google-cloud 文档
在 GKE 上使用 TGI DLC 部署 Meta Llama 3 8B
并获得增强的文档体验
开始使用
在 GKE 上使用 TGI DLC 部署 Meta Llama 3 8B
Meta Llama 3 是 Meta 发布的 Llama 系列最新 LLM,有 8B 和 70B 两种尺寸,包含基础模型和指令微调模型。Text Generation Inference (TGI) 是 Hugging Face 开发的用于部署和提供 LLM 的工具包,具有高性能文本生成能力。而 Google Kubernetes Engine (GKE) 是 Google Cloud 中一个完全托管的 Kubernetes 服务,可用于使用 GCP 的基础设施大规模部署和操作容器化应用程序。
本示例展示了如何在 GKE 集群上部署 Hugging Face Hub 中的 LLM(Meta Llama 3 8B Instruct),该集群运行专门构建的容器,用于在安全且受管的环境中部署 LLM,并使用 Hugging Face 的 TGI DLC。
设置/配置
首先,您需要在本地机器上安装 gcloud 和 kubectl,它们分别是 Google Cloud 和 Kubernetes 的命令行工具,用于与 GCP 和 GKE 集群交互。
- 要安装
gcloud,请按照 Cloud SDK 文档 - 安装 gcloud CLI 中的说明进行操作。 - 要安装
kubectl,请按照 Kubernetes 文档 - 安装工具 中的说明进行操作。
或者,为了简化本教程中命令的使用,您需要为 GCP 设置以下环境变量
export PROJECT_ID=your-project-id
export LOCATION=your-location
export CLUSTER_NAME=your-cluster-name然后您需要登录到您的 GCP 账户,并将项目 ID 设置为您要用于部署 GKE 集群的项目。
gcloud auth login
gcloud auth application-default login # For local development
gcloud config set project $PROJECT_ID登录后,您需要启用 GCP 中必要的服务 API,例如 Google Kubernetes Engine API、Google Container Registry API 和 Google Container File System API,这些都是部署 GKE 集群和 Hugging Face TGI DLC 所必需的。
gcloud services enable container.googleapis.com
gcloud services enable containerregistry.googleapis.com
gcloud services enable containerfilesystem.googleapis.com此外,要将 kubectl 与 GKE 集群凭据一起使用,您还需要安装 gke-gcloud-auth-plugin,可以如下使用 gcloud 进行安装
