google-cloud 文档
在 GKE 上使用 SFT 微调 Gemma 2B 以及 PyTorch 训练 DLC
并获得增强的文档体验
开始使用
在 GKE 上使用 SFT 微调 Gemma 2B 以及 PyTorch 训练 DLC
Gemma 是一系列轻量级、最先进的开放模型,由 Google DeepMind 和 Google 其他团队使用创建 Gemini 模型相同的研究和技术构建。TRL 是 Hugging Face 开发的用于微调和对齐大型语言模型 (LLM) 的全栈库。Google Kubernetes Engine (GKE) 是 Google Cloud 中一项完全托管的 Kubernetes 服务,可用于使用 GCP 的基础设施大规模部署和操作容器化应用程序。
本示例展示了如何在 GKE 集群的多 GPU 设置中,通过监督式微调 (SFT) 使用 TRL 对 Gemma 2B 进行完全微调。
设置 / 配置
首先,您需要在本地机器上安装 gcloud 和 kubectl,它们分别是 Google Cloud 和 Kubernetes 的命令行工具,用于与 GCP 和 GKE 集群交互。
- 要安装
gcloud,请按照 Cloud SDK 文档 - 安装 gcloud CLI 中的说明进行操作。 - 要安装
kubectl,请按照 Kubernetes 文档 - 安装工具 中的说明进行操作。
或者,为了简化本教程中命令的使用,您需要为 GCP 设置以下环境变量
export PROJECT_ID=your-project-id
export LOCATION=your-location
export CLUSTER_NAME=your-cluster-name然后您需要登录到您的 GCP 账户,并将项目 ID 设置为您要用于部署 GKE 集群的项目。
gcloud auth login
