英特尔与Hugging Face合作,推动机器学习硬件加速普及化


Hugging Face的使命是普及优秀的机器学习技术,并最大限度地发挥其在各行各业和社会中的积极影响。我们不仅致力于推动Transformer模型的发展,还在努力简化其应用。
今天,我们很高兴地宣布,英特尔已正式加入我们的硬件合作伙伴计划。得益于Optimum开源库,英特尔和Hugging Face将合作构建最先进的硬件加速技术,用于Transformer模型的训练、微调和预测。
Transformer模型日益庞大和复杂,这可能给对延迟敏感的应用程序(如搜索或聊天机器人)带来生产挑战。不幸的是,延迟优化长期以来一直是机器学习(ML)从业者面临的难题。即使对底层框架和硬件平台有深入了解,也需要大量的试错才能找出要利用的“旋钮”和功能。
英特尔通过Intel Xeon Scalable CPU平台和各种硬件优化的AI软件工具、框架和库,为加速AI提供了完整的解决方案。因此,Hugging Face和英特尔携手合作,共同构建强大的模型优化工具,使用户在英特尔平台上实现最佳性能、规模和生产力,这是水到渠成的事情。
“*我们很高兴与Hugging Face合作,通过开源集成和集成的开发者体验,将英特尔至强硬件和英特尔AI软件的最新创新带给Transformer社区。*” 英特尔副总裁兼AI与分析总经理魏立表示。
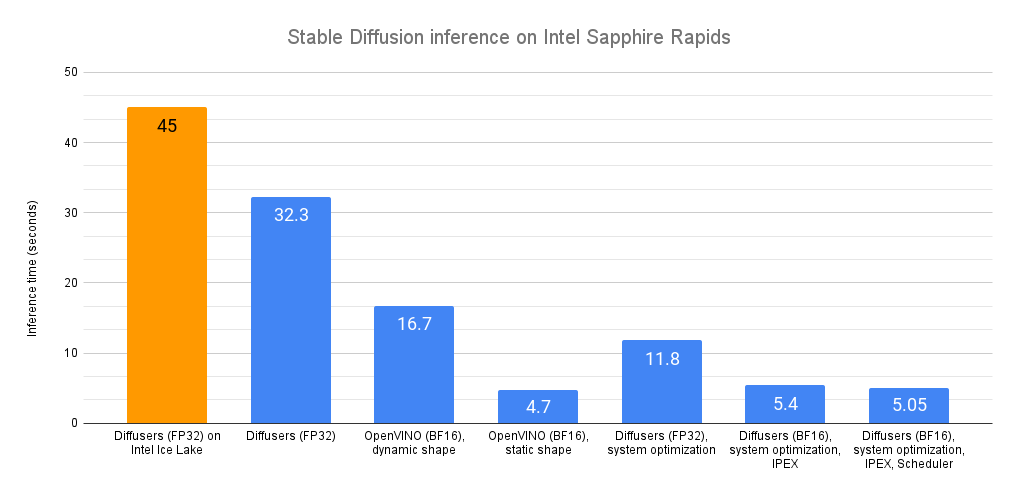
近几个月来,英特尔和Hugging Face在扩展Transformer工作负载方面进行了合作。我们发布了关于推理(第1部分,第2部分)的详细调优指南和基准测试,并在最新的英特尔至强冰湖CPU上实现了DistilBERT的个位数毫秒级延迟。在训练方面,我们增加了对Habana Gaudi加速器的支持,其性价比比GPU高出40%。
下一步自然是扩展这项工作并与机器学习社区分享。请看Optimum Intel开源库!让我们深入了解一下。
使用Optimum Intel实现Transformers性能巅峰
Optimum是由Hugging Face创建的一个开源库,旨在简化Transformer在不断增长的训练和推理设备上的加速。凭借内置的优化技术,您可以使用现成的脚本,或对现有代码进行少量修改,在几分钟内开始加速您的工作负载。初学者可以开箱即用Optimum并获得出色的结果。专家可以继续调整以获得最大性能。
Optimum Intel是Optimum的一部分,并基于Intel Neural Compressor(INC)构建。INC是一个开源库,为流行的网络压缩技术(如量化、剪枝和知识蒸馏)在多个深度学习框架上提供统一接口。该工具支持自动的精度驱动调优策略,帮助用户快速构建最佳量化模型。
借助Optimum Intel,您可以以最小的努力将最先进的优化技术应用于您的Transformer。让我们看一个完整的例子。
案例研究:使用Optimum Intel量化DistilBERT
在这个例子中,我们将对一个经过微调用于分类的DistilBERT模型进行训练后量化。量化是通过减少模型参数的位宽来缩小内存和计算需求的过程。例如,您通常可以用8位整数替换32位浮点参数,但会牺牲预测精度的一小部分。
我们已经微调了原始模型,根据星级(1到5星)对鞋子产品评论进行分类。您可以在Hugging Face Hub上查看此模型及其量化版本。您还可以在此Space中测试原始模型。
让我们开始吧!所有代码都可以在此笔记本中找到。
像往常一样,第一步是安装所有必需的库。值得一提的是,我们需要使用PyTorch的仅CPU版本才能使量化过程正常工作。
pip -q uninstall torch -y
pip -q install torch==1.11.0+cpu --extra-index-url https://download.pytorch.org/whl/cpu
pip -q install transformers datasets optimum[neural-compressor] evaluate --upgrade
然后,我们准备一个评估数据集,以在量化过程中评估模型性能。从我们用于微调原始模型的数据集开始,我们只保留几千条评论及其标签,并将它们保存到本地存储。
接下来,我们从Hugging Face Hub加载原始模型、其tokenizer和评估数据集。
from datasets import load_dataset
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model_name = "juliensimon/distilbert-amazon-shoe-reviews"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=5)
tokenizer = AutoTokenizer.from_pretrained(model_name)
eval_dataset = load_dataset("prashantgrao/amazon-shoe-reviews", split="test").select(range(300))
接下来,我们定义一个评估函数,用于计算评估数据集上的模型指标。这使得Optimum Intel库能够在量化前后比较这些指标。为此,Hugging Face的evaluate库非常方便!
