AutoTrain 文档
使用 AutoTrain Advanced 微调大语言模型
并获得增强的文档体验
开始使用
使用 AutoTrain Advanced 微调大语言模型
AutoTrain Advanced 可以让您轻松地为特定用例微调大语言模型 (LLM)。本指南涵盖了您需要了解的有关大语言模型微调的所有内容。
主要功能
- 使用 CSV 和 JSONL 格式进行简单的数据准备
- 支持多种训练方法 (SFT, DPO, ORPO)
- 内置聊天模板
- 本地和云端训练选项
- 优化的训练参数
支持的训练方法
AutoTrain 支持多种专门的训练器
llm:通用 LLM 训练器llm-sft:监督微调 (Supervised Fine-Tuning) 训练器llm-reward:奖励建模 (Reward modeling) 训练器llm-dpo:直接偏好优化 (Direct Preference Optimization) 训练器llm-orpo:ORPO (Optimal Reward Policy Optimization) 训练器
数据准备
LLM 微调接受 CSV 和 JSONL 格式的数据。JSONL 是首选格式。数据的格式化方式取决于您训练 LLM 的任务。
经典文本生成
对于文本生成,数据应采用以下格式:
| text |
|---|
| wikipedia is a free online encyclopedia |
| it is a collaborative project |
| that anyone can edit |
| wikipedia is the largest and most popular general reference work on the internet |
此格式的示例数据集可以在这里找到:stas/openwebtext-10k
示例任务
- 文本生成
- 代码补全
兼容的训练器
- SFT Trainer
- Generic Trainer (通用训练器)
聊天机器人 / 问答 / 代码生成 / 函数调用
对于此任务,您可以使用 CSV 或 JSONL 数据。如果您自己格式化数据(添加开始、结束标记等),可以使用 CSV 或 JSONL 格式。如果您不想自己格式化数据,而是希望使用 --chat-template 参数为您格式化数据,则必须使用 JSONL 格式。在这两种情况下,CSV 和 JSONL 可以互换使用,但 JSONL 是最首选的格式。
要训练聊天机器人,您的数据需要有 content 和 role。一些模型还支持 system 角色。
这是一个聊天机器人数据集的示例(单个样本):
[{'content': 'Help write a letter of 100 -200 words to my future self for '
'Kyra, reflecting on her goals and aspirations.',
'role': 'user'},
{'content': 'Dear Future Self,\n'
'\n'
"I hope you're happy and proud of what you've achieved. As I "
"write this, I'm excited to think about our goals and how far "
"you've come. One goal was to be a machine learning engineer. I "
"hope you've worked hard and become skilled in this field. Keep "
'learning and innovating. Traveling was important to us. I hope '
"you've seen different places and enjoyed the beauty of our "
'world. Remember the memories and lessons. Starting a family '
'mattered to us. If you have kids, treasure every moment. Be '
'patient, loving, and grateful for your family.\n'
'\n'
'Take care of yourself. Rest, reflect, and cherish the time you '
'spend with loved ones. Remember your dreams and celebrate what '
"you've achieved. Your determination brought you here. I'm "
"excited to see the person you've become, the impact you've made, "
'and the love and joy in your life. Embrace opportunities and '
'keep dreaming big.\n'
'\n'
'With love,\n'
'Kyra',
'role': 'assistant'}]如您所见,数据有 content 和 role 列。role 列可以是 user、assistant 或 system。然而,这些数据尚未为训练进行格式化。您可以在训练期间使用 --chat-template 参数来格式化数据。
--chat-template 支持以下几种模板:
none(默认)zephyrchatmltokenizer:使用 tokenizer 配置文件中提到的聊天模板
下面还展示了一个多行样本:
[{"content": "hello", "role": "user"}, {"content": "hi nice to meet you", "role": "assistant"}]
[{"content": "how are you", "role": "user"}, {"content": "I am fine", "role": "assistant"}]
[{"content": "What is your name?", "role": "user"}, {"content": "My name is Mary", "role": "assistant"}]
[{"content": "Which is the best programming language?", "role": "user"}, {"content": "Python", "role": "assistant"}]
.
