google-cloud 文档
在 GKE 上使用 TGI DLC 部署 Llama 3.1 405B
并获得增强的文档体验
开始使用
在 GKE 上使用 TGI DLC 部署 Llama 3.1 405B
Llama 3.1 是 Meta 发布的 Llama 系列最新大型语言模型之一(截至 2024 年 10 月,最新版本为 Llama 3.2);有三种大小:8B 用于在消费级 GPU 上高效部署和开发,70B 用于大规模 AI 原生应用程序,405B 用于合成数据、LLM 作为裁判或蒸馏;以及其他用例;其中 405B 版本是最大的开源 LLM 之一。Text Generation Inference (TGI) 是 Hugging Face 开发的一套用于部署和提供 LLM 的工具包,具有高性能文本生成能力。Google Kubernetes Engine (GKE) 是 Google Cloud 中一项完全托管的 Kubernetes 服务,可用于使用 Google 基础设施大规模部署和运行容器化应用程序。
本示例展示了如何在 Google Cloud 上使用 Hugging Face 专为 Text Generation Inference (TGI) 构建的深度学习容器 (DLC),将 meta-llama/Llama-3.1-405B-Instruct-FP8 部署到 GKE 集群中搭载 8 块 NVIDIA H100 GPU 的节点上。
设置/配置
首先,您需要在本地机器上安装 gcloud 和 kubectl,它们分别是 Google Cloud 和 Kubernetes 的命令行工具,用于与 GCP 和 GKE 集群交互。
- 要安装
gcloud,请按照 Cloud SDK 文档 - 安装 gcloud CLI 中的说明进行操作。 - 要安装
kubectl,请按照 Kubernetes 文档 - 安装工具 中的说明进行操作。
或者,为了简化本教程中命令的使用,您需要为 GCP 设置以下环境变量
export PROJECT_ID=your-project-id
export LOCATION=your-location
export CLUSTER_NAME=your-cluster-name然后您需要登录到您的 GCP 账户,并将项目 ID 设置为您要用于部署 GKE 集群的项目。
gcloud auth login
gcloud auth application-default login # For local development
gcloud config set project $PROJECT_ID登录后,您需要在 GCP 中启用必要的服务 API,例如 Google Kubernetes Engine API、Google Container Registry API 和 Google Container File System API,这些都是部署 GKE 集群和 Hugging Face DLC for TGI 所必需的。
gcloud services enable container.googleapis.com
gcloud services enable containerregistry.googleapis.com
gcloud services enable containerfilesystem.googleapis.com此外,要将 kubectl 与 GKE 集群凭据一起使用,您还需要安装 gke-gcloud-auth-plugin,可以如下使用 gcloud 进行安装
gcloud components install gke-gcloud-auth-plugin
gke-gcloud-auth-plugin 不需要专门通过 gcloud 安装,要了解更多替代安装方法,请访问 GKE 文档 - 安装 kubectl 并配置集群访问。
最后,请注意,您很可能需要申请配额增加才能访问搭载 8 块 NVIDIA H100 GPU 的 A3 实例,因为这些实例需要 Google Cloud 的特定手动批准。为此,您需要访问 IAM 管理 - 配额 并应用以下过滤器
服务:Compute Engine API:因为 GKE 依赖 Compute Engine 进行资源分配。维度(例如位置):region: $LOCATION:将$LOCATION值替换为上面指定的位置,但请注意,并非所有区域都可能提供 NVIDIA H100 GPU,因此请查看 Compute Engine 文档 - 可用区域和区域。gpu_family: NVIDIA_H100:是 Google Cloud 上 NVIDIA H100 GPU 的标识符。
然后请求将 NVIDIA H100 GPU 的配额增加到 8 个,以运行 meta-llama/Llama-3.1-405B-Instruct-FP8。
创建 GKE 集群
一切准备就绪后,您可以继续创建 GKE 集群和节点池,在这种情况下,它将是单个 GPU 节点,以便使用 GPU 加速器进行高性能推理,同时遵循 TGI 基于其内部 GPU 优化建议。
部署 GKE 集群时,将使用“Autopilot”模式,因为它是大多数工作负载的推荐模式,因为底层基础设施由 Google 管理。或者,您也可以使用“Standard”模式。
