google-cloud 文档
在 GKE 上从 GCS 部署带有 TGI DLC 的 Qwen2 7B
并获得增强的文档体验
开始使用
在 GKE 上从 GCS 部署带有 TGI DLC 的 Qwen2 7B
Qwen2 是阿里巴巴云构建的全新 Qwen 大语言模型 (LLM) 系列,包括从 0.5 到 720 亿参数的基础模型和指令微调语言模型,其中包含一个混合专家模型;7B 变体在 Hugging Face 的 Open LLM 排行榜中位居 7B 尺寸范围第二,而 72B 变体在所有尺寸中位居第一。文本生成推理 (TGI) 是 Hugging Face 开发的用于部署和提供 LLM 的工具包,具有高性能文本生成功能。Google Kubernetes Engine (GKE) 是 Google Cloud 中完全托管的 Kubernetes 服务,可用于使用 GCP 的基础设施大规模部署和操作容器化应用程序。
本示例展示了如何在 GKE 集群上从 Google Cloud Storage (GCS) 存储桶部署 LLM,该集群运行一个专用容器,用于通过 Hugging Face 的 TGI DLC 在安全托管的环境中部署 LLM。
设置/配置
首先,您需要在本地机器上安装 gcloud 和 kubectl,它们分别是 Google Cloud 和 Kubernetes 的命令行工具,用于与 GCP 和 GKE 集群交互。
- 要安装
gcloud,请按照 Cloud SDK 文档 - 安装 gcloud CLI 中的说明进行操作。 - 要安装
kubectl,请按照 Kubernetes 文档 - 安装工具 中的说明进行操作。
或者,为了简化本教程中命令的使用,您需要为 GCP 设置以下环境变量
export PROJECT_ID=your-project-id
export LOCATION=your-location
export CLUSTER_NAME=your-cluster-name
export BUCKET_NAME=your-bucket-name然后您需要登录到您的 GCP 账户,并将项目 ID 设置为您要用于部署 GKE 集群的项目。
gcloud auth login
gcloud auth application-default login # For local development
gcloud config set project $PROJECT_ID登录后,您需要启用 GCP 中必要的服务 API,例如 Google Kubernetes Engine API、Google Container Registry API 和 Google Container File System API,这些都是部署 GKE 集群和 Hugging Face TGI DLC 所必需的。
gcloud services enable container.googleapis.com
gcloud services enable containerregistry.googleapis.com
gcloud services enable containerfilesystem.googleapis.com此外,要将 kubectl 与 GKE 集群凭据一起使用,您还需要安装 gke-gcloud-auth-plugin,可以如下使用 gcloud 进行安装
gcloud components install gke-gcloud-auth-plugin
