google-cloud 文档
在 GKE 上从 GCS 部署 BGE Base v1.5 与 TEI DLC
并获得增强的文档体验
开始使用
在 GKE 上从 GCS 部署 BGE Base v1.5 与 TEI DLC
BGE,即 BAAI General Embedding,是 BAAI 发布的一组嵌入模型,它是一个用于通用嵌入任务的英文基础模型,在 MTEB 排行榜中名列前茅。Text Embeddings Inference (TEI) 是 Hugging Face 开发的一个工具包,用于部署和提供开源文本嵌入和序列分类模型;它能为最流行的模型提供高性能提取,包括 FlagEmbedding、Ember、GTE 和 E5。而 Google Kubernetes Engine (GKE) 是 Google Cloud 中一项完全托管的 Kubernetes 服务,可用于在 GCP 的基础设施上大规模部署和运行容器化应用程序。
本示例展示了如何在一个 GKE 集群上部署一个来自 Google Cloud Storage (GCS) 存储桶的文本嵌入模型,该集群运行一个专门用于在安全受管环境中部署文本嵌入模型的容器,并使用 Hugging Face 的 TEI DLC。
设置 / 配置
首先,您需要在本地机器上安装 gcloud 和 kubectl,它们分别是 Google Cloud 和 Kubernetes 的命令行工具,用于与 GCP 和 GKE 集群交互。
- 要安装
gcloud,请按照 Cloud SDK 文档 - 安装 gcloud CLI 中的说明进行操作。 - 要安装
kubectl,请按照 Kubernetes 文档 - 安装工具 中的说明进行操作。
或者,为了简化本教程中命令的使用,您需要为 GCP 设置以下环境变量
export PROJECT_ID=your-project-id
export LOCATION=your-location
export CLUSTER_NAME=your-cluster-name
export BUCKET_NAME=hf-models-gke-bucket然后您需要登录到您的 GCP 账户,并将项目 ID 设置为您要用于部署 GKE 集群的项目。
gcloud auth login
gcloud auth application-default login # For local development
gcloud config set project $PROJECT_ID登录后,您需要启用 GCP 中必要的服务 API,例如 Google Kubernetes Engine API、Google Container Registry API 和 Google Container File System API,这些都是部署 GKE 集群和 Hugging Face TEI DLC 所必需的。