import evaluate
def eval_func(model):
task_evaluator = evaluate.evaluator("text-classification")
results = task_evaluator.compute(
model_or_pipeline=model,
tokenizer=tokenizer,
data=eval_dataset,
metric=evaluate.load("accuracy"),
label_column="labels",
label_mapping=model.config.label2id,
)
return results["accuracy"]
然后,我们使用[配置]设置量化任务。您可以在Neural Compressor的文档中找到此配置的详细信息。这里,我们选择训练后动态量化,可接受的精度下降为5%。如果精度下降超过允许的5%,则模型的不同部分将被量化,直到精度下降达到可接受范围,或者达到最大尝试次数(此处设置为10)。
from neural_compressor.config import AccuracyCriterion, PostTrainingQuantConfig, TuningCriterion
tuning_criterion = TuningCriterion(max_trials=10)
accuracy_criterion = AccuracyCriterion(tolerable_loss=0.05)
# Load the quantization configuration detailing the quantization we wish to apply
quantization_config = PostTrainingQuantConfig(
approach="dynamic",
accuracy_criterion=accuracy_criterion,
tuning_criterion=tuning_criterion,
)
现在我们可以启动量化任务,并将生成的模型及其配置文件保存到本地存储。
from neural_compressor.config import PostTrainingQuantConfig
from optimum.intel.neural_compressor import INCQuantizer
# The directory where the quantized model will be saved
save_dir = "./model_inc"
quantizer = INCQuantizer.from_pretrained(model=model, eval_fn=eval_func)
quantizer.quantize(quantization_config=quantization_config, save_directory=save_dir)
日志告诉我们,Optimum Intel已经量化了38个`Linear`和2个`Embedding`操作符。
[INFO] |******Mixed Precision Statistics*****|
[INFO] +----------------+----------+---------+
[INFO] | Op Type | Total | INT8 |
[INFO] +----------------+----------+---------+
[INFO] | Embedding | 2 | 2 |
[INFO] | Linear | 38 | 38 |
[INFO] +----------------+----------+---------+
比较原始模型的第一层(`model.distilbert.transformer.layer[0]`)及其量化版本(`inc_model.distilbert.transformer.layer[0]`),我们看到`Linear`确实已被其量化等效物`DynamicQuantizedLinear`取代。
# Original model
TransformerBlock(
(attention): MultiHeadSelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(q_lin): Linear(in_features=768, out_features=768, bias=True)
(k_lin): Linear(in_features=768, out_features=768, bias=True)
(v_lin): Linear(in_features=768, out_features=768, bias=True)
(out_lin): Linear(in_features=768, out_features=768, bias=True)
)
(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(ffn): FFN(
(dropout): Dropout(p=0.1, inplace=False)
(lin1): Linear(in_features=768, out_features=3072, bias=True)
(lin2): Linear(in_features=3072, out_features=768, bias=True)
)
(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
# Quantized model
TransformerBlock(
(attention): MultiHeadSelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(q_lin): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_channel_affine)
(k_lin): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_channel_affine)
(v_lin): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_channel_affine)
(out_lin): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_channel_affine)
)
(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(ffn): FFN(
(dropout): Dropout(p=0.1, inplace=False)
(lin1): DynamicQuantizedLinear(in_features=768, out_features=3072, dtype=torch.qint8, qscheme=torch.per_channel_affine)
(lin2): DynamicQuantizedLinear(in_features=3072, out_features=768, dtype=torch.qint8, qscheme=torch.per_channel_affine)
)
(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
很好,但这如何影响准确性和预测时间呢?
在每个量化步骤之前和之后,Optimum Intel都会对当前模型运行评估函数。量化模型的精度现在略低于原始模型(`0.546` vs. `0.574`)。我们还看到量化模型的评估步骤比原始模型快1.34倍。对于几行代码来说,这已经很不错了!
[INFO] |**********************Tune Result Statistics**********************|
[INFO] +--------------------+----------+---------------+------------------+
[INFO] | Info Type | Baseline | Tune 1 result | Best tune result |
[INFO] +--------------------+----------+---------------+------------------+
[INFO] | Accuracy | 0.5740 | 0.5460 | 0.5460 |
[INFO] | Duration (seconds) | 13.1534 | 9.7695 | 9.7695 |
[INFO] +--------------------+----------+---------------+------------------+
您可以在Hugging Face Hub上找到生成的模型。要加载托管在本地或🤗 Hub上的量化模型,您可以这样做:
from optimum.intel.neural_compressor import INCModelForSequenceClassification
inc_model = INCModelForSequenceClassification.from_pretrained(save_dir)
我们才刚刚开始
在这个例子中,我们向您展示了如何使用Optimum Intel轻松地对模型进行训练后量化,这仅仅是个开始。该库还支持其他类型的量化以及剪枝,这是一种将对预测结果影响很小或没有影响的模型参数置零或移除的技术。
我们很高兴能与英特尔合作,为Hugging Face用户带来最新英特尔至强CPU和英特尔AI库的最高效率。请给Optimum Intel点赞以获取更新,并敬请期待更多即将推出的功能!
非常感谢Ella Charlaix在这篇文章中提供的帮助。