gcloud components install gke-gcloud-auth-plugin
安装 gke-gcloud-auth-plugin 不需要通过 gcloud 特别安装,要了解更多替代安装方法,请访问 https://cloud.google.com/kubernetes-engine/docs/how-to/cluster-access-for-kubectl#install_plugin。
创建 GKE 集群
一切设置完毕后,您可以继续创建 GKE 集群和节点池,本例中将是一个单 GPU 节点,以便使用 GPU 加速器进行高性能推理,同时遵循 TGI 基于其内部 GPU 优化提出的建议。
部署 GKE 集群时,将使用“Autopilot”模式,因为它是大多数工作负载的推荐模式,因为底层基础设施由 Google 管理。或者,您也可以使用“Standard”模式。
在创建 GKE Autopilot 集群之前,务必查看 GKE 文档 - 通过选择机器系列优化 Autopilot Pod 性能,因为并非所有版本都支持 GPU 加速器,例如 nvidia-l4 在 GKE 集群版本 1.28.3 或更低版本中不受支持。
gcloud container clusters create-auto $CLUSTER_NAME \
--project=$PROJECT_ID \
--location=$LOCATION \
--release-channel=stable \
--cluster-version=1.28 \
--no-autoprovisioning-enable-insecure-kubelet-readonly-port要选择您所在位置的特定 GKE 集群版本,您可以运行以下命令
gcloud container get-server-config \
--flatten="channels" \
--filter="channels.channel=STABLE" \
--format="yaml(channels.channel,channels.defaultVersion)" \
--location=$LOCATION欲了解更多信息,请访问 https://cloud.google.com/kubernetes-engine/versioning#specifying_cluster_version。
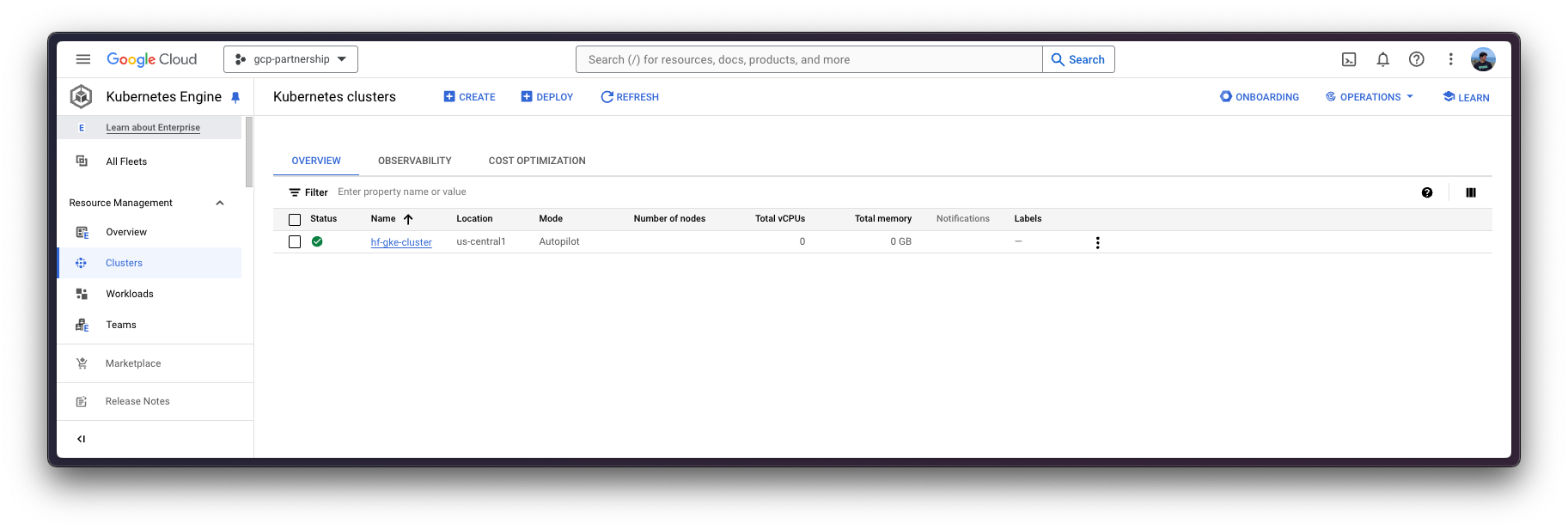
GKE 集群创建完成后,您可以使用以下命令通过 kubectl 获取访问它的凭据
gcloud container clusters get-credentials $CLUSTER_NAME --location=$LOCATION可选:在 GKE 中设置密钥
由于 meta-llama/Meta-Llama-3.1-8B-Instruct 是一个受控模型,您需要通过 kubectl 使用 Hugging Face Hub 令牌设置 Kubernetes 密钥。
要为 Hugging Face Hub 生成自定义令牌,您可以按照 https://huggingface.co/docs/hub/en/security-tokens 上的说明进行操作;建议的设置方式是按如下方式安装 huggingface_hub Python SDK
