Hugging Face 的夏天 😎

夏天正式结束了,Hugging Face 的这几个月相当忙碌。从 Hub 的新功能到研究和开源开发,我们的团队一直努力通过开放和协作的技术赋能社区。
在这篇博客文章中,您将了解 Hugging Face 在 6 月、7 月和 8 月发生的所有事情!

这篇帖子涵盖了我们团队正在努力的广泛领域,所以不要犹豫,直接跳到您最感兴趣的部分 🤗
新功能
在过去的几个月里,Hub 上的公共模型仓库从 10,000 个增加到 16,000 多个模型!感谢我们的社区与世界分享了这么多令人惊叹的模型。除了数量,我们还有大量酷炫的新功能与您分享!
Spaces Beta ()
Spaces 是一种简单免费的解决方案,可以直接在您的用户个人资料或组织 hf.co 个人资料上托管机器学习演示应用程序。我们支持两个很棒的 SDK,让您可以使用 Python 轻松构建酷炫的应用程序:Gradio 和 Streamlit。您可以在几分钟内部署一个应用程序并与社区分享!🚀
Spaces 允许您设置机密,允许自定义要求,甚至可以直接从 GitHub 仓库进行管理。您可以在 注册 Beta 版。以下是我们最喜欢的一些!
- 在 Chef Transformer 的帮助下创建食谱
- 使用 HuBERT 将语音转录为文本
- 使用 DINO 模型在视频中进行分割
- 使用 Paint Transformer 根据给定的图片创作绘画
- 或者您可以探索任何一个现有 !
分享爱意
您现在可以在 https://huggingface.co 上点赞任何模型、数据集或 Space,这意味着您可以与社区分享爱意 ❤️。您还可以通过点击点赞框👀来关注谁喜欢什么。去点赞您自己的仓库吧,我们不会评判 😉。

TensorBoard 集成
6 月下旬,我们为所有模型推出了 TensorBoard 集成。如果仓库中有 TensorBoard 跟踪,就会自动为您启动一个免费的 TensorBoard 实例。这适用于公共和私有仓库以及任何具有 TensorBoard 跟踪的库!

指标
7 月,我们增加了在模型仓库中列出评估指标的功能,只需将它们添加到模型卡中即可📈。如果您在模型卡的 model-index 部分添加评估指标,它们将自豪地显示在您的模型仓库中。
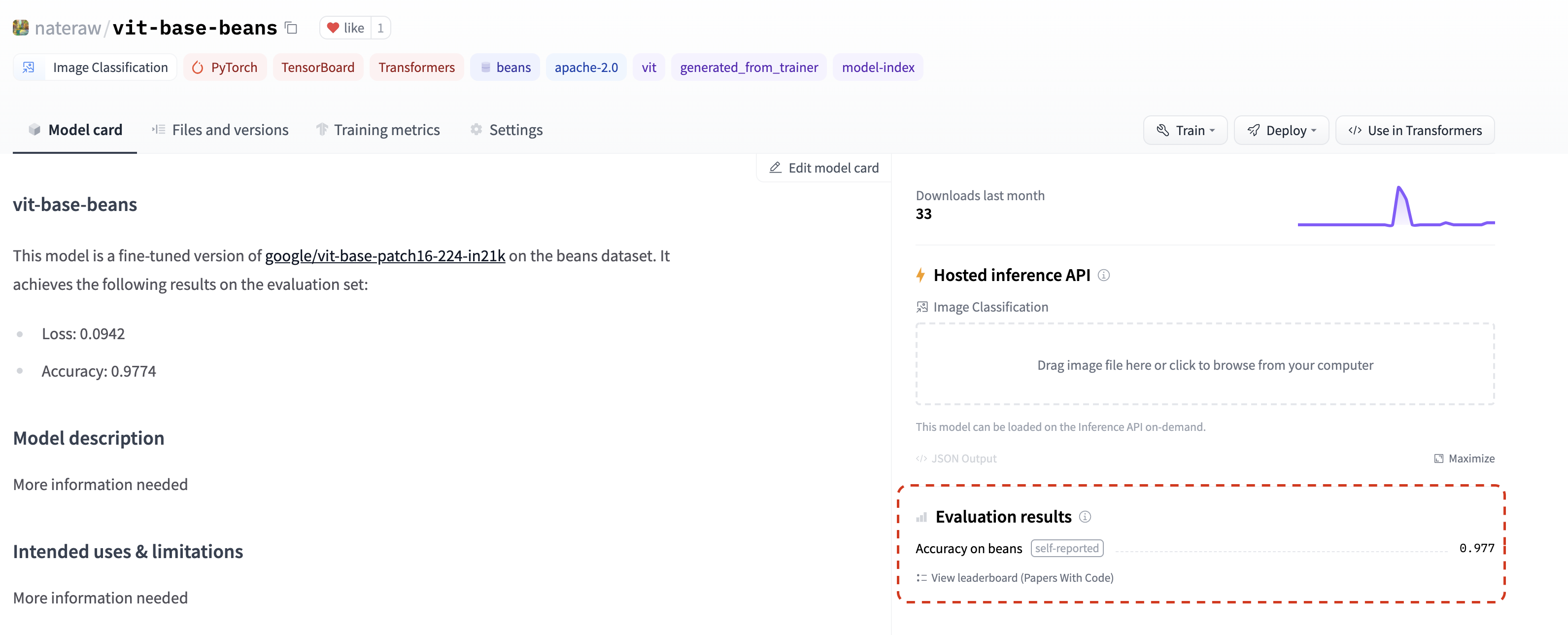
如果这还不够,这些指标将自动链接到相应的 Papers With Code 排行榜。这意味着您一旦在 Hub 上分享您的模型,就可以与社区中的其他人并排比较您的结果。💪
