近端策略优化 (Proximal Policy Optimization, PPO)







Hugging Face 深度强化学习课程 🤗 第八单元
⚠️ 本文的最新更新版本请点击此处 👉 https://huggingface.co/deep-rl-course/unit1/introduction
本文是深度强化学习课程的一部分。这是一个从入门到精通的免费课程。请在此处查看课程大纲 here. 
⚠️ 本文的最新更新版本请点击此处 👉 https://huggingface.co/deep-rl-course/unit1/introduction
本文是深度强化学习课程的一部分。这是一个从入门到精通的免费课程。请在此处查看课程大纲 here.
在上一单元中,我们学习了优势 Actor-Critic (A2C),这是一种结合了基于价值和基于策略方法的混合架构,通过以下方式减少方差来稳定训练:
- Actor(演员) 控制 我们 Agent 的行为方式 (基于策略的方法)。
- Critic(评论家) 衡量 所采取行动的好坏 (基于价值的方法)。
今天我们将学习近端策略优化 (Proximal Policy Optimization, PPO),这是一种通过避免过大的策略更新来提高 Agent 训练稳定性的架构。为此,我们使用一个比率来表示当前策略和旧策略之间的差异,并将此比率裁剪到一个特定范围 内。
这样做可以确保 我们的策略更新不会过大,从而使训练更加稳定。
然后,在理论之后,我们将使用 PyTorch 从头开始编写 PPO 架构,并使用 CartPole-v1 和 LunarLander-v2 对我们的实现进行稳健性测试。
听起来很刺激吧?我们开始吧!
PPO 背后的直觉
近端策略优化 (PPO) 的思想是,我们希望通过限制在每个训练周期对策略进行的更改来提高策略的训练稳定性:我们希望避免过大的策略更新。
原因有二:
- 我们从经验上知道,训练期间较小的策略更新更有可能收敛到最优解。
- 策略更新中过大的一步可能会导致“跌落悬崖”(得到一个糟糕的策略),并且需要很长时间甚至无法恢复。

因此,使用 PPO,我们保守地更新策略。为此,我们需要使用当前策略和旧策略之间的比率计算来衡量当前策略与之前策略的变化程度。我们将这个比率裁剪在一个范围 内,这意味着我们消除了当前策略偏离旧策略太远的动机(因此称为近端策略项)。
引入裁剪替代目标函数 (Clipped Surrogate Objective)
回顾:策略目标函数
让我们回顾一下 Reinforce 算法中需要优化的目标函数:
其思想是,通过对这个函数进行梯度上升(等同于对此函数的负值进行梯度下降),我们能够促使我们的 Agent 采取能带来更高回报的行动,并避免有害的行动。
然而,问题出在步长上
- 步长太小,训练过程会太慢
- 步长太大,训练中会有太大的不确定性
在这里,PPO 的思想是通过一个名为*裁剪替代目标函数 (Clipped surrogate objective function)* 的新目标函数来约束我们的策略更新,该函数使用裁剪将策略变化限制在一个小范围内。
这个新函数旨在避免破坏性的大权重更新。

让我们研究每个部分,以理解其工作原理。
比率函数

这个比率是这样计算的

它是当前策略下在状态 采取行动 的概率与前一策略下采取该行动的概率之比。
正如我们所见, 表示当前策略和旧策略之间的概率比。
- 如果 ,那么在状态 下采取行动 在当前策略中比在旧策略中更有可能发生。
- 如果 在 0 和 1 之间,那么该行动在当前策略中比在旧策略中发生的可能性更小。
因此,这个概率比是一种估计旧策略和当前策略之间差异的简单方法。
裁剪替代目标函数的未裁剪部分