pip install --upgrade --quiet huggingface_hub
然后使用生成的具有对受限/私有模型读取权限的令牌登录
huggingface-cli login
最后,您可以使用 huggingface_hub Python SDK 检索令牌,如下所示创建包含 Hugging Face Hub 生成令牌的 Kubernetes secret
kubectl create secret generic hf-secret \
--from-literal=hf_token=$(python -c "from huggingface_hub import get_token; print(get_token())") \
--dry-run=client -o yaml | kubectl apply -f -或者,您可以直接按如下方式设置令牌
kubectl create secret generic hf-secret \
--from-literal=hf_token=hf_*** \
--dry-run=client -o yaml | kubectl apply -f -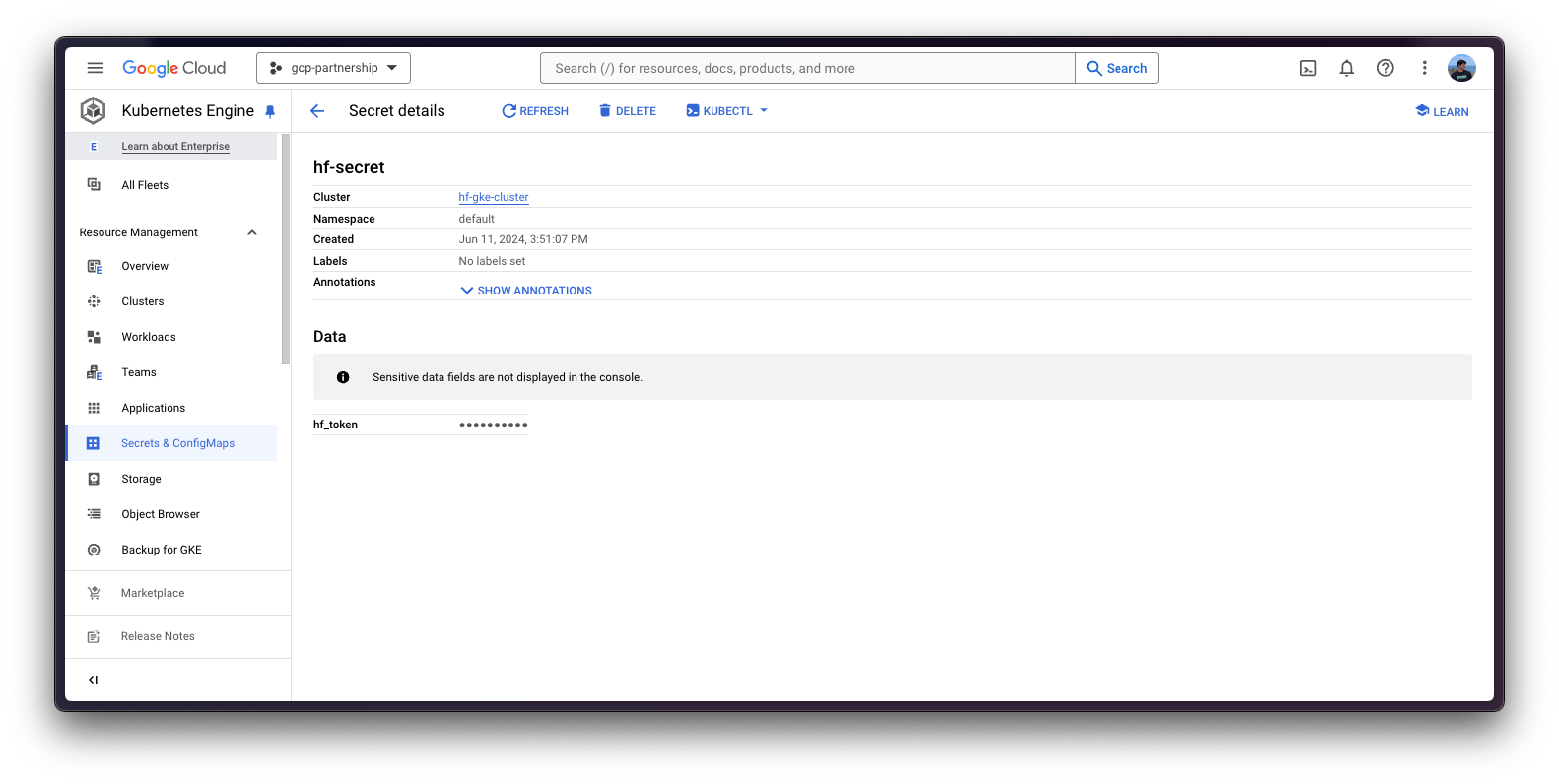
有关如何在 GKE 集群中设置 Kubernetes 密钥的更多信息,请访问 https://cloud.google.com/secret-manager/docs/secret-manager-managed-csi-component。
部署 TGI
现在您可以继续进行 Hugging Face TGI DLC 的 Kubernetes 部署,从 Hugging Face Hub 提供 meta-llama/Meta-Llama-3.1-8B-Instruct 模型。
要探索所有可以通过 TGI 提供的模型,您可以在 Hub 中通过 text-generation-inference 标签探索模型,网址为 https://huggingface.co/models?other=text-generation-inference。
Hugging Face TGI DLC 将通过 kubectl 从 config/ 目录中的配置文件部署
deployment.yaml:包含 Pod 的部署详细信息,包括对 Hugging Face TGI DLC 的引用,将MODEL_ID设置为meta-llama/Meta-Llama-3.1-8B-Instruct。service.yaml:包含 Pod 的服务详细信息,暴露 8080 端口用于 TGI 服务。- (可选)
ingress.yaml:包含 Pod 的入口详细信息,将服务暴露给外部世界,以便可以通过入口 IP 访问。
git clone https://github.com/huggingface/Google-Cloud-Containers
kubectl apply -f Google-Cloud-Containers/examples/gke/tgi-deployment/config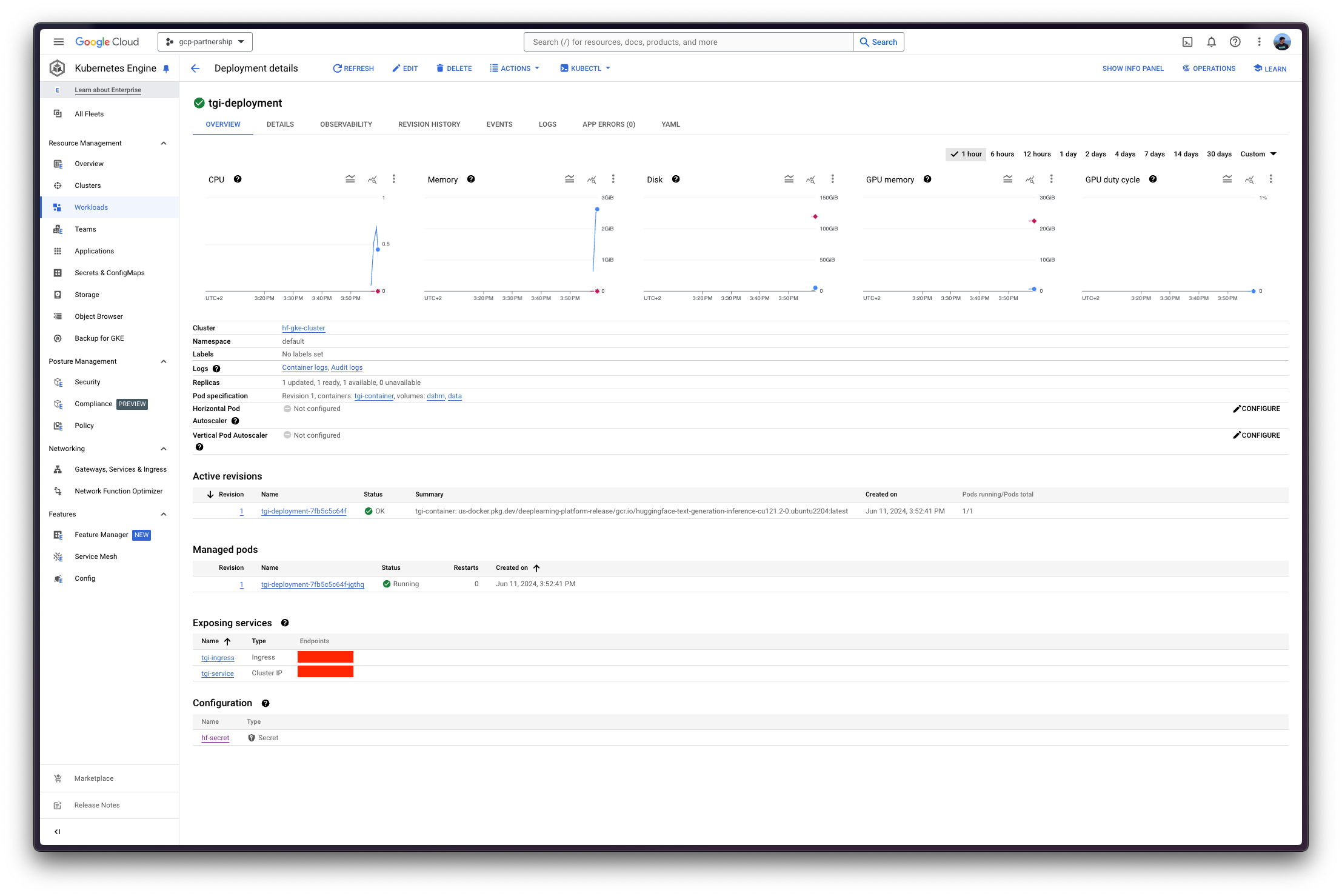
