优势 Actor-Critic (A2C)






Hugging Face 深度强化学习课程 🤗 第 7 单元
⚠️ 本文的最新版本已发布在此处 👉 https://huggingface.co/deep-rl-course/unit1/introduction
本文是深度强化学习课程的一部分。这是一个从入门到精通的免费课程。请在此处查看课程大纲 here.

⚠️ 本文的最新版本已发布在此处 👉 https://huggingface.co/deep-rl-course/unit1/introduction
本文是深度强化学习课程的一部分。这是一个从入门到精通的免费课程。请在此处查看课程大纲 here.
在第 5 单元中,我们学习了第一个基于策略的算法,名为 Reinforce。在基于策略的方法中,我们旨在直接优化策略,而不使用值函数。更准确地说,Reinforce 属于*基于策略方法*的一个子类,称为*策略梯度方法*。该子类通过使用梯度上升法估计最优策略的权重来直接优化策略。
我们看到 Reinforce 效果不错。然而,由于我们使用蒙特卡洛采样来估计回报(我们使用整个回合来计算回报),策略梯度估计存在显著的方差。
请记住,策略梯度估计是回报最陡峭的增长方向。也就是说,如何更新我们的策略权重,以便使导致良好回报的动作有更高的被选择概率。我们将在本单元进一步研究的蒙特卡洛方差,会导致训练速度变慢,因为我们需要大量样本来减轻它。
今天我们将学习 Actor-Critic 方法,这是一种结合了基于值和基于策略的方法的混合架构,通过减少方差来帮助稳定训练。
- 一个 Actor(演员),控制我们智能体的行为方式(基于策略的方法)
- 一个 Critic(评论家),衡量所采取动作的好坏(基于值的方法)
我们将研究其中一种混合方法,称为优势 Actor Critic (A2C),并使用 Stable-Baselines3 在机器人环境中训练我们的智能体。我们将训练两个智能体学会走路:
- 一个双足步行者 🚶
- 一只蜘蛛 🕷️

听起来很刺激吧?我们开始吧!
Reinforce 算法中的方差问题
在 Reinforce 中,我们希望根据回报的高低成比例地增加轨迹中动作的概率。

- 如果回报高,我们将提高(状态,动作)组合的概率。
- 反之,如果回报低,它将降低(状态,动作)组合的概率。