在创建 GKE Autopilot 集群之前,务必查看 GKE 文档 - 通过选择机器系列优化 Autopilot Pod 性能,因为并非所有版本都支持 GPU 加速器,例如 GKE 集群版本 1.28.3 或更低版本不支持 nvidia-l4。
gcloud container clusters create-auto $CLUSTER_NAME \
--project=$PROJECT_ID \
--location=$LOCATION \
--release-channel=stable \
--cluster-version=1.29 \
--no-autoprovisioning-enable-insecure-kubelet-readonly-port要选择您所在位置的特定 GKE 集群版本,您可以运行以下命令
gcloud container get-server-config \
--flatten="channels" \
--filter="channels.channel=STABLE" \
--format="yaml(channels.channel,channels.defaultVersion)" \
--location=$LOCATION欲了解更多信息,请访问 GKE 文档 - 指定集群版本。
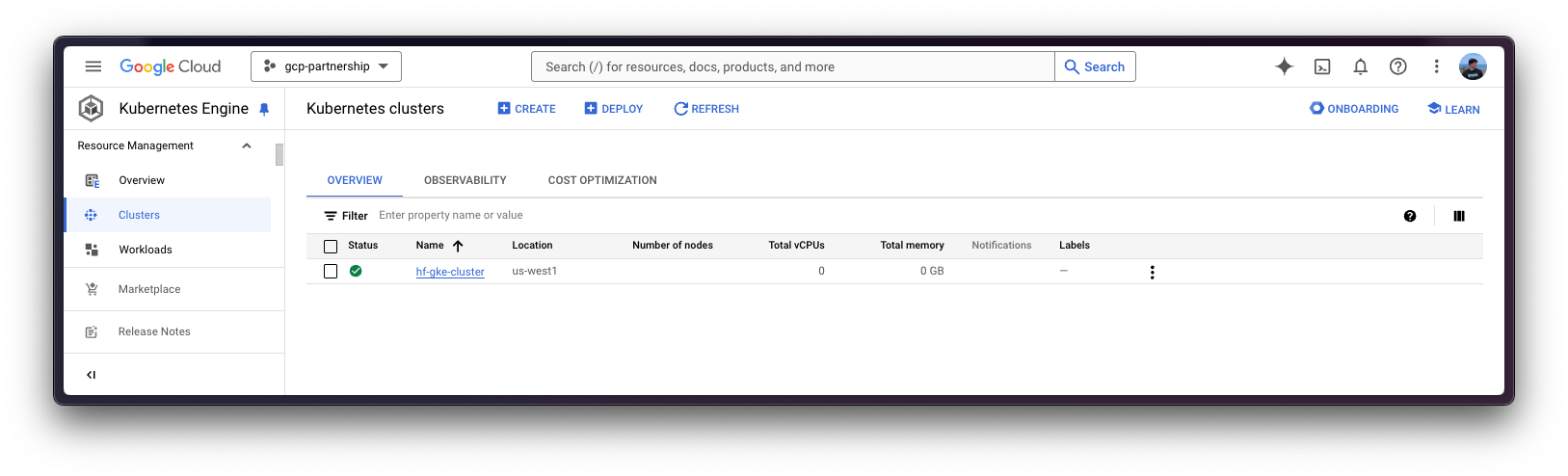
GKE 集群创建完成后,您可以使用以下命令通过 kubectl 获取访问它的凭据
gcloud container clusters get-credentials $CLUSTER_NAME --location=$LOCATION获取 Hugging Face token 并在 GKE 中设置密钥
由于 meta-llama/Llama-3.1-405B-Instruct-FP8 是一个受限模型,您需要通过 kubectl 设置一个包含 Hugging Face Hub token 的 Kubernetes 密钥。
要为 Hugging Face Hub 生成自定义令牌,您可以按照 Hugging Face Hub - 用户访问令牌 中的说明进行操作;建议的设置方式是安装 huggingface_hub Python SDK,如下所示
pip install --upgrade --quiet huggingface_hub
然后使用生成的具有对受限/私有模型读取权限的令牌登录
huggingface-cli login
最后,您可以使用 huggingface_hub Python SDK 检索令牌,如下所示创建包含 Hugging Face Hub 生成令牌的 Kubernetes secret
kubectl create secret generic hf-secret \
--from-literal=hf_token=$(python -c "from huggingface_hub import get_token; print(get_token())") \
--dry-run=client -o yaml | kubectl apply -f -或者,您可以直接按如下方式设置令牌
kubectl create secret generic hf-secret \
--from-literal=hf_token=hf_*** \
--dry-run=client -o yaml | kubectl apply -f -
有关如何在 GKE 集群中设置 Kubernetes 密钥的更多信息,请参阅 Secret Manager 文档 - 将 Secret Manager 插件与 Google Kubernetes Engine 结合使用。
部署 TGI
现在,您可以继续 Kubernetes 部署 Hugging Face TGI DLC,从 Hugging Face Hub 提供 meta-llama/Llama-3.1-405B-Instruct-FP8 模型。
要探索可以通过 TGI 提供的所有模型,您可以查看Hugging Face Hub 中标记为 text-generation-inference 的模型。
Hugging Face TGI DLC 将通过 kubectl 部署,配置文件位于 config/ 目录中
deployment.yaml:包含 Pod 的部署详情,包括对 Hugging Face TGI DLC 的引用,将MODEL_ID设置为meta-llama/Llama-3.1-405B-Instruct-FP8。service.yaml:包含 Pod 的服务详情,暴露 TGI 服务的 8080 端口。- (可选)
ingress.yaml:包含 Pod 的入口详情,将服务暴露给外部世界,以便可以通过入口 IP 访问。
git clone https://github.com/huggingface/Google-Cloud-Containers
kubectl apply -f Google-Cloud-Containers/examples/gke/tgi-llama-405b-deployment/configKubernetes 部署可能需要几分钟才能准备就绪,您可以使用以下命令检查部署状态:
kubectl get pods
