google-cloud 文档
使用 SFT + LoRA 在 Vertex AI 上通过 PyTorch 训练 DLC 微调 Gemma 2B
并获得增强的文档体验
开始使用
使用 SFT + LoRA 在 Vertex AI 上通过 PyTorch 训练 DLC 微调 Gemma 2B
Transformer Reinforcement Learning (TRL) 是 Hugging Face 开发的一个框架,用于使用监督微调 (SFT)、奖励建模 (RM)、近端策略优化 (PPO)、直接偏好优化 (DPO) 和其他方法来微调和对齐 Transformer 语言和扩散模型。另一方面,Vertex AI 是一个机器学习 (ML) 平台,可让您训练和部署 ML 模型和 AI 应用程序,并自定义大型语言模型 (LLM) 以用于您的 AI 驱动应用程序。
此示例展示了如何在 Vertex AI 上创建自定义训练作业,运行 Hugging Face PyTorch DLC 进行训练,并使用 TRL CLI 在单个 GPU 中使用 SFT + LoRA 微调 7B LLM。
设置/配置
首先,您需要按照 Cloud SDK Documentation - Install the gcloud CLI 中的说明,在本地计算机上安装 Google Cloud 的命令行工具 gcloud。
然后,您还需要安装 google-cloud-aiplatform Python SDK,这是以编程方式创建 Vertex AI 模型、注册模型、创建端点并在 Vertex AI 上部署模型所需的。
!pip install --upgrade --quiet google-cloud-aiplatform
或者,为了简化本教程中命令的使用,您需要为 GCP 设置以下环境变量
%env PROJECT_ID=your-project-id
%env LOCATION=your-location
%env BUCKET_URI=gs://hf-vertex-pipelines
