Transformers 文档
FastSpeech2Conformer
并获得增强的文档体验
开始使用
FastSpeech2Conformer
概述
FastSpeech2Conformer 模型是 Pengcheng Guo、Florian Boyer、Xuankai Chang、Tomoki Hayashi、Yosuke Higuchi、Hirofumi Inaguma、Naoyuki Kamo、Chenda Li、Daniel Garcia-Romero、Jiatong Shi、Jing Shi、Shinji Watanabe、Kun Wei、Wangyou Zhang 和 Yuekai Zhang 在论文 由 Conformer 推动的 Espnet 工具包的最新发展 中提出的。
原始 FastSpeech2 论文的摘要如下:
非自回归文本到语音 (TTS) 模型,如 FastSpeech (Ren et al., 2019),可以比以前的自回归模型更快地合成语音,同时保持可比的质量。FastSpeech 模型的训练依赖于自回归教师模型进行时长预测(提供更多信息作为输入)和知识蒸馏(简化输出数据分布),这可以缓解 TTS 中的一对多映射问题(即多个语音变体对应相同的文本)。然而,FastSpeech 有几个缺点:1) 教师-学生蒸馏流程复杂且耗时,2) 从教师模型提取的时长不够准确,以及从教师模型蒸馏的目标 Mel 谱图由于数据简化而遭受信息损失,这两者都限制了语音质量。在本文中,我们提出了 FastSpeech 2,它通过以下方式解决了 FastSpeech 中的问题并更好地解决了一对多映射问题:1) 直接使用真实目标而不是教师模型的简化输出来训练模型,2) 引入更多语音变异信息(例如音高、能量和更准确的时长)作为条件输入。具体来说,我们从语音波形中提取时长、音高和能量,并在训练中直接将其作为条件输入,在推理中使用预测值。我们进一步设计了 FastSpeech 2s,这是首次尝试并行地从文本直接生成语音波形,从而享受了完全端到端推理的优势。实验结果表明:1) FastSpeech 2 实现了比 FastSpeech 快 3 倍的训练速度,FastSpeech 2s 甚至享有更快的推理速度;2) FastSpeech 2 和 2s 在语音质量上优于 FastSpeech,FastSpeech 2 甚至可以超越自回归模型。音频样本可在 https://speechresearch.github.io/fastspeech2/ 获取。
该模型由 Connor Henderson 贡献。原始代码可以在 此处 找到。
🤗 模型架构
FastSpeech2 的通用结构与 Mel 谱图解码器相结合,并且传统 Transformer 块被 Conformer 块取代,正如 ESPnet 库中所示。
FastSpeech2 模型架构

Conformer 块

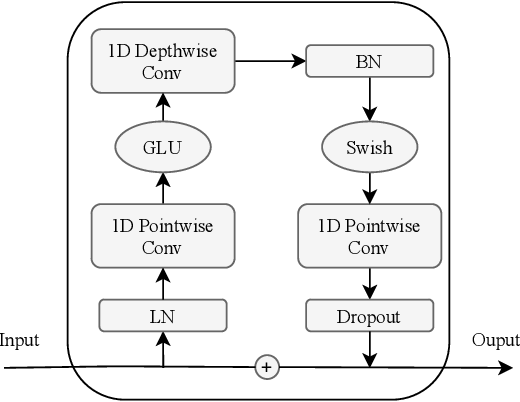
卷积模块
🤗 Transformers 用法
您可以使用 🤗 Transformers 库在本地运行 FastSpeech2Conformer。
- 首先安装 🤗 Transformers 库, g2p-en
pip install --upgrade pip pip install --upgrade transformers g2p-en
- 通过 Transformer 建模代码分别运行模型和 hifigan 的推理
from transformers import FastSpeech2ConformerTokenizer, FastSpeech2ConformerModel, FastSpeech2ConformerHifiGan
import soundfile as sf
tokenizer = FastSpeech2ConformerTokenizer.from_pretrained("espnet/fastspeech2_conformer")
inputs = tokenizer("Hello, my dog is cute.", return_tensors="pt")
input_ids = inputs["input_ids"]
model = FastSpeech2ConformerModel.from_pretrained("espnet/fastspeech2_conformer")
output_dict = model(input_ids, return_dict=True)
spectrogram = output_dict["spectrogram"]
hifigan = FastSpeech2ConformerHifiGan.from_pretrained("espnet/fastspeech2_conformer_hifigan")
waveform = hifigan(spectrogram)
sf.write("speech.wav", waveform.squeeze().detach().numpy(), samplerate=22050)- 通过 Transformer 建模代码运行模型和 hifigan 的组合推理
from transformers import FastSpeech2ConformerTokenizer, FastSpeech2ConformerWithHifiGan
import soundfile as sf
tokenizer = FastSpeech2ConformerTokenizer.from_pretrained("espnet/fastspeech2_conformer")
inputs = tokenizer("Hello, my dog is cute.", return_tensors="pt")
input_ids = inputs["input_ids"]
model = FastSpeech2ConformerWithHifiGan.from_pretrained("espnet/fastspeech2_conformer_with_hifigan")
output_dict = model(input_ids, return_dict=True)
waveform = output_dict["waveform"]
sf.write("speech.wav", waveform.squeeze().detach().numpy(), samplerate=22050)- 使用管道运行推理并指定要使用的声码器
from transformers import pipeline, FastSpeech2ConformerHifiGan
import soundfile as sf
vocoder = FastSpeech2ConformerHifiGan.from_pretrained("espnet/fastspeech2_conformer_hifigan")
synthesiser = pipeline(model="espnet/fastspeech2_conformer", vocoder=vocoder)
speech = synthesiser("Hello, my dog is cooler than you!")