查看 这个仓库 作为示例,密切关注其 模型卡 的 model-index 部分,了解如何自行操作并 自动 在 Papers with Code 中找到指标。
新部件
Hub 有 18 个小部件,允许用户直接在浏览器中试用模型。
随着我们最新与 Sentence Transformers 的集成,我们还引入了两个新部件:特征提取和句子相似度。
最新的音频分类小部件实现了许多酷炫的用例:语言识别、街道声音检测 🚨、命令识别、说话人识别等等!您今天就可以使用 transformers 和 speechbrain 模型来尝试!🔊 (请注意,当您尝试某些模型时,您可能需要大声吠叫)
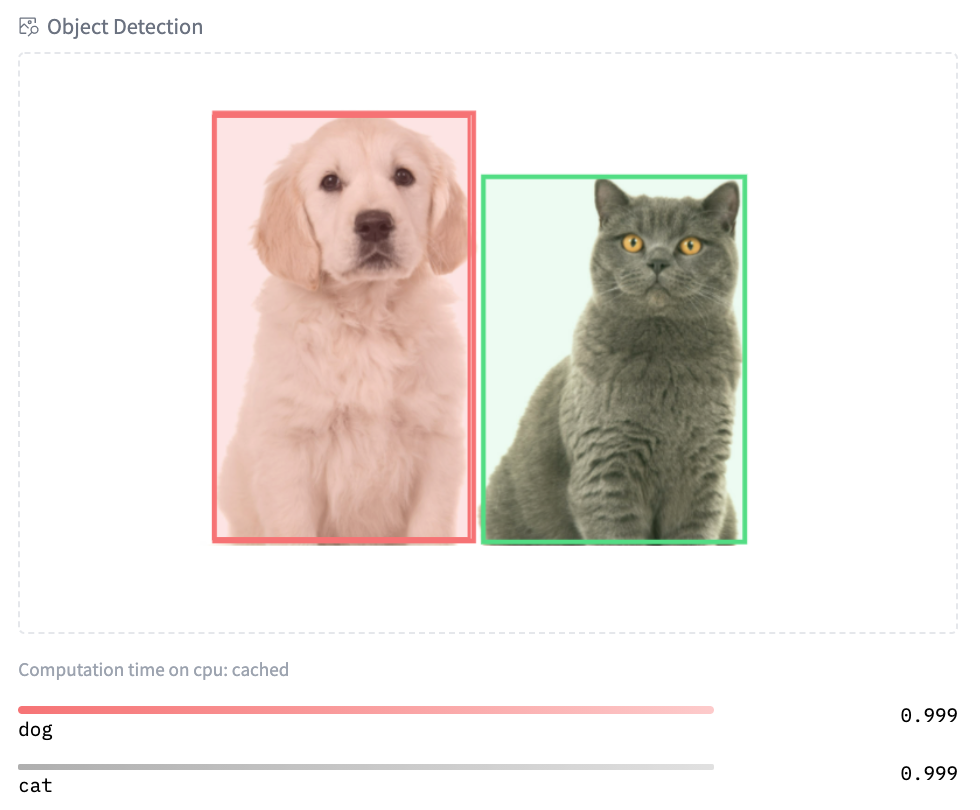
您可以试用我们使用 Scikit-learn 的 结构化数据分类 的早期演示。最后,我们还为图像相关模型引入了新部件:文本到图像、图像分类和对象检测。在这里 尝试 Google 的 ViT 模型的图像分类,在这里 尝试 Facebook AI 的 DETR 模型的对象检测!
更多功能
这并非 Hub 发生的全部。我们已经引入了新的、改进的 Hub 文档。我们还引入了两个广泛请求的功能:用户现在可以转移/重命名仓库,并直接将新文件上传到 Hub。
社区
Hugging Face 课程
6 月,我们推出了 免费在线课程 的第一部分!本课程教授您有关 🤗 生态系统的所有知识:Transformers、Tokenizers、Datasets、Accelerate 和 Hub。您还可以在我们库的官方文档中找到课程链接。所有章节的直播课程都可以在我们的 YouTube 频道 上找到。敬请期待我们将在今年晚些时候推出的课程的下一部分!
JAX/FLAX 冲刺
7 月,我们举办了有史以来规模最大的 社区活动,近 800 人参加!本次活动由 JAX/Flax 和 Google Cloud 团队共同组织,通过提供免费的 TPUv3,使计算密集型 NLP、计算机视觉和语音项目能够被更广泛的工程师和研究人员访问。参与者创建了超过 170 个模型、22 个数据集和 38 个 Spaces 演示 🤯。您可以在 这里 探索所有令人惊叹的演示和项目。
活动中围绕 JAX/Flax、Transformers、大规模语言建模等主题进行了演讲!您可以在 这里 找到所有录音。
我们非常高兴能分享 3 个获胜团队的工作!