%env CONTAINER_URI=us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-pytorch-training-cu121.2-3.transformers.4-42.ubuntu2204.py310然后您需要登录您的 GCP 帐户,并将项目 ID 设置为您想要用于在 Vertex AI 上注册和部署模型的项目 ID。
!gcloud auth login
!gcloud auth application-default login # For local development
!gcloud config set project $PROJECT_ID登录后,您需要启用 GCP 中必要的服务 API,例如 Vertex AI API、Compute Engine API 和 Google Container Registry 相关 API。
!gcloud services enable aiplatform.googleapis.com !gcloud services enable compute.googleapis.com !gcloud services enable container.googleapis.com !gcloud services enable containerregistry.googleapis.com !gcloud services enable containerfilesystem.googleapis.com
可选:在 GCS 中创建存储桶
您可以使用现有存储桶来存储微调工件,如果您已有存储桶,请随意跳过此步骤,直接进入下一步。
由于 Vertex AI 作业会生成工件,您需要指定一个 Google Cloud Storage (GCS) 存储桶来存储这些工件。因此,您需要通过 gcloud storage buckets create 子命令创建一个 GCS 存储桶,如下所示:
!gcloud storage buckets create $BUCKET_URI --project $PROJECT_ID --location=$LOCATION --default-storage-class=STANDARD --uniform-bucket-level-access准备 CustomContainerTrainingJob