sf.write("speech.wav", speech["audio"].squeeze(), samplerate=speech["sampling_rate"])FastSpeech2ConformerConfig
class transformers.FastSpeech2ConformerConfig
< 来源 >( hidden_size = 384 vocab_size = 78 num_mel_bins = 80 encoder_num_attention_heads = 2 encoder_layers = 4 encoder_linear_units = 1536 decoder_layers = 4 decoder_num_attention_heads = 2 decoder_linear_units = 1536 speech_decoder_postnet_layers = 5 speech_decoder_postnet_units = 256 speech_decoder_postnet_kernel = 5 positionwise_conv_kernel_size = 3 encoder_normalize_before = False decoder_normalize_before = False encoder_concat_after = False decoder_concat_after = False reduction_factor = 1 speaking_speed = 1.0 use_macaron_style_in_conformer = True use_cnn_in_conformer = True encoder_kernel_size = 7 decoder_kernel_size = 31 duration_predictor_layers = 2 duration_predictor_channels = 256 duration_predictor_kernel_size = 3 energy_predictor_layers = 2 energy_predictor_channels = 256 energy_predictor_kernel_size = 3 energy_predictor_dropout = 0.5 energy_embed_kernel_size = 1 energy_embed_dropout = 0.0 stop_gradient_from_energy_predictor = False pitch_predictor_layers = 5 pitch_predictor_channels = 256 pitch_predictor_kernel_size = 5 pitch_predictor_dropout = 0.5 pitch_embed_kernel_size = 1 pitch_embed_dropout = 0.0 stop_gradient_from_pitch_predictor = True encoder_dropout_rate = 0.2 encoder_positional_dropout_rate = 0.2 encoder_attention_dropout_rate = 0.2 decoder_dropout_rate = 0.2 decoder_positional_dropout_rate = 0.2 decoder_attention_dropout_rate = 0.2 duration_predictor_dropout_rate = 0.2 speech_decoder_postnet_dropout = 0.5 max_source_positions = 5000 use_masking = True use_weighted_masking = False num_speakers = None num_languages = None speaker_embed_dim = None is_encoder_decoder = True **kwargs )
参数
- hidden_size (
int, 可选, 默认为 384) — 隐藏层维度。 - vocab_size (
int, 可选, 默认为 78) — 词汇表大小。 - num_mel_bins (
int, 可选, 默认为 80) — 滤波器组中使用的 Mel 滤波器数量。 - encoder_num_attention_heads (
int, 可选, 默认为 2) — 编码器中的注意力头数量。 - encoder_layers (
int, 可选, 默认为 4) — 编码器中的层数。 - encoder_linear_units (
int, 可选, 默认为 1536) — 编码器线性层中的单元数量。 - decoder_layers (
int, 可选, 默认为 4) — 解码器中的层数。 - decoder_num_attention_heads (
int, 可选, 默认为 2) — 解码器中的注意力头数量。 - decoder_linear_units (
int, 可选, 默认为 1536) — 解码器线性层中的单元数量。 - speech_decoder_postnet_layers (
int, 可选, 默认为 5) — 语音解码器后处理网络中的层数。 - speech_decoder_postnet_units (
int, 可选, 默认为 256) — 语音解码器后处理网络层中的单元数量。 - speech_decoder_postnet_kernel (
int, 可选, 默认为 5) — 语音解码器后处理网络中的核大小。 - positionwise_conv_kernel_size (
int, 可选, 默认为 3) — 位置感知层中使用的卷积核大小。 - encoder_normalize_before (
bool, 可选, 默认为False) — 指定是否在编码器层之前进行归一化。 - decoder_normalize_before (
bool, 可选, 默认为False) — 指定是否在解码器层之前进行归一化。 - encoder_concat_after (
bool, 可选, 默认为False) — 指定是否在编码器层之后进行连接。 - decoder_concat_after (
bool, 可选, 默认为False) — 指定是否在解码器层之后进行连接。 - reduction_factor (
int, 可选, 默认为 1) — 语音帧速率的缩减因子。 - speaking_speed (
float, 可选, 默认为 1.0) — 生成语音的速度。 - use_macaron_style_in_conformer (
bool, 可选, 默认为True) — 指定是否在 conformer 中使用马卡龙风格。 - use_cnn_in_conformer (
bool, 可选, 默认为True) — 指定是否在 conformer 中使用卷积神经网络。 - encoder_kernel_size (
int, 可选, 默认为 7) — 编码器中使用的核大小。 - decoder_kernel_size (
int, 可选, 默认为 31) — 解码器中使用的核大小。 - duration_predictor_layers (
int, 可选, 默认为 2) — 时长预测器中的层数。 - duration_predictor_channels (
int, 可选, 默认为 256) — 时长预测器中的通道数量。 - duration_predictor_kernel_size (
int, 可选, 默认为 3) — 时长预测器中使用的核大小。 - energy_predictor_layers (
int, 可选, 默认为 2) — 能量预测器中的层数。 - energy_predictor_channels (
int, 可选, 默认为 256) — 能量预测器中的通道数量。 - energy_predictor_kernel_size (
int, 可选, 默认为 3) — 能量预测器中使用的核大小。 - energy_predictor_dropout (
float, 可选, 默认为 0.5) — 能量预测器中的 dropout 率。 - energy_embed_kernel_size (
