十亿级分类







您已经优化了模型。您的流水线运行顺畅。但现在,您的云账单却飞涨。每天运行10亿次以上的分类或嵌入任务不仅是技术挑战,也是财务挑战。如何在不超出预算的情况下进行如此规模的处理?无论您是运行大规模文档分类还是用于检索增强生成(RAG)的批量嵌入流水线,您都需要高成本效益、高吞吐量的推理才能使其可行,而这需要通过优化配置来实现。
这些任务通常使用编码器模型,它们比现代LLM小得多,但在10亿次以上推理请求的规模下,这仍然是一个相当不平凡的任务。需要明确的是,这相当于英文维基百科的144倍。我没有看到太多关于如何以成本为导向处理此问题的信息,我想解决这个问题。本博客将详细介绍如何计算大规模分类和嵌入的成本和延迟。我们将分析不同的模型架构,对不同硬件选择的成本进行基准测试,并为您提供一个清晰的优化框架。此外,如果您不想亲自经历这个过程,我们还应该能够建立一些直觉。
您可能有几个问题
- 对于10亿个输入,解决我任务最便宜的配置是什么?(批量推理)
- 在考虑延迟的同时,我该怎么做?(高负载使用)
这是实现它的代码:https://github.com/datavistics/encoder-analysis
tl;我不会重现这个,告诉我你发现了什么;dr
通过这个定价,我能够获得以下成本
| 用例 | 分类 | 嵌入 | 视觉嵌入 |
|---|---|---|---|
| 模型 | lxyuan/distilbert-base-multilingual-cased-sentiments-student | Alibaba-NLP/gte-modernbert-base | vidore/colqwen2-v1.0-merged |
| 数据 | tyqiangz/multilingual-sentiments | sentence-transformers/trivia-qa-triplet | openbmb/RLAIF-V-Dataset |
| 硬件类型 | nvidia-L4 ($0.8/小时) |
nvidia-L4 ($0.8/小时) |
nvidia-L4 ($0.8/小时) |
| 10亿输入的成本 | $253.82 | $409.44 | $44,496.51 |
方法
为了评估成本和延迟,我们需要4个关键组件
- 硬件选项:各种硬件以比较成本
- 部署协调器:一种以我们选择的设置部署模型的方式
- 负载测试:一种发送请求并衡量性能的方式
- 推理服务器:一种在所选硬件上高效运行模型的方式
我将利用推理端点作为我的硬件选项,因为它允许我从广泛的硬件选择中进行选择。请注意,您可以将其替换为您选择/考虑的GPU。对于部署协调器,我将使用非常实用的Hugging Face Hub库,它允许我轻松地以编程方式部署模型。
对于推理服务器,我还将使用Infinity,这是一个用于服务基于编码器模型(现在更多了!)的绝佳库。我已经写过关于TEI的内容,这是另一个很棒的库。在处理您的用例时,您应该绝对考虑TEI,尽管本博客侧重于方法论而非框架比较。Infinity具有许多关键优势,例如服务多模态嵌入、针对不同硬件(AMD、Nvidia、CPU和Inferentia)以及运行任何包含尚未集成到huggingface transformer库中的远程代码的新模型。对我来说,其中最重要的是大多数模型默认兼容。
对于负载测试,我将使用Grafana的k6,这是一个用Go语言编写的开源负载测试工具,带有JavaScript接口。它易于配置,性能高,开销低。它有很多内置的执行器,非常有用。它还预先分配虚拟用户(VUs),这比自己随意进行测试更真实。
我将介绍3个用例,它们应该涵盖各种有趣的方面
| 用例 | 模型 | 基础架构 | 参数计数 | 关注点 |
|---|---|---|---|---|
| 分类(文本) | lxyuan/distilbert-base-multilingual-cased-sentiments-student | DistilBertForSequenceClassification | 1.35亿 | 精简的架构小巧快速,对某些用例来说很理想。 |
| 嵌入 | Alibaba-NLP/gte-modernbert-base | ModernBertModel | 1.49亿 | 使用ModernBERT,速度非常快。也可扩展用于长上下文。 |
| 视觉嵌入 | vidore/colqwen2-v1.0-merged | ColQwen2 | 22.1亿 | ColQwen2可以在ColBERT风格的VLM检索中提供独特的见解。 |
优化