或者,您也可以使用以下命令等待部署准备就绪:
kubectl wait --for=condition=Available --timeout=700s deployment/tgi-deployment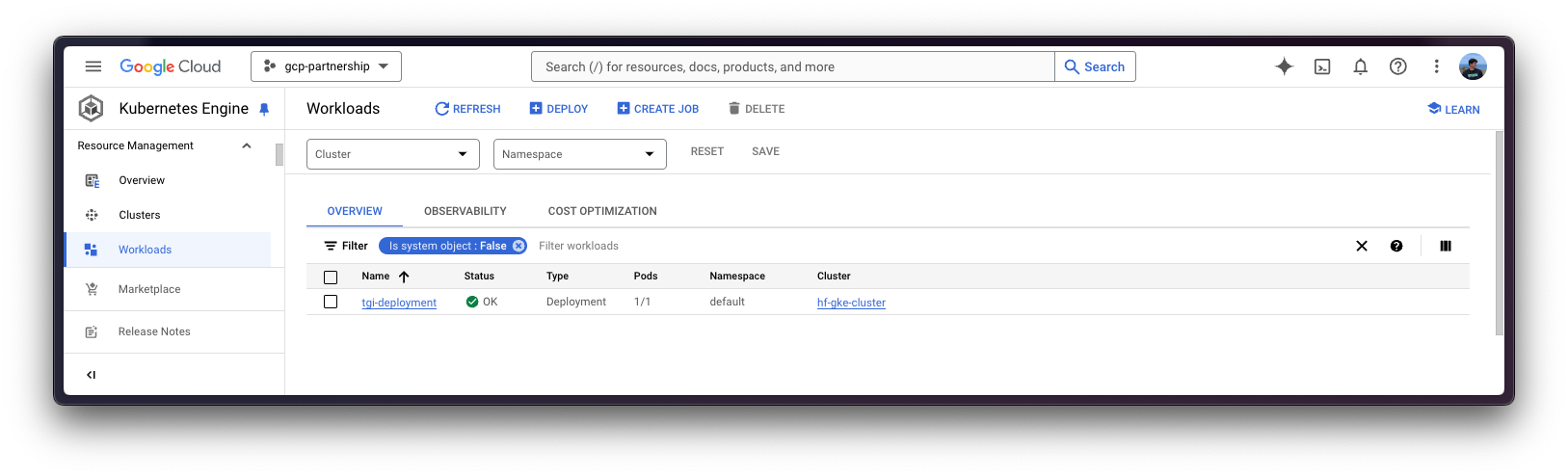
使用 TGI 进行推理
要对已部署的 TGI 服务运行推理,您可以选择以下方式:
将已部署的 TGI 服务端口转发到 8080 端口,以便通过
localhost访问,命令如下:kubectl port-forward service/tgi-service 8080:8080
通过入口的外部 IP 访问 TGI 服务,这是这里的默认场景,因为您已在
config/ingress.yaml文件中定义了入口配置(但可以跳过它以使用端口转发),可以通过以下命令检索kubectl get ingress tgi-ingress -o jsonpath='{.status.loadBalancer.ingress[0].ip}'
通过 cURL
要使用 `cURL` 向 TGI 服务发送 POST 请求,您可以运行以下命令:
curl https://:8080/v1/chat/completions \
-X POST \
-d '{"messages":[{"role":"system","content": "You are a helpful assistant."},{"role":"user","content":"What'\''s Deep Learning?"}],"temperature":0.7,"top_p":0.95,"max_tokens":128}}' \
-H 'Content-Type: application/json'或者向入口 IP 发送 POST 请求(无需指定端口)
curl http://$(kubectl get ingress tgi-ingress -o jsonpath='{.status.loadBalancer.ingress[0].ip}')/v1/chat/completions \
-X POST \
-d '{"messages":[{"role":"system","content":"You are a helpful assistant."},{"role":"user","content":"What'\''s Deep Learning?"}],"temperature":0.7,"top_p":0.95,"max_tokens":128}}' \
-H 'Content-Type: application/json'生成以下输出
{"object":"chat.completion","id":"","created":1727782287,"model":"meta-llama/Llama-3.1-405B-Instruct-FP8","system_fingerprint":"2.2.0-native","choices":[{"index":0,"message":{"role":"assistant","content":"Deep learning is a subset of machine learning, which is a field of artificial intelligence (AI) that enables computers to learn from data without being explicitly programmed. It's a type of neural network that's inspired by the structure and function of the human brain.\n\nIn traditional machine learning, computers are trained on data using algorithms that are designed to recognize patterns and make predictions. However, these algorithms are often limited in their ability to handle complex data, such as images, speech, and text.\n\nDeep learning, on the other hand, uses multiple layers of artificial neural networks to analyze data. Each layer processes the data in a different way, allowing the"},"logprobs":null,"finish_reason":"length"}],"usage":{"prompt_tokens":46,"completion_tokens":128,"total_tokens":174}}通过 Python
要使用 Python 运行推理,您可以使用 huggingface_hub Python SDK(推荐)或 openai Python SDK。