配置好环境并创建好 GCS 存储桶(如果适用)后,您可以继续定义 CustomContainerTrainingJob,它是一个在 Vertex AI 上运行容器的标准容器作业,该容器是用于训练的 Hugging Face PyTorch DLC。
import os
from google.cloud import aiplatform
aiplatform.init(
project=os.getenv("PROJECT_ID"),
location=os.getenv("LOCATION"),
staging_bucket=os.getenv("BUCKET_URI"),
)现在您需要定义一个 CustomContainerTrainingJob,它在用于训练的 Hugging Face PyTorch DLC 上运行,需要设置 trl sft 命令,捕获作业运行时将提供的参数。
CustomContainerTrainingJob 将覆盖所提供的容器 URI 中提供的默认 ENTRYPOINT,因此如果 ENTRYPOINT 已准备好接收参数,则无需定义自定义 command。
job = aiplatform.CustomContainerTrainingJob(
display_name="trl-lora-sft",
container_uri=os.getenv("CONTAINER_URI"),
command=[
"sh",
"-c",
'exec trl sft "$@"',
"--",
],
)定义 CustomContainerTrainingJob 要求
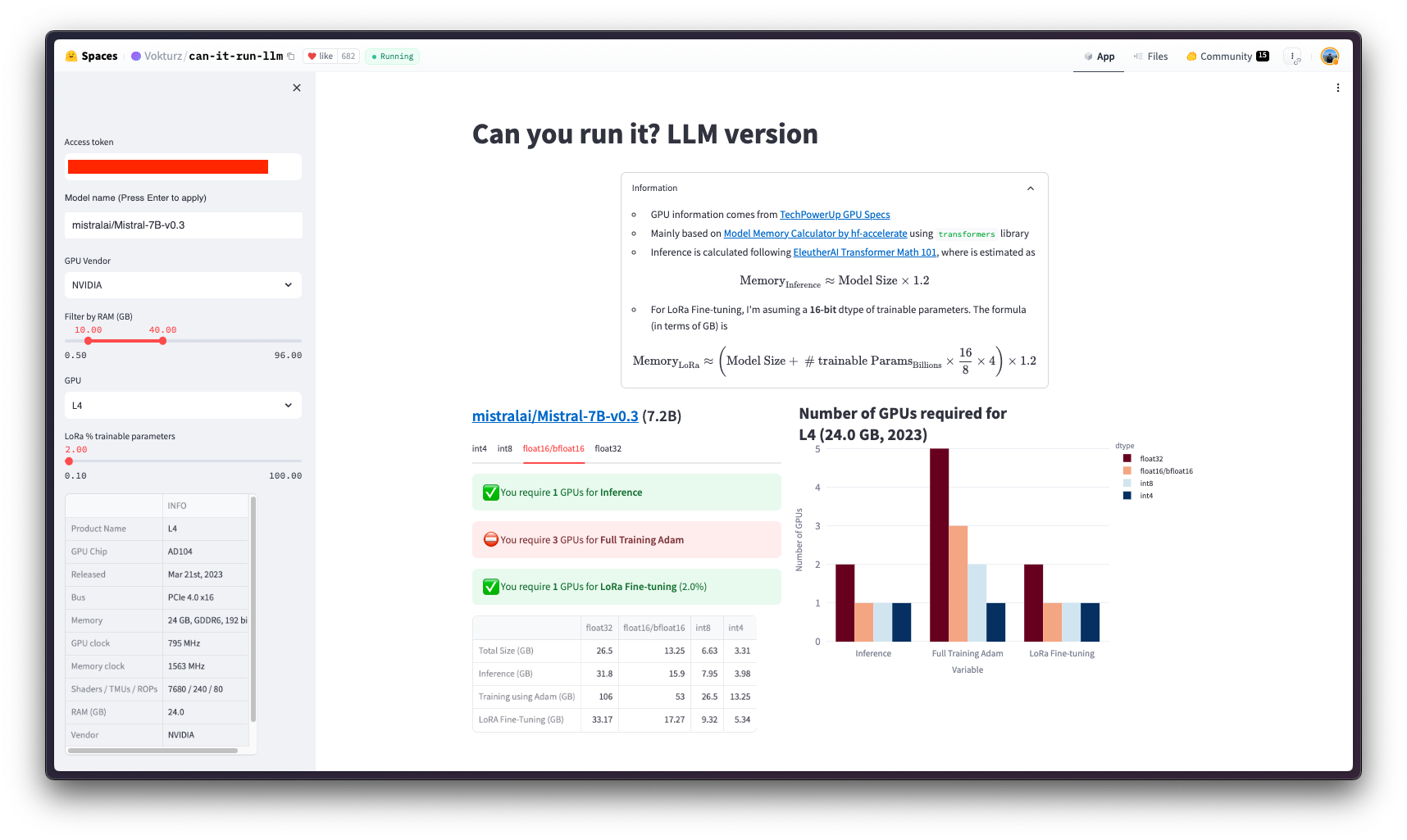
在通过用于训练的 Hugging Face PyTorch DLC 进行 CustomContainerTrainingJob 之前,您需要首先定义成功运行作业所需的配置,即哪个 GPU 能够以 bfloat16 和 LoRA 适配器微调 mistralai/Mistral-7B-v0.3。
粗略计算,您可以假设以半精度微调模型所需的 GPU 显存量约为模型大小的四倍(更多信息请参阅 Eleuther AI - Transformer Math 101)。