优化是一个棘手的问题,有很多方面需要考虑。从宏观层面看,我希望遍历重要的负载测试参数,并找到最适合单个GPU的参数,因为大多数编码器模型都能在一个GPU中运行。一旦我们有了单个GPU的基线成本,就可以通过增加副本GPU的数量来横向扩展GPU数量和吞吐量。
设置
对于每个用例,我将使用以下高级流程
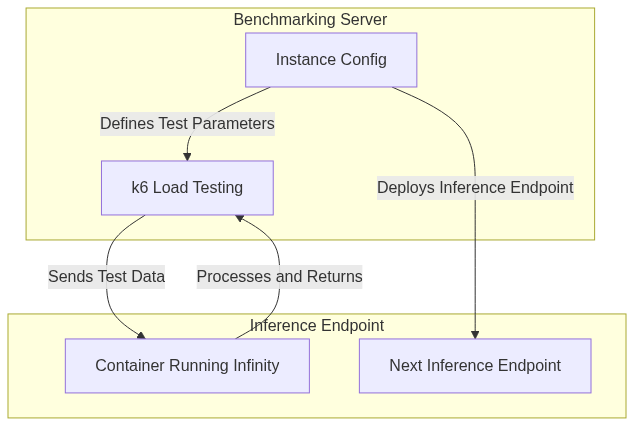
既然您有了代码,请随意根据您的需要调整任何部分
- GPU
- 部署流程
- 实验框架
- 等等
我不会介意的。
负载测试参数
VUs 和 Batch Size 很重要,因为它们会影响我们如何充分利用 GPU 中所有可用的计算资源。足够大的 Batch Size 可以确保我们充分利用 Streaming Multiprocessors 和 VRAM。有些情况下我们会剩下 VRAM,但存在带宽成本,这会阻止吞吐量增加。因此,实验可以帮助我们。VUs 允许我们确保我们充分利用可用的 Batch Size。
这些是我将要测试的主要参数
INFINITY_BATCH_SIZE- 这是在模型中进行批处理前向传递的文档数量
- 太低将无法充分利用 GPU
- 太高将导致 GPU 无法处理大输入
VUs- 这是模拟发送到 K6 的并行客户端请求的虚拟用户数量
- 模拟大量用户可能很困难,并且每台机器都会有所不同。
- GPU
- 推理端点提供多种GPU选择
- 我优先选择了性能/成本比最佳的那些
- CPU
- 我省略了这些,因为Nvidia-T4非常便宜,在轻度测试后,CPU显得没有吸引力。不过,如果用户有兴趣,我留下了一些代码来测试它!
根据您的模型,您可能需要考虑
- 您正在使用的Docker镜像。[
'michaelf34/infinity:0.0.75-trt-onnx','michaelf34/infinity:0.0.75']- 有许多Infinity镜像可以支持不同的后端。您应该考虑哪些最适用于您的硬件/模型/配置。
INFINITY_COMPILE是否要使用torch.compile()文档INFINITY_BETTERTRANSFORMER是否要让torch使用Better Transformer
K6
K6 很棒,因为它允许您预分配虚拟用户 (VUs) 并防止一些潜在的错误。它在发送请求方面非常灵活。我决定以一种特定的方式使用它。
当我调用 K6 实验时,我主要想知道请求的吞吐量和平均延迟,并对所选的负载测试参数进行一些健全性检查。我还想进行一次全面扫描,这意味着需要进行许多实验。
我使用了 `shared-iterations` 执行器 (文档),这意味着 K6 会在虚拟用户之间共享迭代次数。一旦 K6 执行完所有迭代,测试就结束了。这使得我能够设置合理的超时时间,同时也能发出足够的请求,以确保在全面扫描中能够有效地辨别负载测试参数选择。与其它执行器相比,这让我确信我正在模拟客户端在每个虚拟用户上尽可能努力地工作,这应该能显示出最经济的选择。
我使用 `10_000` 个请求†,最大实验时间为 `1 分钟`。所以如果 10_000 个请求在 1 分钟内没有完成,那么该实验就结束了。
export const options = {
scenarios: {
shared_load_test: {
executor: 'shared-iterations',
vus: {{ pre_allocated_vus }},
iterations: 10000,
maxDuration: '1m',
},
},
};
统计
- P95††和平均延迟
- 吞吐量
完整性检查
- 准确性(仅限分类)
- 测试持续时间
- 成功请求
- 格式验证
† 鉴于视觉嵌入的吞吐量低且图像较大,我为它们设置了较少的最大请求数。
†† P95意味着95%的请求在此时间内完成。它代表了大多数用户的最坏情况延迟。
编排
您可以在此处找到将优化工作流整合在一起的3个笔记本
主要目的是定义我的实验,使用正确的参数启动正确的推理端点,并使用正确的参数启动k6来测试端点。
我做了一些设计选择,您可能需要仔细考虑它们是否适合您
- 我以指数方式增加虚拟用户(VU),然后进行二分查找以找到最佳值。
- 我不认为结果是完全可重复的。
- 如果您多次运行相同的测试,您将得到略微不同的结果
- 我使用2%的改进阈值来决定是否继续搜索
分类
介绍
文本分类在大规模应用中具有多种用例,例如垃圾邮件过滤、预训练数据集中的毒性检测等。最初的经典架构是BERT,很快又出现了许多其他架构。请注意,与流行的解码器模型不同,这些模型在使用前需要根据您的任务进行微调。我认为目前以下架构†最值得关注
- DistilBERT
- 良好的任务性能,出色的工程性能
- 它对原始Bert进行了一些架构更改,不兼容TEI的分类
- DeBERTa-v3
- 出色的任务性能
- 工程性能非常慢††,因为其独特的注意力机制难以优化
