PEFT 文档
正交微调(OFT 与 BOFT)
并获得增强的文档体验
开始使用
正交微调(OFT 与 BOFT)
本概念指南简要概述了 OFT、OFTv2 和 BOFT,这是一种参数高效的微调技术,利用正交矩阵对预训练权重矩阵进行乘法变换。
为了实现高效微调,OFT 使用正交变换来表示权重更新。该正交变换通过一个与预训练权重矩阵相乘的正交矩阵进行参数化。这些新矩阵可以被训练以适应新数据,同时保持总体变化数量较少。原始权重矩阵保持冻结,不再进行任何调整。为了产生最终结果,原始权重和适配后的权重会相乘。
正交蝶形(Orthogonal Butterfly,BOFT)通过蝶形分解(Butterfly factorization)对 OFT 进行了推广,进一步提高了其参数效率和微调灵活性。简而言之,OFT 可以被视为 BOFT 的一个特例。与使用加性低秩权重更新的 LoRA 不同,BOFT 使用乘性正交权重更新。对比如下所示。
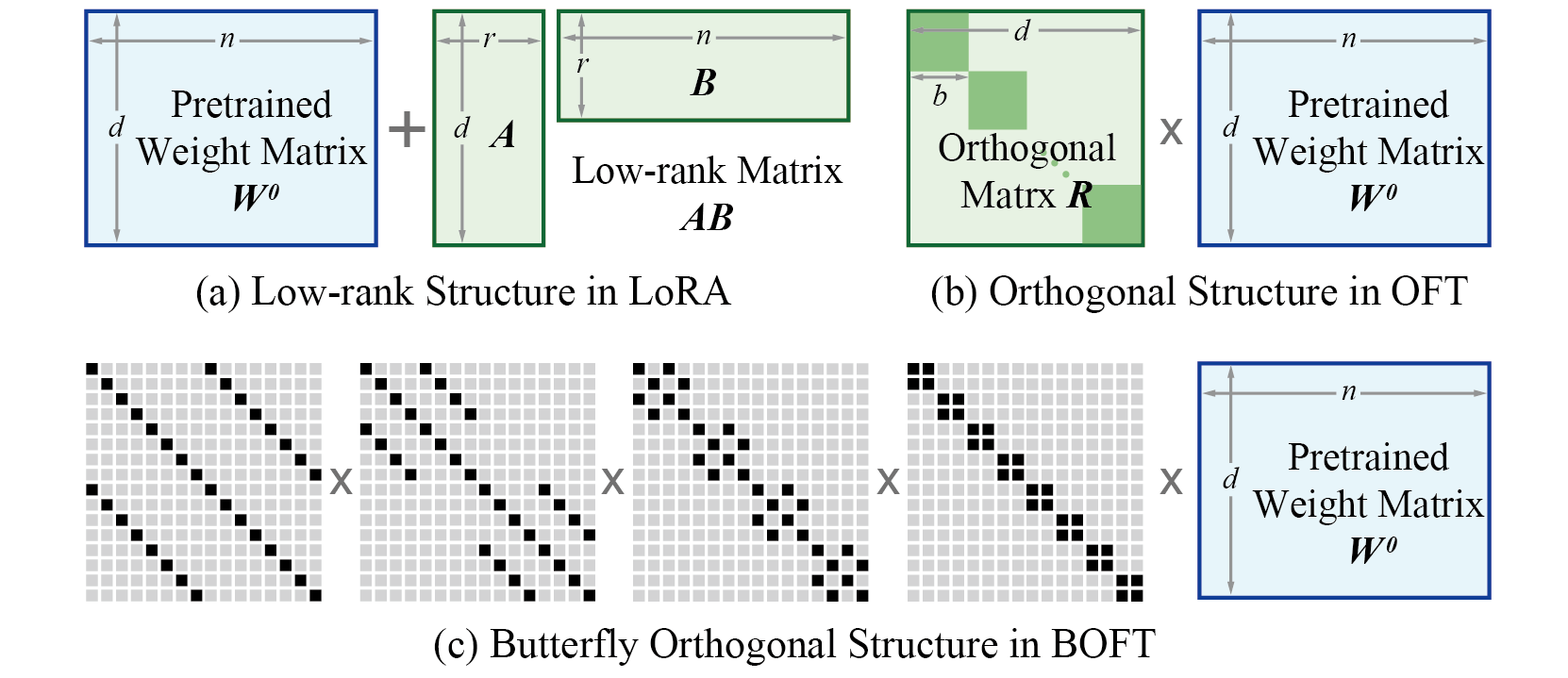
与 LoRA 相比,BOFT 具有一些优势
- BOFT 提出了一种简单而通用的方法,用于将预训练模型微调至下游任务,从而更好地保留预训练知识并提高参数效率。
- 通过正交性,BOFT 引入了一种结构性约束,即在微调过程中保持超球面能量不变。这可以有效减少对预训练知识的遗忘。
- BOFT 使用蝶形分解来高效地参数化正交矩阵,这产生了一个紧凑且富有表现力的学习空间(即假设类别)。
- BOFT 中的稀疏矩阵分解带来了额外的归纳偏置,这有利于泛化。
原则上,BOFT 可以应用于神经网络中权重矩阵的任何子集,以减少可训练参数的数量。给定注入 BOFT 参数的目标层,可训练参数的数量可以根据权重矩阵的大小确定。
将 OFT/BOFT 权重合并到基础模型中
与 LoRA 类似,通过 OFT/BOFT 学到的权重可以使用 merge_and_unload() 函数集成到预训练权重矩阵中。此函数将适配器权重与基础模型合并,使您能够有效地将新合并的模型作为一个独立模型使用。

这是因为在训练期间,正交权重矩阵(上图中的 R)和预训练权重矩阵是分开的。但一旦训练完成,这些权重实际上可以合并(相乘)成一个新的等效权重矩阵。
OFT / BOFT 的工具函数
PEFT 中 OFT / BOFT 的通用参数
与 PEFT 支持的其他方法一样,要使用 OFT 或 BOFT 微调模型,您需要:
- 实例化一个基础模型。
- 创建一个配置(`OFTConfig` 或 `BOFTConfig`),在其中定义 OFT/BOFT 特定的参数。
- 使用 `get_peft_model()` 包装基础模型以获得一个可训练的 `PeftModel`。
- 像训练基础模型一样训练 `PeftModel`。
OFT 特定参数
`OFTConfig` 允许您通过以下参数控制如何将 OFT 应用于基础模型:
- `r`:OFT 的秩,即每个注入层的 OFT 块数。**更大**的 `r` 会导致更稀疏的更新矩阵和**更少**的可训练参数。**注意**:您只能指定 `r` 或 `oft_block_size`,不能同时指定两者,因为 `r` × `oft_block_size` = 层的维度。为简单起见,我们让用户指定 `r` 或 `oft_block_size` 中的一个,然后推断出另一个。默认设置为 `r = 0`,建议用户设置 `oft_block_size` 以获得更好的清晰度。