安装 gke-gcloud-auth-plugin 不需要通过 gcloud 进行特定安装,要了解更多替代安装方法,请访问 https://cloud.google.com/kubernetes-engine/docs/how-to/cluster-access-for-kubectl#install_plugin。
创建 GKE 集群
一切设置完成后,您可以继续创建 GKE 集群和节点池,本例中它将是一个独立的 GPU 节点,以便使用 GPU 加速器进行高性能推理,同时遵循 TGI 基于其内部 GPU 优化提出的建议。
部署 GKE 集群时,将使用“Autopilot”模式,因为它是大多数工作负载的推荐模式,因为底层基础设施由 Google 管理。或者,您也可以使用“Standard”模式。
在创建 GKE Autopilot 集群之前,请务必查看 GKE 文档 - 通过选择机器系列优化 Autopilot Pod 性能,因为并非所有版本都支持 GPU 加速器,例如 nvidia-l4 不受 GKE 集群版本 1.28.3 或更低版本的支持。
gcloud container clusters create-auto $CLUSTER_NAME \
--project=$PROJECT_ID \
--location=$LOCATION \
--release-channel=stable \
--cluster-version=1.28 \
--no-autoprovisioning-enable-insecure-kubelet-readonly-port要选择您所在位置的特定 GKE 集群版本,您可以运行以下命令
gcloud container get-server-config \
--flatten="channels" \
--filter="channels.channel=STABLE" \
--format="yaml(channels.channel,channels.defaultVersion)" \
--location=$LOCATION欲了解更多信息,请访问 https://cloud.google.com/kubernetes-engine/versioning#specifying_cluster_version。
GKE 集群创建完成后,您可以使用以下命令通过 kubectl 获取访问它的凭据
gcloud container clusters get-credentials $CLUSTER_NAME --location=$LOCATION可选:将模型从 Hugging Face Hub 上传到 GCS
这是本教程中的一个可选步骤,因为您可能希望重复使用 GCS 存储桶中的现有模型,如果是这样,那么请随意跳到本教程的下一步,了解如何为 GCS 配置 IAM,以便您可以从 GKE 集群中的 Pod 访问存储桶。
否则,要将 Hugging Face Hub 中的模型上传到 GCS 存储桶,您可以使用脚本 scripts/upload_model_to_gcs.sh,该脚本将从 Hugging Face Hub 下载模型并将其上传到 GCS 存储桶(如果尚未创建,则创建存储桶)。
gsutil 组件应通过 gcloud 安装,并且还应安装带有额外 hf_transfer 的 Python 包 huggingface_hub 和包 crcmod。
gcloud components install gsutil
pip install --upgrade --quiet "huggingface_hub[hf_transfer]" crcmod然后,您可以运行脚本从 Hugging Face Hub 下载模型并将其上传到 GCS 存储桶。
