AutoTrain 文档
文本分类 & 回归
并获得增强的文档体验
开始使用
文本分类 & 回归
使用 AutoTrain 训练文本分类/回归模型超级简单!只需将您的数据准备成正确的格式,然后点击几下,您最先进的模型就可以用于生产环境了。
配置文件任务名称
text_classification文本分类text_regressiontext-regression
数据格式
文本分类/回归支持 CSV 和 JSONL 格式的数据集。
CSV 格式
让我们来训练一个模型,用于对电影评论的情感进行分类。数据应为以下 CSV 格式:
text,target
"this movie is great",positive
"this movie is bad",negative
.
.
.如您所见,CSV 文件中有两列。一列是文本,另一列是标签。标签可以是任何字符串。在此示例中,我们有两个标签:`positive` 和 `negative`。您可以根据需要拥有任意数量的标签。
如果您想训练一个模型,对电影评论进行 1-5 分的评分,数据可以如下所示:
text,target
"this movie is great",4.9
"this movie is bad",1.5
.
.
.JSONL 格式
除了 CSV,您还可以使用 JSONL 格式。JSONL 格式应如下所示:
{"text": "this movie is great", "target": "positive"}
{"text": "this movie is bad", "target": "negative"}
.
.
.对于回归任务:
{"text": "this movie is great", "target": 4.9}
{"text": "this movie is bad", "target": 1.5}
.
.列映射/名称
您的 CSV 数据集必须有两列:`text` 和 `target`。如果您的列名与 `text` 和 `target` 不同,您可以将数据集的列映射到 AutoTrain 的列名。
训练
本地训练
要在本地训练文本分类/回归模型,您可以使用 `autotrain --config config.yaml` 命令。
这是一个用于训练文本分类模型的 `config.yaml` 文件示例:
task: text_classification # or text_regression
base_model: google-bert/bert-base-uncased
project_name: autotrain-bert-imdb-finetuned
log: tensorboard
backend: local
data:
path: stanfordnlp/imdb
train_split: train
valid_split: test
column_mapping:
text_column: text
target_column: label
params:
max_seq_length: 512
epochs: 3
batch_size: 4
lr: 2e-5
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 1
mixed_precision: fp16
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true在这个例子中,我们使用 `google-bert/bert-base-uncased` 模型在 IMDB 数据集上训练一个文本分类模型。我们使用的是 `stanfordnlp/imdb` 数据集,它已经可以在 Hugging Face Hub 上找到。我们将模型训练 3 个 epoch,批处理大小为 4,学习率为 `2e-5`。我们使用 `adamw_torch` 优化器和 `linear` 调度器。我们还使用了混合精度训练,梯度累积为 1。
如果您想使用本地的 CSV/JSONL 数据集,可以将 `data` 部分更改为:
data:
path: data/ # this must be the path to the directory containing the train and valid files
train_split: train # this must be either train.csv or train.json
valid_split: valid # this must be either valid.csv or valid.json
column_mapping:
text_column: text # this must be the name of the column containing the text
target_column: label # this must be the name of the column containing the target要训练模型,请运行以下命令
$ autotrain --config config.yaml
在 Hugging Face Spaces 上训练
在 Hugging Face Spaces 上训练的参数与本地训练相同。如果您使用自己的数据集,请选择“本地”作为数据集源并上传您的数据集。在下面的截图中,我们正在使用 `google-bert/bert-base-uncased` 模型在 IMDB 数据集上训练一个文本分类模型。
