推理端点(专用)文档
定价
加入 Hugging Face 社区
并获得增强的文档体验
开始使用
定价
使用 🤗 推理端点可在专用基础设施上轻松部署机器学习模型。创建端点时,您可以选择要部署的实例类型,并根据每小时费率扩展模型。具有有效订阅和信用卡信息的 Hugging Face 帐户可以使用 🤗 推理端点。在订阅期结束时,当成功部署的端点(准备好提供服务)处于“正在初始化”和“正在运行”状态时,用户或组织帐户将按使用的计算资源收费。
您可以在下方找到 🤗 推理端点所有可用实例的每小时定价,以及费用计算示例。虽然价格按小时显示,但实际费用按分钟计算。
CPU 实例
下表显示了当前可用的 CPU 实例及其每小时定价。如果在应用程序中无法选择实例类型,您需要请求配额才能使用它。
| 提供商 | 实例类型 | 实例大小 | 每小时费率 | vCPU | 内存 | 架构 |
|---|---|---|---|---|---|---|
| aws | intel-spr | x1 | $0.033 | 1 | 2 GB | Intel Sapphire Rapids |
| aws | intel-spr | x2 | $0.067 | 2 | 4 GB | Intel Sapphire Rapids |
| aws | intel-spr | x4 | $0.134 | 4 | 8 GB | Intel Sapphire Rapids |
| aws | intel-spr | x8 | $0.268 | 8 | 16 GB | Intel Sapphire Rapids |
| aws | intel-spr | x16 | $0.536 | 16 | 32 GB | Intel Sapphire Rapids |
| azure | intel-xeon | x1 | $0.060 | 1 | 2 GB | Intel Xeon |
| azure | intel-xeon | x2 | $0.120 | 2 | 4 GB | Intel Xeon |
| azure | intel-xeon | x4 | $0.240 | 4 | 8 GB | Intel Xeon |
| azure | intel-xeon | x8 | $0.480 | 8 | 16 GB | Intel Xeon |
| gcp | intel-spr | x1 | $0.050 | 1 | 2 GB | Intel Sapphire Rapids |
| gcp | intel-spr | x2 | $0.100 | 2 | 4 GB | Intel Sapphire Rapids |
| gcp | intel-spr | x4 | $0.200 | 4 | 8 GB | Intel Sapphire Rapids |
| gcp | intel-spr | x8 | $0.400 | 8 | 16 GB | Intel Sapphire Rapids |