gcloud auth application-default login # For local development
gcloud config set project $PROJECT_ID登录后,您需要启用 GCP 中必要的服务 API,例如 Google Kubernetes Engine API、Google Container Registry API 和 Google Container File System API,这些 API 对于部署 GKE 集群和用于 TGI 的 Hugging Face DLC 是必需的。
gcloud services enable container.googleapis.com
gcloud services enable containerregistry.googleapis.com
gcloud services enable containerfilesystem.googleapis.com此外,要将 kubectl 与 GKE 集群凭据一起使用,您还需要安装 gke-gcloud-auth-plugin,可以如下使用 gcloud 进行安装
gcloud components install gke-gcloud-auth-plugin
无需通过 `gcloud` 特别安装 `gke-gcloud-auth-plugin`,有关其他安装方法的更多信息,请访问 https://cloud.google.com/kubernetes-engine/docs/how-to/cluster-access-for-kubectl#install_plugin。
创建 GKE 集群
一切设置好后,您可以继续创建 GKE 集群和节点池,本例中将是一个单 GPU 节点,以便使用 GPU 加速器进行高性能推理,同时遵循 TGI 基于其内部 GPU 优化所做的建议。
部署 GKE 集群时,将使用“Autopilot”模式,因为它是大多数工作负载的推荐模式,因为底层基础设施由 Google 管理。或者,您也可以使用“Standard”模式。
在创建 GKE Autopilot 集群之前,务必检查 GKE 文档 - 通过选择机器系列优化 Autopilot Pod 性能,因为并非所有版本都支持 GPU 加速器,例如 `nvidia-l4` 不受 GKE 集群版本 1.28.3 或更低版本的支持。
gcloud container clusters create-auto $CLUSTER_NAME \
--project=$PROJECT_ID \
--location=$LOCATION \
--release-channel=stable \
--cluster-version=1.28 \
--no-autoprovisioning-enable-insecure-kubelet-readonly-port要选择您所在位置的特定 GKE 集群版本,您可以运行以下命令
gcloud container get-server-config \
--flatten="channels" \
--filter="channels.channel=STABLE" \
--format="yaml(channels.channel,channels.defaultVersion)" \
--location=$LOCATION欲了解更多信息,请访问 https://cloud.google.com/kubernetes-engine/versioning#specifying_cluster_version。
GKE 集群创建完成后,您可以使用以下命令通过 kubectl 获取访问它的凭据
gcloud container clusters get-credentials $CLUSTER_NAME --location=$LOCATION为 GCS 配置 IAM