在下面的示例中将使用 localhost,但如果使用 ingress 部署了 TGI,请随意使用上述 ingress IP(无需指定端口)。
huggingface_hub
您可以通过 pip install --upgrade --quiet huggingface_hub 安装它,然后运行以下代码片段来模仿上面的 cURL 命令,即向 Messages API 发送请求
from huggingface_hub import InferenceClient
client = InferenceClient(base_url="https://:8080", api_key="-")
chat_completion = client.chat.completions.create(
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What's Deep Learning?"},
],
max_tokens=128,
)生成以下输出
ChatCompletionOutput(choices=[ChatCompletionOutputComplete(finish_reason='length', index=0, message=ChatCompletionOutputMessage(role='assistant', content='Deep learning is a subset of machine learning that focuses on neural networks with many layers, typically more than two. These neural networks are designed to mimic the structure and function of the human brain, with each layer processing and transforming inputs in a hierarchical manner.\n\nIn traditional machine learning, models are trained using a set of predefined features, such as edges, textures, or shapes. In contrast, deep learning models learn to extract features from raw data automatically, without the need for manual feature engineering.\n\nDeep learning models are trained using large amounts of data and computational power, which enables them to learn complex patterns and relationships in the data. These models can be', tool_calls=None), logprobs=None)], created=1727782322, id='', model='meta-llama/Llama-3.1-405B-Instruct-FP8', system_fingerprint='2.2.0-native', usage=ChatCompletionOutputUsage(completion_tokens=128, prompt_tokens=46, total_tokens=174))或者,您也可以自行格式化提示,并通过文本生成 API 发送
from huggingface_hub import InferenceClient, get_token
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.1-405B-Instruct-FP8", token=get_token())
client = InferenceClient("https://:8080", api_key="-")
generation = client.text_generation(
prompt=tokenizer.apply_chat_template(
[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What's Deep Learning?"},
],
tokenize=False,
add_generation_prompt=True,
),
max_new_tokens=128,
)生成以下输出