| aws | intel-icl | x1 | $0.032 | 1 | 2 GB | Intel Ice Lake - 从 2025 年 7 月起弃用 |
| aws | intel-icl | x2 | $0.064 | 2 | 4 GB | Intel Ice Lake - 从 2025 年 7 月起弃用 |
| aws | intel-icl | x4 | $0.128 | 4 | 8 GB | Intel Ice Lake - 从 2025 年 7 月起弃用 |
| aws | intel-icl | x8 | $0.256 | 8 | 16 GB | Intel Ice Lake - 从 2025 年 7 月起弃用 |
GPU 实例
下表显示了当前可用的 GPU 实例及其每小时定价。如果在应用程序中无法选择实例类型,您需要请求配额才能使用它。
| 提供商 | 实例类型 | 实例大小 | 每小时费率 | GPU | 内存 | 架构 |
|---|---|---|---|---|---|---|
| aws | nvidia-t4 | x1 | $0.5 | 1 | 14 GB | NVIDIA T4 |
| aws | nvidia-t4 | x4 | $3 | 4 | 56 GB | NVIDIA T4 |
| aws | nvidia-l4 | x1 | $0.8 | 1 | 24 GB | NVIDIA L4 |
| aws | nvidia-l4 | x4 | $3.8 | 4 | 96 GB | NVIDIA L4 |
| aws | nvidia-a10g | x1 | $1 | 1 | 24 GB | NVIDIA A10G |
| aws | nvidia-a10g | x4 | $5 | 4 | 96 GB | NVIDIA A10G |
| aws | nvidia-l40s | x1 | $1.8 | 1 | 48 GB | NVIDIA L40S |
| aws | nvidia-l40s | x4 | $8.3 | 4 | 192 GB | NVIDIA L40S |
| aws | nvidia-l40s | x8 | $23.5 | 8 | 384 GB | NVIDIA L40S |
| aws | nvidia-a100 | x1 | $2.5 | 1 | 80 GB | NVIDIA A100 |
| aws | nvidia-a100 | x2 | $5 | 2 | 160 GB | NVIDIA A100 |
| aws | nvidia-a100 | x4 | $10 | 4 | 320 GB | NVIDIA A100 |
| aws | nvidia-a100 | x8 | $20 | 8 | 640 GB | NVIDIA A100 |
| aws | nvidia-h200 | x1 | $5 | 1 | 141 GB | NVIDIA H200 |