确保设置正确的权限以运行脚本,即 chmod +x scripts/upload_model_to_gcs.sh。
./scripts/upload_model_to_gcs.sh --model-id Qwen/Qwen2-7B-Instruct --gcs gs://$BUCKET_NAME/Qwen2-7B-Instruct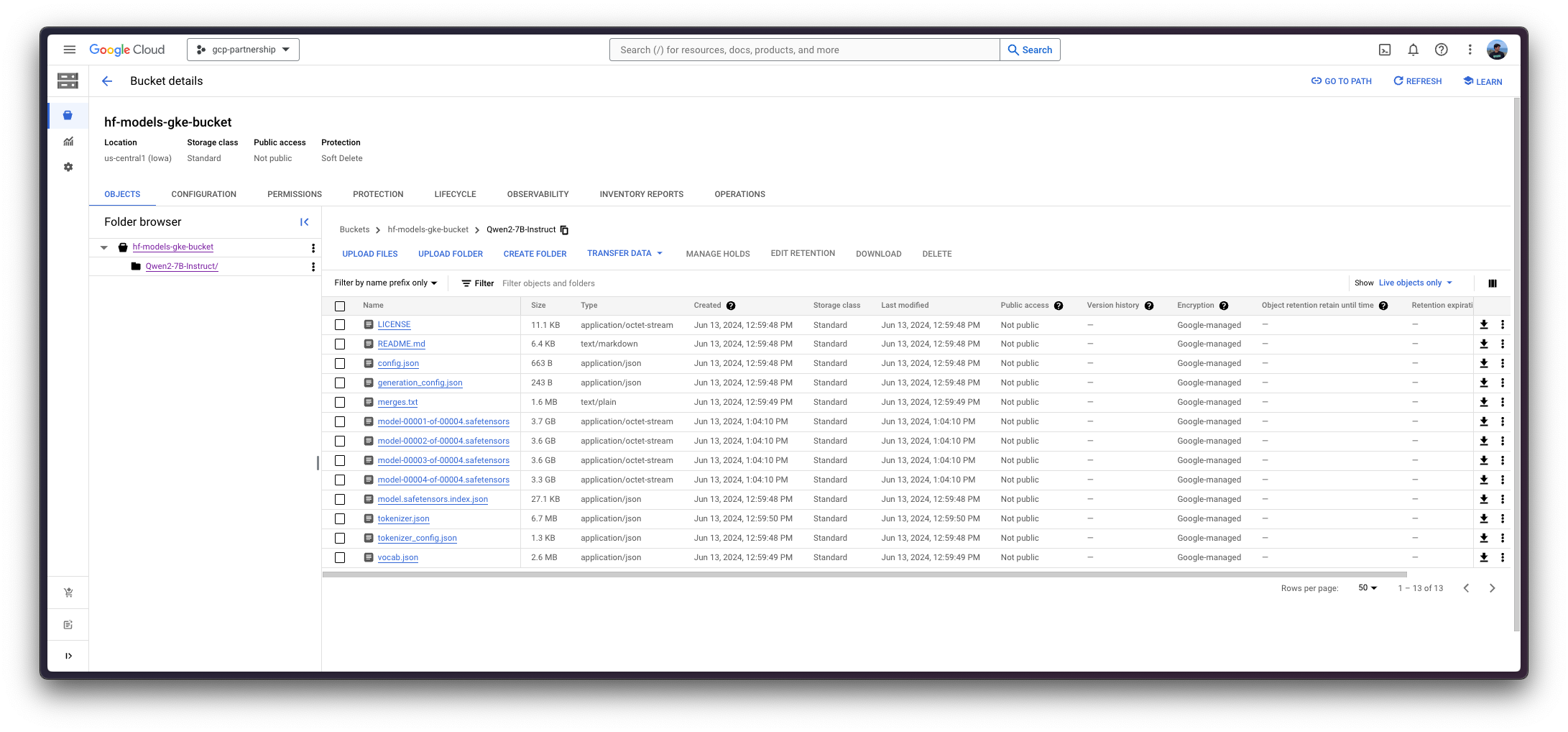
配置 GCS 的 IAM
在继续在 GKE 集群上部署 Hugging Face TGI DLC 之前,您需要为 GCS 存储桶设置 IAM 权限,以便 GKE 集群中的 Pod 可以访问该存储桶。为此,您需要在 GKE 集群中创建命名空间和服务帐户,然后为包含模型的 GCS 存储桶设置 IAM 权限,无论是从 Hugging Face Hub 上传的模型还是 GCS 存储桶中已有的模型。
为方便起见,由于命名空间和服务账户的引用将在以下步骤中使用,因此将设置环境变量 NAMESPACE 和 SERVICE_ACCOUNT。
export NAMESPACE=hf-gke-namespace
export SERVICE_ACCOUNT=hf-gke-service-account然后您可以在 GKE 集群中创建命名空间和服务账户,从而在使用该服务账户时,允许该命名空间中的 Pod 访问 GCS 存储桶的 IAM 权限。
kubectl create namespace $NAMESPACE
kubectl create serviceaccount $SERVICE_ACCOUNT --namespace $NAMESPACE然后您需要按如下方式将 IAM 策略绑定添加到存储桶
gcloud storage buckets add-iam-policy-binding \
gs://$BUCKET_NAME \
--member "principal://iam.googleapis.com/projects/$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")/locations/global/workloadIdentityPools/$PROJECT_ID.svc.id.goog/subject/ns/$NAMESPACE/sa/$SERVICE_ACCOUNT" \
--role "roles/storage.objectUser"部署 TGI
现在您可以继续在 Kubernetes 上部署 Hugging Face TGI DLC,提供 Qwen/Qwen2-7B-Instruct 模型,从挂载在 /data 的卷中复制,该卷是从模型所在的 GCS 存储桶复制的。
要探索所有可以通过 TGI 提供的模型,您可以在 Hub 中探索带有 text-generation-inference 标签的模型,网址为 https://huggingface.co/models?other=text-generation-inference。
Hugging Face TGI DLC 将通过 kubectl 部署,来自 config/ 目录中的配置文件。