这个比率可以替代我们在策略目标函数中使用的对数概率。这就得到了新目标函数的左半部分:将比率乘以优势值。

然而,如果没有约束,如果所采取的行动在当前策略中比在旧策略中更有可能发生,这将导致一个显著的策略梯度步长,从而导致过度的策略更新。
裁剪替代目标函数的裁剪部分

因此,我们需要通过惩罚导致比率偏离 1 的变化来约束此目标函数(在论文中,比率只能在 0.8 到 1.2 之间变化)。
通过裁剪比率,我们确保不会有太大的策略更新,因为当前策略不能与旧策略相差太大。
为此,我们有两种解决方案
- TRPO (Trust Region Policy Optimization, 信赖域策略优化) 在目标函数之外使用 KL 散度约束来限制策略更新。但这种方法实现复杂且计算耗时较多。
- PPO 通过其裁剪替代目标函数直接在目标函数中裁剪概率比。
这个裁剪部分是 rt(theta) 被裁剪在 之间的一个版本。
有了裁剪替代目标函数,我们就有两个概率比率,一个未裁剪的,一个裁剪在一定范围内的(在 之间,epsilon 是一个帮助我们定义这个裁剪范围的超参数,在论文中 )。
然后,我们取裁剪后和未裁剪目标的最小值,因此最终目标是未裁剪目标的一个下界(悲观界限)。
取裁剪和未裁剪目标的最小值意味着我们将根据比率和优势情况选择裁剪或未裁剪的目标。
可视化裁剪替代目标函数
别担心。如果现在这看起来很复杂,这是正常的。但我们将看到这个裁剪替代目标函数是什么样子,这将帮助你更好地形象化正在发生的事情。
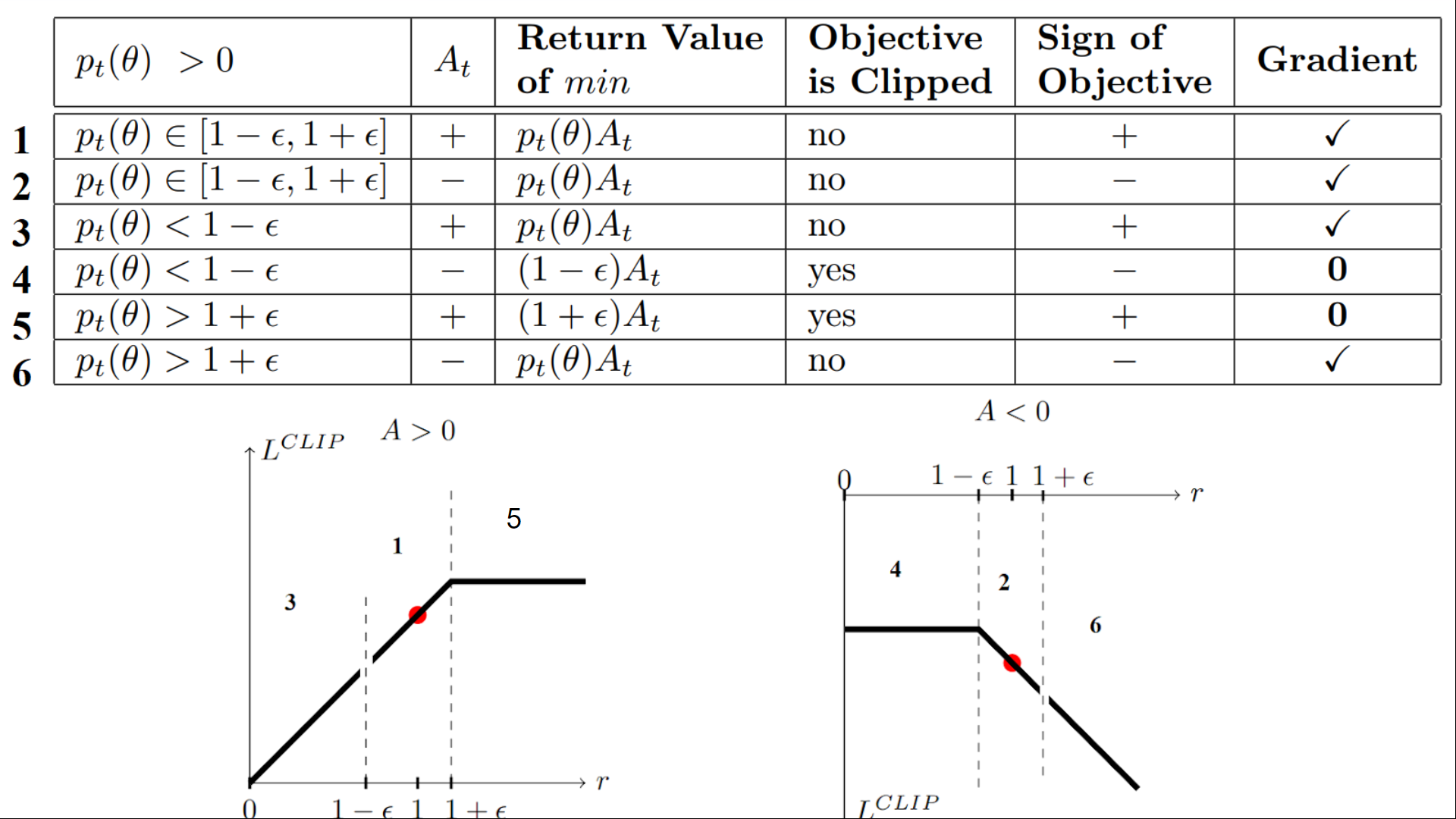
我们有六种不同的情况。首先记住,我们在裁剪和未裁剪的目标之间取最小值。
情况 1 和 2:比率在范围内
在情况 1 和 2 中,裁剪不适用,因为比率在范围 内。
在情况 1 中,我们有一个正的优势值:该行动优于该状态下所有行动的平均值。因此,我们应该鼓励我们当前的策略增加在该状态下采取该行动的概率。
由于比率在区间内,我们可以增加我们的策略在该状态下采取该行动的概率。
在情况 2 中,我们有一个负的优势值:该行动比该状态下所有行动的平均值要差。因此,我们应该不鼓励我们当前的策略在该状态下采取该行动。
由于比率在区间内,我们可以降低我们的策略在该状态下采取该行动的概率。
