS_TOKEN`。
请注意,以下示例使用 /v1/chat/completions TGI 端点,该端点与 OpenAI 兼容,这意味着 cURL 和 Python 只是几种建议,但可以使用任何 OpenAI 兼容客户端代替。
cURL
要使用 `cURL` 向 TGI 服务发送 POST 请求,您可以运行以下命令:
curl $SERVICE_URL/v1/chat/completions \
-X POST \
-H "Authorization: Bearer $ACCESS_TOKEN" \
-H 'Content-Type: application/json' \
-d '{
"model": "tgi",
"messages": [
{
"role": "user",
"content": "What is Deep Learning?"
}
],
"max_tokens": 128
}'Python
要使用 Python 进行推理,您可以使用 `huggingface_hub` Python SDK(推荐)或 `openai` Python SDK。
huggingface_hub
您可以通过 `pip install --upgrade --quiet huggingface_hub` 安装它,然后运行
import os
from huggingface_hub import InferenceClient
client = InferenceClient(
base_url=os.getenv("SERVICE_URL"),
api_key=os.getenv("ACCESS_TOKEN"),
)
chat_completion = client.chat.completions.create(
model="hugging-quants/gemma-2-9b-it-AWQ-INT4",
messages=[
{"role": "user", "content": "What is Deep Learning?"},
],
max_tokens=128,
)openai
您可以通过 `pip install --upgrade openai` 安装它,然后运行
import os
from openai import OpenAI
client = OpenAI(
base_url=os.getenv("SERVICE_URL"),
api_key=os.getenv("ACCESS_TOKEN"),
)
chat_completion = client.chat.completions.create(
model="tgi",
messages=[
{"role": "user", "content": "What is Deep Learning?"},
],
max_tokens=128,
)资源清理
最后,当您在 Cloud Run 服务上使用完 TGI 后,您可以安全地删除它,以避免产生不必要的费用,例如,如果 Cloud Run 服务在免费套餐中被意外调用超过每月配额。
要删除 Cloud Run 服务,您可以手动前往 Google Cloud Console:https://console.cloud.google.com/run;或者使用 Google Cloud SDK 通过 gcloud 命令,如下所示:
gcloud run services delete $SERVICE_NAME --region $LOCATION此外,如果您按照通过 Cloud Run 服务 URL 中的步骤生成了服务账号和访问令牌,您可以删除服务账号,或者在访问令牌仍然有效的情况下撤销它。
- (推荐)撤销访问令牌,如下所示:
gcloud auth revoke --impersonate-service-account=$SERVICE_ACCOUNT_NAME@$PROJECT_ID.iam.gserviceaccount.com- (可选)删除服务帐户,如下所示:
gcloud iam service-accounts delete $SERVICE_ACCOUNT_NAME@$PROJECT_ID.iam.gserviceaccount.com最后,如果您决定通过 Cloud NAT 启用 VPC 网络,您还可以删除 Cloud NAT(这是一项付费产品),如下所示:
gcloud compute routers nats delete vm-nat --router=nat-router --region=$LOCATION
gcloud compute routers delete nat-router --region=$LOCATION参考资料
📍 在 GitHub 上查找完整示例:此处!