| aws | nvidia-h200 | x2 | $10 | 2 | 282 GB | NVIDIA H200 |
| aws | nvidia-h200 | x4 | $20 | 4 | 564 GB | NVIDIA H200 |
| aws | nvidia-h200 | x8 | $40 | 8 | 1128 GB | NVIDIA H200 |
| gcp | nvidia-t4 | x1 | $0.5 | 1 | 16 GB | NVIDIA T4 |
| gcp | nvidia-l4 | x1 | $0.7 | 1 | 24 GB | NVIDIA L4 |
| gcp | nvidia-l4 | x4 | $3.8 | 4 | 96 GB | NVIDIA L4 |
| gcp | nvidia-a100 | x1 | $3.6 | 1 | 80 GB | NVIDIA A100 |
| gcp | nvidia-a100 | x2 | $7.2 | 2 | 160 GB | NVIDIA A100 |
| gcp | nvidia-a100 | x4 | $14.4 | 4 | 320 GB | NVIDIA A100 |
| gcp | nvidia-a100 | x8 | $28.8 | 8 | 640 GB | NVIDIA A100 |
| gcp | nvidia-h100 | x1 | $10 | 1 | 80 GB | NVIDIA H100 |
| gcp | nvidia-h100 | x2 | $20 | 2 | 160 GB | NVIDIA H100 |
| gcp | nvidia-h100 | x4 | $40 | 4 | 320 GB | NVIDIA H100 |
| gcp | nvidia-h100 | x8 | $80 | 8 | 640 GB | NVIDIA H100 |
加速器实例
下表显示了当前可用的自定义加速器实例及其每小时定价。如果在应用程序中无法选择实例类型,您需要请求配额才能使用它。
| 提供商 | 实例类型 | 实例大小 | 每小时费率 | 加速器 | 加速器内存 | RAM | 架构 |
|---|---|---|---|---|---|---|---|
| aws | inf2 | x1 | $0.75 | 1 | 32 GB | 14.5 GB | AWS Inferentia2 |
| aws | inf2 | x12 | $12 | 12 | 384 GB | 760 GB | AWS Inferentia2 |
| gcp | tpu | 1x1 | $1.2 | 1 | 16 GB | 44 GB | Google TPU v5e |
| gcp | tpu | 2x2 | $4.75 | 4 | 64 GB | 186 GB | Google TPU v5e |