gcloud services enable container.googleapis.com
gcloud services enable containerregistry.googleapis.com
gcloud services enable containerfilesystem.googleapis.com此外,要将 kubectl 与 GKE 集群凭据一起使用,您还需要安装 gke-gcloud-auth-plugin,可以如下使用 gcloud 进行安装
gcloud components install gke-gcloud-auth-plugin
安装 gke-gcloud-auth-plugin 不需要通过 gcloud 专门安装,要了解更多替代安装方法,请访问 https://cloud.google.com/kubernetes-engine/docs/how-to/cluster-access-for-kubectl#install_plugin。
创建 GKE 集群
一切设置完成后,您可以继续创建 GKE 集群和节点池,在此示例中,它将是一个单 CPU 节点,因为对于大多数工作负载,CPU 推理足以服务大多数文本嵌入模型,尽管它从 GPU 服务中受益匪浅。
CPU 用于在文本嵌入模型之上运行推理,以展示 TEI 的当前功能,但切换到 GPU 就像将 spec.containers[0].image 替换为 us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-text-embeddings-inference-cu122.1-4.ubuntu2204,然后更新请求的资源以及 deployment.yaml 文件中的 nodeSelector 要求一样简单。有关更多信息,请参阅 gpu-config 目录,其中包含用于 TEI 中 GPU 服务(使用 NVIDIA Tesla T4 GPU,计算能力为 7.5,即 TEI 原生支持)的预定义配置。
部署 GKE 集群时,将使用“Autopilot”模式,因为它是大多数工作负载的推荐模式,因为底层基础设施由 Google 管理。或者,您也可以使用“Standard”模式。
在创建 GKE Autopilot 集群之前,务必查看 GKE 文档 - 通过选择机器系列优化 Autopilot Pod 性能,因为并非所有集群版本都支持所有 CPU。GPU 支持也同样适用,例如,GKE 集群版本 1.28.3 或更低版本不支持 nvidia-l4。
gcloud container clusters create-auto $CLUSTER_NAME \
--project=$PROJECT_ID \
--location=$LOCATION \
--release-channel=stable \