int, 可选, 默认为 1) — 能量嵌入层中使用的核大小。 - energy_embed_dropout (
float, 可选, 默认为 0.0) — 能量嵌入层中的 dropout 率。 - stop_gradient_from_energy_predictor (
bool, 可选, 默认为False) — 指定是否阻止能量预测器的梯度。 - pitch_predictor_layers (
int, 可选, 默认为 5) — 音高预测器中的层数。 - pitch_predictor_channels (
int, 可选, 默认为 256) — 音高预测器中的通道数量。 - pitch_predictor_kernel_size (
int, 可选, 默认为 5) — 音高预测器中使用的核大小。 - pitch_predictor_dropout (
float, optional, 默认为 0.5) — 音高预测器中的 dropout 率。 - pitch_embed_kernel_size (
int, optional, 默认为 1) — 音高嵌入层中使用的核大小。 - pitch_embed_dropout (
float, optional, 默认为 0.0) — 音高嵌入层中的 dropout 率。 - stop_gradient_from_pitch_predictor (
bool, optional, 默认为True) — 指定是否停止音高预测器的梯度。 - encoder_dropout_rate (
float, optional, 默认为 0.2) — 编码器中的 dropout 率。 - encoder_positional_dropout_rate (
float, optional, 默认为 0.2) — 编码器中的位置 dropout 率。 - encoder_attention_dropout_rate (
float, optional, 默认为 0.2) — 编码器中的注意力 dropout 率。 - decoder_dropout_rate (
float, optional, 默认为 0.2) — 解码器中的 dropout 率。 - decoder_positional_dropout_rate (
float, optional, 默认为 0.2) — 解码器中的位置 dropout 率。 - decoder_attention_dropout_rate (
float, optional, 默认为 0.2) — 解码器中的注意力 dropout 率。 - duration_predictor_dropout_rate (
float, optional, 默认为 0.2) — 时长预测器中的 dropout 率。 - speech_decoder_postnet_dropout (
float, optional, 默认为 0.5) — 语音解码器 postnet 中的 dropout 率。 - max_source_positions (
int, optional, 默认为 5000) — 如果使用"relative"位置嵌入,定义最大源输入位置。 - use_masking (
bool, optional, 默认为True) — 指定是否在模型中使用掩码。 - use_weighted_masking (
bool, optional, 默认为False) — 指定是否在模型中使用加权掩码。 - num_speakers (
int, optional) — 说话人数量。如果设置为 > 1,则假定说话人 ID 将作为输入提供,并使用说话人 ID 嵌入层。 - num_languages (
int, optional) — 语言数量。如果设置为 > 1,则假定语言 ID 将作为输入提供,并使用语言 ID 嵌入层。 - speaker_embed_dim (
int, optional) — 说话人嵌入维度。如果设置为 > 0,则假定 speaker_embedding 将作为输入提供。 - is_encoder_decoder (
bool, optional, 默认为True) — 指定模型是否为编码器-解码器。
这是用于存储 FastSpeech2ConformerModel 配置的配置类。它用于根据指定的参数实例化 FastSpeech2Conformer 模型,定义模型架构。使用默认值实例化配置将产生与 FastSpeech2Conformer espnet/fastspeech2_conformer 架构类似的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。有关更多信息,请参阅 PretrainedConfig 的文档。
示例
>>> from transformers import FastSpeech2ConformerModel, FastSpeech2ConformerConfig
>>> # Initializing a FastSpeech2Conformer style configuration
>>> configuration = FastSpeech2ConformerConfig()
>>> # Initializing a model from the FastSpeech2Conformer style configuration
>>> model = FastSpeech2ConformerModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configFastSpeech2ConformerHifiGanConfig
class transformers.FastSpeech2ConformerHifiGanConfig
< source >( model_in_dim = 80 upsample_initial_channel = 512 upsample_rates = [8, 8, 2, 2] upsample_kernel_sizes = [16, 16, 4, 4] resblock_kernel_sizes = [3, 7, 11] resblock_dilation_sizes = [[1, 3, 5], [1, 3, 5], [1, 3, 5]] initializer_range = 0.01 leaky_relu_slope = 0.1 normalize_before = True **kwargs )
参数
- model_in_dim (
int, optional, 默认为 80) — 输入 log-mel 语谱图中的频率 bin 数量。 - upsample_initial_channel (
int, optional, 默认为 512) — 上采样网络中的输入通道数量。 - upsample_rates (
tuple[int]或list[int], optional, 默认为[8, 8, 2, 2]) — 定义上采样网络中每个一维卷积层的步幅的整数元组。upsample_rates 的长度定义了卷积层的数量,并且必须与 upsample_kernel_sizes 的长度匹配。 - upsample_kernel_sizes (
tuple[int]或list[int], optional, 默认为[16, 16, 4, 4]) — 定义上采样网络中每个一维卷积层的核大小的整数元组。upsample_kernel_sizes 的长度定义了卷积层的数量,并且必须与 upsample_rates 的长度匹配。 - resblock_kernel_sizes (
tuple[int]或list[int], optional, 默认为[3, 7, 11]) — 定义多感受野融合 (MRF) 模块中一维卷积层核大小的整数元组。 - resblock_dilation_sizes (
tuple[tuple[int]]或list[list[int]], optional, 默认为[[1, 3, 5], [1, 3, 5], [1, 3, 5]]) — 定义多感受野融合 (MRF) 模块中膨胀一维卷积层膨胀率的嵌套整数元组。 - initializer_range (