这个回报 是使用*蒙特卡洛采样*计算的。实际上,我们收集一条轨迹并计算折扣回报,然后使用这个分数来增加或减少该轨迹中每个动作的概率。如果回报好,所有动作都将通过增加其被采取的可能性而得到“加强”。
这种方法的优点是它是无偏的。因为我们没有估计回报,我们只使用我们获得的真实回报。
但问题是方差很高,因为由于环境的随机性(回合中的随机事件)和策略的随机性,轨迹可能导致不同的回报。因此,相同的起始状态可能导致非常不同的回报。正因为如此,从同一状态开始的回报在不同回合之间可能会有很大差异。
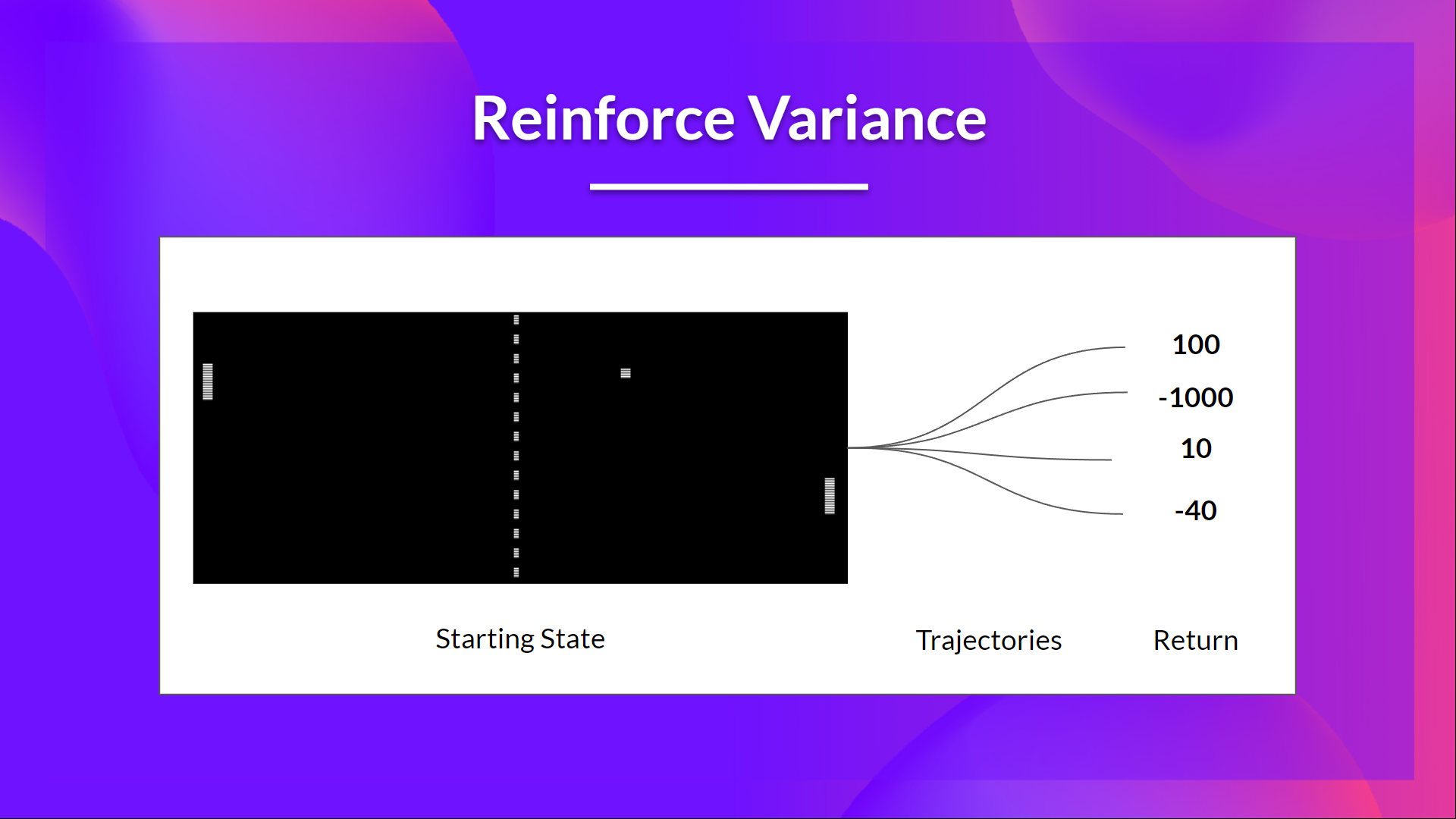
解决方案是通过使用大量轨迹来减轻方差,希望在任何一条轨迹中引入的方差能在总体上减少,并提供一个“真实”的回报估计。
然而,显著增加批次大小会降低样本效率。因此,我们需要找到额外的机制来减少方差。
如果你想更深入地了解深度强化学习中的方差和偏差权衡问题,可以查看这两篇文章: - 理解(深度)强化学习中的偏差/方差权衡 - 强化学习中的偏差-方差权衡
优势 Actor-Critic (A2C)
使用 Actor-Critic 方法减少方差