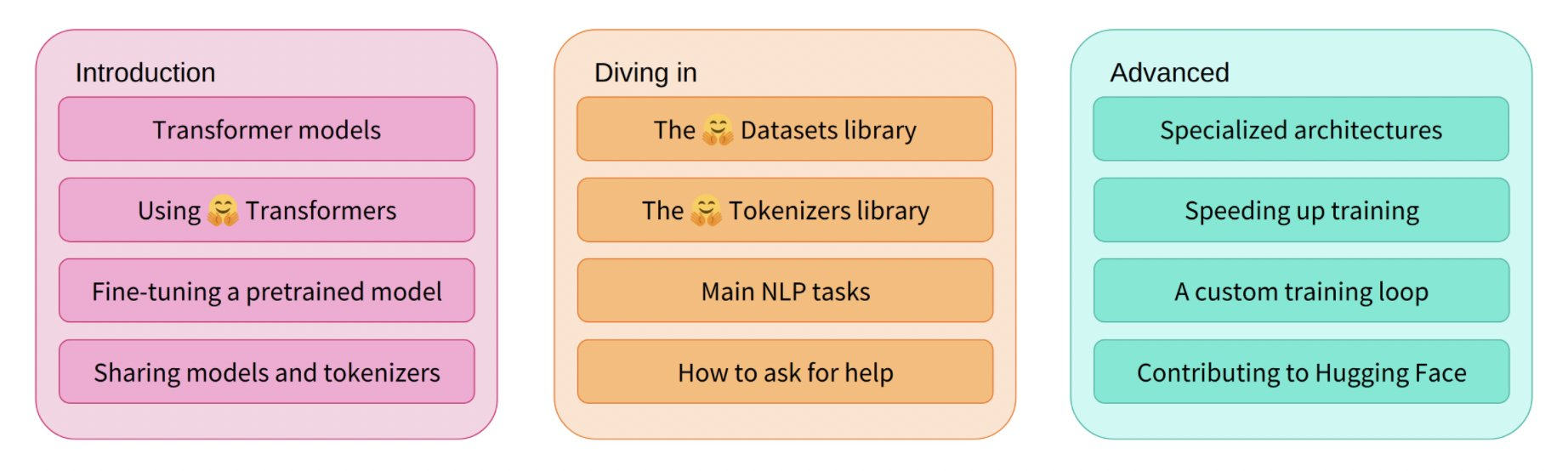
Dall-e mini。DALL·E mini 是一个可以根据您提供的任何提示生成图像的模型!DALL·E mini 比原始 DALL·E 小 27 倍,但仍具有令人印象深刻的结果。
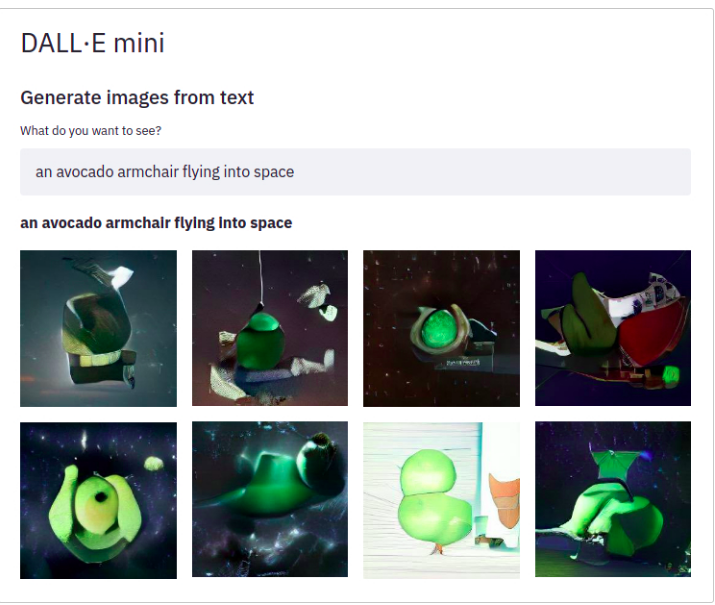
DietNerf。DietNerf 是一种 3D 神经视图合成模型,旨在通过少量 2D 视图进行 3D 场景重建的少样本学习。这是“Putting Nerf on a Diet”论文的第一个开源实现。
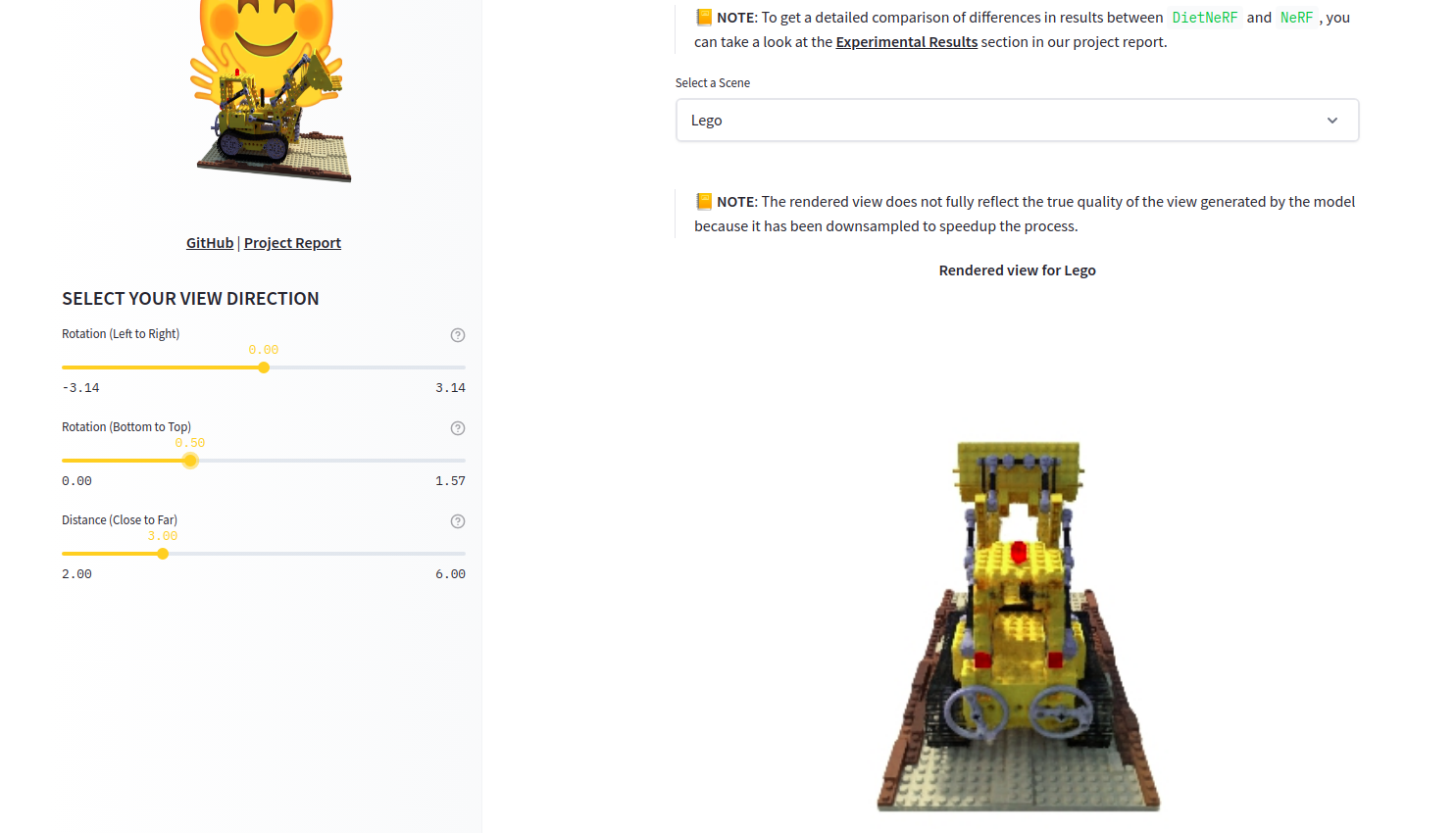
CLIP RSIC。CLIP RSIC 是一种在遥感图像数据上微调的 CLIP 模型,可实现零样本卫星图像分类和字幕生成。该项目展示了微调后的 CLIP 模型在专业领域中的有效性。
除了这些非常酷的项目,我们还很高兴看到这些社区活动如何实现对多种语言的大型多模态模型进行训练。例如,我们看到了有史以来第一个针对斯瓦希里语 (Swahili)、波兰语 (Polish) 和马拉地语 (Marathi) 等资源匮乏语言的开源大型语言模型。
附赠
除了我们刚刚分享的所有内容,我们的团队还在做很多其他事情。以下只是其中的一部分
- 📖 这个 3 部分的 视频系列 展示了如何训练最先进的句子嵌入模型的理论。