float, optional, 默认为 0.01) — 用于初始化所有权重矩阵的 truncated_normal_initializer 的标准差。 - leaky_relu_slope (
float, optional, 默认为 0.1) — Leaky ReLU 激活函数使用的负斜率角度。 - normalize_before (
bool, optional, 默认为True) — 是否在使用声码器学习到的均值和方差对声谱图进行归一化。
这是用于存储 FastSpeech2ConformerHifiGanModel 配置的配置类。它用于根据指定的参数实例化 FastSpeech2Conformer HiFi-GAN 声码器模型,定义模型架构。使用默认值实例化配置将产生与 FastSpeech2Conformer espnet/fastspeech2_conformer_hifigan 架构类似的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。有关更多信息,请参阅 PretrainedConfig 的文档。
示例
>>> from transformers import FastSpeech2ConformerHifiGan, FastSpeech2ConformerHifiGanConfig
>>> # Initializing a FastSpeech2ConformerHifiGan configuration
>>> configuration = FastSpeech2ConformerHifiGanConfig()
>>> # Initializing a model (with random weights) from the configuration
>>> model = FastSpeech2ConformerHifiGan(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configFastSpeech2ConformerWithHifiGanConfig
class transformers.FastSpeech2ConformerWithHifiGanConfig
< source >( model_config: typing.Optional[dict] = None vocoder_config: typing.Optional[dict] = None **kwargs )
这是用于存储 FastSpeech2ConformerWithHifiGan 配置的配置类。它用于根据指定的子模型配置实例化 FastSpeech2ConformerWithHifiGanModel 模型,定义模型架构。
使用默认值实例化配置将产生与 FastSpeech2ConformerModel espnet/fastspeech2_conformer 和 FastSpeech2ConformerHifiGan espnet/fastspeech2_conformer_hifigan 架构类似的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。有关更多信息,请参阅 PretrainedConfig 的文档。
model_config (FastSpeech2ConformerConfig, optional): 文本转语音模型的配置。vocoder_config (FastSpeech2ConformerHiFiGanConfig, optional): 声码器模型的配置。
示例
>>> from transformers import (
... FastSpeech2ConformerConfig,
... FastSpeech2ConformerHifiGanConfig,
... FastSpeech2ConformerWithHifiGanConfig,
... FastSpeech2ConformerWithHifiGan,
... )
>>> # Initializing FastSpeech2ConformerWithHifiGan sub-modules configurations.
>>> model_config = FastSpeech2ConformerConfig()
>>> vocoder_config = FastSpeech2ConformerHifiGanConfig()
>>> # Initializing a FastSpeech2ConformerWithHifiGan module style configuration
>>> configuration = FastSpeech2ConformerWithHifiGanConfig(model_config.to_dict(), vocoder_config.to_dict())
>>> # Initializing a model (with random weights)
>>> model = FastSpeech2ConformerWithHifiGan(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configFastSpeech2ConformerTokenizer
class transformers.FastSpeech2ConformerTokenizer
< source >( vocab_file bos_token = '<sos/eos>' eos_token = '<sos/eos>' pad_token = '<blank>' unk_token = '<unk>' should_strip_spaces = False **kwargs )
参数
- vocab_file (
str) — 词汇表文件的路径。 - bos_token (
str, optional, 默认为"<sos/eos>") — 序列开始标记。请注意,对于 FastSpeech2,它与eos_token相同。 - eos_token (
str, optional, 默认为"<sos/eos>") — 序列结束标记。请注意,对于 FastSpeech2,它与bos_token相同。 - pad_token (
str, optional, 默认为"<blank>") — 用于填充的标记,例如在批处理不同长度的序列时。 - unk_token (
str, optional, 默认为"<unk>") — 未知标记。不在词汇表中的标记不能转换为 ID,而是设置为此标记。 - should_strip_spaces (
bool, optional, 默认为False) — 是否从标记列表中去除空格。
构建 FastSpeech2Conformer 分词器。
__call__
< source >( text: typing.Union[str, list[str], list[list[str]], NoneType] = None text_pair: typing.Union[str, list[str], list[list[str]], NoneType] = None text_target: typing.Union[str, list[str], list[list[str]], NoneType] = None text_pair_target: typing.Union[str, list[str], list[list[str]], NoneType] = None add_special_tokens: bool = True padding: typing.Union[bool, str, transformers.utils.generic.PaddingStrategy] = False truncation: typing.Union[bool, str, transformers.tokenization_utils_base.TruncationStrategy, NoneType] = None max_length: typing.Optional[int] = None stride: int = 0 is_split_into_words: bool = False pad_to_multiple_of: typing.Optional[int] = None padding_side: typing.Optional[str] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None return_token_type_ids: typing.Optional[bool] = None return_attention_mask: typing.Optional[bool] = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True **kwargs → BatchEncoding