.
.此格式的示例数据集可以在这里找到:HuggingFaceH4/no_robots
如果您不想使用 --chat-template 格式化数据,可以自行格式化数据并使用以下格式:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\nToday Date: 03 Oct 2024\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nHelp write a letter of 100 -200 words to my future self for Kyra, reflecting on her goals and aspirations.<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\nDear Future Self,\n\nI hope you're happy and proud of what you've achieved. As I write this, I'm excited to think about our goals and how far you've come. One goal was to be a machine learning engineer. I hope you've worked hard and become skilled in this field. Keep learning and innovating. Traveling was important to us. I hope you've seen different places and enjoyed the beauty of our world. Remember the memories and lessons. Starting a family mattered to us. If you have kids, treasure every moment. Be patient, loving, and grateful for your family.\n\nTake care of yourself. Rest, reflect, and cherish the time you spend with loved ones. Remember your dreams and celebrate what you've achieved. Your determination brought you here. I'm excited to see the person you've become, the impact you've made, and the love and joy in your life. Embrace opportunities and keep dreaming big.\n\nWith love,\nKyra<|eot_id|>下面展示了一个多行数据集的样本:
[{"text": "<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\nToday Date: 03 Oct 2024\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nhello<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\nhi nice to meet you<|eot_id|>"}]
[{"text": "<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\nToday Date: 03 Oct 2024\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nhow are you<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\nI am fine<|eot_id|>"}]
[{"text": "<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\nToday Date: 03 Oct 2024\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nWhat is your name?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\nMy name is Mary<|eot_id|>"}]
[{"text": "<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\nToday Date: 03 Oct 2024\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nWhich is the best programming language?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\nPython<|eot_id|>"}]
.
.
.此格式的示例数据集可以在这里找到:timdettmers/openassistant-guanaco