- 我们在 PyTorch 社区之声上进行了演示,并参与了问答环节 (视频)。
- Hugging Face 与 NLP in Spanish 和 SpainAI 合作开设了一个西班牙语 课程,通过用例教授概念、最先进的架构及其应用。
- 我们在 MLOps World Demo Days 上进行了演示。
开源
Transformers 新增内容
夏天对于 🤗 Transformers 来说是一个激动人心的时刻!该库达到了 50,000 颗星,总下载量达到 3000 万次,贡献者接近 1000 人!🤩
那么,有什么新内容呢?JAX/Flax 现在是第三个受支持的框架,Hub 中有超过 5000 个模型!您可以找到用于不同任务(例如文本分类)的积极维护的 示例。我们还在努力改进对 TensorFlow 的支持:我们所有的 示例 都经过了重写,使其更加健壮、更符合 TensorFlow 习惯,并且更清晰。这包括摘要、翻译和命名实体识别等示例。
您现在可以轻松地将模型发布到 Hub,包括自动生成的模型卡、评估指标和 TensorBoard 实例。通过新的 transformers.onnx 模块,对将模型导出到 ONNX 的支持也增加了。
python -m transformers.onnx --model=bert-base-cased onnx/bert-base-cased/
最近 4 个版本引入了许多新的酷炫模型!