参数
- text (
str,list[str],list[list[str]], optional) — 要编码的序列或序列批次。每个序列可以是字符串或字符串列表(预分词字符串)。如果序列以字符串列表(预分词)形式提供,则必须设置is_split_into_words=True(以消除与序列批次的歧义)。 - text_pair (
str,list[str],list[list[str]], optional) — 要编码的序列或序列批次。每个序列可以是字符串或字符串列表(预分词字符串)。如果序列以字符串列表(预分词)形式提供,则必须设置is_split_into_words=True(以消除与序列批次的歧义)。 - text_target (
str,list[str],list[list[str]], optional) — 要作为目标文本编码的序列或序列批次。每个序列可以是字符串或字符串列表(预分词字符串)。如果序列以字符串列表(预分词)形式提供,则必须设置is_split_into_words=True(以消除与序列批次的歧义)。 - text_pair_target (
str,list[str],list[list[str]], optional) — 要作为目标文本编码的序列或序列批次。每个序列可以是字符串或字符串列表(预分词字符串)。如果序列以字符串列表(预分词)形式提供,则必须设置is_split_into_words=True(以消除与序列批次的歧义)。 - add_special_tokens (
bool, optional, 默认为True) — 编码序列时是否添加特殊标记。这将使用底层PretrainedTokenizerBase.build_inputs_with_special_tokens函数,该函数定义哪些标记会自动添加到输入 ID。如果您想自动添加bos或eos标记,这会很有用。 - padding (
bool,str或 PaddingStrategy, optional, 默认为False) — 激活并控制填充。接受以下值:True或'longest':填充到批次中最长的序列(如果只提供一个序列,则不填充)。'max_length':填充到由参数max_length指定的最大长度,如果未提供该参数,则填充到模型可接受的最大输入长度。False或'do_not_pad'(默认):不填充(即,可以输出包含不同长度序列的批次)。
- truncation (
bool,str或 TruncationStrategy, 可选, 默认为False) — 激活并控制截断。接受以下值:True或'longest_first':截断到由参数max_length指定的最大长度,如果未提供该参数,则截断到模型可接受的最大输入长度。这将逐个截断标记,如果提供了一对序列(或一批对),则从最长序列中移除一个标记。'only_first':截断到由参数max_length指定的最大长度,如果未提供该参数,则截断到模型可接受的最大输入长度。如果提供了一对序列(或一批对),这将仅截断一对中的第一个序列。'only_second':截断到由参数max_length指定的最大长度,如果未提供该参数,则截断到模型可接受的最大输入长度。如果提供了一对序列(或一批对),这将仅截断一对中的第二个序列。False或'do_not_truncate'(默认):不进行截断(即,可以输出序列长度大于模型最大允许输入大小的批次)。
- max_length (
int, 可选) — 控制截断/填充参数使用的最大长度。如果未设置或设置为
None,则如果截断/填充参数需要最大长度,将使用预定义的模型最大长度。如果模型没有特定的最大输入长度(如 XLNet),则最大长度的截断/填充将被停用。 - stride (
int, 可选, 默认为 0) — 如果与max_length一起设置为一个数字,当return_overflowing_tokens=True时返回的溢出标记将包含截断序列末尾的一些标记,以在截断序列和溢出序列之间提供一些重叠。此参数的值定义了重叠标记的数量。 - is_split_into_words (
bool, 可选, 默认为False) — 输入是否已预先分词(例如,按单词分割)。如果设置为True,分词器假定输入已按单词分割(例如,通过在空白处分割),然后它将对其进行分词。这对于 NER 或标记分类很有用。 - pad_to_multiple_of (
int, 可选) — 如果设置,将序列填充到所提供值的倍数。需要激活padding。这对于在计算能力>= 7.5(Volta) 的 NVIDIA 硬件上使用 Tensor Cores 特别有用。 - padding_side (
str, 可选) — 模型应在其上应用填充的侧面。应在 ['right', 'left'] 之间选择。默认值从同名的类属性中选取。 - return_tensors (
str或 TensorType, 可选) — 如果设置,将返回张量而不是 Python 整数列表。可接受的值为:'tf':返回 TensorFlowtf.constant对象。'pt':返回 PyTorchtorch.Tensor对象。'np':返回 Numpynp.ndarray对象。
- return_token_type_ids (
bool, 可选) — 是否返回标记类型 ID。如果保留默认值,将根据特定分词器的默认值(由return_outputs属性定义)返回标记类型 ID。 - return_attention_mask (
bool, 可选) — 是否返回注意力掩码。如果保留默认值,将根据特定分词器的默认值(由return_outputs属性定义)返回注意力掩码。 - return_overflowing_tokens (
bool, 可选, 默认为False) — 是否返回溢出标记序列。如果提供了输入 ID 的一对序列(或一批对),并且truncation_strategy = longest_first或True,则会引发错误而不是返回溢出标记。 - return_special_tokens_mask (
bool, 可选, 默认为False) — 是否返回特殊标记掩码信息。 - return_offsets_mapping (
bool, 可选, 默认为False) — 是否为每个标记返回(char_start, char_end)。这仅在继承自 PreTrainedTokenizerFast 的快速分词器上可用,如果使用 Python 的分词器,此方法将引发
NotImplementedError。 - return_length (
bool, 可选, 默认为False) — 是否返回编码输入的长度。 - verbose (
bool, 可选, 默认为True) — 是否打印更多信息和警告。 - **kwargs — 传递给
self.tokenize()方法
一个 BatchEncoding,包含以下字段:
-
input_ids — 要输入到模型中的标记 ID 列表。
-
token_type_ids — 要输入到模型中的标记类型 ID 列表(当
return_token_type_ids=True或如果 *“token_type_ids”* 在self.model_input_names中时)。 -
attention_mask — 指定模型应关注哪些标记的索引列表(当
return_attention_mask=True或如果 *“attention_mask”* 在self.model_input_names中时)。 -
overflowing_tokens — 溢出标记序列列表(当指定
max_length且return_overflowing_tokens=True时)。 -
num_truncated_tokens — 截断标记的数量(当指定