减少 Reinforce 算法方差并更快、更好地训练我们的智能体的解决方案是使用基于策略和基于值的方法的组合:Actor-Critic 方法。
要理解 Actor-Critic,想象你在玩一个电子游戏。你可以和一个会给你反馈的朋友一起玩。你是 Actor(演员),你的朋友是 Critic(评论家)。

一开始你不知道怎么玩,所以你随机尝试一些动作。Critic 观察你的动作并提供反馈。
从这些反馈中学习, 你将更新你的策略,并在玩这个游戏时表现得更好。
另一方面,你的朋友(Critic)也会更新他提供反馈的方式,以便下次能做得更好。
这就是 Actor-Critic 背后的思想。我们学习两个函数近似:
一个策略,它控制我们的智能体如何行动:
一个值函数,通过衡量所采取动作的好坏来辅助策略更新:
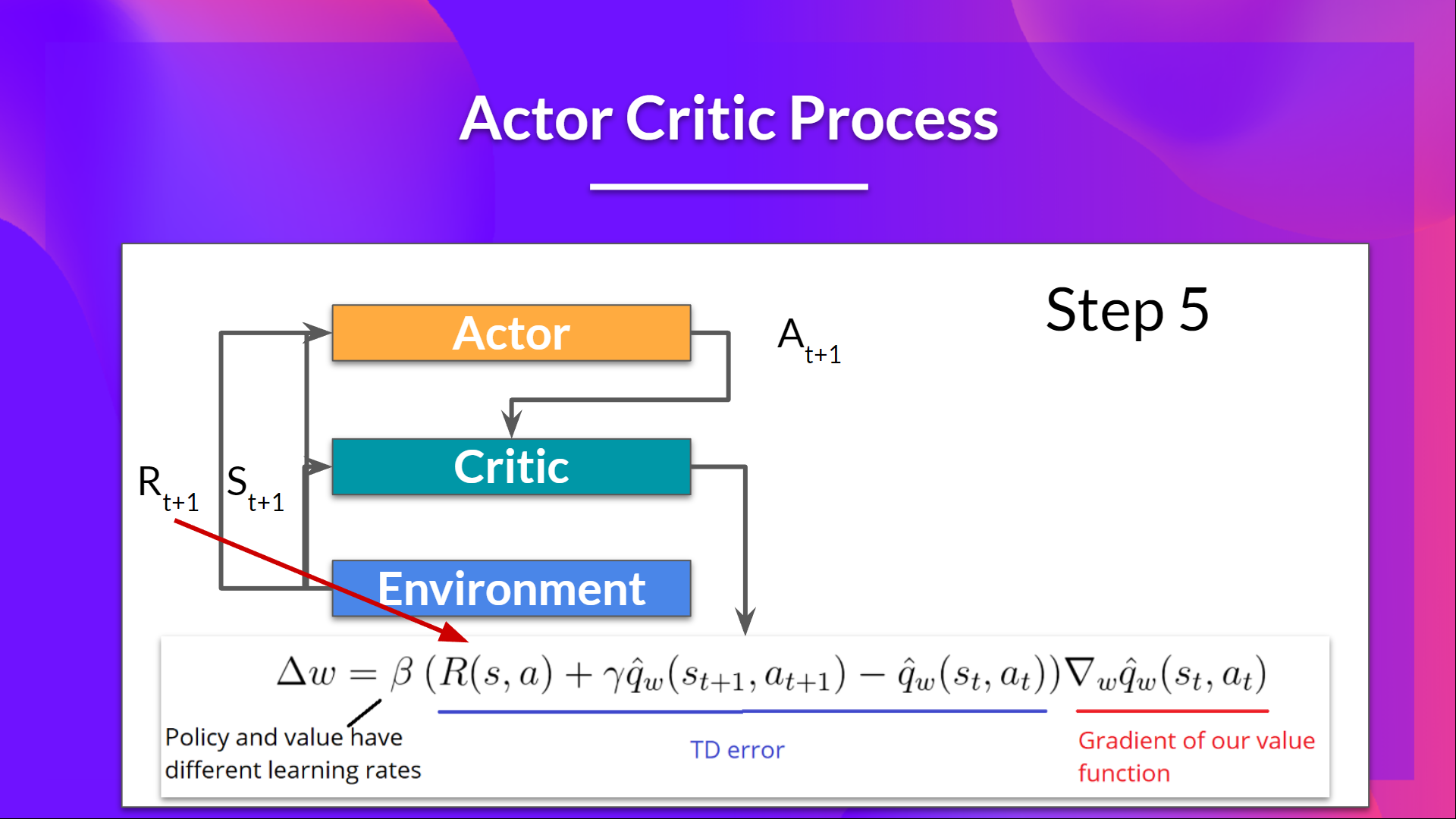
Actor-Critic 流程
现在我们已经了解了 Actor-Critic 的大概情况,让我们深入探讨一下 Actor 和 Critic 在训练过程中是如何共同进步的。
正如我们所见,Actor-Critic 方法中有两个函数近似(两个神经网络):