--cluster-version=1.28 \
--no-autoprovisioning-enable-insecure-kubelet-readonly-port要选择您所在位置的特定 GKE 集群版本,您可以运行以下命令
gcloud container get-server-config \
--flatten="channels" \
--filter="channels.channel=STABLE" \
--format="yaml(channels.channel,channels.defaultVersion)" \
--location=$LOCATION欲了解更多信息,请访问 https://cloud.google.com/kubernetes-engine/versioning#specifying_cluster_version。
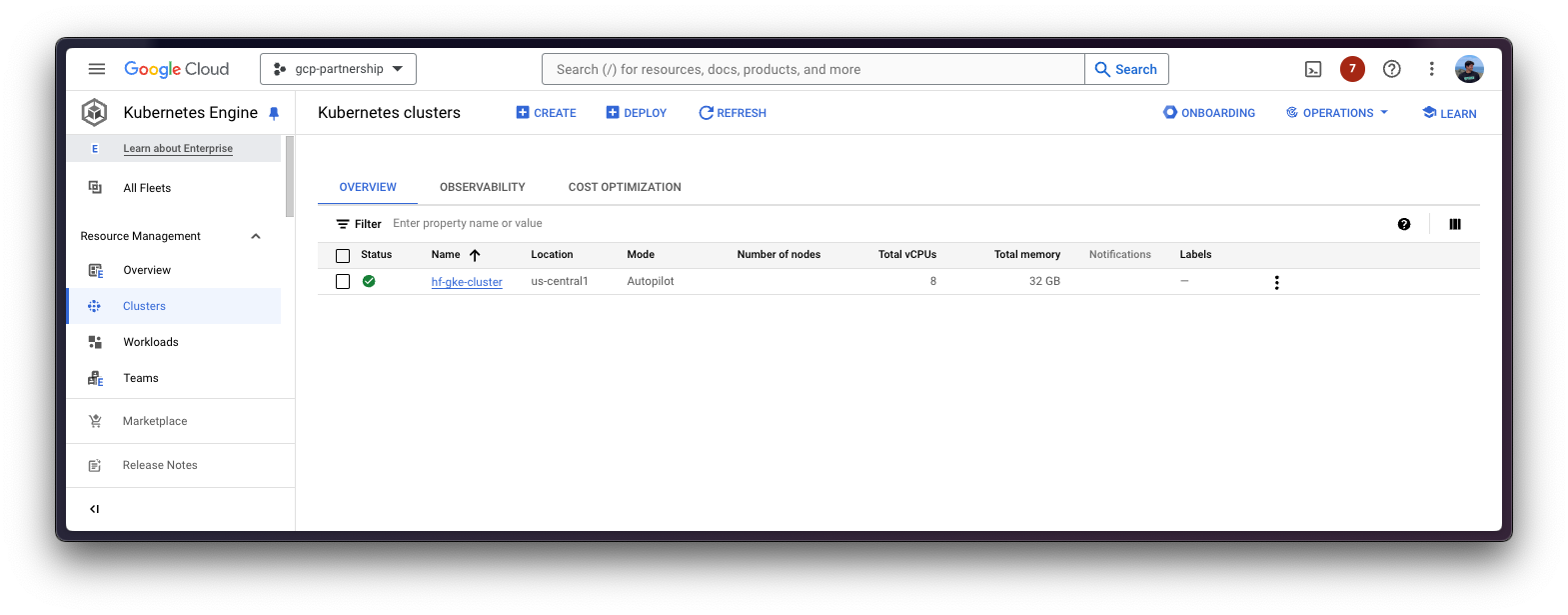
GKE 集群创建完成后,您可以使用以下命令通过 kubectl 获取访问它的凭据
gcloud container clusters get-credentials $CLUSTER_NAME --location=$LOCATION可选:将模型从 Hugging Face Hub 上传到 GCS
这是本教程中的可选步骤,因为您可能希望重复使用 GCS 存储桶中已有的模型,如果是这种情况,请随意跳到本教程的下一步,了解如何配置 GCS 的 IAM,以便您可以从 GKE 集群中的 Pod 访问存储桶。
否则,要将模型从 Hugging Face Hub 上传到 GCS 存储桶,可以使用脚本 scripts/upload_model_to_gcs.sh,它将从 Hugging Face Hub 下载模型并将其上传到 GCS 存储桶(如果尚未创建,则创建存储桶)。
gsutil 组件应通过 gcloud 安装,并且还应安装带有额外 hf_transfer 的 Python 包 huggingface_hub 和包 crcmod。
gcloud components install gsutil
pip install --upgrade --quiet "huggingface_hub[hf_transfer]" crcmod然后,您可以运行脚本从 Hugging Face Hub 下载模型,然后将其上传到 GCS 存储桶
确保设置适当的权限以运行脚本,即 chmod +x ./scripts/upload_model_to_gcs.sh。
./scripts/upload_model_to_gcs.sh --model-id BAAI/bge-base-en-v1.5 --gcs gs://$BUCKET_NAME/bge-base-en-v1.5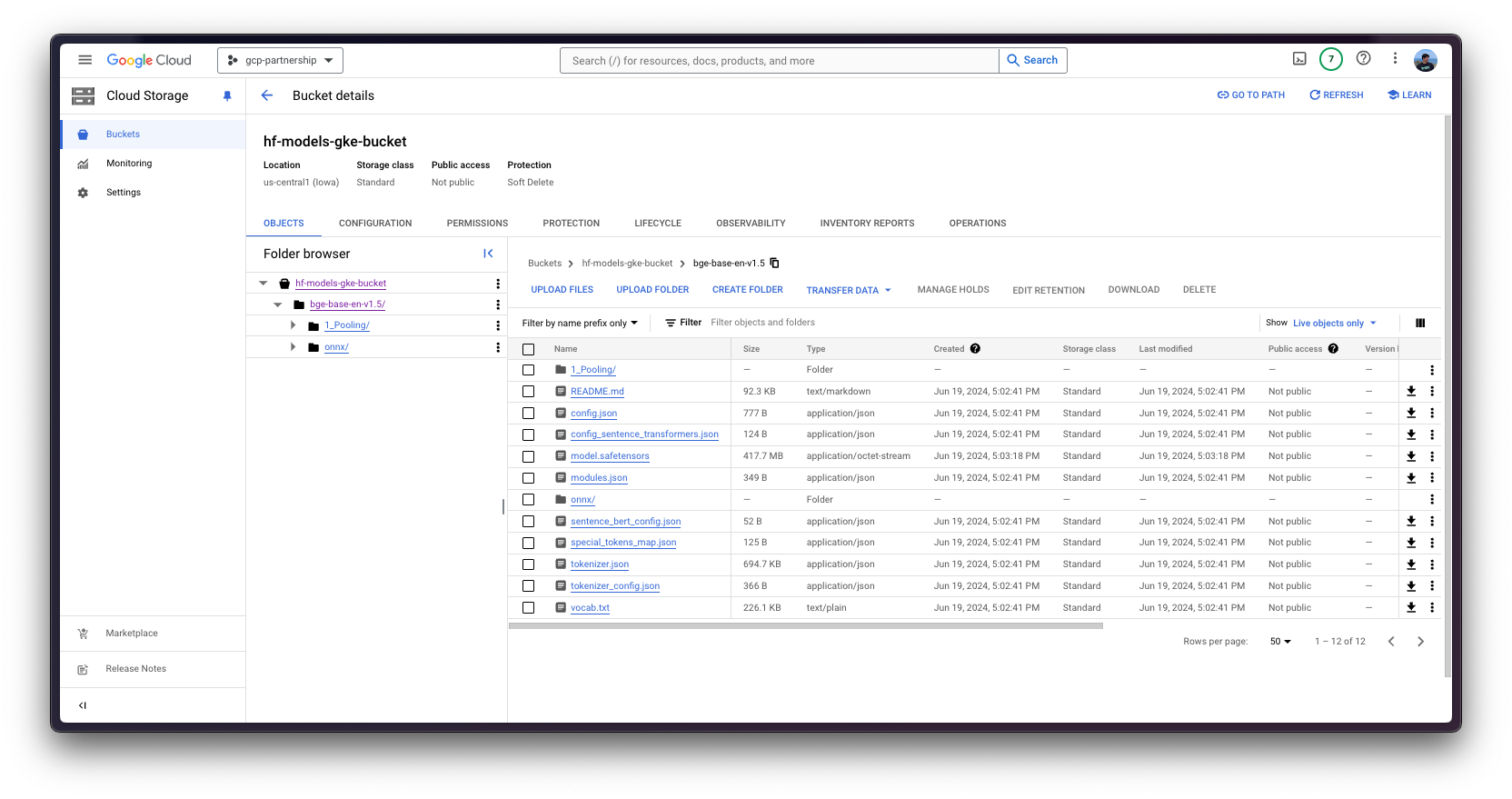
为 GCS 配置 IAM
