推理端点(专用)文档
高级设置(实例类型、自动扩缩、版本控制)
并获得增强的文档体验
开始使用
高级设置(实例类型、自动扩缩、版本控制)
我们在创建你的第一个端点中已经看到部署一个端点是多么快速和简单,但这并非全部。在创建过程中,选择云提供商和区域后,点击 [高级配置] 按钮,将显示更多端点的配置选项。
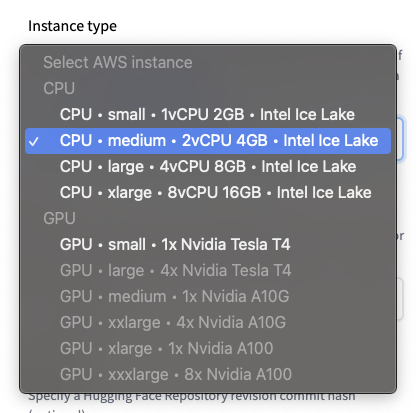
实例类型
🤗 Inference Endpoints 提供了一系列精选的 CPU 和 GPU 实例。
注意:你的 Hugging Face 账户对 CPU 和 GPU 实例有容量配额。如需增加配额或请求新的实例类型,请与我们联系。
默认值:CPU-medium
副本自动扩缩
设置你希望端点根据使用率自动扩缩的副本范围(最小值 (>=1) 和最大值)。
默认值:最小 1;最大 2
任务
选择一个支持的机器学习任务,或设置为自定义。自定义可以/应该在你未使用基于 Transformers 的模型或希望自定义推理流水线时使用,请参阅创建你自己的推理处理器。
默认值:从模型仓库派生。
框架
对于 Transformers 模型,如果 PyTorch 和 TensorFlow 权重都可用,你可以选择使用哪种模型权重。这将有助于减小镜像制品的大小,并加速端点的启动/扩缩。
默认值:如果可用,则为 PyTorch。
版本
创建端点时,可以为其源 Hugging Face 模型仓库指定一个特定的版本提交(revision commit)。这允许你对端点进行版本控制,并确保即使你更新了模型仓库,也始终使用相同的权重。
默认值:最新的提交。
图像
允许你提供想要部署到端点中的自定义容器镜像。这些可以是公共镜像,例如 tensorflow/serving:2.7.3,也可以是托管在 Docker Hub、AWS ECR、Azure ACR 或 Google GCR 上的私有镜像。
更多关于如何“使用你自己的自定义容器”的内容见下文。
< > 在 GitHub 上更新