- `oft_block_size`:不同层的 OFT 块大小。**更大**的 `oft_block_size` 会导致更密集的更新矩阵和**更多**的可训练参数。**注意**:请选择能被层输入维度(`in_features`)整除的 `oft_block_size`,例如 4, 8, 16。您只能指定 `r` 或 `oft_block_size`,不能同时指定两者,因为 `r` × `oft_block_size` = 层的维度。为简单起见,我们让用户指定 `r` 或 `oft_block_size` 中的一个,然后推断出另一个。默认设置为 `oft_block_size = 32`。
- `use_cayley_neumann`:指定是否使用 Cayley-Neumann 参数化(高效但近似)或原版 Cayley 参数化(精确但因矩阵求逆而计算成本高)。我们建议将其设置为 `True` 以获得更好的效率,但由于近似误差,性能可能会稍差。请根据您的需求测试两种设置(`True` 和 `False`)。默认为 `False`。
- `module_dropout`:乘性 dropout 的概率,通过在训练期间将 OFT 块设置为单位矩阵,类似于 LoRA 中的 dropout 层。
- `bias`:指定是否应训练 `bias` 参数。可以是 `"none"`、`"all"` 或 `"oft_only"`。
- `target_modules`:要注入 OFT 矩阵的模块(例如,注意力块)。
- `modules_to_save`:除了 OFT 矩阵之外,要设置为可训练并保存在最终检查点中的模块列表。这些通常包括为微调任务随机初始化的模型的自定义头部。
BOFT 特定参数
`BOFTConfig` 允许您通过以下参数控制如何将 BOFT 应用于基础模型:
- `boft_block_size`:不同层的 BOFT 矩阵块大小,以 `int` 表示。**更大**的 `boft_block_size` 会导致更密集的更新矩阵和**更多**的可训练参数。**注意**,请选择能被大多数层的输入维度(`in_features`)整除的 `boft_block_size`,例如 4, 8, 16。另外,请只指定 `boft_block_size` 或 `boft_block_num` 中的一个,不要同时指定或都留为 0,因为 `boft_block_size` × `boft_block_num` 必须等于层的输入维度。
- `boft_block_num`:不同层的 BOFT 矩阵块数,以 `int` 表示。**更大**的 `boft_block_num` 会导致更稀疏的更新矩阵和**更少**的可训练参数。**注意**,请选择能被大多数层的输入维度(`in_features`)整除的 `boft_block_num`,例如 4, 8, 16。另外,请只指定 `boft_block_size` 或 `boft_block_num` 中的一个,不要同时指定或都留为 0,因为 `boft_block_size` × `boft_block_num` 必须等于层的输入维度。
- `boft_n_butterfly_factor`:蝶形因子的数量。**注意**,当 `boft_n_butterfly_factor=1` 时,BOFT 与原版 OFT 相同;当 `boft_n_butterfly_factor=2` 时,OFT 的有效块大小变为两倍,块数变为一半。
- `bias`:指定是否应训练 `bias` 参数。可以是 `"none"`、`"all"` 或 `"boft_only"`。