- ModernBERT
- 使用序列打包和Flash-Attention-2
- 出色的任务性能和出色的工程性能††
† 请注意,对于这些模型,您通常需要根据自己的数据进行微调才能获得良好性能。
†† 我使用“工程性能”来表示预期的延迟/吞吐量
实验
| 类别 | 数值 |
|---|---|
| 模型 | lxyuan/distilbert-base-multilingual-cased-sentiments-student |
| 模型架构 | DistilBERT |
| 数据 | tyqiangz/multilingual-sentiments(`text` 列)平均 100 个 token(最少 50 个),多种语言 |
| 硬件 | nvidia-L4 ($0.8/小时) nvidia-t4 ($0.5/小时) |
| 无限图像 | trt-onnx vs 默认 |
批处理大小 |
[16, 32, 64, 128, 256, 512, 1024] |
虚拟用户数 |
32+ |
我选择DistilBERT作为重点,因为它对于许多应用来说是一个出色的轻量级选择。我比较了两种GPU,`nvidia-t4`和`nvidia-l4`,以及两种Infinity Docker镜像。
结果
您可以在此处以交互式格式查看结果,或者在下方“分析”部分嵌入的空间中查看。这是我运行的实验中最便宜的配置
| 类别 | 最佳价值 |
|---|---|
| 10亿输入的成本 | $253.82 |
| 硬件类型 | nvidia-L4 ($0.8/小时) |
| 无限图像 | 默认 |
批处理大小 |
64 |
虚拟用户数 |
448 |
嵌入
介绍
文本嵌入是一种笼统的说法,用于描述将文本输入投射到语义空间中的任务,在该空间中,相近的点在意义上相似,而遥远的点则不相似(示例如下)。这在RAG中大量使用,是AI搜索的重要组成部分(有些人是其拥护者)。
有大量兼容的架构,您可以在MTEB排行榜中查看性能最佳的架构。
实验
ModernBERT 是自 2020 年 DeBERTa 以来最令人兴奋的编码器发布。它将所有咳咳现代技巧内置到一个古老而熟悉的架构中。它是一个吸引人的实验模型,因为它比其他架构探索得少得多,并且具有更大的潜力。在速度和性能方面有一些改进,但对用户来说最值得注意的是 8k 上下文窗口。请查看这篇博客以获得更全面的理解。
需要注意的是,Flash Attention 2 由于计算能力要求,只能与更现代的 GPU 配合使用,因此我选择跳过 T4 而转而使用 L4。对于重度用户,H100 也会在这里表现出色。
| 类别 | 数值 |
|---|---|
| 模型 | Alibaba-NLP/gte-modernbert-base |
| 模型架构 | ModernBERT |
| 数据 | sentence-transformers/trivia-qa-triplet(`positive` 列)平均 144 个 token,标准差 14。 |
| 硬件 | nvidia-L4 ($0.8/小时) |
| 无限图像 | 默认 |
批处理大小 |
[16, 32, 64, 128, 256, 512, 1024] |
虚拟用户数 |
32+ |
结果
您可以在此处以交互式格式查看结果。这是我运行的实验中最便宜的配置
| 类别 | 最佳价值 |
|---|---|
| 10亿输入的成本 | $409.44 |
| 硬件类型 | nvidia-L4 ($0.8/小时) |
| 无限图像 | 默认 |
批处理大小 |
32 |
虚拟用户数 |
256 |
视觉嵌入
介绍
ColQwen2 是一个视觉检索器,它基于 Qwen2-VL-2B-Instruct,并使用 ColBERT 风格的文本和图像多向量表示。我们可以看到,与我们上面探索的编码器相比,它具有更复杂的架构。

在大规模应用中,有许多用例可能会从中受益,例如电子商务搜索、多模态推荐、企业多模态 RAG 等
ColBERT 风格与我们之前的嵌入用例不同,因为它将输入分解成多个 token,并为每个 token 返回一个向量,而不是为整个输入返回一个向量。您可以在 Jina AI 的此处找到一篇非常棒的教程。这可以带来卓越的语义编码和更好的检索,但速度也更慢,成本也更高。
我对这个实验感到兴奋,因为它探索了两个鲜为人知的概念:视觉嵌入和 ColBERT 风格嵌入†。关于 ColQwen2/VLM,有几点需要注意
- 2B 比我们在这篇博客中讨论的其他模型大约 15 倍
- ColQwen2 拥有一个复杂的架构,包含多个模型,其中包括一个比编码器慢的解码器。
- 图像很容易消耗大量 token。
- API 成本
- 通过 API 发送图像比发送文本慢。