在上面的示例中,我们只看到了两轮对话:一轮来自用户,一轮来自助手。但是,您可以在单个样本中包含来自用户和助手的多轮对话。
聊天模型可以使用以下训练器进行训练:
SFT Trainer
- 仅需要
text列 - 示例数据集:HuggingFaceH4/no_robots
- 仅需要
Generic Trainer (通用训练器)
- 仅需要
text列 - 示例数据集:HuggingFaceH4/no_robots
- 仅需要
Reward Trainer (奖励训练器)
- 需要
text和rejected_text列 - 示例数据集:trl-lib/ultrafeedback_binarized
- 需要
DPO Trainer
- 需要
prompt、text和rejected_text列 - 示例数据集:trl-lib/ultrafeedback_binarized
- 需要
ORPO Trainer
- 需要
prompt、text和rejected_text列 - 示例数据集:trl-lib/ultrafeedback_binarized
- 需要
奖励训练器和 DPO/ORPO 训练器的数据格式之间的唯一区别是,奖励训练器只需要 text 和 rejected_text 列,而 DPO/ORPO 训练器需要额外的 prompt 列。
LLM 微调的最佳实践
内存优化
- 为您的硬件使用适当的
block_size和model_max_length - 在可能的情况下启用混合精度训练
- 对大型模型使用 PEFT 技术
数据质量
- 清理并验证您的训练数据
- 确保对话样本均衡
- 使用适当的聊天模板
训练技巧
- 从较小的学习率开始
- 使用 tensorboard 监控训练指标
- 在训练过程中验证模型输出
相关资源
训练
本地训练
在本地,可以使用 autotrain --config config.yaml 命令进行训练。config.yaml 文件应包含以下参数:
task: llm-orpo
base_model: meta-llama/Meta-Llama-3-8B-Instruct
project_name: autotrain-llama3-8b-orpo
log: tensorboard
backend: local
data:
path: argilla/distilabel-capybara-dpo-7k-binarized
train_split: train
valid_split: null
chat_template: chatml
column_mapping:
text_column: chosen
rejected_text_column: rejected
prompt_text_column: prompt
params:
block_size: 1024
model_max_length: 8192
max_prompt_length: 512
epochs: 3
batch_size: 2
lr: 3e-5
peft: true
quantization: int4
target_modules: all-linear
padding: right
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 4
mixed_precision: fp16
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true在上述配置文件中,我们正在使用 ORPO 训练器训练一个模型。该模型基于 meta-llama/Meta-Llama-3-8B-Instruct 模型进行训练。数据是 argilla/distilabel-capybara-dpo-7k-binarized 数据集。chat_template 参数设置为 chatml。column_mapping 参数用于将数据集中的列映射到 ORPO 训练器所需的列。params 部分包含训练参数,如 block_size、model_max_length、epochs、batch_size、lr、peft、quantization、target_modules、padding、optimizer、scheduler、gradient_accumulation 和 mixed_precision。hub 部分包含 Hugging Face 账户的用户名和 token,并且 push_to_hub 参数设置为 true,以将训练好的模型推送到 Hugging Face Hub。
如果您在本地有训练文件,可以将数据部分更改为:
data:
path: path/to/training/file
train_split: train # name of the training file
valid_split: null
chat_template: chatml
column_mapping:
text_column: chosen
rejected_text_column: rejected
prompt_text_column: prompt以上假设您在 path/to/training/file 目录中有 train.csv 或 train.jsonl 文件,并且您将对数据应用 chatml 模板。
您可以使用以下命令运行训练:
