AutoTrain 文档
使用 AutoTrain 进行抽取式问答
并获得增强的文档体验
开始使用
使用 AutoTrain 进行抽取式问答
抽取式问答(QA)使人工智能模型能够从文本段落中查找并提取精确的答案。本指南将向您展示如何使用 AutoTrain 训练自定义的问答模型,支持像 BERT、RoBERTa 和 DeBERTa 这样的流行架构。
什么是抽取式问答?
抽取式问答模型学习
- 在较长的文本段落中定位确切的答案范围
- 理解问题并将其与相关上下文匹配
- 提取精确答案而不是生成答案
- 处理关于文本的简单和复杂查询
准备您的数据
您的数据集需要以下基本列
text: 包含潜在答案的段落(也称为上下文)question: 您想回答的查询answer: 答案范围信息,包括文本和位置
以下是您的数据集应有的示例
{"context":"Architecturally, the school has a Catholic character. Atop the Main Building's gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend \"Venite Ad Me Omnes\". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.","question":"To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?","answers":{"text":["Saint Bernadette Soubirous"],"answer_start":[515]}}
{"context":"Architecturally, the school has a Catholic character. Atop the Main Building's gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend \"Venite Ad Me Omnes\". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.","question":"What is in front of the Notre Dame Main Building?","answers":{"text":["a copper statue of Christ"],"answer_start":[188]}}
{"context":"Architecturally, the school has a Catholic character. Atop the Main Building's gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend \"Venite Ad Me Omnes\". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.","question":"The Basilica of the Sacred heart at Notre Dame is beside to which structure?","answers":{"text":["the Main Building"],"answer_start":[279]}}注意:问答任务的首选格式是 JSONL,如果您想使用 CSV,answer 列应为包含 text 和 answer_start 键的字符串化 JSON。
Hugging Face Hub 上的示例数据集:lhoestq/squad
附注:您可以使用 squad 和 squad v2 两种数据格式,只要正确进行列映射即可。
训练选项
本地训练
在您自己的硬件上训练模型,完全控制整个过程。
要在本地训练一个抽取式问答模型,您需要一个配置文件
task: extractive-qa
base_model: google-bert/bert-base-uncased
project_name: autotrain-bert-ex-qa1
log: tensorboard
backend: local
data:
path: lhoestq/squad
train_split: train
valid_split: validation
column_mapping:
text_column: context
question_column: question
answer_column: answers
params:
max_seq_length: 512
max_doc_stride: 128
epochs: 3
batch_size: 4
lr: 2e-5
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 1
mixed_precision: fp16
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true要训练模型,请运行以下命令
$ autotrain --config config.yaml
在这里,我们正在 SQuAD 数据集上使用抽取式问答任务训练一个 BERT 模型。该模型训练 3 个 epoch,批大小为 4,学习率为 2e-5。训练过程使用 TensorBoard 进行日志记录。模型在本地训练,并在训练后推送到 Hugging Face Hub。
在 Hugging Face 上进行云训练
使用 Hugging Face 的云基础设施训练模型,以获得更好的可扩展性。
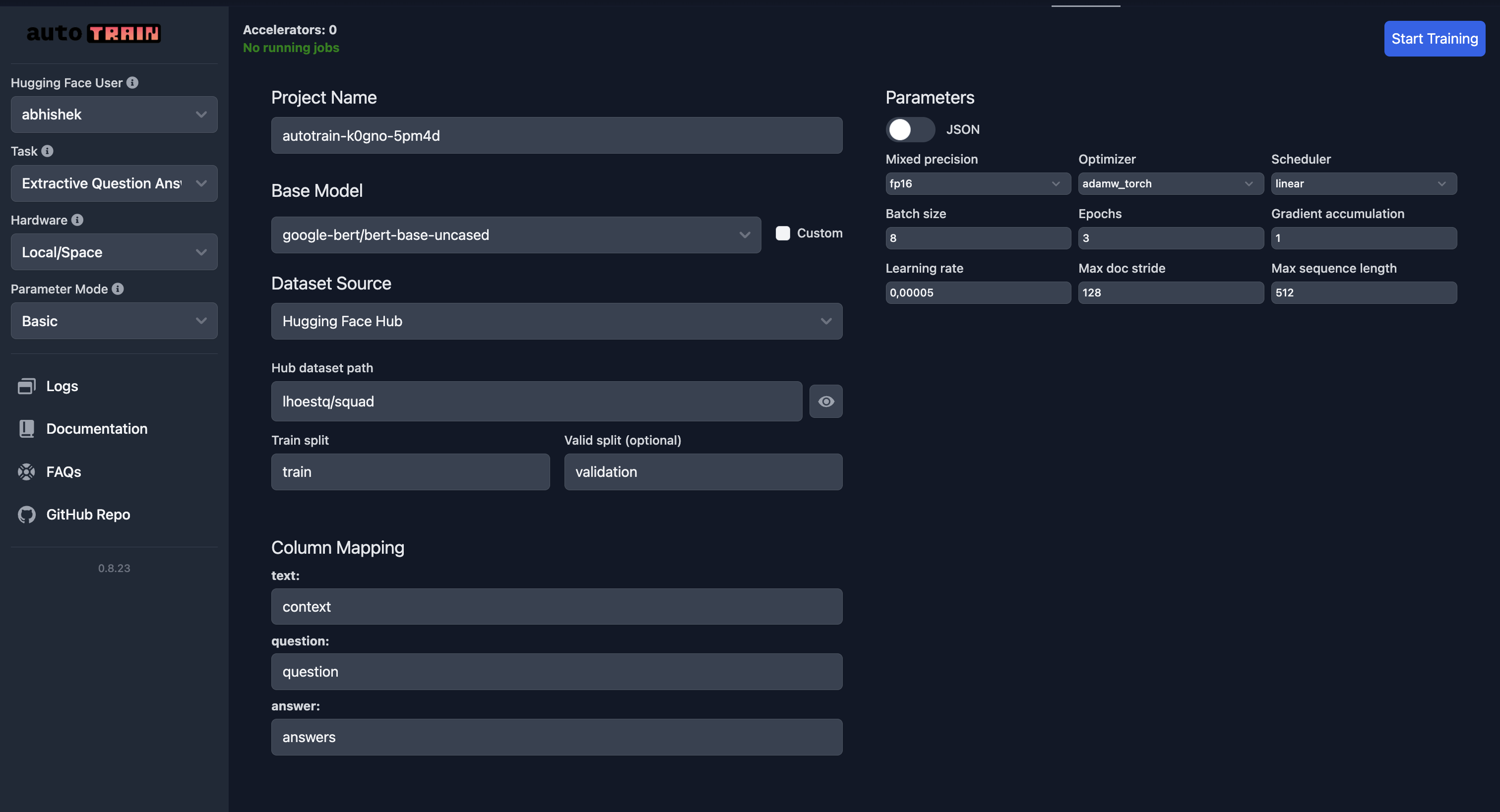
和往常一样,请特别注意列映射。
参数参考