另外,如果您的模型已上传到 Hugging Face Hub,您可以在社区空间 Vokturz/can-it-run-llm 中查看数字,该空间会根据要微调的模型和可用硬件为您进行这些计算。
运行 CustomContainerTrainingJob
如前所述,该作业将在 mistralai/Mistral-7B-v0.3 之上,使用 TRL CLI 在 bfloat16 中运行 LoRA 监督微调 (SFT),并使用 timdettmers/openassistant-guanaco,这是 OpenAssistant/oasst1 的一个子集,包含约 10k 个样本。
一旦您决定了用于运行作业的资源,您就需要相应地定义超参数,以确保所选实例能够运行作业。为了避免出现 OOM 错误,您可能需要考虑以下一些超参数:
- LoRA / QLoRA:您可能需要调整由
r表示的秩,它定义了每个线性层可训练参数的比例,这意味着秩越低,内存消耗越少。 - 优化器:默认情况下将使用 AdamW 优化器,但也可以使用低精度优化器来减少内存,例如
adamw_bnb_8bit(有关 8 位优化器的更多信息,请查看 https://huggingface.co/docs/bitsandbytes/main/en/optimizers)。 - 批次大小:当遇到 OOM 时,您可以调整此参数以使用更小的批次大小,或者您也可以调整梯度累积步数以模拟类似的批次大小来更新梯度,但每次批次中提供的输入更少,例如
batch_size=8和gradient_accumulation=1实际上与batch_size=4和gradient_accumulation=2相同。
由于 CustomContainerTrainingJob 定义了命令 trl sft,要提供的参数列在 Python 参考 trl.SFTConfig 或通过 trl sft --help 命令中。
有关 TRL CLI 的更多信息,请参阅 https://huggingface.co/docs/trl/en/clis。