在 GKE 集群上运行用于训练的 Hugging Face PyTorch DLC 的微调作业之前,您需要为 GCS 存储桶设置 IAM 权限,以便 GKE 集群中的 Pod 可以访问该存储桶,该存储桶将被挂载到正在运行的容器中并用于写入生成的工件,从而自动上传到 GCS 存储桶。为此,您需要在 GKE 集群中创建一个命名空间和服务帐户,然后为 GCS 存储桶设置 IAM 权限。
为方便起见,由于命名空间和服务账户的引用将在以下步骤中使用,因此将设置环境变量 NAMESPACE 和 SERVICE_ACCOUNT。
export NAMESPACE=hf-gke-namespace
export SERVICE_ACCOUNT=hf-gke-service-account然后您可以在 GKE 集群中创建命名空间和服务账户,从而在使用该服务账户时,允许该命名空间中的 Pod 访问 GCS 存储桶的 IAM 权限。
kubectl create namespace $NAMESPACE
kubectl create serviceaccount $SERVICE_ACCOUNT --namespace $NAMESPACE然后您需要按如下方式将 IAM 策略绑定添加到存储桶
gcloud storage buckets add-iam-policy-binding \
gs://$BUCKET_NAME \
--member "principal://iam.googleapis.com/projects/$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")/locations/global/workloadIdentityPools/$PROJECT_ID.svc.id.goog/subject/ns/$NAMESPACE/sa/$SERVICE_ACCOUNT" \
--role "roles/storage.objectUser"可选:在 GKE 中设置密钥