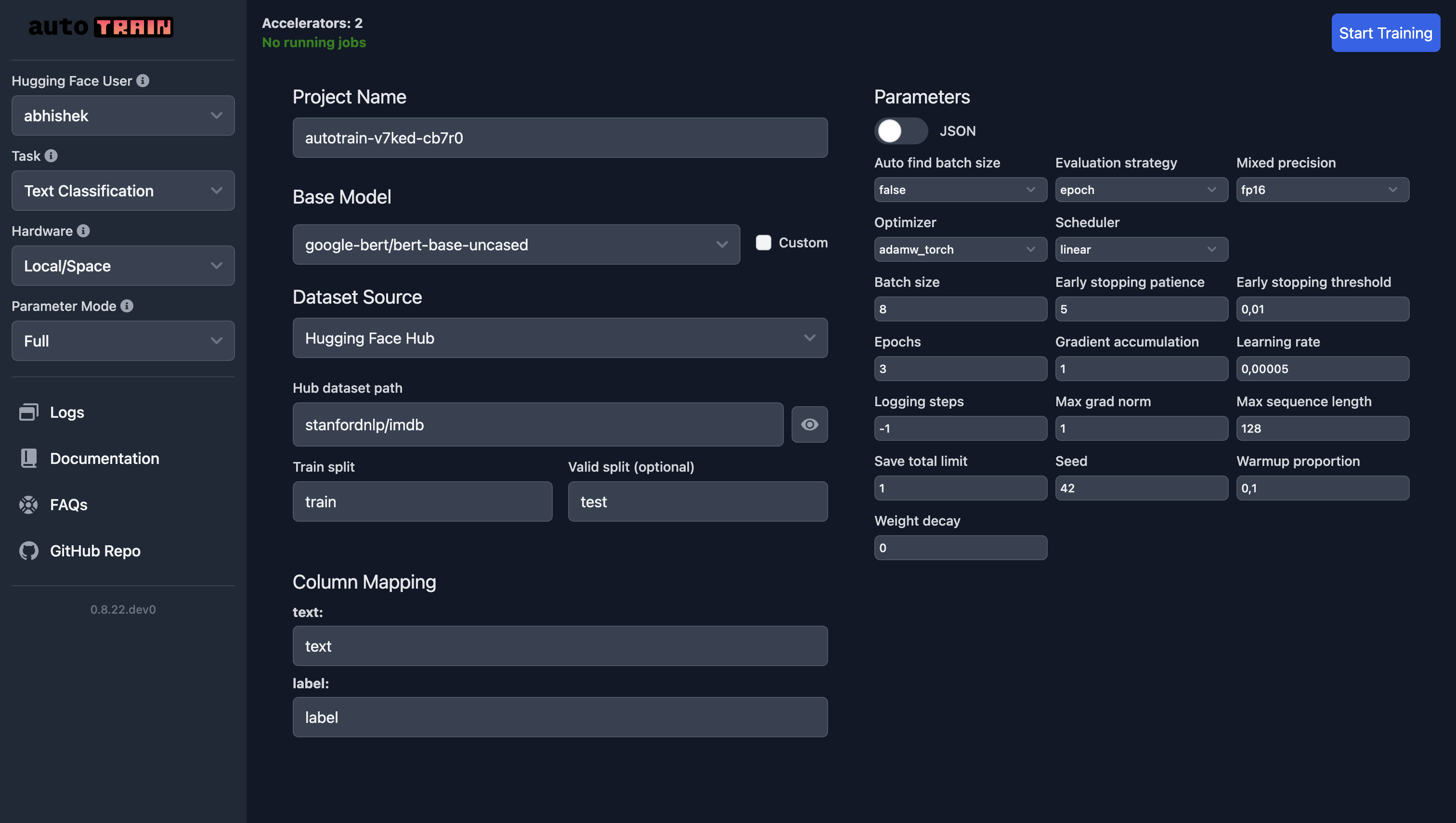
对于文本回归,您只需选择“文本回归”作为任务,其他所有内容都保持不变(当然,除了数据)。
训练参数
文本分类和回归的训练参数是相同的。
class autotrain.trainers.text_classification.params.TextClassificationParams
< 源码 >( data_path: str = None model: str = 'bert-base-uncased' lr: float = 5e-05 epochs: int = 3 max_seq_length: int = 128 batch_size: int = 8 warmup_ratio: float = 0.1 gradient_accumulation: int = 1 optimizer: str = 'adamw_torch' scheduler: str = 'linear' weight_decay: float = 0.0 max_grad_norm: float = 1.0 seed: int = 42 train_split: str = 'train' valid_split: typing.Optional[str] = None text_column: str = 'text' target_column: str = 'target' logging_steps: int = -1 project_name: str = 'project-name' auto_find_batch_size: bool = False mixed_precision: typing.Optional[str] = None save_total_limit: int = 1 token: typing.Optional[str] = None push_to_hub: bool = False eval_strategy: str = 'epoch' username: typing.Optional[str] = None log: str = 'none' early_stopping_patience: int = 5 early_stopping_threshold: float = 0.01 )
参数
- data_path (str) — 数据集路径。
- model (str) — 要使用的模型名称。默认为“bert-base-uncased”。
- lr (float) — 学习率。默认为 5e-5。
- epochs (int) — 训练轮数。默认为 3。
- max_seq_length (int) — 最大序列长度。默认为 128。
- batch_size (int) — 训练批次大小。默认为 8。
- warmup_ratio (float) — 预热比例。默认为 0.1。
- gradient_accumulation (int) — 梯度累积步数。默认为 1。
- optimizer (str) — 要使用的优化器。默认为“adamw_torch”。
- scheduler (str) — 要使用的调度器。默认为“linear”。
- weight_decay (float) — 权重衰减。默认为 0.0。
- max_grad_norm (float) — 最大梯度范数。默认为 1.0。
- seed (int) — 随机种子。默认为 42。
- train_split (str) — 训练集的名称。默认为“train”。
- valid_split (Optional[str]) — 验证集的名称。默认为 None。
- text_column (str) — 数据集中文本列的名称。默认为“text”。
- target_column (str) — 数据集中目标列的名称。默认为“target”。
- logging_steps (int) — 两次日志记录之间的步数。默认为 -1。
- project_name (str) — 项目名称。默认为“project-name”。
- auto_find_batch_size (bool) — 是否自动查找批次大小。默认为 False。
- mixed_precision (Optional[str]) — 混合精度设置(fp16、bf16 或 None)。默认为 None。
- save_total_limit (int) — 要保存的检查点总数。默认为 1。
- token (Optional[str]) — 用于身份验证的 Hub 令牌。默认为 None。
- push_to_hub (bool) — 是否将模型推送到 Hub。默认为 False。
- eval_strategy (str) — 评估策略。默认为“epoch”。
- username (Optional[str]) — Hugging Face 用户名。默认为 None。
- log (str) — 用于实验跟踪的日志记录方法。默认为“none”。
- early_stopping_patience (int) — 训练在没有改善的情况下将停止的轮数。默认为 5。
- early_stopping_threshold (float) — 用于衡量是否继续训练的新最优值的阈值。默认为 0.01。
`TextClassificationParams` 是一个用于文本分类训练参数的配置类。