- Actor,一个由 theta 参数化的策略函数:
- Critic,一个由 w 参数化的值函数:
我们来看看训练过程,以了解 Actor 和 Critic 是如何被优化的。
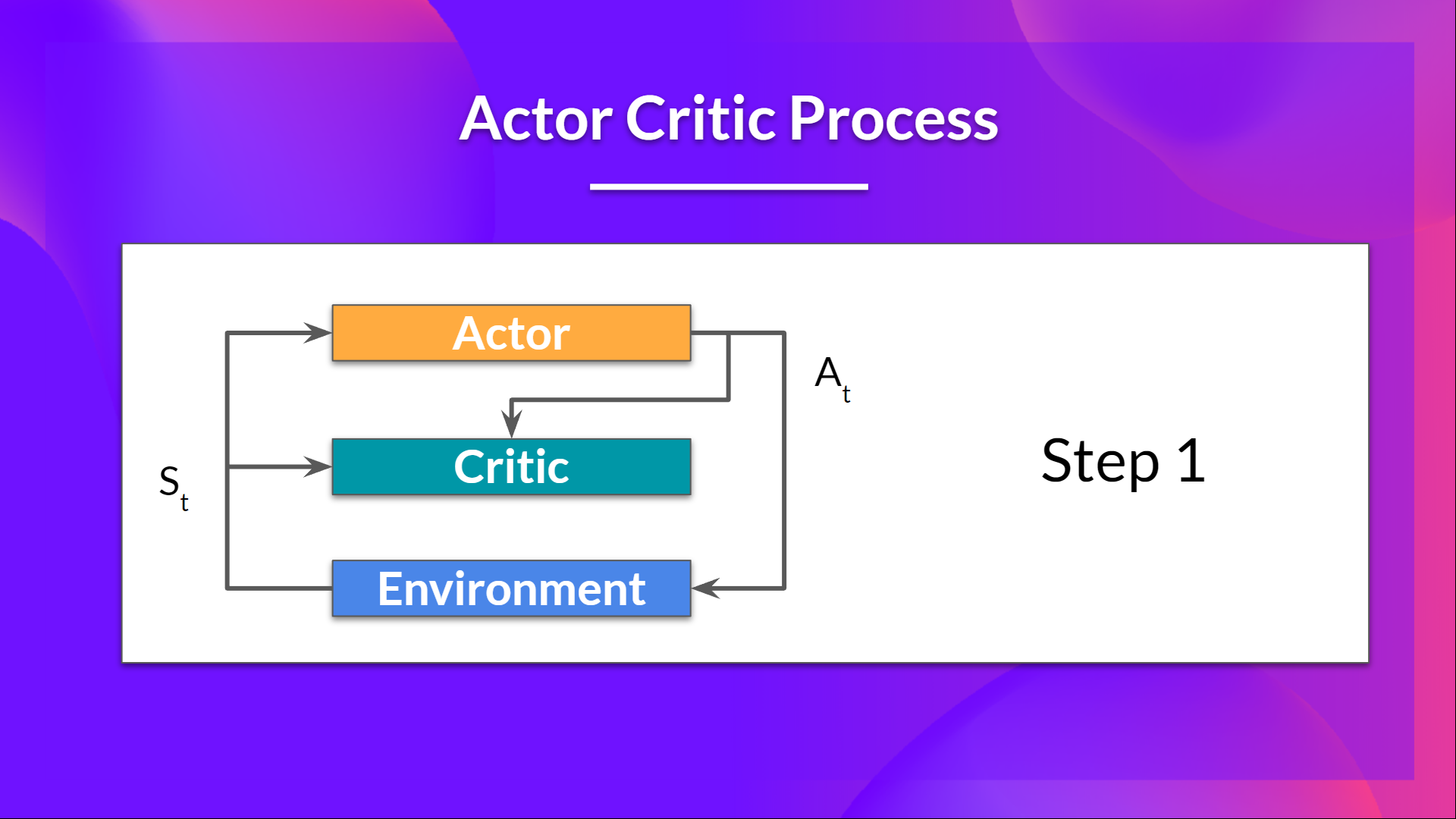
在每个时间步 t,我们从环境中获得当前状态 ,并将其作为输入传递给我们的 Actor 和 Critic。
我们的策略接收状态并输出一个动作 。
- Critic 也将该动作作为输入,并使用 和 ,计算在该状态下采取该动作的价值:即 Q 值。
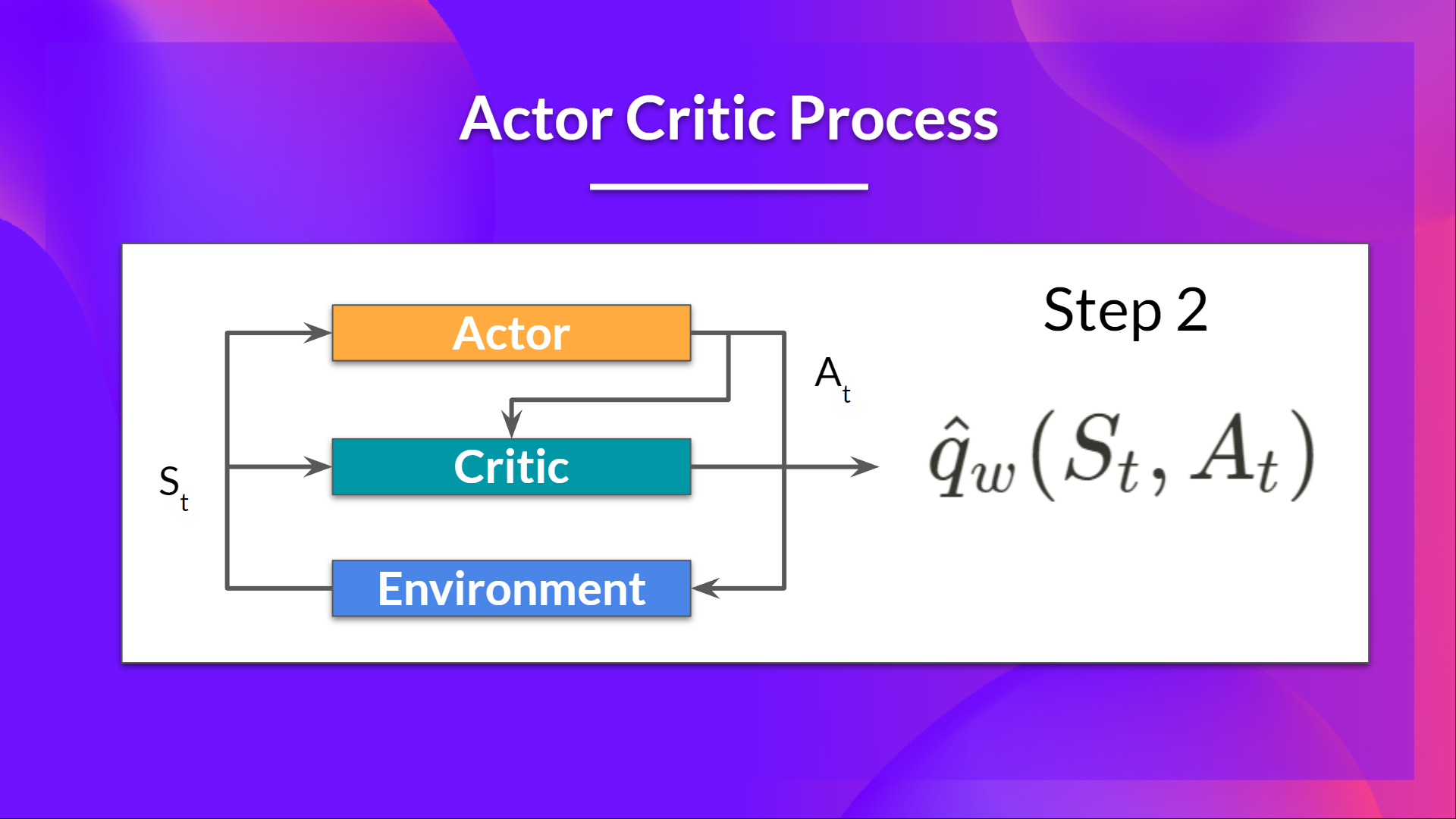
- 在环境中执行的动作 会产生一个新的状态 和一个奖励 。
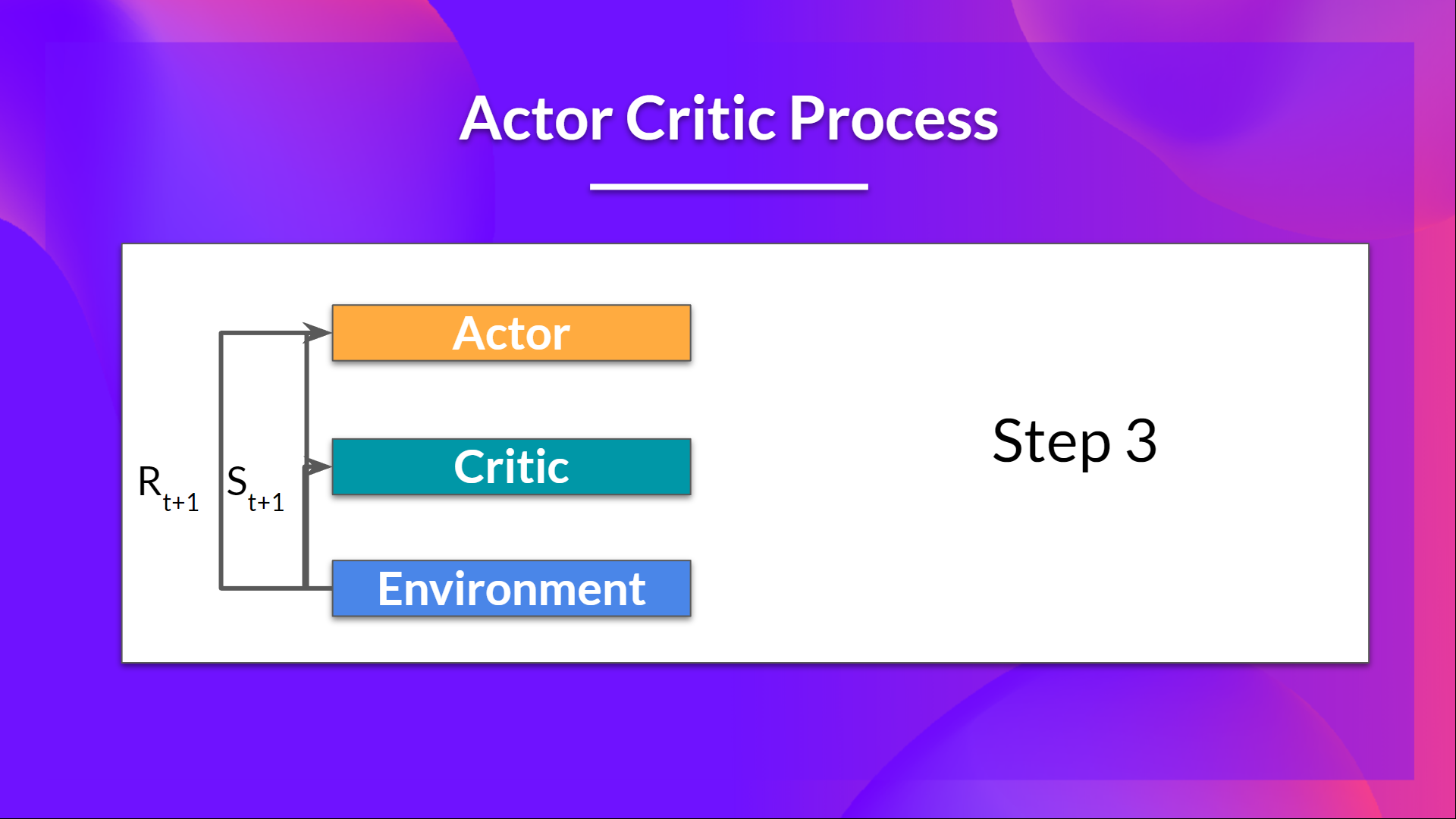
- Actor 使用 Q 值更新其策略参数。

得益于其更新后的参数,Actor 会在给定新状态 的情况下,生成在 要采取的下一个动作。
然后 Critic 更新其值参数。
优势 Actor-Critic (A2C)
我们可以通过使用优势函数作为 Critic 而不是动作值函数来进一步稳定学习。