情况 3 和 4:比率低于范围
如果概率比低于 ,那么在该状态下采取该行动的概率比旧策略要低得多。
如果像情况 3 那样,优势估计是正的 (A>0),那么你希望增加在该状态下采取该行动的概率。
但如果像情况 4 那样,优势估计是负的,我们不希望进一步降低在该状态下采取该行动的概率。因此,梯度=0(因为我们在一条平线上),所以我们不更新权重。
情况 5 和 6:比率高于范围
如果概率比高于 ,那么当前策略在该状态下采取该行动的概率远高于旧策略。
如果像情况 5 那样,优势值为正,我们不希望变得太贪心。我们已经比旧策略有更高的概率在该状态下采取该行动。因此,梯度=0(因为我们在一条平线上),所以我们不更新权重。
如果像情况 6 那样,优势值为负,我们希望降低在该状态下采取该行动的概率。
总而言之,我们只用未裁剪的目标部分来更新策略。当最小值为裁剪的目标部分时,我们不更新策略权重,因为梯度将等于 0。
所以我们只在以下情况下更新策略:
- 我们的比率在范围 内。
- 我们的比率超出了范围,但优势值导致其更接近范围
- 比率低于范围,但优势值 > 0
- 比率高于范围,但优势值 < 0
你可能想知道为什么当最小值为裁剪比率时,梯度为 0。 当比率被裁剪时,这种情况下的导数将不是 的导数,而是 或 的导数,这两者都等于 0。
总而言之,由于这个裁剪替代目标,我们限制了当前策略可以偏离旧策略的范围。因为我们消除了概率比移动到区间外的动机,因为裁剪会影响梯度。如果比率 > 或 < ,梯度将等于 0。
PPO Actor-Critic 风格的最终裁剪替代目标损失函数是这样的,它是裁剪替代目标函数、价值损失函数和熵奖励的组合
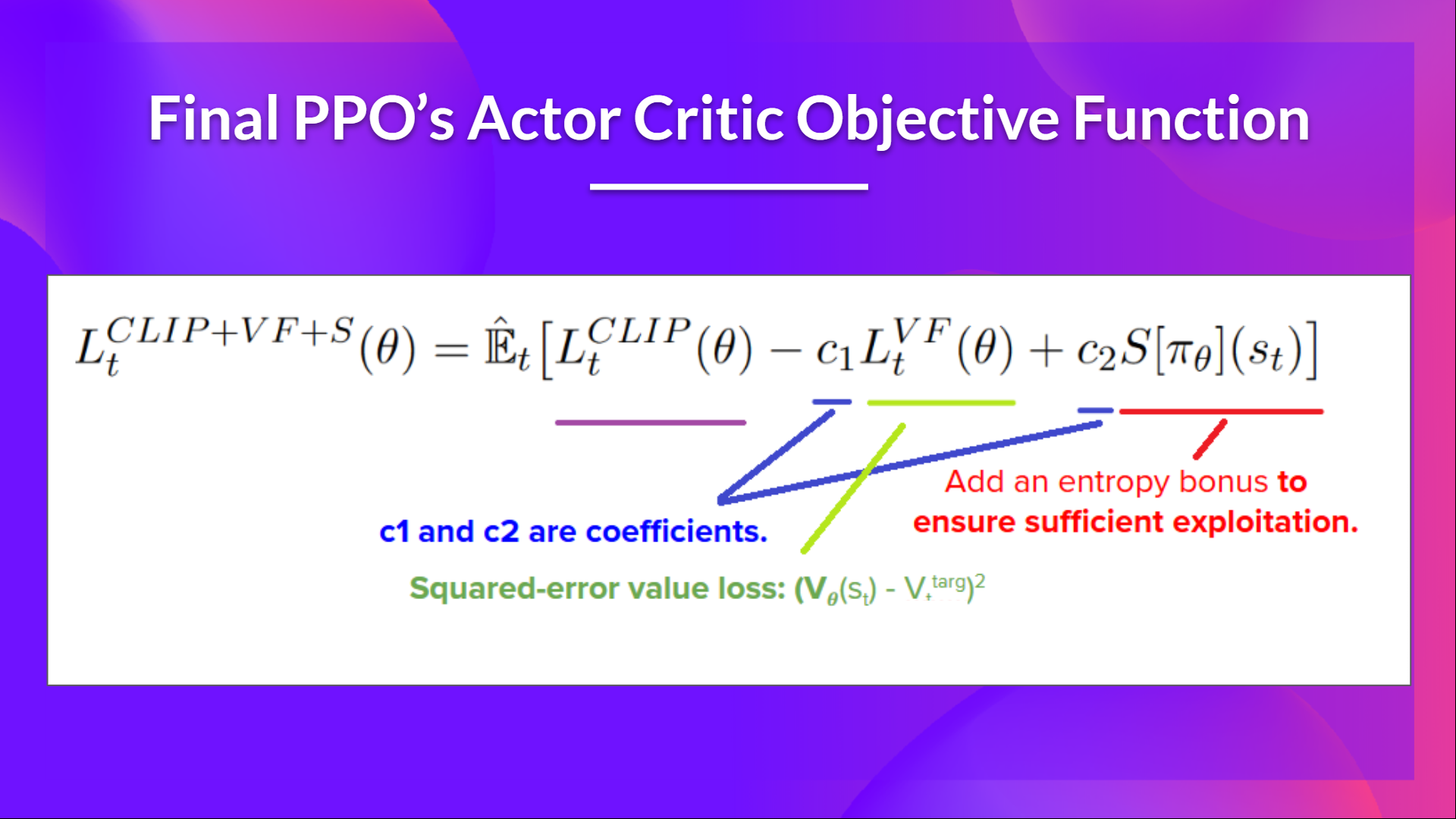
这部分相当复杂。花些时间通过查看表格和图表来理解这些情况。你必须理解为什么这样做是合理的。如果你想深入了解,最好的资源是 Daniel Bick 的文章 《迈向对近端策略优化的连贯自洽解释》(Towards Delivering a Coherent Self-Contained Explanation of Proximal Policy Optimization),尤其是第 3.4 部分。
让我们来编写 PPO Agent