在继续将 Hugging Face TEI DLC 部署到 GKE 集群之前,您需要为 GCS 存储桶设置 IAM 权限,以便 GKE 集群中的 pod 可以访问该存储桶。为此,您需要在 GKE 集群中创建一个命名空间和一个服务帐户,然后为包含模型的 GCS 存储桶设置 IAM 权限,无论该模型是从 Hugging Face Hub 上传的还是已经存在于 GCS 存储桶中。
为方便起见,由于命名空间和服务账户的引用将在以下步骤中使用,因此将设置环境变量 NAMESPACE 和 SERVICE_ACCOUNT。
export NAMESPACE=hf-gke-namespace
export SERVICE_ACCOUNT=hf-gke-service-account然后您可以在 GKE 集群中创建命名空间和服务账户,从而在使用该服务账户时,允许该命名空间中的 Pod 访问 GCS 存储桶的 IAM 权限。
kubectl create namespace $NAMESPACE
kubectl create serviceaccount $SERVICE_ACCOUNT --namespace $NAMESPACE然后您需要按如下方式将 IAM 策略绑定添加到存储桶
gcloud storage buckets add-iam-policy-binding \
gs://$BUCKET_NAME \
--member "principal://iam.googleapis.com/projects/$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")/locations/global/workloadIdentityPools/$PROJECT_ID.svc.id.goog/subject/ns/$NAMESPACE/sa/$SERVICE_ACCOUNT" \
--role "roles/storage.objectUser"部署 TEI
现在您可以继续进行 Hugging Face TEI DLC 的 Kubernetes 部署,从挂载在 /data 的卷中提供 BAAI/bge-base-en-v1.5 模型,该卷是从模型所在的 GCS 存储桶复制的。
最近,Hugging Face Hub 团队已在 Hub 中包含了 text-embeddings-inference 标签,因此您可以随意浏览 Hub 中所有可以通过 TEI 服务嵌入的模型,网址为 https://huggingface.co/models?other=text-embeddings-inference。
Hugging Face TEI DLC 将通过 kubectl 部署,配置文件位于 cpu-config/ 或 gpu-config/ 目录中,具体取决于您是想使用 CPU 还是 GPU 加速器。