$ autotrain --config config.yaml
更多用于微调不同类型 LLM 和不同任务的示例配置文件可以在这里找到。
在 Hugging Face Spaces 中训练
如果您在 Hugging Face Spaces 中进行训练,一切都与本地训练相同。
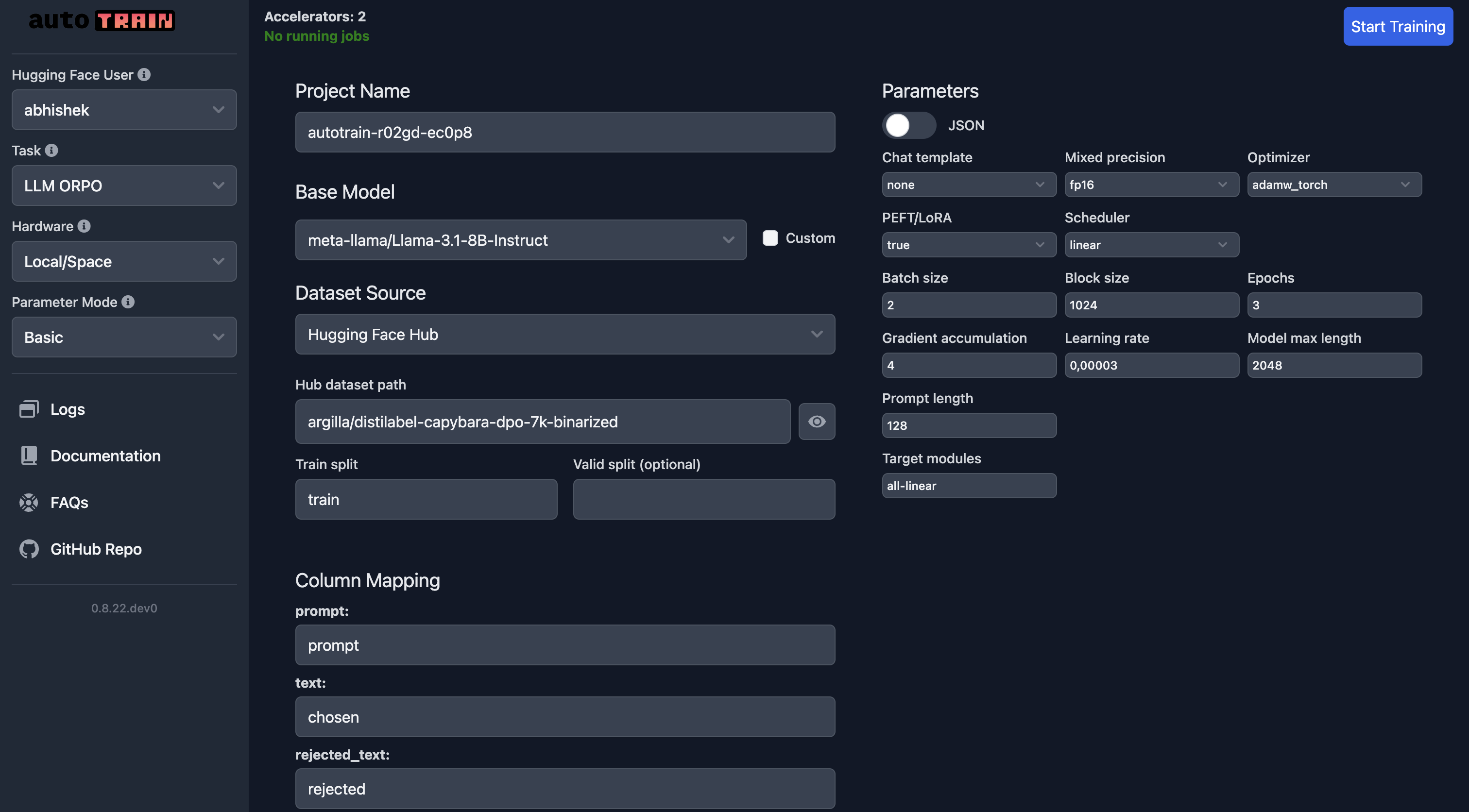
在 UI 中,您需要确保选择了正确的模型、数据集和数据分割。应特别注意 column_mapping。
一旦您对参数感到满意,可以点击 Start Training 按钮开始训练过程。
参数
LLM 微调参数
class autotrain.trainers.clm.params.LLMTrainingParams
< 源代码 >( model: str = 'gpt2' project_name: str = 'project-name' data_path: str = 'data' train_split: str = 'train' valid_split: typing.Optional[str] = None add_eos_token: bool = True block_size: typing.Union[int, typing.List[int]] = -1 model_max_length: int = 2048 padding: typing.Optional[str] = 'right' trainer: str = 'default' use_flash_attention_2: bool = False log: str = 'none' disable_gradient_checkpointing: bool = False logging_steps: int = -1 eval_strategy: str = 'epoch' save_total_limit: int = 1 auto_find_batch_size: bool = False mixed_precision: typing.Optional[str] = None lr: float = 3e-05 epochs: int = 1 batch_size: int = 2 warmup_ratio: float = 0.1 gradient_accumulation: int = 4 optimizer: str = 'adamw_torch' scheduler: str = 'linear' weight_decay: float = 0.0 max_grad_norm: float = 1.0 seed: int = 42 chat_template: typing.Optional[str] = None quantization: typing.Optional[str] = 'int4' target_modules: typing.Optional[str] = 'all-linear' merge_adapter: bool = False peft: bool = False lora_r: int = 16 lora_alpha: int = 32 lora_dropout: float = 0.05 model_ref: typing.Optional[str] = None dpo_beta: float = 0.1 max_prompt_length: int = 128 max_completion_length: typing.Optional[int] = None prompt_text_column: typing.Optional[str] = None text_column: str = 'text' rejected_text_column: typing.Optional[str] = None push_to_hub: bool = False username: typing.Optional[str] = None token: typing.Optional[str] = None unsloth: bool = False distributed_backend: typing.Optional[str] = None )
参数
- model (str) — 用于训练的模型名称。默认为 “gpt2”。
- project_name (str) — 项目名称和输出目录。默认为 “project-name”。
- data_path (str) — 数据集的路径。默认为 “data”。
- train_split (str) — 训练数据分割的配置。默认为 “train”。
- valid_split (Optional[str]) — 验证数据分割的配置。默认为 None。
- add_eos_token (bool) — 是否在序列末尾添加 EOS 标记。默认为 True。
- block_size (Union[int, List[int]]) — 用于训练的块大小,可以是一个整数或一个整数列表。默认为 -1。
- model_max_length (int) — 模型输入的最大长度。默认为 2048。
- padding (Optional[str]) — 填充序列的一侧(左侧或右侧)。默认为 “right”。
- trainer (str) — 要使用的训练器类型。默认为 “default”。