- `boft_dropout`:指定乘性 dropout 的概率。
- `target_modules`:要注入 OFT/BOFT 矩阵的模块(例如,注意力块)。
- `modules_to_save`:除了 OFT/BOFT 矩阵之外,要设置为可训练并保存在最终检查点中的模块列表。这些通常包括为微调任务随机初始化的模型的自定义头部。
OFT 使用示例
要使用 OFT 进行量化微调,并结合 TRL 进行 `SFT`、`PPO` 或 `DPO` 微调,请遵循以下大纲:
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from trl import SFTTrainer
from peft import OFTConfig
if use_quantization:
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_storage=torch.bfloat16,
)
model = AutoModelForCausalLM.from_pretrained(
"model_name",
quantization_config=bnb_config
)
tokenizer = AutoTokenizer.from_pretrained("model_name")
# Configure OFT
peft_config = OFTConfig(
oft_block_size=32,
use_cayley_neumann=True,
target_modules="all-linear",
bias="none",
task_type="CAUSAL_LM"
)
trainer = SFTTrainer(
model=model,
train_dataset=ds['train'],
peft_config=peft_config,
processing_class=tokenizer,
args=training_arguments,
data_collator=collator,
)
trainer.train()BOFT 使用示例
关于 BOFT 方法在各种下游任务中的应用示例,请参考以下指南:
请查看以下关于如何使用 BOFT 微调模型的分步指南:
对于图像分类任务,可以如下为 DinoV2 模型初始化 BOFT 配置:
import transformers
from transformers import AutoModelForSeq2SeqLM, BOFTConfig
from peft import BOFTConfig, get_peft_model
config = BOFTConfig(
boft_block_size=4,
boft_n_butterfly_factor=2,
target_modules=["query", "value", "key", "output.dense", "mlp.fc1", "mlp.fc2"],
boft_dropout=0.1,
bias="boft_only",
modules_to_save=["classifier"],
)
model = transformers.Dinov2ForImageClassification.from_pretrained(
"facebook/dinov2-large",
num_labels=100,
)
boft_model = get_peft_model(model, config)