由于 google/gemma-2b 是一个门控模型,您需要通过 `kubectl` 使用 Hugging Face Hub 令牌设置 Kubernetes 密钥。
要为 Hugging Face Hub 生成自定义令牌,您可以按照 https://huggingface.co/docs/hub/en/security-tokens 上的说明进行操作;建议的设置方式是安装 `huggingface_hub` Python SDK,如下所示:
pip install --upgrade --quiet huggingface_hub
然后使用生成的具有对受限/私有模型读取权限的令牌登录
huggingface-cli login
最后,您可以使用 huggingface_hub Python SDK 检索令牌,如下所示创建包含 Hugging Face Hub 生成令牌的 Kubernetes secret
kubectl create secret generic hf-secret \
--from-literal=hf_token=$(python -c "from huggingface_hub import get_token; print(get_token())") \
--dry-run=client -o yaml \
--namespace $NAMESPACE | kubectl apply -f -或者,您可以直接按如下方式设置令牌
kubectl create secret generic hf-secret \
--from-literal=hf_token=hf_*** \
--dry-run=client -o yaml \
--namespace $NAMESPACE | kubectl apply -f -有关如何在 GKE 集群中设置 Kubernetes 密钥的更多信息,请访问 https://cloud.google.com/secret-manager/docs/secret-manager-managed-csi-component。