| gcp | tpu | 2x4 | $9.5 | 8 | 128 GB | 380 GB | Google TPU v5e |
定价示例
以下定价场景示例展示了如何计算成本。您可以在上表中找到所有实例类型和大小的每小时费率。使用以下公式计算成本:
instance hourly rate * ((hours * # min replica) + (scale-up hrs * # additional replicas))基本端点
- AWS CPU intel-spr x2 (2 个 vCPU 4GB RAM)
- 自动扩缩(最少 1 个副本,最多 1 个副本)
每小时费用
instance hourly rate * (hours * # min replica) = hourly cost
$0.067/hr * (1hr * 1 replica) = $0.067/hr每月费用
instance hourly rate * (hours * # min replica) = monthly cost
$0.064/hr * (730hr * 1 replica) = $46.72/month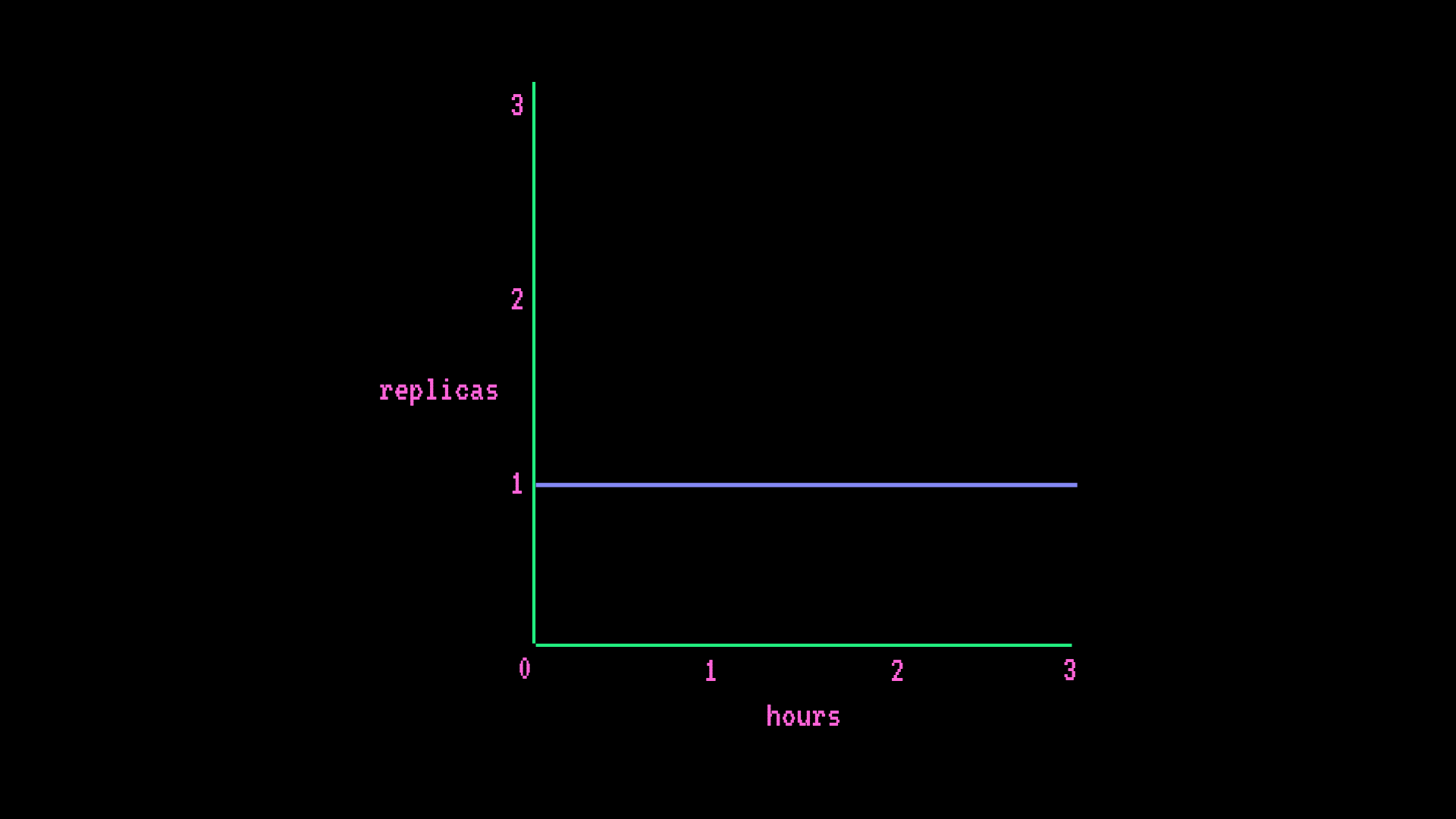
高级端点
- AWS GPU 小型(1 个 GPU 14GB RAM)
- 自动扩缩(最少 1 个副本,最多 3 个副本),每小时流量高峰会将端点从 1 个副本扩缩到 3 个副本,持续 15 分钟
每小时费用
instance hourly rate * ((hours * # min replica) + (scale-up hrs * # additional replicas)) = hourly cost
$0.5/hr * ((1hr * 1 replica) + (0.25hr * 2 replicas)) = $0.75/hr每月费用
instance hourly rate * ((hours * # min replica) + (scale-up hrs * # additional replicas)) = monthly cost
$0.5/hr * ((730hr * 1 replica) + (182.5hr * 2 replicas)) = $547.5/month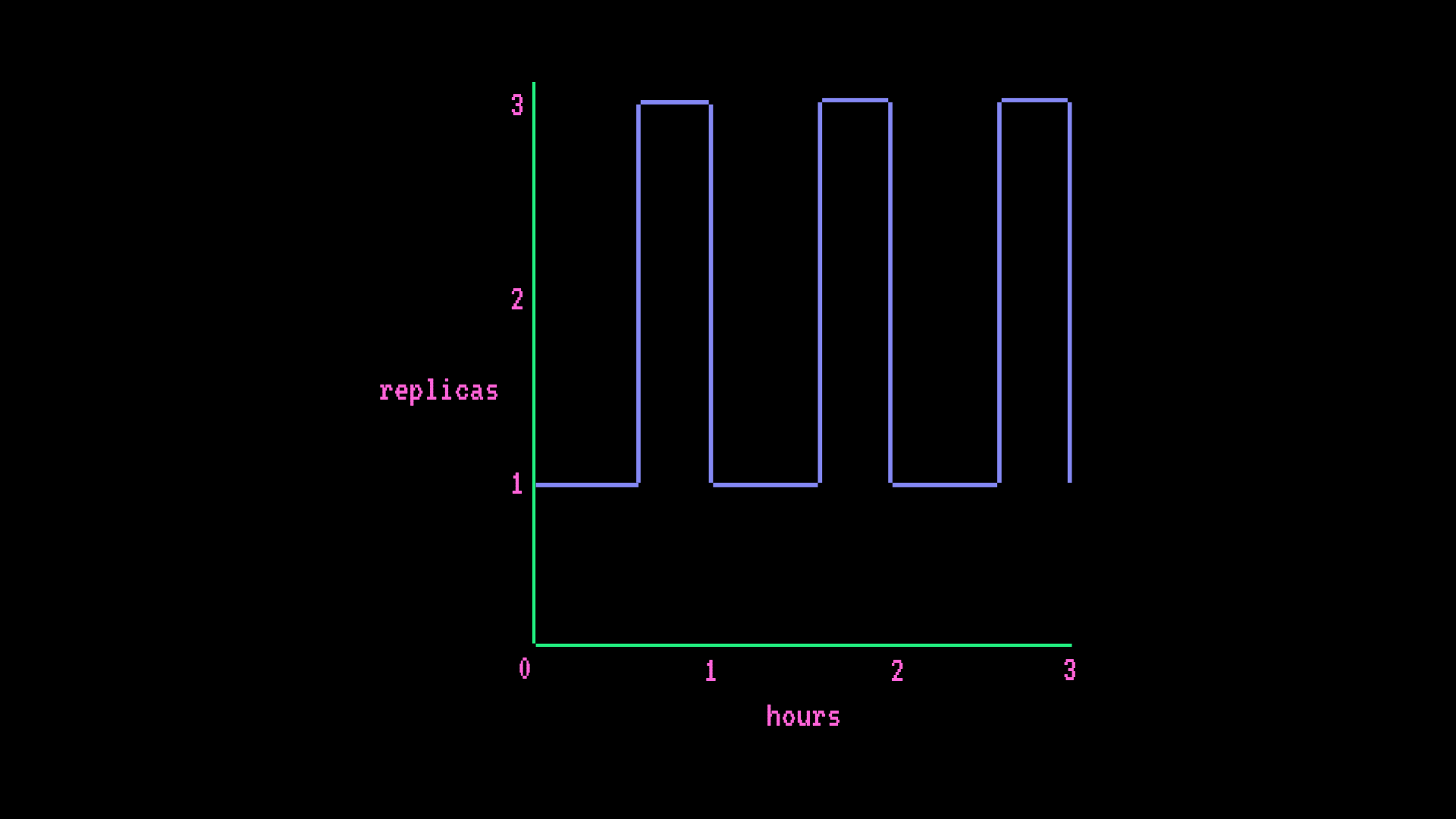
配额
现在可在推理仪表板 https://ui.endpoints.huggingface.co 的“已用配额”下查看列出的可用配额。
显示的数字将引用已用实例数/可用实例配额。*暂停*的端点不会计入“已用”配额。*缩减到零*的端点将被计为“已用”配额——如果您想解锁此配额,只需暂停缩减到零的端点即可。
如果您想增加配额分配,请联系我们。PRO 用户和 Enterprise Hub 组织在请求时将获得更高的配额。
< > 在 GitHub 上更新