Kubernetes 部署可能需要几分钟才能准备就绪,您可以使用以下命令检查部署状态:
kubectl get pods
或者,您也可以使用以下命令等待部署准备就绪:
kubectl wait --for=condition=Available --timeout=700s deployment/tgi-deployment使用 TGI 进行推理
要对已部署的 TGI 服务运行推理,您可以选择以下方式:
将已部署的 TGI 服务端口转发到 8080 端口,以便通过
localhost访问,命令如下:kubectl port-forward service/tgi-service 8080:8080
通过入口的外部 IP 访问 TGI 服务,这是这里的默认情况,因为您已经在 `config/ingress.yaml` 文件中定义了入口配置(但可以跳过它而使用端口转发),可以通过以下命令检索:
kubectl get ingress tgi-ingress -o jsonpath='{.status.loadBalancer.ingress[0].ip}'
通过 cURL
要使用 `cURL` 向 TGI 服务发送 POST 请求,您可以运行以下命令:
curl https://:8080/generate \
-X POST \
-d '{"inputs":"<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nYou are a helpful assistant.<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nWhat is 2+2?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n","parameters":{"temperature":0.7, "top_p": 0.95, "max_new_tokens": 128}}' \
-H 'Content-Type: application/json'或者向 ingress IP 发送 POST 请求:
curl http://$(kubectl get ingress tgi-ingress -o jsonpath='{.status.loadBalancer.ingress[0].ip}')/generate \
-X POST \
-d '{"inputs":"<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nYou are a helpful assistant.<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nWhat is 2+2?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n","parameters":{"temperature":0.7, "top_p": 0.95, "max_new_tokens": 128}}' \
-H 'Content-Type: application/json'它会产生以下输出