max_length且return_overflowing_tokens=True时)。 -
special_tokens_mask — 0 和 1 的列表,其中 1 表示添加的特殊标记,0 表示常规序列标记(当
add_special_tokens=True且return_special_tokens_mask=True时)。 -
length — 输入的长度(当
return_length=True时)
将一个或多个序列或一对或多对序列标记化并准备用于模型的主要方法。
save_vocabulary
< 源 >( save_directory: str filename_prefix: typing.Optional[str] = None ) → Tuple(str)
将词汇表和特殊标记文件保存到目录。
batch_decode
< 源 >( sequences: typing.Union[list[int], list[list[int]], ForwardRef('np.ndarray'), ForwardRef('torch.Tensor'), ForwardRef('tf.Tensor')] skip_special_tokens: bool = False clean_up_tokenization_spaces: typing.Optional[bool] = None **kwargs ) → list[str]
参数
- sequences (
Union[list[int], list[list[int]], np.ndarray, torch.Tensor, tf.Tensor]) — 标记化的输入 ID 列表。可以使用__call__方法获取。 - skip_special_tokens (
bool, 可选, 默认为False) — 解码时是否删除特殊标记。 - clean_up_tokenization_spaces (
bool, 可选) — 是否清理分词空间。如果为None,将默认为self.clean_up_tokenization_spaces。 - kwargs (附加关键字参数, 可选) — 将传递给底层模型特定的解码方法。
返回
list[str]
解码后的句子列表。
通过调用 decode 将标记 ID 列表的列表转换为字符串列表。
FastSpeech2ConformerModel
class transformers.FastSpeech2ConformerModel
< 源 >( config: FastSpeech2ConformerConfig )
参数
- config (FastSpeech2ConformerConfig) — 模型配置类,包含模型的所有参数。使用配置文件初始化不加载与模型相关的权重,只加载配置。请查看 from_pretrained() 方法加载模型权重。
FastSpeech2Conformer 模型。
此模型继承自 PreTrainedModel。请查看超类文档,了解库为其所有模型实现的一般方法(例如下载或保存、调整输入嵌入大小、修剪头部等)。
此模型也是 PyTorch torch.nn.Module 子类。将其作为常规 PyTorch 模块使用,并参考 PyTorch 文档了解所有与一般用法和行为相关的事项。
forward
< 源 >( input_ids: LongTensor attention_mask: typing.Optional[torch.LongTensor] = None spectrogram_labels: typing.Optional[torch.FloatTensor] = None duration_labels: typing.Optional[torch.LongTensor] = None pitch_labels: typing.Optional[torch.FloatTensor] = None energy_labels: typing.Optional[torch.FloatTensor] = None speaker_ids: typing.Optional[torch.LongTensor] = None lang_ids: typing.Optional[torch.LongTensor] = None speaker_embedding: typing.Optional[torch.FloatTensor] = None return_dict: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None ) → transformers.models.fastspeech2_conformer.modeling_fastspeech2_conformer.FastSpeech2ConformerModelOutput 或 tuple(torch.FloatTensor)
参数
- input_ids (形状为
(batch_size, sequence_length)的torch.LongTensor) — 文本向量的输入序列。 - attention_mask (形状为
(batch_size, sequence_length)的torch.LongTensor, 可选) — 避免对填充标记索引执行注意力操作的掩码。掩码值选择在[0, 1]之间:- 1 表示 未被掩码 的标记,
- 0 表示 被掩码 的标记。
- spectrogram_labels (形状为
(batch_size, max_spectrogram_length, num_mel_bins)的torch.FloatTensor, 可选, 默认为None) — 填充的目标特征批次。 - duration_labels (形状为
(batch_size, sequence_length + 1)的torch.LongTensor, 可选, 默认为None) — 填充的持续时间批次。 - pitch_labels (形状为
(batch_size, sequence_length + 1, 1)的torch.FloatTensor, 可选, 默认为None) — 填充的按标记平均的音高批次。 - energy_labels (形状为
(batch_size, sequence_length + 1, 1)的torch.FloatTensor, 可选, 默认为None) — 填充的按标记平均的能量批次。 - speaker_ids (形状为
(batch_size, 1)的torch.LongTensor, 可选, 默认为None) — 用于通过模型调节语音输出特征的说话人 ID。 - lang_ids (形状为
(batch_size, 1)的torch.LongTensor, 可选, 默认为None) — 用于通过模型调节语音输出特征的语言 ID。 - speaker_embedding (形状为
(batch_size, embedding_dim)的torch.FloatTensor, 可选, 默认为None) — 包含语音特征调节信号的嵌入。 - return_dict (
bool, 可选) — 是否返回 ModelOutput 而不是纯元组。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。
返回
transformers.models.fastspeech2_conformer.modeling_fastspeech2_conformer.FastSpeech2ConformerModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.models.fastspeech2_conformer.modeling_fastspeech2_conformer.FastSpeech2ConformerModelOutput 或一个 torch.FloatTensor 元组(如果传递 return_dict=False 或当 config.return_dict=False 时),包含根据配置 (FastSpeech2ConformerConfig) 和输入的不同元素。
-
loss (形状为
(1,)的torch.FloatTensor, 可选, 提供labels时返回) — 频谱图生成损失。 -
spectrogram (形状为