'Deep learning is a subset of machine learning that involves the use of artificial neural networks to analyze and interpret data. Inspired by the structure and function of the human brain, deep learning algorithms are designed to learn and improve on their own by automatically adjusting the connections between nodes or "neurons" in the network.\n\nIn traditional machine learning, algorithms are trained on a set of data and then use that training to make predictions or decisions on new, unseen data. However, these algorithms often rely on hand-engineered features and rules to extract relevant information from the data. In contrast, deep learning algorithms can automatically learn to extract relevant features and patterns from the'openai
此外,您还可以通过 openai 使用 Messages API;您可以通过 pip 安装它,命令为 pip install --upgrade openai,然后运行:
from openai import OpenAI
client = OpenAI(
base_url="https://:8080/v1/",
api_key="-",
)
chat_completion = client.chat.completions.create(
model="tgi",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What's Deep Learning?"},
],
max_tokens=128,
)生成以下输出
ChatCompletion(id='', choices=[Choice(finish_reason='length', index=0, logprobs=None, message=ChatCompletionMessage(content='Deep learning is a subset of machine learning that involves the use of artificial neural networks to analyze and interpret data. Inspired by the structure and function of the human brain, deep learning algorithms are designed to learn and improve on their own by automatically adjusting the connections between nodes or "neurons" in the network.\n\nIn traditional machine learning, algorithms are trained using a set of predefined rules and features. In contrast, deep learning algorithms learn to identify patterns and features from the data itself, eliminating the need for manual feature engineering. This allows deep learning models to be highly accurate and efficient, especially when dealing with large and complex datasets.\n\nKey characteristics of deep', refusal=None, role='assistant', function_call=None, tool_calls=None))], created=1727782478, model='meta-llama/Llama-3.1-405B-Instruct-FP8', object='chat.completion', service_tier=None, system_fingerprint='2.2.0-native', usage=CompletionUsage(completion_tokens=128, prompt_tokens=46, total_tokens=174))删除 GKE 集群
最后,一旦您完成在 GKE 集群上使用 TGI,您可以安全地删除 GKE 集群以避免产生不必要的费用。
gcloud container clusters delete $CLUSTER_NAME --location=$LOCATION或者,如果您想保留集群,也可以将已部署的 Pod 的副本数缩减到 0,因为默认情况下部署的 GKE 集群在 GKE Autopilot 模式下只运行一个 e2-small 实例。
kubectl scale --replicas=0 deployment/tgi-deployment
📍 完整示例请在 GitHub 此处 查找!