其思想是,优势函数计算的是在该状态下采取该动作相比于该状态的平均价值有多好。它是从状态-动作对中减去状态的平均价值。

换句话说,这个函数计算的是如果我们在这个状态下采取这个动作,相比于我们在这个状态下获得的平均奖励,我们能获得的额外奖励。
额外的奖励是超出该状态期望价值的部分。
- 如果 A(s,a) > 0:我们的梯度将朝那个方向推动。
- 如果 A(s,a) < 0(我们的动作比该状态的平均价值差),我们的梯度将朝相反方向推动。
实现这个优势函数的问题在于它需要两个值函数—— 和 。幸运的是, 我们可以使用 TD 误差作为优势函数的一个良好估计。

使用 PyBullet 进行机器人模拟的优势 Actor Critic (A2C) 🤖
现在你已经学习了优势 Actor Critic (A2C) 背后的理论, 你已经准备好使用 Stable-Baselines3 在机器人环境中训练你的 A2C 智能体了 。
点击此处开始教程 👉 https://colab.research.google.com/github/huggingface/deep-rl-class/blob/main/unit7/unit7.ipynb
用于与同学比较结果的排行榜 🏆 👉 https://huggingface.co/spaces/chrisjay/Deep-Reinforcement-Learning-Leaderboard
结论
恭喜你完成本章!这里有很多信息。也恭喜你完成了教程。🥳
如果你对所有这些元素仍然感到困惑,这很正常。 我和所有学习强化学习的人都有过同样的感受。
在继续之前,花点时间理解这些材料。同时,请查看我们在本文和教学大纲中提供的额外阅读材料以进行更深入的学习 👉 https://github.com/huggingface/deep-rl-class/blob/main/unit7/README.md
不要犹豫,在其他环境中训练你的 Agent。最好的学习方式是自己动手尝试!
在下一个单元中,我们将学习使用近端策略优化(Proximal Policy Optimization)来改进 Actor-Critic 方法。
别忘了与想要学习的朋友分享 🤗!
最后,我们希望通过您的反馈来迭代改进和更新课程。如果您有任何建议,请填写此表格 👉 https://forms.gle/3HgA7bEHwAmmLfwh9