- ByT5 是 Hub 中第一个无需分词器的模型!您可以在这里找到所有可用的检查点。
- CANINE 是 Google AI 发布的另一个无需分词器的仅编码器模型,直接在字符级别操作。您可以在这里找到所有(多语言)检查点。
- HuBERT 在下游音频任务中展现出令人兴奋的结果,例如命令分类和情感识别。在此处查看模型。
- LayoutLMv2 和 LayoutXLM 是两个令人难以置信的模型,它们能够通过结合文本、布局和视觉信息来解析文档图像(如 PDF)。我们构建了一个 Space 演示,您可以直接尝试!演示笔记本可以在 这里 找到。

- 微软研究院的 BEiT 通过受 BERT 启发的巧妙预训练目标,使自监督 Vision Transformer 的性能超越了有监督的 Vision Transformer。
- RemBERT,一个大型多语言 Transformer,在零样本迁移方面优于 XLM-R(以及参数数量相似的 mT5)。
- Splinter 可用于少样本问答。仅给定 128 个示例,Splinter 就能在 SQuAD 上达到约 73% 的 F1 分数,比基于 MLM 的模型高出 24 个点!
Hub 现在已集成到 `transformers` 中,能够直接从 Python 运行时向 Hub 推送配置、模型和分词器文件!`Trainer` 现在可以在每次保存检查点时直接推送到 Hub。
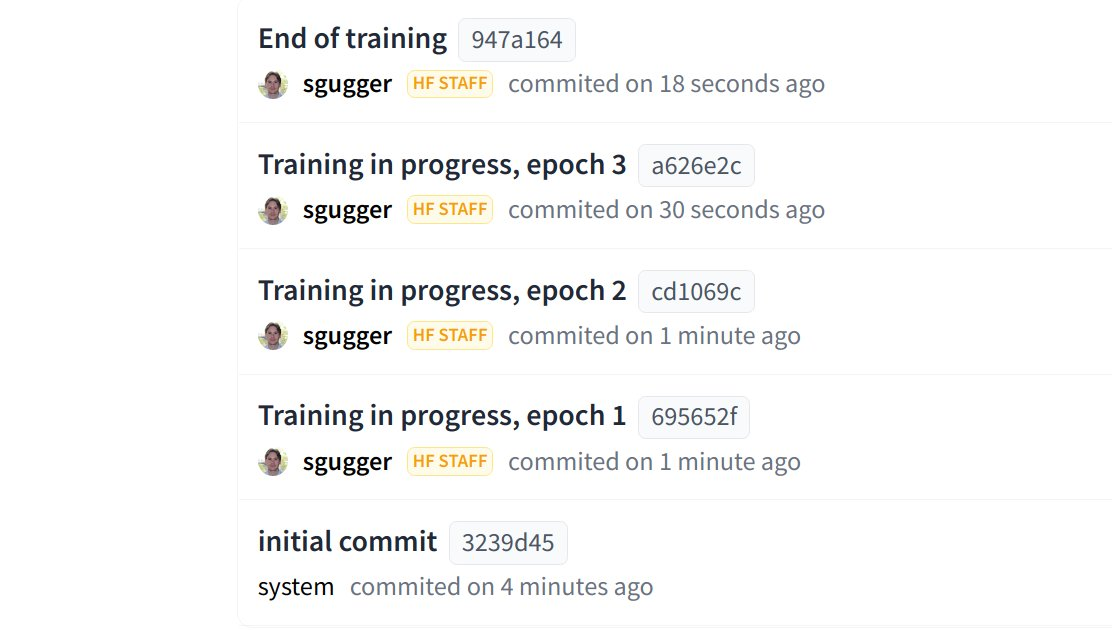
Datasets 新增内容
多亏了我们社区所有贡献者的出色工作,您可以在 https://huggingface.co/datasets 中找到 1400 个公共数据集。💯
对 datasets 的支持持续增长:它可以在 JAX 中使用,处理 parquet 文件,使用远程文件,并对其他领域(如自动语音识别和图像分类)有更广泛的支持。
用户还可以通过将数据文件上传到 Dataset Hub 上的仓库,直接托管并与社区共享他们的数据集。
新的数据集亮点是什么?Microsoft CodeXGlue 数据集 用于多项编码任务(代码补全、生成、搜索等),以及 C4 和 MC4 等大型数据集,还有更多,例如 RussianSuperGLUE 和 DISFL-QA。
欢迎新库加入 Hub
除了与基于 transformers 的模型深度集成外,Hub 还与开源机器学习库建立了良好的合作关系,以提供免费的模型托管和版本控制。我们通过 huggingface_hub 开源库以及新的 Hub 文档 实现了这一目标。
所有 spaCy 规范管道现在都可以在官方的 spaCy 组织中找到,任何用户都可以通过一条命令 python -m spacy huggingface-hub 共享他们的管道。要了解更多信息,请访问 https://huggingface.co/blog/spacy。您可以在演示 Space 中直接在 Hub 中试用所有规范的 spaCy 模型!