需要注意的是,由于 GCS FUSE 用于将存储桶作为目录挂载到正在运行的容器作业中,因此挂载路径遵循 /gcs/ 格式。更多信息请参见 https://cloud.google.com/vertex-ai/docs/training/code-requirements。因此 output_dir 需要设置为挂载的 GCS 存储桶,这意味着 SFTTrainer 在那里写入的任何内容都将自动上传到 GCS 存储桶。
args = [
# MODEL
"--model_name_or_path=mistralai/Mistral-7B-v0.3",
"--torch_dtype=bfloat16",
"--attn_implementation=flash_attention_2",
# DATASET
"--dataset_name=timdettmers/openassistant-guanaco",
"--dataset_text_field=text",
# PEFT
"--use_peft",
"--lora_r=16",
"--lora_alpha=32",
"--lora_dropout=0.1",
"--lora_target_modules=all-linear",
# TRAINER
"--bf16",
"--max_seq_length=1024",
"--per_device_train_batch_size=2",
"--gradient_accumulation_steps=8",
"--gradient_checkpointing",
"--learning_rate=0.0002",
"--lr_scheduler_type=cosine",
"--optim=adamw_bnb_8bit",
"--num_train_epochs=1",
"--logging_steps=10",
"--do_eval",
"--eval_steps=100",
"--report_to=none",
f"--output_dir={os.getenv('BUCKET_URI').replace('gs://', '/gcs/')}/Mistral-7B-v0.3-LoRA-SFT-Guanaco",
"--overwrite_output_dir",
"--seed=42",
"--log_level=debug",