deployment.yaml:包含 Pod 的部署详细信息,包括对 Hugging Face TGI DLC 的引用,将MODEL_ID设置为卷挂载中的模型路径,在本例中为/data/Qwen2-7B-Instruct。service.yaml:包含 Pod 的服务详细信息,公开端口 8080 用于 TGI 服务。storageclass.yaml:包含 Pod 的存储类详细信息,定义卷挂载的存储类。- (可选)
ingress.yaml:包含 Pod 的入口详细信息,将服务公开到外部,以便可以通过入口 IP 访问。
git clone https://github.com/huggingface/Google-Cloud-Containers
kubectl apply -f Google-Cloud-Containers/examples/gke/tgi-from-gcs-deployment/config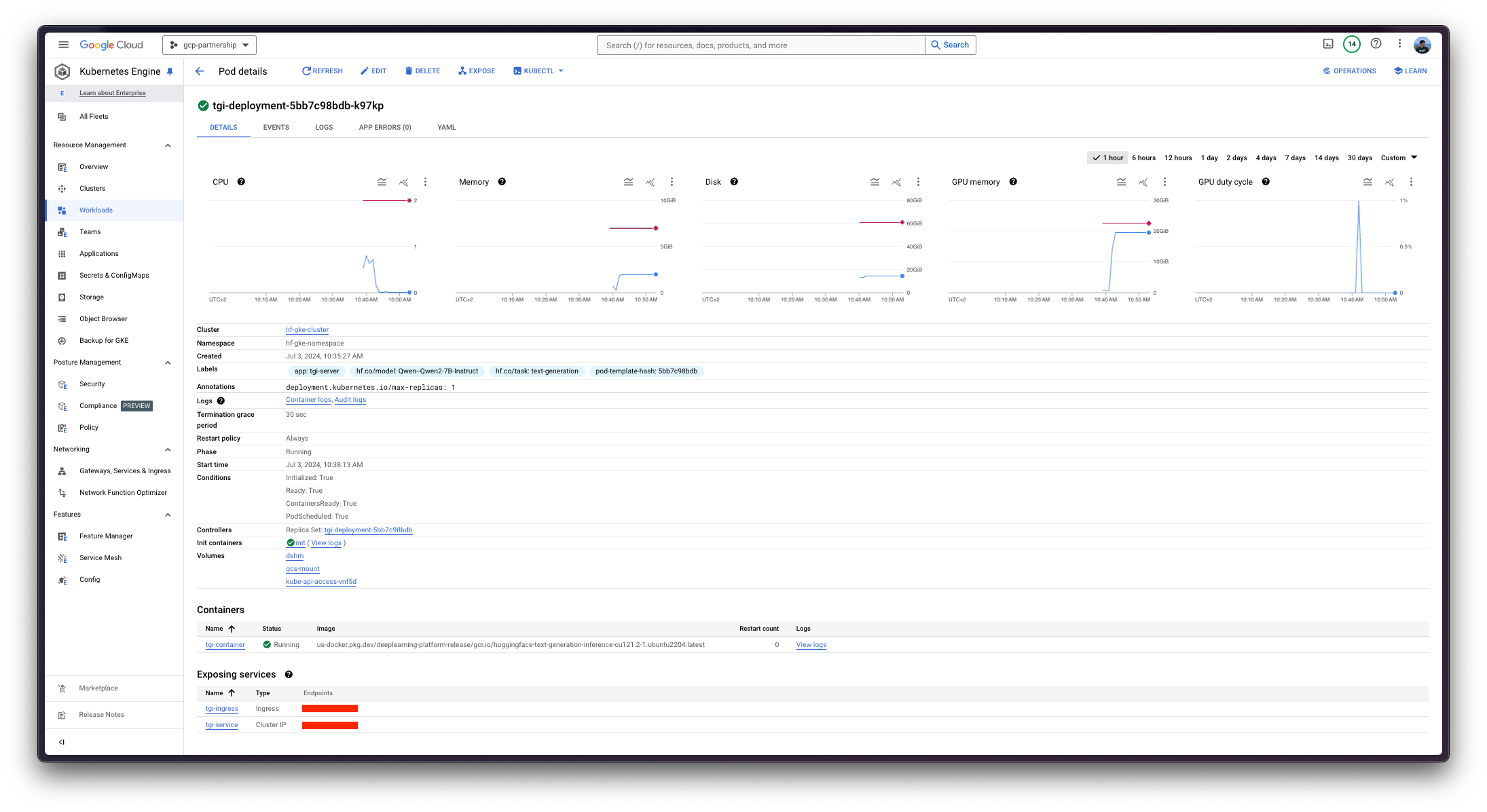
Kubernetes 部署可能需要几分钟才能准备就绪,您可以使用以下命令检查部署状态:
kubectl get pods --namespace $NAMESPACE或者,您也可以使用以下命令等待部署准备就绪:
kubectl wait --for=condition=Available --timeout=700s --namespace $NAMESPACE deployment/tgi-deployment使用 TGI 进行推理
要对已部署的 TGI 服务运行推理,您可以选择以下任一方式:
将已部署的 TGI 服务端口转发到 8080 端口,以便通过
localhost访问,命令如下:kubectl port-forward --namespace $NAMESPACE service/tgi-service 8080:8080通过入口的外部 IP 访问 TGI 服务,这是这里的默认场景,因为您已在
config/ingress.yaml文件中定义了入口配置(但可以跳过它而使用端口转发),可以通过以下命令检索:kubectl get ingress --namespace $NAMESPACE tgi-ingress -o jsonpath='{.status.loadBalancer.ingress[0].ip}'
通过 cURL
要使用 `cURL` 向 TGI 服务发送 POST 请求,您可以运行以下命令:
curl https://:8080/generate \
-X POST \
-d '{"inputs":"<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\nWhat is 2+2?<|im_end|>\n<|im_start|>assistant\n","parameters":{"temperature":0.7, "top_p": 0.95, "max_new_tokens": 128}}' \
-H 'Content-Type: application/json'或者向 ingress IP 发送 POST 请求:
curl http://$(kubectl get ingress --namespace $NAMESPACE tgi-ingress -o jsonpath='{.status.loadBalancer.ingress[0].ip}')/generate \
-X POST \
-d '{"inputs":"<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\nWhat is 2+2?<|im_end|>\n<|im_start|>assistant\n","parameters":{"temperature":0.7, "top_p": 0.95, "max_new_tokens": 128}}' \