class autotrain.trainers.extractive_question_answering.params.ExtractiveQuestionAnsweringParams
< 来源 >( data_path: str = None model: str = 'bert-base-uncased' lr: float = 5e-05 epochs: int = 3 max_seq_length: int = 128 max_doc_stride: int = 128 batch_size: int = 8 warmup_ratio: float = 0.1 gradient_accumulation: int = 1 optimizer: str = 'adamw_torch' scheduler: str = 'linear' weight_decay: float = 0.0 max_grad_norm: float = 1.0 seed: int = 42 train_split: str = 'train' valid_split: typing.Optional[str] = None text_column: str = 'context' question_column: str = 'question' answer_column: str = 'answers' logging_steps: int = -1 project_name: str = 'project-name' auto_find_batch_size: bool = False mixed_precision: typing.Optional[str] = None save_total_limit: int = 1 token: typing.Optional[str] = None push_to_hub: bool = False eval_strategy: str = 'epoch' username: typing.Optional[str] = None log: str = 'none' early_stopping_patience: int = 5 early_stopping_threshold: float = 0.01 )
参数
- data_path (str) — 数据集路径。
- model (str) — 预训练模型名称。默认为 “bert-base-uncased”。
- lr (float) — 优化器的学习率。默认为 5e-5。
- epochs (int) — 训练的 epoch 数。默认为 3。
- max_seq_length (int) — 输入的最大序列长度。默认为 128。
- max_doc_stride (int) — 用于拆分上下文的最大文档步幅。默认为 128。
- batch_size (int) — 训练的批大小。默认为 8。
- warmup_ratio (float) — 学习率调度器的预热比例。默认为 0.1。
- gradient_accumulation (int) — 梯度累积步数。默认为 1。
- optimizer (str) — 优化器类型。默认为 “adamw_torch”。
- scheduler (str) — 学习率调度器类型。默认为 “linear”。
- weight_decay (float) — 优化器的权重衰减。默认为 0.0。
- max_grad_norm (float) — 用于裁剪的最大梯度范数。默认为 1.0。
- seed (int) — 用于可复现性的随机种子。默认为 42。
- train_split (str) — 训练数据分割的名称。默认为 “train”。
- valid_split (Optional[str]) — 验证数据分割的名称。默认为 None。
- text_column (str) — 上下文/文本的列名。默认为 “context”。
- question_column (str) — 问题的列名。默认为 “question”。
- answer_column (str) — 答案的列名。默认为 “answers”。
- logging_steps (int) — 两次日志记录之间的步数。默认为 -1。
- project_name (str) — 用于输出目录的项目名称。默认为 “project-name”。
- auto_find_batch_size (bool) — 自动寻找最佳批大小。默认为 False。
- mixed_precision (Optional[str]) — 混合精度训练模式 (fp16, bf16 或 None)。默认为 None。
- save_total_limit (int) — 要保存的最大检查点数量。默认为 1。
- token (Optional[str]) — 用于 Hugging Face Hub 的身份验证令牌。默认为 None。
- push_to_hub (bool) — 是否将模型推送到 Hugging Face Hub。默认为 False。
- eval_strategy (str) — 训练期间的评估策略。默认为 “epoch”。
- username (Optional[str]) — 用于身份验证的 Hugging Face 用户名。默认为 None。
- log (str) — 用于实验跟踪的日志记录方法。默认为 “none”。
- early_stopping_patience (int) — 提前停止前无改进的 epoch 数。默认为 5。
- early_stopping_threshold (float) — 提前停止改进的阈值。默认为 0.01。
ExtractiveQuestionAnsweringParams