定义作业配置
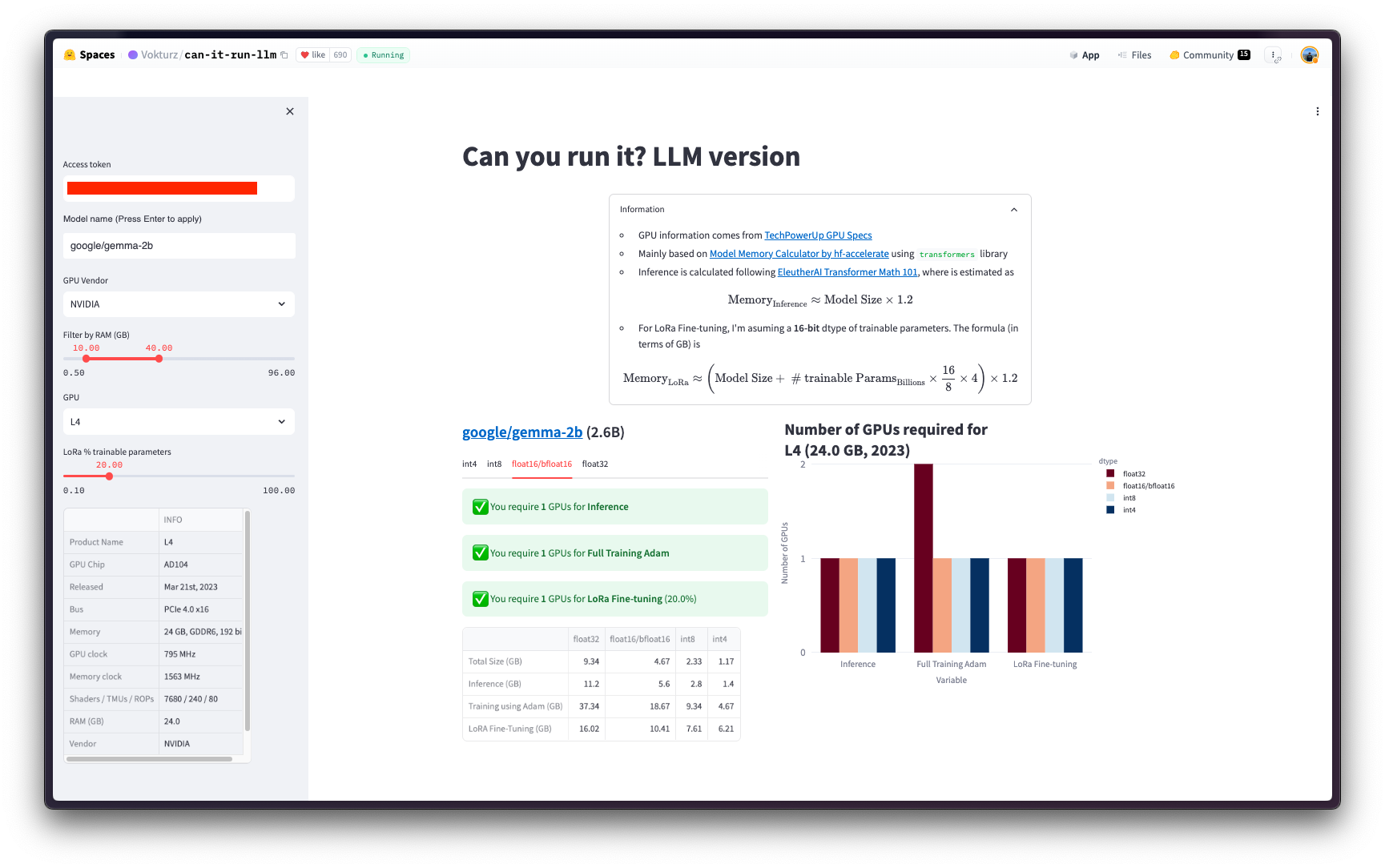
在通过 Hugging Face PyTorch 训练 DLC 进行 Kubernetes 批量作业部署之前,您需要首先定义作业成功运行所需的配置,即哪种 GPU 能够以 `bfloat16` 格式微调 `google/gemma-2b`。
粗略估算,你可以假设以半精度微调模型所需的 GPU VRAM 大约是模型大小的四倍(更多信息请参阅 Eleuther AI - Transformer Math 101)。
或者,如果您的模型已上传到 Hugging Face Hub,您可以在社区空间 `Vokturz/can-it-run-llm` 中查看这些数字,该空间会根据要微调的模型和可用硬件为您进行这些计算。
运行作业
现在,您可以通过 `kubectl` 从 `job.yaml` 配置文件在 GKE 集群上运行 Hugging Face PyTorch 训练 DLC 中的 Kubernetes 作业。该文件包含运行 `trl sft` 命令的作业规范,该命令由 TRL CLI 提供,用于在 4 x A100 40GiB GPU 上使用 `timdettmers/openassistant-guanaco`(来自 `OpenAssistant/oasst1` 的子集,约有 1 万个样本)以 `bfloat16` 对 `google/gemma-2b` 进行 SFT 完全微调,并将生成的工件存储在挂载到 GCS 存储桶的 `/data` 卷下。
git clone https://github.com/huggingface/Google-Cloud-Containers