- 如果您在云端,您将面临更高的出口费用。
† 如果您对此新颖有趣的领域感兴趣,请务必查看这篇更详细的博客。
实验
我想尝试像`nvidia-l4`这样小型现代的GPU,因为它应该能够适应20亿参数模型,并且由于价格便宜,也能很好地扩展。和其他嵌入模型一样,我将改变`batch_size`和`vus`。
| 类别 | 数值 |
|---|---|
| 模型 | vidore/colqwen2-v1.0-merged |
| 模型架构 | ColQwen2 |
| 数据 | openbmb/RLAIF-V-Dataset(`image` 列)大多数图像为 ~600x400,大小为 4MB |
| 硬件 | nvidia-L4 ($0.8/小时) |
| 无限图像 | 默认 |
批处理大小 |
[1, 2, 4, 8, 16] |
虚拟用户数 |
1+ |
结果
您可以在此处以交互式格式查看结果。这是我运行的实验中最便宜的配置
| 类别 | 最佳价值 |
|---|---|
| 10亿输入的成本 | $44,496.51 |
| 硬件类型 | nvidia-l4 |
| 无限图像 | 默认 |
批处理大小 |
4 |
虚拟用户数 |
4 |
分析
请查看此空间(derek-thomas/classification-analysis)中关于分类用例的详细分析(隐藏侧边栏并向下滚动查看图表)
结论
每天将分类或嵌入扩展到十亿以上是一个不小的挑战,但通过适当的优化,可以实现成本效益。从我的实验中,出现了一些关键模式
- 硬件至关重要——NVIDIA L4(0.80美元/小时)在性能和成本之间始终提供了最佳平衡,使其成为现代工作负载T4的首选。CPU在大规模应用中不具有竞争力。
- 批处理大小至关重要——批处理大小的最佳点因任务而异,但总的来说,在不触及GPU内存和带宽限制的情况下,最大化批处理大小是实现效率的关键。对于分类,批处理大小64是最佳选择;对于嵌入,则是32。
- 并行性是关键——找到合适的虚拟用户(VU)数量可确保GPU得到充分利用。指数增加+二分查找方法有助于高效地收敛到最佳VU设置。
- ColBERT 风格的视觉嵌入成本高昂——每十亿次嵌入超过 44,000 美元,基于图像的检索比基于文本的任务成本高出两个数量级。
您的数据、硬件、模型等可能有所不同,但我希望您能从提供的方法和代码中找到一些用处。获得估计的最佳方法是使用您自己的配置在您自己的任务上运行此代码。让我们开始探索吧!
特别感谢 andrewrreed/auto-bench 提供的一些灵感,以及 Michael Feil 创建 Infinity。还要感谢 Pedro Cuenca、Erik Kaunismaki 和 Tom Aarsen 帮助我审查。
参考文献
- https://towardsdatascience.com/exploring-the-power-of-embeddings-in-machine-learning-18a601238d6b
- https://yellow-apartment-148.notion.site/AI-Search-The-Bitter-er-Lesson-44c11acd27294f4495c3de778cd09c8d
- https://jina.ai/news/what-is-colbert-and-late-interaction-and-why-they-matter-in-search/
附录
完整性检查
随着复杂度的增加,扩展完整性检查变得很重要。由于我们使用 `subprocess` 和 `jinja` 来调用 `k6`,我感觉离实际测试很远,所以我进行了一些检查。
任务表现
任务性能的目标是确保在特定配置下,我们的表现与预期相似。任务性能在不同任务中会有不同的含义。对于分类,我选择了准确性,而对于嵌入,我跳过了。我们可以查看平均相似度和其他类似指标。对于 ColBERT 样式,由于我们每个请求会得到许多向量,因此会变得更加复杂。
即使对于某些3类分类任务来说,58%的准确率不算差,但这并不重要。目标是确保我们获得预期的任务性能。如果我们发现显著变化(增加或减少),我们应该怀疑并尝试理解原因。
下面是一个来自分类用例的很好的例子,我们可以看到一个极其紧密的分布和一个异常值。经过进一步调查,这个异常值是由于发送的请求数量较少。
您可以在此处通过nbviewer查看交互式结果
失败请求检查
我们应该期望没有失败的请求,因为推理端点有一个队列来处理额外的请求。这适用于所有三种用例:分类、嵌入和视觉嵌入。
sum(df.total_requests - df.successful_requests) 可以让我们查看是否有任何失败的请求。
单调序列——我们是否尝试了足够多的虚拟用户?