(batch_size, sequence_length, num_bins)的torch.FloatTensor, 可选, 默认为None) — 预测的频谱图。 -
encoder_last_hidden_state (形状为
(batch_size, sequence_length, hidden_size)的torch.FloatTensor, 可选, 默认为None) — 模型编码器最后一层输出的隐藏状态序列。 -
encoder_hidden_states (
tuple[torch.FloatTensor], 可选, 传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于嵌入层输出,如果模型有嵌入层,+一个用于每层输出)。编码器在每一层输出时的隐藏状态以及初始嵌入输出。
-
encoder_attentions (
tuple[torch.FloatTensor], 可选, 传递output_attentions=True或当config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。编码器的注意力权重,在注意力 softmax 之后,用于计算自注意力头中的加权平均。
-
decoder_hidden_states (
tuple[torch.FloatTensor], 可选, 传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于嵌入层输出,如果模型有嵌入层,+一个用于每层输出)。解码器在每一层输出时的隐藏状态以及初始嵌入输出。
-
decoder_attentions (
tuple[torch.FloatTensor], 可选, 传递output_attentions=True或当config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。解码器的注意力权重,在注意力 softmax 之后,用于计算自注意力头中的加权平均。
-
duration_outputs (形状为
(batch_size, max_text_length + 1)的torch.LongTensor, 可选) — 持续时间预测器的输出。 -
pitch_outputs (形状为
(batch_size, max_text_length + 1, 1)的torch.FloatTensor, 可选) — 音高预测器的输出。 -
energy_outputs (形状为
(batch_size, max_text_length + 1, 1)的torch.FloatTensor, 可选) — 能量预测器的输出。
FastSpeech2ConformerModel 的 forward 方法,覆盖了 __call__ 特殊方法。
尽管前向传播的配方需要在该函数内定义,但之后应调用 Module 实例,而不是此函数,因为前者负责运行预处理和后处理步骤,而后者则默默忽略它们。
示例
>>> from transformers import (
... FastSpeech2ConformerTokenizer,
... FastSpeech2ConformerModel,
... FastSpeech2ConformerHifiGan,
... )
>>> tokenizer = FastSpeech2ConformerTokenizer.from_pretrained("espnet/fastspeech2_conformer")
>>> inputs = tokenizer("some text to convert to speech", return_tensors="pt")
>>> input_ids = inputs["input_ids"]
>>> model = FastSpeech2ConformerModel.from_pretrained("espnet/fastspeech2_conformer")
>>> output_dict = model(input_ids, return_dict=True)
>>> spectrogram = output_dict["spectrogram"]
>>> vocoder = FastSpeech2ConformerHifiGan.from_pretrained("espnet/fastspeech2_conformer_hifigan")
>>> waveform = vocoder(spectrogram)
>>> print(waveform.shape)
torch.Size([1, 49664])FastSpeech2ConformerHifiGan
class transformers.FastSpeech2ConformerHifiGan
< 源 >( config: FastSpeech2ConformerHifiGanConfig )
参数
- config (FastSpeech2ConformerHifiGanConfig) — 模型配置类,包含模型的所有参数。使用配置文件初始化不加载与模型相关的权重,只加载配置。请查看 from_pretrained() 方法加载模型权重。
HiFi-GAN 声码器。
此模型继承自 PreTrainedModel。请查看超类文档,了解库为其所有模型实现的一般方法(例如下载或保存、调整输入嵌入大小、修剪头部等)。
此模型也是 PyTorch torch.nn.Module 子类。将其作为常规 PyTorch 模块使用,并参考 PyTorch 文档了解所有与一般用法和行为相关的事项。
forward
< 源 >( spectrogram: FloatTensor **kwargs ) → torch.FloatTensor
将对数梅尔谱图转换为语音波形。传递一批对数梅尔谱图将返回一批语音波形。传递单个未批处理的对数梅尔谱图将返回单个未批处理的语音波形。
FastSpeech2ConformerWithHifiGan
class transformers.FastSpeech2ConformerWithHifiGan
< source >( config: FastSpeech2ConformerWithHifiGanConfig )
参数
- config (FastSpeech2ConformerWithHifiGanConfig) — 模型配置类,包含模型的所有参数。用配置文件初始化并不会加载与模型相关的权重,只加载配置。请查看 from_pretrained() 方法加载模型权重。
带有 FastSpeech2ConformerHifiGan 声码器头的 FastSpeech2ConformerModel,用于执行文本到语音(波形)转换。
此模型继承自 PreTrainedModel。请查看超类文档,了解库为其所有模型实现的一般方法(例如下载或保存、调整输入嵌入大小、修剪头部等)。
此模型也是 PyTorch torch.nn.Module 子类。将其作为常规 PyTorch 模块使用,并参考 PyTorch 文档了解所有与一般用法和行为相关的事项。
forward
< source >( input_ids: LongTensor attention_mask: typing.Optional[torch.LongTensor] = None spectrogram_labels: typing.Optional[torch.FloatTensor] = None duration_labels: typing.Optional[torch.LongTensor] = None pitch_labels: typing.Optional[torch.FloatTensor] = None energy_labels: typing.Optional[torch.FloatTensor] = None speaker_ids: typing.Optional[torch.LongTensor] = None lang_ids: typing.Optional[torch.LongTensor] = None speaker_embedding: typing.Optional[torch.FloatTensor] = None return_dict: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None ) → transformers.models.fastspeech2_conformer.modeling_fastspeech2_conformer.FastSpeech2ConformerModelOutput 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensor,形状为(batch_size, sequence_length)) — 文本向量输入序列。 - attention_mask (