deployment.yaml:包含 Pod 的部署详细信息,包括对 Hugging Face TEI DLC 的引用,将MODEL_ID设置为卷挂载中的模型路径,在本例中为/data/bge-base-en-v1.5。service.yaml:包含 Pod 的服务详细信息,暴露 TEI 服务的 8080 端口。storageclass.yaml:包含 Pod 的存储类详细信息,定义卷挂载的存储类。- (可选)
ingress.yaml:包含 Pod 的入口详细信息,将服务暴露给外部世界,以便可以通过入口 IP 访问。
git clone https://github.com/huggingface/Google-Cloud-Containers
kubectl apply -f Google-Cloud-Containers/examples/gke/tei-from-gcs-deployment/cpu-config如前所述,对于本示例,您将把容器部署到 CPU 节点,但部署 TEI 到 GPU 节点的配置也已在 gpu-config 目录中提供,因此如果您想将 TEI 部署到 GPU 节点,请运行 kubectl apply -f Google-Cloud-Containers/examples/gke/tei-from-gcs-deployment/gpu-config 而不是 kubectl apply -f Google-Cloud-Containers/examples/gke/tei-from-gcs-deployment/cpu-config。
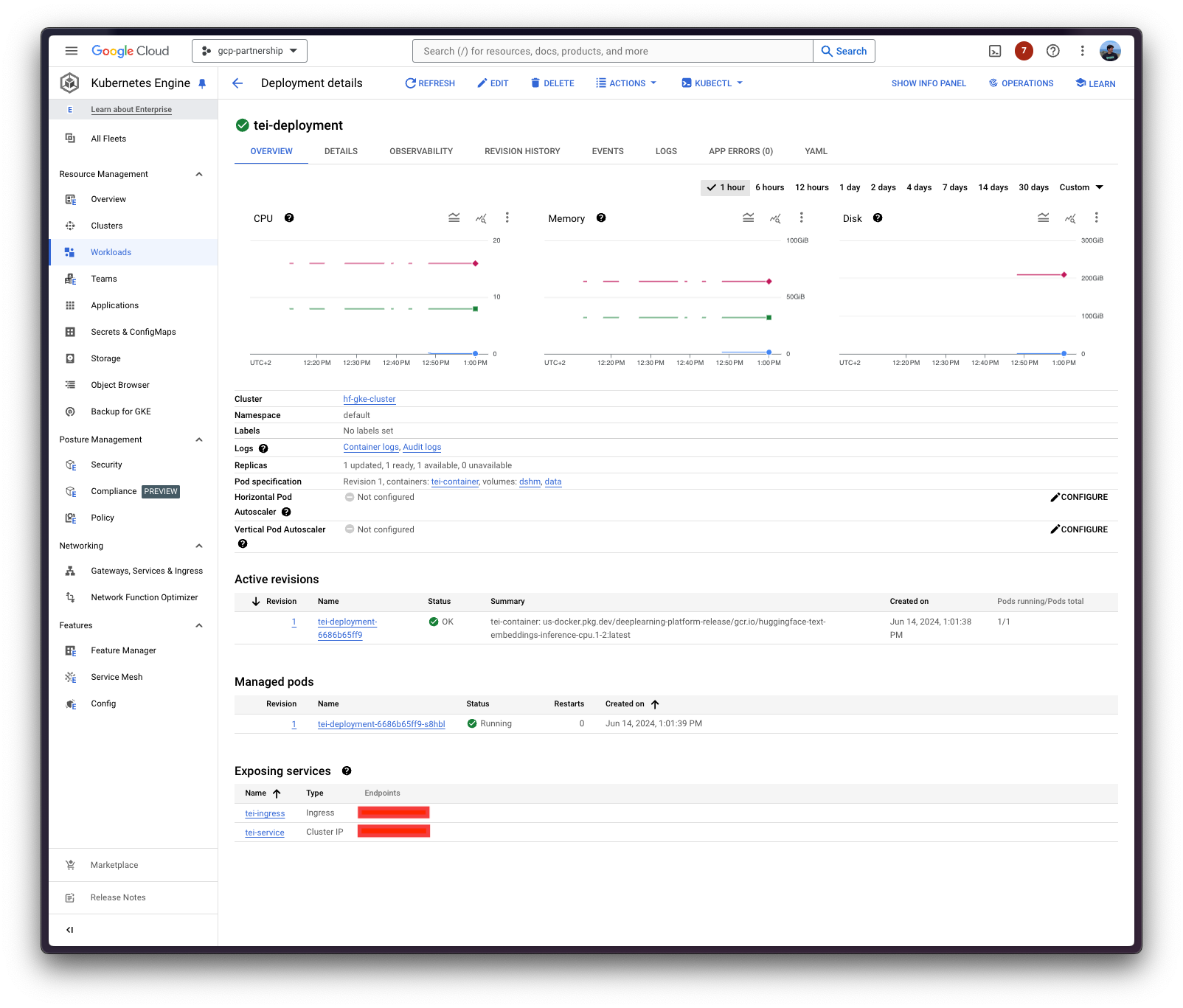
Kubernetes 部署可能需要几分钟才能准备就绪,您可以使用以下命令检查部署状态:
kubectl get pods --namespace $NAMESPACE或者,您也可以使用以下命令等待部署准备就绪:
kubectl wait --for=condition=Available --timeout=700s --namespace $NAMESPACE deployment/tei-deployment使用 TEI 进行推理
要在已部署的 TEI 服务上运行推理,您可以选择:
将已部署的 TEI 服务端口转发到 8080 端口,以便通过
localhost访问,命令如下:kubectl port-forward --namespace $NAMESPACE service/tei-service 8080:8080通过 ingress 的外部 IP 访问 TEI 服务,这是此处的默认场景,因为您已在
cpu-configs/ingress.yaml或gpu-config/ingress.yaml文件中定义了 ingress 配置(但可以跳过而使用端口转发),可以通过以下命令检索:kubectl get ingress --namespace $NAMESPACE tei-ingress -o jsonpath='{.status.loadBalancer.ingress[0].ip}'