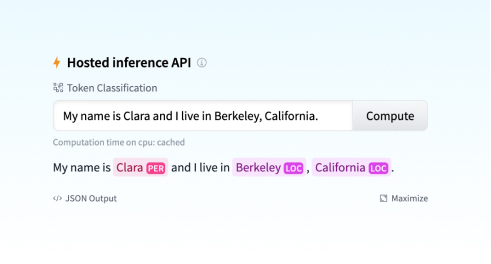
另一个令人兴奋的集成是 Sentence Transformers。您可以在 博客公告 中阅读更多内容:您可以在 Hub 中找到超过 200 个模型,轻松与社区的其他成员共享您的模型并重用社区中的模型。
但这还不是全部!您现在可以在 Hub 中找到超过 100 个 Adapter Transformers,并直接在浏览器中使用 Speechbrain 模型和部件进行不同任务,例如音频分类。如果您对我们与新 ML 库集成到 Hub 的合作感兴趣,您可以在 此处 阅读更多信息。

解决方案
即将推出:Infinity
Transformers 延迟降至 1 毫秒?🤯🤯🤯
我们一直在研究一个非常巧妙的解决方案,旨在为最先进的 Transformer 模型实现无与伦比的效率,供公司在其自己的基础设施中部署。
- Infinity 作为一个单一容器提供,可以在任何生产环境中部署。
- 它可以在 GPU 上实现 BERT 类模型 1 毫秒的延迟,在 CPU 上实现 4-10 毫秒的延迟 🤯🤯🤯
- Infinity 符合最高的安全要求,可以集成到您的系统中,无需互联网访问。您可以控制所有传入和传出流量。
⚠️ 欢迎在 9 月 28 日的现场发布和演示 中与我们一同见证 Infinity 首次公开亮相!
新增:硬件加速
Hugging Face 正在与领先的 AI 硬件加速器(如 Intel、Qualcomm 和 GraphCore)合作,旨在使最先进的生产性能触手可及,并扩展 SOTA 硬件上的训练能力。作为这一旅程的第一步,我们推出了一款新的开源库:🤗 Optimum——用于生产性能的 ML 优化工具包 🏎。在此博客文章中了解更多信息。
新增:SageMaker 上的推理
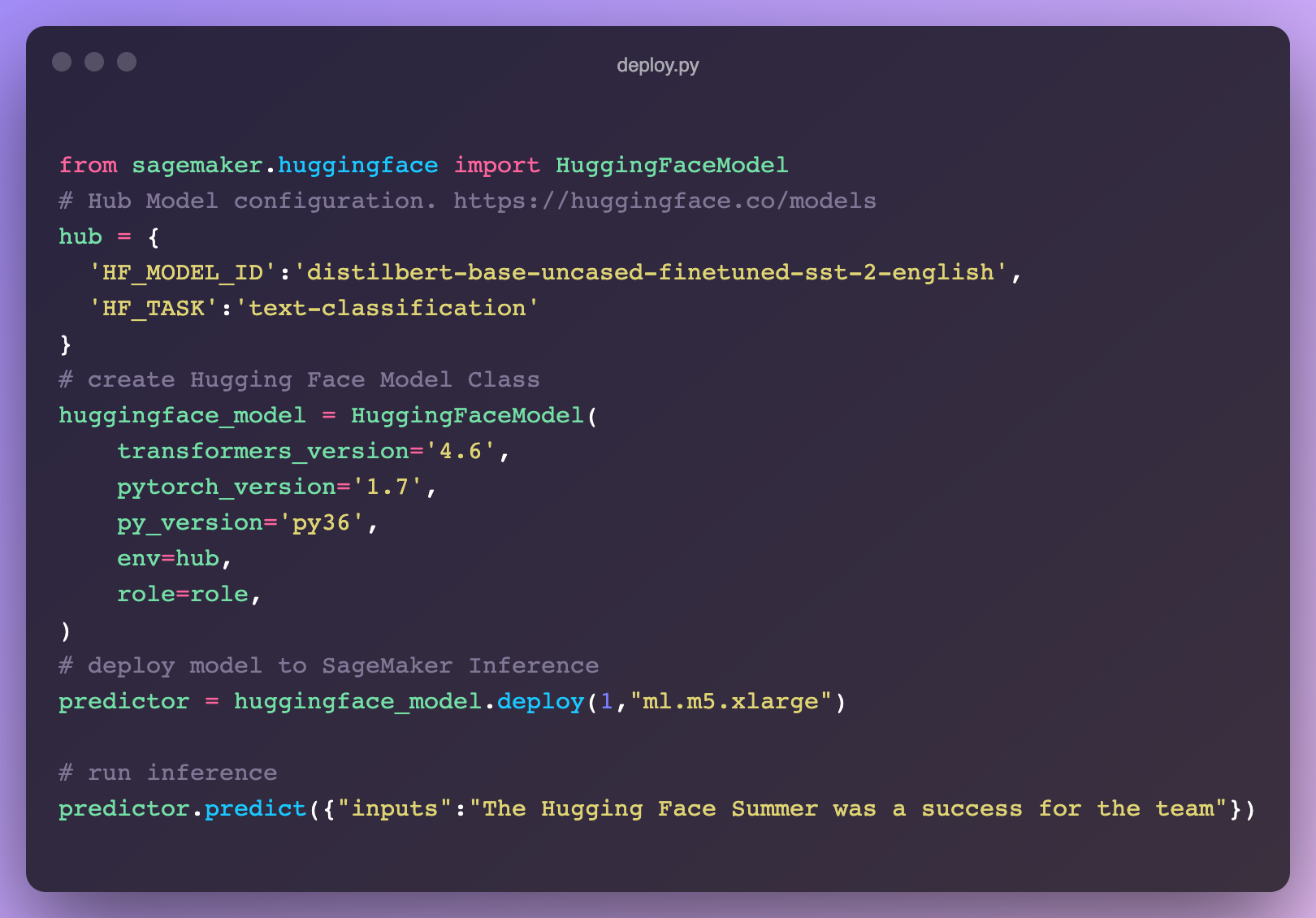
我们与 AWS 推出了一项新集成,让在 SageMaker 中部署 🤗 Transformers 比以往任何时候都容易 🔥。直接从 🤗 Hub 模型页面获取代码片段!在我们的文档中了解如何在 SageMaker 中利用 Transformers,或者查看这些视频教程。
如有疑问,请在论坛上联系我们:https://discuss.huggingface.co/c/sagemaker/17
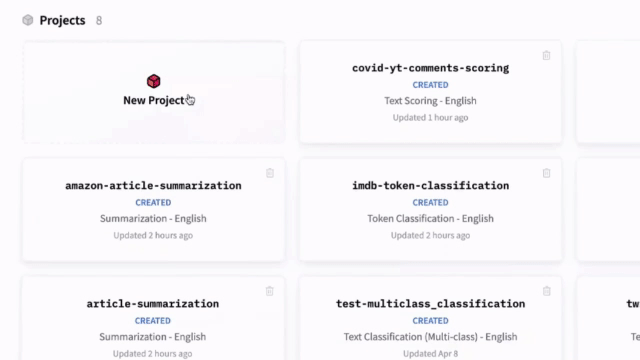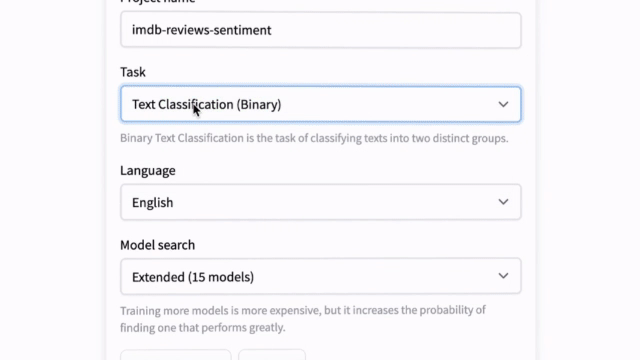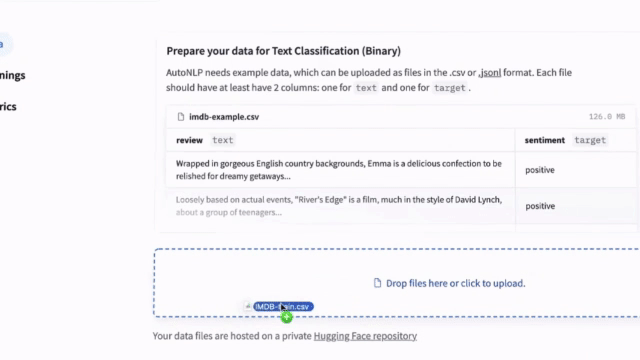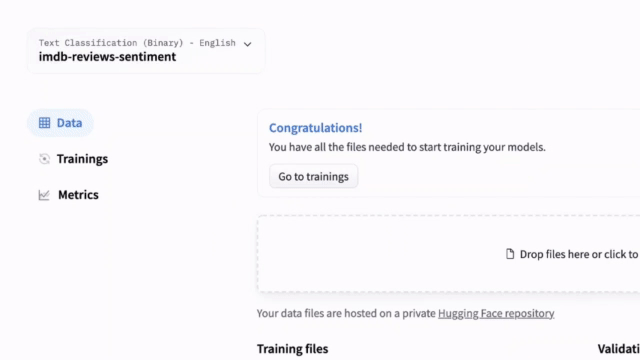
新增:浏览器中的 AutoNLP