{"generated_text":"The answer to 2+2 is 4."}要生成具有预期聊天模板格式的 `inputs`,可以使用以下代码片段
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct")
tokenizer.apply_chat_template(
[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is 2+2?"},
],
tokenize=False,
add_generation_prompt=True,
)通过 Python
要使用 Python 运行推理,您可以使用 openai Python SDK(请参阅 https://platform.openai.com/docs/quickstart 上的安装说明),将 localhost 或入口 IP 设置为客户端的 base_url,然后运行以下代码
from huggingface_hub import get_token
from openai import OpenAI
client = OpenAI(
base_url="https://:8080/v1/",
api_key=get_token() or "-",
)
chat_completion = client.chat.completions.create(
model="tgi",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is 2+2?"},
],
max_tokens=128,
)它会产生以下输出
ChatCompletion(id='', choices=[Choice(finish_reason='eos_token', index=0, logprobs=None, message=ChatCompletionMessage(content='The answer to 2+2 is 4!', role='assistant', function_call=None, tool_calls=None))], created=1718108522, model='meta-llama/Meta-Llama-3-8B-Instruct', object='text_completion', system_fingerprint='2.0.2-sha-6073ece', usage=CompletionUsage(completion_tokens=12, prompt_tokens=28, total_tokens=40))删除 GKE 集群
最后,一旦您完成在 GKE 集群上使用 TGI,您可以安全地删除 GKE 集群以避免产生不必要的费用。
gcloud container clusters delete $CLUSTER_NAME --location=$LOCATION或者,如果您想保留集群,也可以将已部署的 Pod 的副本数缩减到 0,因为默认情况下部署的 GKE 集群在 GKE Autopilot 模式下只运行一个 e2-small 实例。
kubectl scale --replicas=0 deployment/tgi-deployment
📍 完整示例请在 GitHub 上找到 此处!