如上所述,我们正在使用一个很好的策略,即采用指数增长,然后进行二分查找来找到最佳的虚拟用户(VUs)数量。但是我们怎么知道我们是否尝试了足够的VUs呢?如果我们尝试了更高数量的VUs,并且吞吐量持续增加,那该怎么办?如果是这种情况,我们就会看到VUs和吞吐量之间存在单调递增的关系,那么我们就需要运行更多的测试。
您可以在此处通过nbviewer查看交互式结果
嵌入大小检查
当我们请求嵌入时,返回的嵌入大小与模型类型指定的大小相同是有道理的。您可以在此处查看检查
ColBERT 嵌入计数
我们正在使用 ColBERT 风格的模型进行视觉嵌入,这意味着每张图像我们应该获得多个向量。查看这些向量的分布很有趣,因为它允许我们检查是否有任何意外情况并了解我们的数据。为此,我在实验中存储了 `min_num_vectors`、`avg_num_vectors` 和 `max_num_vectors`。
我们应该会看到所有3个值都有一些变化,但`min_num_vectors`和`max_num_vectors`在不同实验中具有相同的值是可以接受的。
你可以在这里查看检查结果
成本分析
这里有一个简短的描述,但您可以在空间中获得更详细的交互式体验:derek-thomas/classification-analysis
成本节省最佳图像
对于分类用例,我们查看了两种不同的Infinity Images,`default`和`trt-onnx`。哪种更好?最好在相同的设置(GPU,batch_size,VUs)下进行比较。我们可以简单地按这些设置对结果进行分组,然后查看哪种更便宜。

成本与延迟
这是一个关键图表,因为对于许多用例而言,用户能够承受的最大延迟是有限的。通常,如果我们允许延迟增加,我们可以提高吞吐量,从而形成权衡场景。这在我所研究的所有用例中都是如此。拥有帕累托曲线对于帮助可视化这种权衡在哪里非常有用。
成本与 VUs 和批处理大小等高线图
最后,重要的是要对尝试这些不同设置时发生的情况建立直觉。我们会得到漂亮的理想化图表吗?我们会看到意想不到的梯度吗?我们需要在某个区域进行更多探索吗?我们的设置是否存在问题,例如没有隔离环境?所有这些都是很好的问题,有些可能很难回答。
等高线图是通过在由3个维度定义的空间中插入中间点来构建的。有几种值得理解的现象
- 颜色梯度:显示成本水平,颜色越深表示成本越高,颜色越浅表示成本越低。
- 等高线:表示成本水平,有助于识别成本效益高的区域。
- 紧密聚类:(等高线)表示成本随批量大小或虚拟用户(VUs)的微小调整而迅速变化。
我们可以看到一个复杂的等高线图,其中包含来自分类用例的一些有趣结果

但这是视觉嵌入任务的一个更清晰的图表。

Infinity客户端
实际使用时,请考虑使用infinity客户端。在进行基准测试时,使用k6了解可能性是个好习惯。对于实际使用,请使用官方库或类似的东西,以获得以下几点好处
- Base64意味着更小的负载(更快更便宜)
- 维护良好的库应使开发更简洁、更容易。
- 您具有固有的兼容性,这将加快开发速度。
您还可以选择与Infinity后端兼容的OpenAI库。
例如,视觉嵌入可以这样访问
pip install infinity_client && python -c "from infinity_client.vision_client import InfinityVisionAPI"
其他经验教训
- 我尝试在同一GPU上部署多个模型,但没有看到明显的改进,尽管还有剩余的VRAM和GPU处理能力,这可能是由于处理大批次数据的带宽成本造成的。
- 在使用SharedArrays之前,让 K6 处理图像是一件令人头疼的事情。
- 图像数据处理起来可能非常麻烦
- 调试 K6 时,生成脚本的关键是手动运行 K6 并查看输出。
未来改进
- 让测试并行运行,同时管理全局最大`VUs`,将节省大量时间
- 研究更多样化的数据集,看看它们如何影响数字。