我们发布了全新的 AutoNLP 体验:一个可以直接从浏览器训练模型的网页界面!现在,只需点击几下即可在您自己的数据上训练、评估和部署 🤗 Transformers 模型。无需代码,立即尝试!
推理 API
网络研讨会:
我们举办了一场在线研讨会,展示了如何用几行代码添加机器学习功能。我们还构建了一个 VSCode 扩展,它利用 Hugging Face 推理 API 生成描述 Python 代码的注释。
Hugging Face + Zapier 演示
20,000 多个机器学习模型连接到 3,000 多个应用程序?🤯 通过利用 推理 API,您现在可以轻松地将模型直接连接到 Gmail、Slack、Twitter 等应用程序。在这个演示视频中,我们创建了一个使用此 代码片段 来分析您的 Twitter 提及并在 Slack 上提醒您负面提及的 zap。
Hugging Face + Google 表格演示
借助 推理 API,您可以轻松地将零样本分类直接应用到 Google 表格中的电子表格中。只需在 工具 -> 脚本编辑器中添加此脚本
少样本学习实践
我们写了一篇博客文章,介绍了什么是少样本学习,并探讨了如何使用 GPT-Neo 和 🤗 加速推理 API 来生成自己的预测。
专家加速计划
查看 专家加速计划的全新主页;您现在可以从我们的机器学习专家那里获得直接、优质的支持,更快地构建更好的机器学习解决方案。
研究
在 BigScience,我们于 7 月举办了第一次现场活动(自启动以来)BigScience Episode #1。我们的第二次活动 BigScience Episode #2 于 2021 年 9 月 20 日举行,包括 BigScience 工作组的技术讲座和更新,以及 Jade Abbott (Masakhane)、Percy Liang (Stanford CRFM)、Stella Biderman (EleutherAI) 等受邀讲座。我们已经完成了 Jean Zay 上的第一次大规模训练,一个 13B 仅限英语的解码器模型(您可以在这里找到详细信息),我们目前正在决定第二个模型的架构。组织工作组已经提交了第二笔计算预算的申请:Jean Zay V100:2,500,000 GPU 小时。🚀
6 月,我们分享了与 Yandex 研究团队合作的成果:DeDLOC,这是一种协作训练大型神经网络的方法,即无需使用 HPC 集群,而是利用各种可访问的资源,如 Google Colaboratory 或 Kaggle 笔记本、个人电脑或抢占式虚拟机。通过这种方法,我们成功地与 40 名志愿者一起训练了孟加拉语模型 sahajBERT!我们的模型与最先进的模型竞争,甚至在 Soham 新闻文章分类数据集上下游分类任务中表现最佳。您可以在这篇博客文章中阅读更多内容。这是一条引人入胜的研究方向,因为它将使模型预训练在财务上更具可及性!