- use_flash_attention_2 (bool) — 是否使用 Flash Attention 第 2 版。默认为 False。
- log (str) — 用于实验跟踪的日志记录方法。默认为 “none”。
- disable_gradient_checkpointing (bool) — 是否禁用梯度检查点。默认为 False。
- logging_steps (int) — 日志记录事件之间的步数。默认为 -1。
- eval_strategy (str) — 评估策略(例如,‘epoch’)。默认为 “epoch”。
- save_total_limit (int) — 要保留的最大检查点数量。默认为 1。
- auto_find_batch_size (bool) — 是否自动寻找最佳批次大小。默认为 False。
- mixed_precision (Optional[str]) — 要使用的混合精度类型(例如,‘fp16’、‘bf16’ 或 None)。默认为 None。
- lr (float) — 训练的学习率。默认为 3e-5。
- epochs (int) — 训练轮数。默认为 1。
- batch_size (int) — 训练的批次大小。默认为 2。
- warmup_ratio (float) — 用于学习率预热的训练比例。默认为 0.1。
- gradient_accumulation (int) — 在更新前累积梯度的步数。默认为 4。
- optimizer (str) — 用于训练的优化器。默认为 “adamw_torch”。
- scheduler (str) — 要使用的学习率调度器。默认为 “linear”。
- weight_decay (float) — 应用于优化器的权重衰减。默认为 0.0。
- max_grad_norm (float) — 用于梯度裁剪的最大范数。默认为 1.0。
- seed (int) — 用于可复现性的随机种子。默认为 42。
- chat_template (Optional[str]) — 用于基于聊天模型的模板,选项包括:None、zephyr、chatml 或 tokenizer。默认为 None。
- quantization (Optional[str]) — 要使用的量化方法(例如 ‘int4’、‘int8’ 或 None)。默认为 “int4”。
- target_modules (Optional[str]) — 用于量化或微调的目标模块。默认为 “all-linear”。
- merge_adapter (bool) — 是否合并适配器层。默认为 False。
- peft (bool) — 是否使用参数高效微调 (PEFT)。默认为 False。
- lora_r (int) — LoRA 矩阵的秩。默认为 16。
- lora_alpha (int) — LoRA 的 Alpha 参数。默认为 32。
- lora_dropout (float) — LoRA 的丢弃率。默认为 0.05。
- model_ref (Optional[str]) — DPO 训练器的参考模型。默认为 None。
- dpo_beta (float) — DPO 训练器的 Beta 参数。默认为 0.1。
- max_prompt_length (int) — 提示的最大长度。默认为 128。
- max_completion_length (Optional[int]) — 补全的最大长度。默认为 None。
- prompt_text_column (Optional[str]) — 提示文本的列名。默认为 None。
- text_column (str) — 文本数据的列名。默认为 “text”。
- rejected_text_column (Optional[str]) — 拒绝文本数据的列名。默认为 None。
- push_to_hub (bool) — 是否将模型推送到 Hugging Face Hub。默认为 False。
- username (Optional[str]) — 用于身份验证的 Hugging Face 用户名。默认为 None。
- token (Optional[str]) — 用于身份验证的 Hugging Face 令牌。默认为 None。
- unsloth (bool) — 是否使用 unsloth 库。默认为 False。
- distributed_backend (Optional[str]) — 用于分布式训练的后端。默认为 None。
LLMTrainingParams:使用 autotrain 库训练语言模型的参数。
任务特定参数
不同训练器使用的长度参数可能不同。有些比其他的需要更多的上下文。
- block_size:这是最大序列长度或一个文本块的长度。设置为 -1 可自动确定块大小。默认为 -1。
- model_max_length:设置模型在单个批次中处理的最大长度,这会影响性能和内存使用。默认为 1024
- max_prompt_length:指定训练中使用的提示的最大长度,这对于需要初始上下文输入的任务尤为重要。仅用于
orpo和dpo训练器。 - max_completion_length:要使用的补全长度,对于 orpo:仅限编码器-解码器模型。对于 dpo,它是补全文本的长度。
注意:
- 块大小不能大于 model_max_length!