kubectl apply -f Google-Cloud-Containers/examples/gke/trl-full-fine-tuning/job.yaml
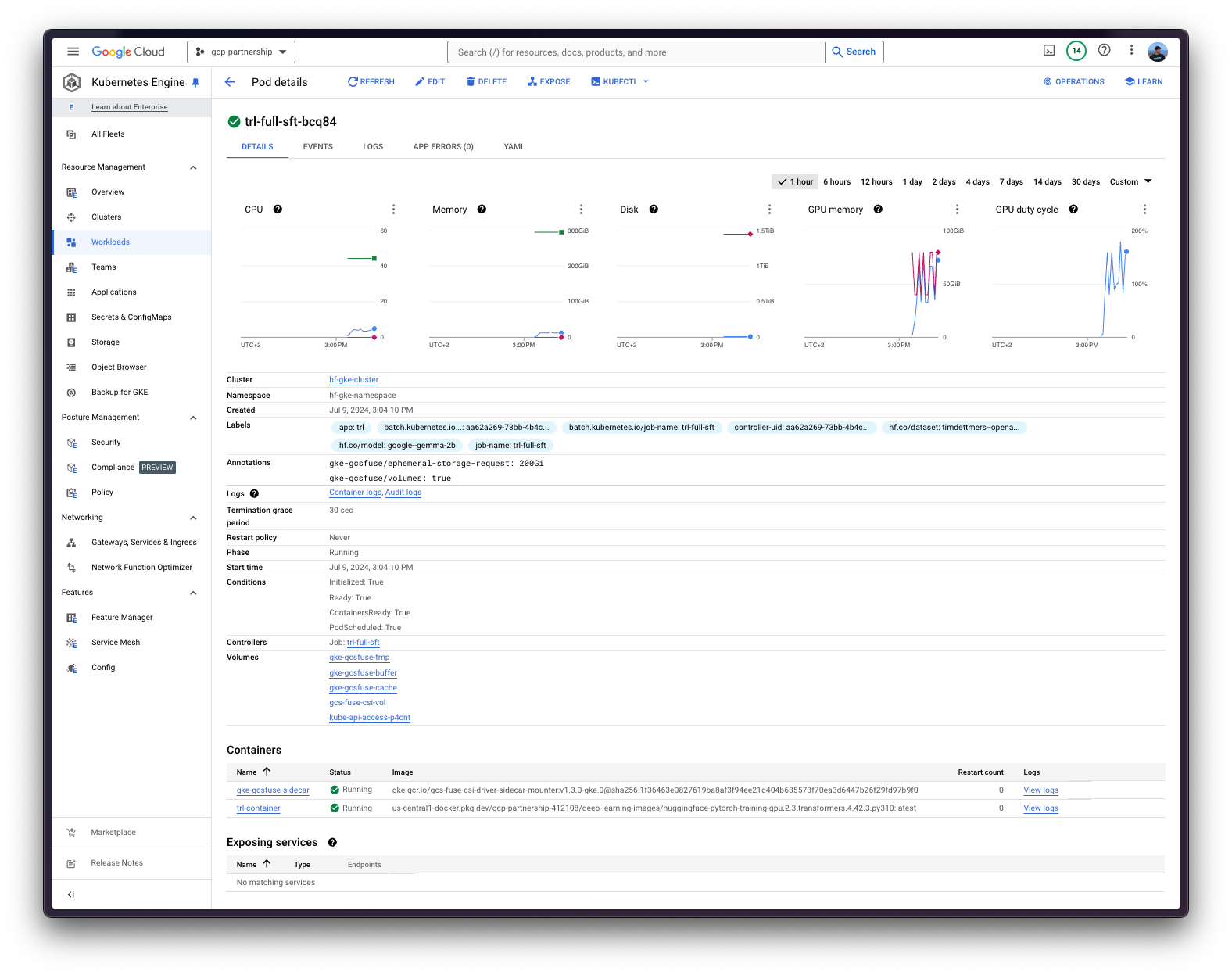
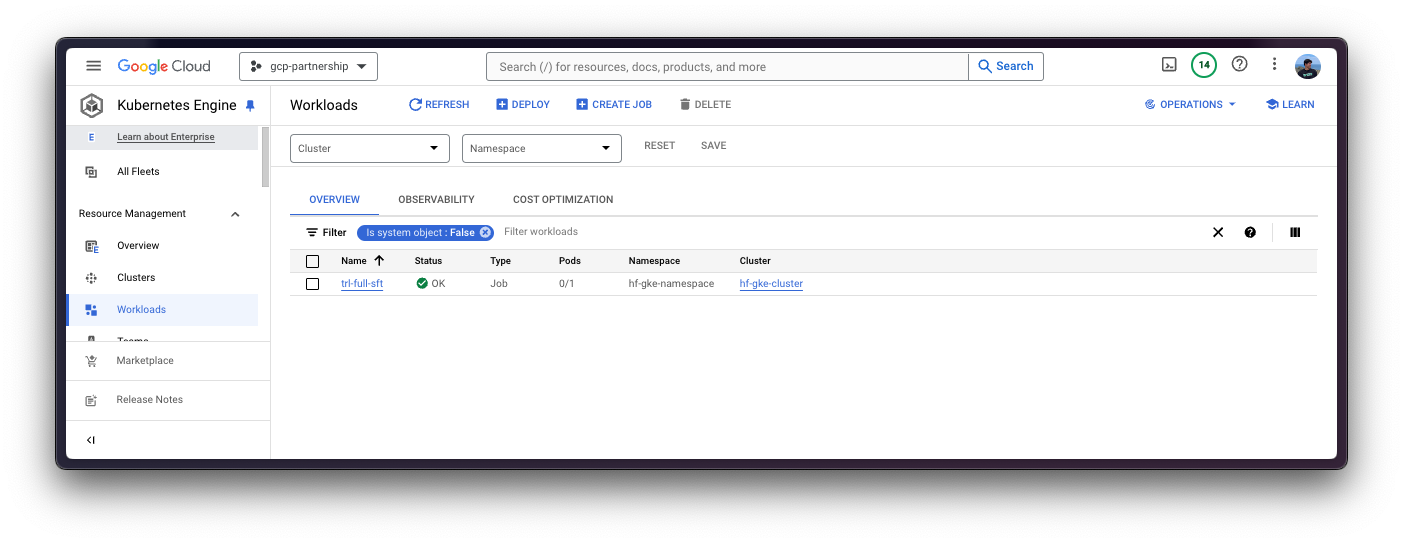
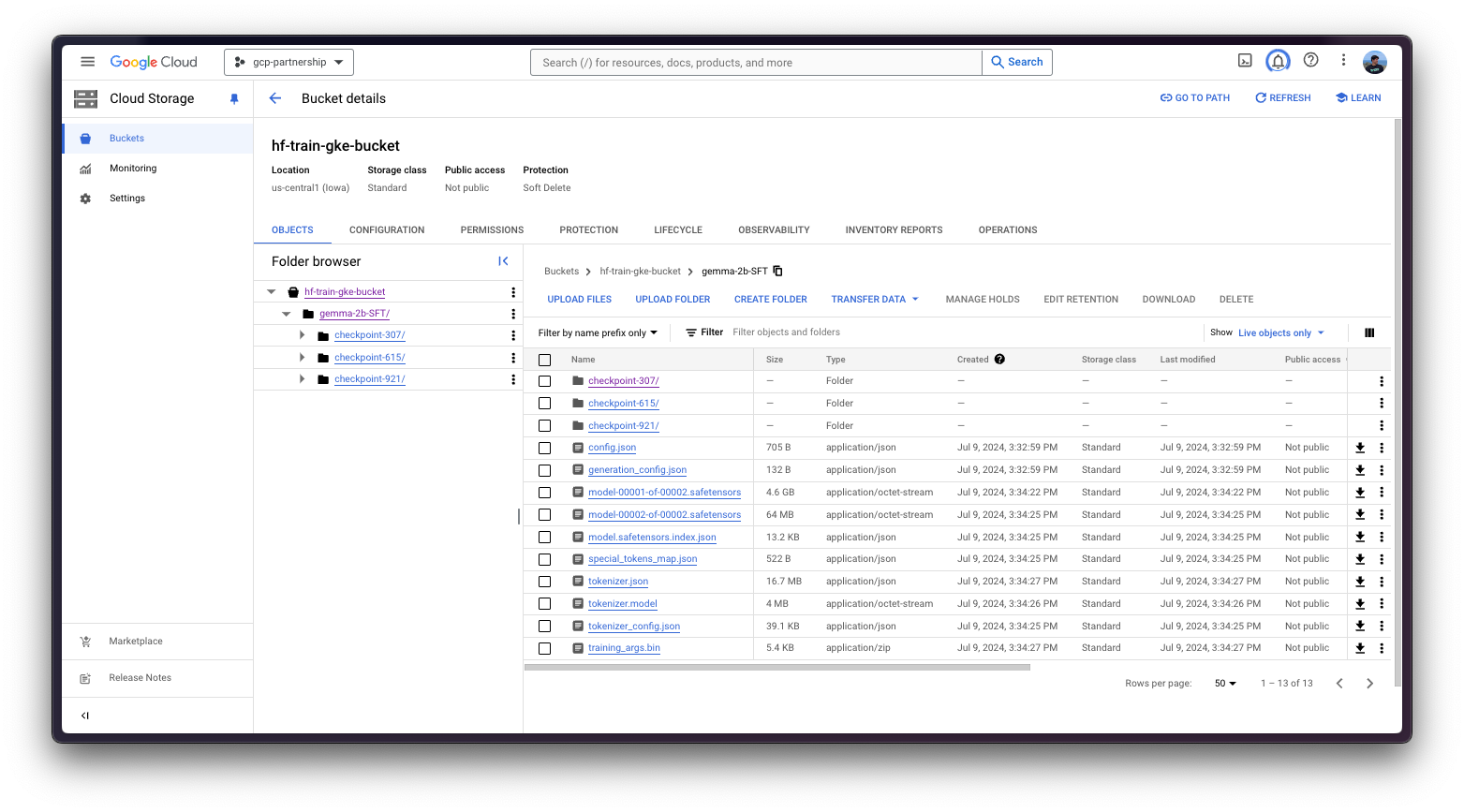
在这种情况下,由于您正在运行批处理作业,它将只使用 `job.yaml` 文件中指定的一个节点,因为您不需要其他任何东西。因此,该作业将部署一个 pod,该 pod 在 Hugging Face PyTorch DLC 训练容器之上运行 `trl sft` 命令,以及一个 GCS FUSE 容器,该容器将 GCS 存储桶挂载到 `/data` 路径,以便将生成的工件存储在 GCS 中。一旦作业完成,它将自动缩减到 0,这意味着它将不消耗资源。
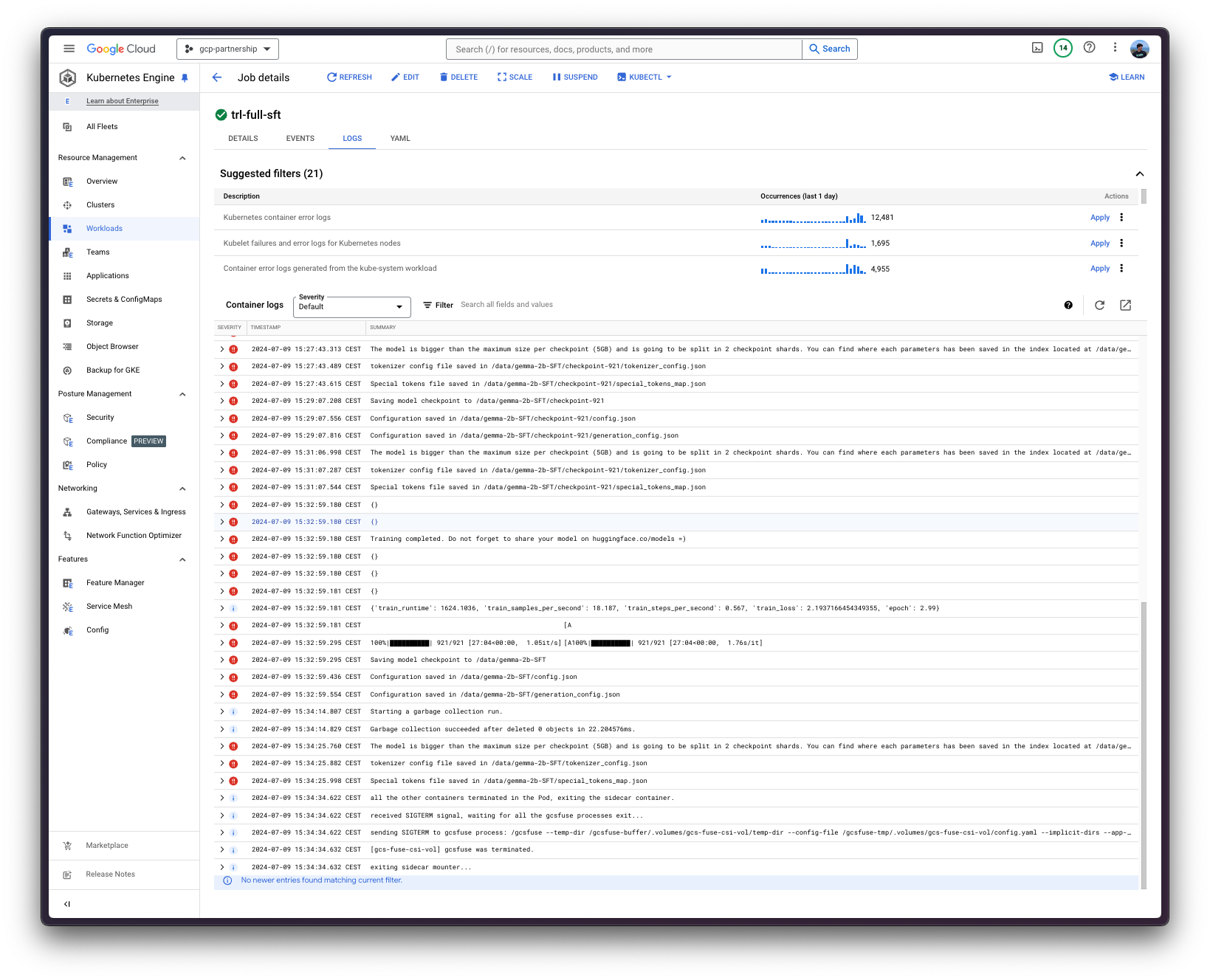
此外,您可以使用 `kubectl` 流式传输作业日志,如下所示:
kubectl logs -f job/trl-full-sft --container trl-container --namespace $NAMESPACE最后,一旦作业完成,Pod 将缩减到 0,并且工件将在作业中挂载的 GCS 存储桶中可见。
删除 GKE 集群
最后,一旦微调作业完成,您可以安全地删除 GKE 集群,以避免不必要的费用。
gcloud container clusters delete $CLUSTER_NAME --location=$LOCATION或者,您也可以选择在作业完成后继续运行 GKE 集群,因为使用 GKE Autopilot 模式部署的默认 GKE 集群仅运行单个 `e2-small` 实例。
📍 在 GitHub 上找到完整示例,点击这里!