-H 'Content-Type: application/json'生成以下输出
{"generated_text":"2 + 2 equals 4."}要使用预期的聊天模板格式生成 inputs,您可以使用以下代码片段
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct")
tokenizer.apply_chat_template(
[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is 2+2?"},
],
tokenize=False,
add_generation_prompt=True,
)通过 Python
要使用 Python 运行推理,您可以使用 openai Python SDK(请参阅 https://platform.openai.com/docs/quickstart 上的安装说明),将 localhost 或 ingress IP 设置为客户端的 base_url,然后运行以下代码:
from huggingface_hub import get_token
from openai import OpenAI
client = OpenAI(
base_url="https://:8080/v1/",
api_key=get_token() or "-",
)
chat_completion = client.chat.completions.create(
model="tgi",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is 2+2?"},
],
max_tokens=128,
)生成以下输出
ChatCompletion(id='', choices=[Choice(finish_reason='eos_token', index=0, message=ChatCompletionMessage(content='2 + 2 equals 4.', role='assistant', function_call=None, tool_calls=None), logprobs=None)], created=1719996359, model='/data/Qwen2-7B-Instruct', object='chat.completion', system_fingerprint='2.1.0-native', usage=CompletionUsage(completion_tokens=9, prompt_tokens=26, total_tokens=35))删除 GKE 集群
最后,一旦您完成在 GKE 集群上使用 TGI,您可以安全地删除 GKE 集群以避免产生不必要的费用。
gcloud container clusters delete $CLUSTER_NAME --location=$LOCATION或者,如果您想保留集群,也可以将已部署的 Pod 的副本数缩减到 0,因为默认情况下部署的 GKE 集群在 GKE Autopilot 模式下只运行一个 e2-small 实例。
kubectl scale --replicas=0 --namespace $NAMESPACE deployment/tgi-deployment📍 在 GitHub 上找到完整的示例 此处!