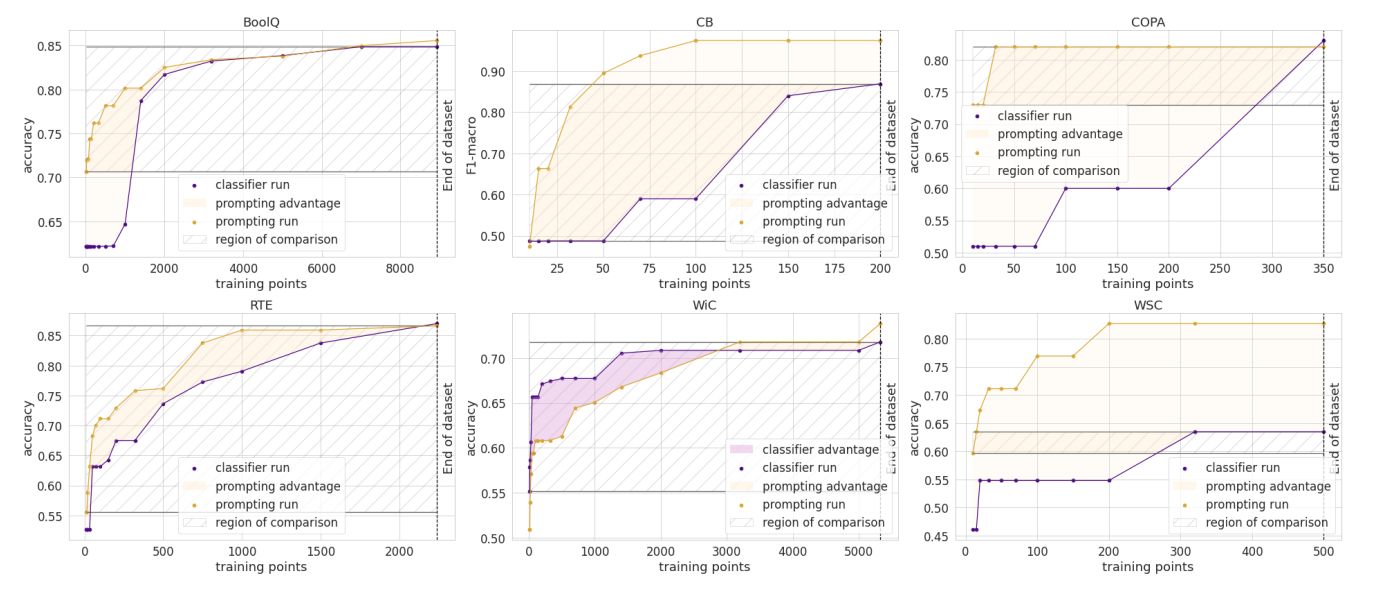
6 月,我们的论文《How Many Data Points is a Prompt Worth?》在 NAACL 获得了最佳论文奖!在论文中,我们协调并比较了传统的和基于提示的方法来适应预训练模型,发现人工编写的提示在新的任务上相当于数千个有监督的数据点。您也可以阅读其博客文章。
我们期待今年的 EMNLP,届时我们有四篇论文被录用!
- 我们的论文“Datasets: A Community Library for Natural Language Processing”记录了 Hugging Face Datasets 项目,该项目拥有 300 多名贡献者。这个社区项目为研究人员提供了数百个数据集的便捷访问。它促进了跨数据集 NLP 的新用例,并具有索引和流式传输大型数据集等高级功能。
- 我们与达姆施塔特工业大学研究人员的合作促成了另一篇会议论文的发表 (“避免少样本提示微调中的推理启发式”)。在这篇论文中,我们展示了基于提示微调的语言模型(在少样本设置中表现出色)仍然存在学习表面启发式(有时称为数据集偏差)的问题,而零样本模型则没有。
- 我们提交的论文《用于更快 Transformer 的块剪枝》也被接收为长论文。在这篇论文中,我们展示了如何使用块稀疏性来获得又快又小的 Transformer 模型。我们的实验结果表明,在 SQuAD 上,模型比 BERT 快 2.4 倍,小 74%。
结语
😎 🔥 夏天真有趣!发生了好多事情!我们希望您喜欢阅读这篇博客文章,并期待分享我们正在开发的新项目。冬天再见!❄️