TEI 根据模型提供的任务公开不同的推理端点
- 文本嵌入:文本嵌入模型暴露
/embed端点,期望负载中包含键inputs,其值为字符串或字符串列表,用于进行嵌入。 - 重排序:重排序模型暴露
/rerank端点,期望负载中包含query和texts键,其中query是用于对texts中的每个文本进行相似性排序的参考。 - 序列分类:经典序列分类模型暴露
/predict端点,期望负载中包含键inputs,其值为字符串或字符串列表,用于进行分类。更多信息请访问 https://huggingface.co/docs/text-embeddings-inference/quick_tour。
通过 cURL
要使用 cURL 向 TEI 服务发送 POST 请求,您可以运行以下命令:
curl https://:8080/embed \
-X POST \
-d '{"inputs":"What is Deep Learning?"}' \
-H 'Content-Type: application/json'或者向 ingress IP 发送 POST 请求:
curl http://$(kubectl get ingress --namespace=$NAMESPACE tei-ingress -o jsonpath='{.status.loadBalancer.ingress[0].ip}')/embed \
-X POST \
-d '{"inputs":"What is Deep Learning?"}' \
-H 'Content-Type: application/json'这将产生以下输出(为简洁起见已截断,但原始张量长度为 768,这是您正在服务的模型 BAAI/bge-base-en-v1.5 的嵌入维度)
[[-0.01483098,0.010846359,-0.024679236,0.012507628,0.034231555,...]]删除 GKE 集群
最后,当您使用完 GKE 集群上的 TEI 后,您可以安全地删除 GKE 集群,以避免产生不必要的成本。
gcloud container clusters delete $CLUSTER_NAME --location=$LOCATION或者,如果您想保留集群,也可以将已部署的 Pod 的副本数缩减到 0,因为默认情况下部署的 GKE 集群在 GKE Autopilot 模式下只运行一个 e2-small 实例。
kubectl scale --replicas=0 --namespace=$NAMESPACE deployment/tei-deployment📍 在 GitHub 上找到完整示例 此处!