既然我们已经学习了 PPO 背后的理论,理解其工作原理的最佳方式就是从头开始实现它。
从头开始实现一个架构是理解它的最佳方式,也是一个好习惯。我们已经对基于价值的 Q-Learning 方法和基于策略的 Reinforce 方法这样做过。
因此,为了能够编写它,我们将使用两个资源
- 由 Costa Huang 制作的教程。Costa 是 CleanRL 的幕后开发者,这是一个深度强化学习库,提供高质量的单文件实现,并具有适合研究的特性。
- 除了教程,要更深入地了解,你可以阅读 13 个核心实现细节:https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/
然后,为了测试其鲁棒性,我们将在 2 个不同的经典环境中训练它
最后,我们会将训练好的模型推送到 Hub,以评估和可视化你的 Agent 玩游戏的情况。
LunarLander-v2 是你开始本课程时使用的第一个环境。那时,你不知道它是如何工作的,而现在,你可以从头开始编写代码并训练它。这有多么不可思议 🤩。
从这里开始教程 👉 https://github.com/huggingface/deep-rl-class/blob/main/unit8/unit8.ipynb
恭喜完成本章!这里有很多信息。也恭喜你完成了教程。🥳,这是本课程中最难的部分之一。
不要犹豫,在其他环境中训练你的 Agent。最好的学习方式是自己动手尝试!
我希望你思考一下自第一单元以来的进步。通过这八个单元,你已经在深度强化学习方面打下了坚实的基础。恭喜你!
但这并不是结束,即使课程的基础部分已经完成,这也不是旅程的终点。我们正在开发新的内容
- 增加新的环境和教程。
- 一个关于多智能体(自对弈、合作、竞争)的部分。
- 另一个关于离线强化学习和决策 Transformer 的部分。
- 论文解读文章。
- 以及更多内容即将到来。
保持联系的最佳方式是注册课程,以便我们向你更新最新信息 👉 http://eepurl.com/h1pElX
别忘了与想要学习的朋友分享 🤗!
最后,我们希望通过你的反馈迭代地改进和更新课程。如果你有任何建议,请填写此表格 👉 https://forms.gle/3HgA7bEHwAmmLfwh9
下次见!