torch.LongTensor,形状为(batch_size, sequence_length), 可选) — 用于避免对填充标记索引执行注意力操作的掩码。掩码值选择在[0, 1]之间:- 1 表示 未被掩码 的标记,
- 0 表示 被掩码 的标记。
- spectrogram_labels (
torch.FloatTensor,形状为(batch_size, max_spectrogram_length, num_mel_bins), 可选, 默认为None) — 填充后的目标特征批次。 - duration_labels (
torch.LongTensor,形状为(batch_size, sequence_length + 1), 可选, 默认为None) — 填充后的持续时间批次。 - pitch_labels (
torch.FloatTensor,形状为(batch_size, sequence_length + 1, 1), 可选, 默认为None) — 填充后的音高标记平均值批次。 - energy_labels (
torch.FloatTensor,形状为(batch_size, sequence_length + 1, 1), 可选, 默认为None) — 填充后的能量标记平均值批次。 - speaker_ids (
torch.LongTensor,形状为(batch_size, 1), 可选, 默认为None) — 用于根据模型输出的语音特征进行条件化的说话人 ID。 - lang_ids (
torch.LongTensor,形状为(batch_size, 1), 可选, 默认为None) — 用于根据模型输出的语音特征进行条件化的语言 ID。 - speaker_embedding (
torch.FloatTensor,形状为(batch_size, embedding_dim), 可选, 默认为None) — 包含语音特征条件信号的嵌入。 - return_dict (
bool, 可选) — 是否返回 ModelOutput 而不是普通元组。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。更多详情请参见返回张量中的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。更多详情请参见返回张量中的hidden_states。
返回
transformers.models.fastspeech2_conformer.modeling_fastspeech2_conformer.FastSpeech2ConformerModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.models.fastspeech2_conformer.modeling_fastspeech2_conformer.FastSpeech2ConformerModelOutput 或一个 torch.FloatTensor 元组(如果传递 return_dict=False 或当 config.return_dict=False 时),包含根据配置 (FastSpeech2ConformerConfig) 和输入的不同元素。
-
loss (形状为
(1,)的torch.FloatTensor, 可选, 提供labels时返回) — 频谱图生成损失。 -
spectrogram (形状为
(batch_size, sequence_length, num_bins)的torch.FloatTensor, 可选, 默认为None) — 预测的频谱图。 -
encoder_last_hidden_state (形状为
(batch_size, sequence_length, hidden_size)的torch.FloatTensor, 可选, 默认为None) — 模型编码器最后一层输出的隐藏状态序列。 -
encoder_hidden_states (
tuple[torch.FloatTensor], 可选, 传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于嵌入层输出,如果模型有嵌入层,+一个用于每层输出)。编码器在每一层输出时的隐藏状态以及初始嵌入输出。
-
encoder_attentions (
tuple[torch.FloatTensor], 可选, 传递output_attentions=True或当config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。编码器的注意力权重,在注意力 softmax 之后,用于计算自注意力头中的加权平均。
-
decoder_hidden_states (
tuple[torch.FloatTensor], 可选, 传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于嵌入层输出,如果模型有嵌入层,+一个用于每层输出)。解码器在每一层输出时的隐藏状态以及初始嵌入输出。
-
decoder_attentions (
tuple[torch.FloatTensor], 可选, 传递output_attentions=True或当config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。解码器的注意力权重,在注意力 softmax 之后,用于计算自注意力头中的加权平均。
-
duration_outputs (形状为
(batch_size, max_text_length + 1)的torch.LongTensor, 可选) — 持续时间预测器的输出。 -
pitch_outputs (形状为
(batch_size, max_text_length + 1, 1)的torch.FloatTensor, 可选) — 音高预测器的输出。 -
energy_outputs (形状为
(batch_size, max_text_length + 1, 1)的torch.FloatTensor, 可选) — 能量预测器的输出。
FastSpeech2ConformerWithHifiGan 的 forward 方法,重写了 __call__ 特殊方法。
尽管前向传播的配方需要在该函数内定义,但之后应调用 Module 实例,而不是此函数,因为前者负责运行预处理和后处理步骤,而后者则默默忽略它们。
示例
>>> from transformers import (
... FastSpeech2ConformerTokenizer,
... FastSpeech2ConformerWithHifiGan,
... )
>>> tokenizer = FastSpeech2ConformerTokenizer.from_pretrained("espnet/fastspeech2_conformer")
>>> inputs = tokenizer("some text to convert to speech", return_tensors="pt")
>>> input_ids = inputs["input_ids"]
>>> model = FastSpeech2ConformerWithHifiGan.from_pretrained("espnet/fastspeech2_conformer_with_hifigan")
>>> output_dict = model(input_ids, return_dict=True)
>>> waveform = output_dict["waveform"]
>>> print(waveform.shape)
torch.Size([1, 49664])