]然后您需要调用 aiplatform.CustomContainerTrainingJob 上的 submit 方法,这是一个非阻塞方法,它将调度作业而不阻塞执行。
提供给 submit 方法的参数如下:
args定义了要提供给trl sft命令的参数列表,格式为trl sft --arg_1=value ...。replica_count定义了运行作业的副本数量,对于训练通常此值设置为 1。machine_type、accelerator_type和accelerator_count分别定义了机器(即 Compute Engine 实例)、加速器(如果有)以及加速器数量(范围从 1 到 8)。machine_type和accelerator_type是绑定的,因此您需要选择支持您正在使用的加速器的实例,反之亦然。有关不同实例的更多信息,请参阅 Compute Engine Documentation - GPU 机器类型,有关accelerator_type命名的更多信息,请参阅 Vertex AI Documentation - MachineSpec。base_output_dir定义了将从 GCS 存储桶挂载到运行容器内的基本目录,这取决于最初提供给aiplatform.init的staging_bucket参数。(可选)
environment_variables定义了在运行容器内定义的环境变量。由于您正在微调一个门控模型,即mistralai/Mistral-7B-v0.3,您需要设置HF_TOKEN环境变量。此外,还定义了其他一些环境变量,用于设置缓存路径(HF_HOME)并确保日志消息正确流式传输到 Google Cloud Logs Explorer(TRL_USE_RICH、ACCELERATE_LOG_LEVEL、TRANSFORMERS_LOG_LEVEL和TQDM_POSITION)。(可选)
timeout和create_request_timeout分别定义了中断作业执行或作业创建请求(分配所需资源和开始执行的时间)之前的超时时间(以秒为单位)。
!pip install --upgrade --quiet huggingface_hub