- max_prompt_length 不能大于 model_max_length!
- max_prompt_length 不能大于 block_size!
- max_completion_length 不能大于 model_max_length!
- max_completion_length 不能大于 block_size!
注意:不遵守这些限制将导致错误或 nan 损失。
通用训练器
--add_eos_token, --add-eos-token
Toggle whether to automatically add an End Of Sentence (EOS) token at the end of texts, which can be critical for certain
types of models like language models. Only used for `default` trainer
--block_size BLOCK_SIZE, --block-size BLOCK_SIZE
Specify the block size for processing sequences. This is maximum sequence length or length of one block of text. Setting to
-1 determines block size automatically. Default is -1.
--model_max_length MODEL_MAX_LENGTH, --model-max-length MODEL_MAX_LENGTH
Set the maximum length for the model to process in a single batch, which can affect both performance and memory usage.
Default is 1024SFT 训练器
--block_size BLOCK_SIZE, --block-size BLOCK_SIZE
Specify the block size for processing sequences. This is maximum sequence length or length of one block of text. Setting to
-1 determines block size automatically. Default is -1.
--model_max_length MODEL_MAX_LENGTH, --model-max-length MODEL_MAX_LENGTH
Set the maximum length for the model to process in a single batch, which can affect both performance and memory usage.
Default is 1024奖励训练器
--block_size BLOCK_SIZE, --block-size BLOCK_SIZE
Specify the block size for processing sequences. This is maximum sequence length or length of one block of text. Setting to
-1 determines block size automatically. Default is -1.
--model_max_length MODEL_MAX_LENGTH, --model-max-length MODEL_MAX_LENGTH
Set the maximum length for the model to process in a single batch, which can affect both performance and memory usage.
Default is 1024DPO 训练器
--dpo-beta DPO_BETA, --dpo-beta DPO_BETA
Beta for DPO trainer
--model-ref MODEL_REF
Reference model to use for DPO when not using PEFT
--block_size BLOCK_SIZE, --block-size BLOCK_SIZE
Specify the block size for processing sequences. This is maximum sequence length or length of one block of text. Setting to
-1 determines block size automatically. Default is -1.
--model_max_length MODEL_MAX_LENGTH, --model-max-length MODEL_MAX_LENGTH
Set the maximum length for the model to process in a single batch, which can affect both performance and memory usage.
Default is 1024
--max_prompt_length MAX_PROMPT_LENGTH, --max-prompt-length MAX_PROMPT_LENGTH
Specify the maximum length for prompts used in training, particularly relevant for tasks requiring initial contextual input.
Used only for `orpo` trainer.
--max_completion_length MAX_COMPLETION_LENGTH, --max-completion-length MAX_COMPLETION_LENGTH
Completion length to use, for orpo: encoder-decoder models onlyORPO 训练器
--block_size BLOCK_SIZE, --block-size BLOCK_SIZE
Specify the block size for processing sequences. This is maximum sequence length or length of one block of text. Setting to
-1 determines block size automatically. Default is -1.
--model_max_length MODEL_MAX_LENGTH, --model-max-length MODEL_MAX_LENGTH
Set the maximum length for the model to process in a single batch, which can affect both performance and memory usage.
Default is 1024
--max_prompt_length MAX_PROMPT_LENGTH, --max-prompt-length MAX_PROMPT_LENGTH
Specify the maximum length for prompts used in training, particularly relevant for tasks requiring initial contextual input.
Used only for `orpo` trainer.
--max_completion_length MAX_COMPLETION_LENGTH, --max-completion-length MAX_COMPLETION_LENGTH
Completion length to use, for orpo: encoder-decoder models only