from huggingface_hub import interpreter_login
interpreter_login()from huggingface_hub import get_token
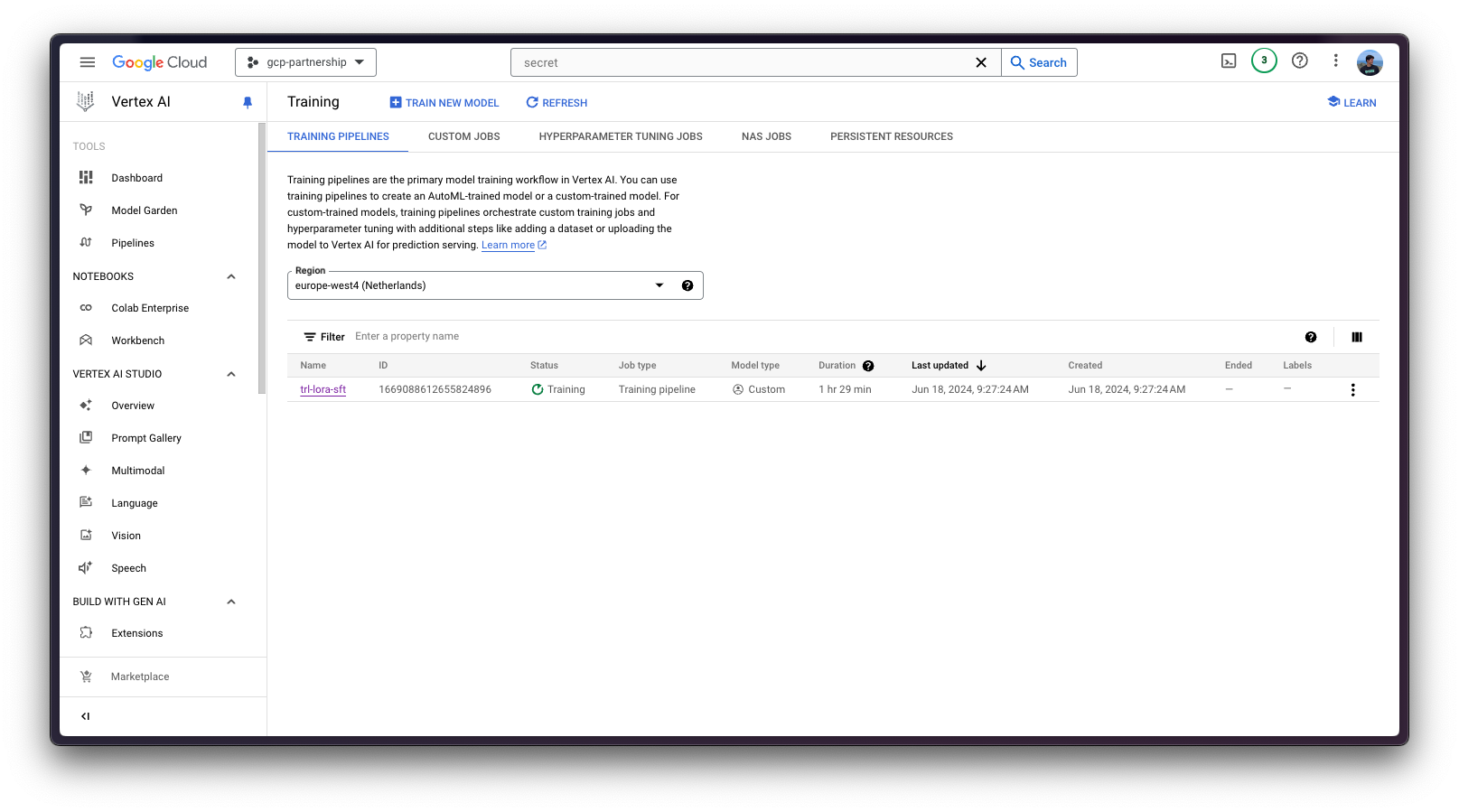
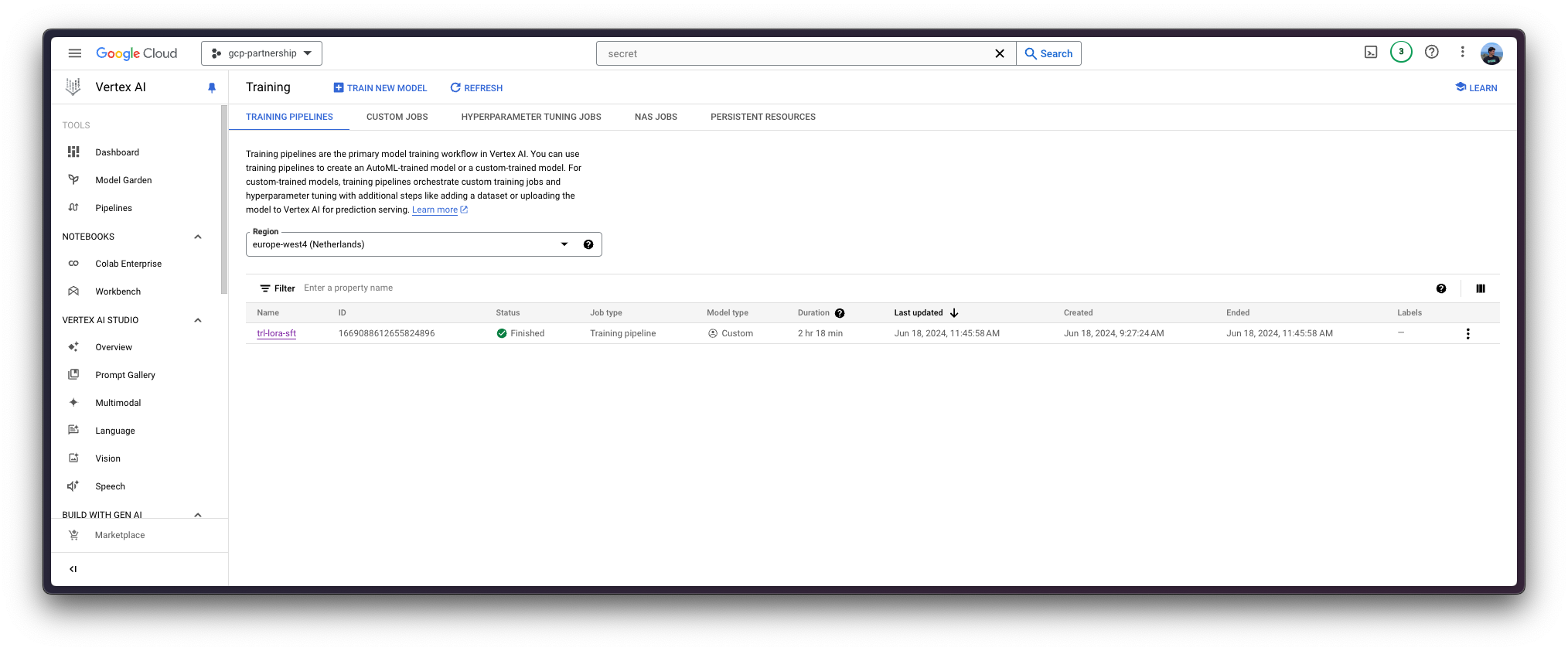
job.submit(
args=args,
replica_count=1,
machine_type="g2-standard-12",
accelerator_type="NVIDIA_L4",
accelerator_count=1,
base_output_dir=f"{os.getenv('BUCKET_URI')}/Mistral-7B-v0.3-LoRA-SFT-Guanaco",
environment_variables={
"HF_HOME": "/root/.cache/huggingface",
"HF_TOKEN": get_token(),
"TRL_USE_RICH": "0",
"ACCELERATE_LOG_LEVEL": "INFO",
"TRANSFORMERS_LOG_LEVEL": "INFO",
"TQDM_POSITION": "-1",
},
timeout=60 * 60 * 3, # 3 hours (10800s)
create_request_timeout=60 * 10, # 10 minutes (600s)
)
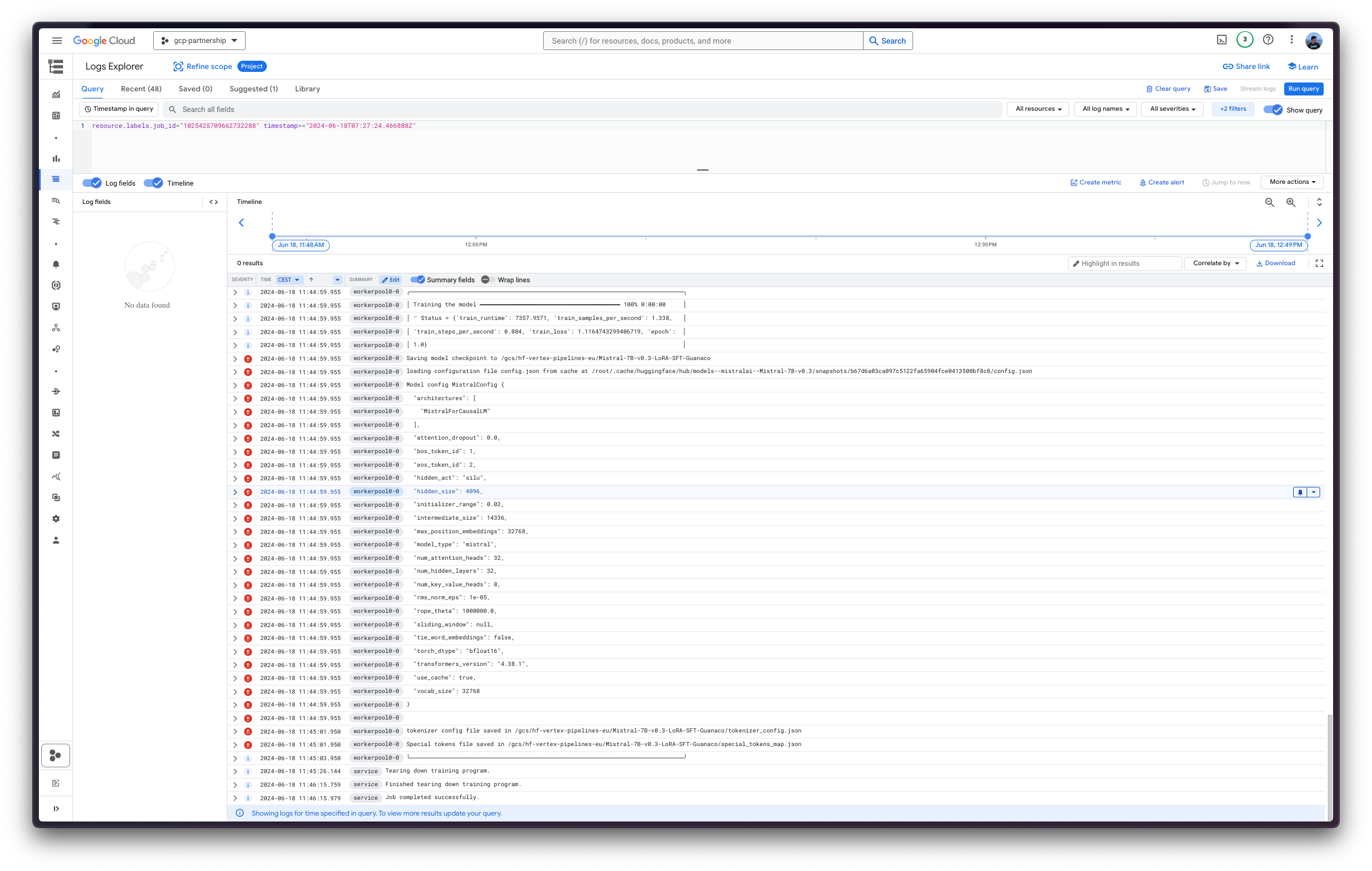
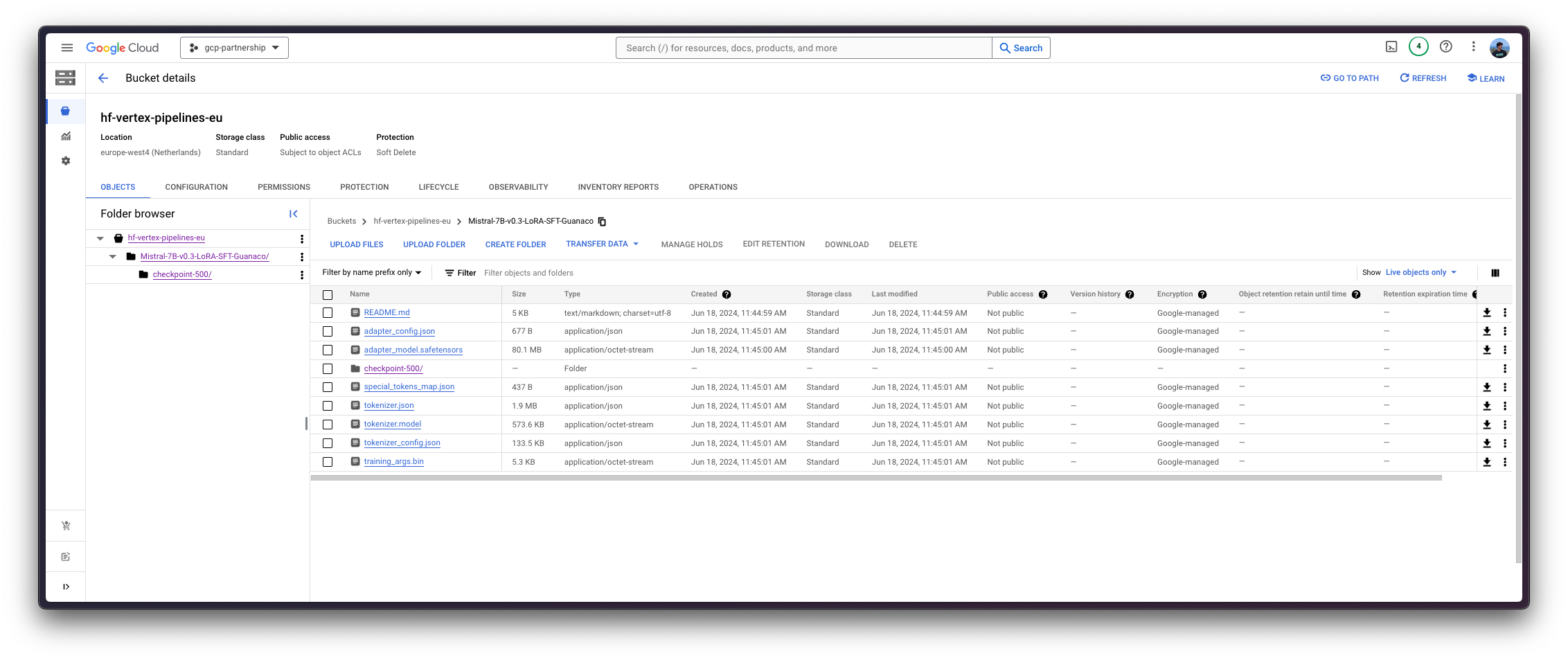
最后,您可以将微调后的模型上传到 Hugging Face Hub,或者将其保留在 Google Cloud Storage (GCS) 存储桶中。之后,您可以在合并适配器后,通过 Hugging Face PyTorch DLC(通过 transformers 中的 pipeline)或通过 Hugging Face DLC for TGI(因为模型已针对文本生成进行了微调)在其之上运行推理。
📍 完整示例请参见 GitHub 此处!