Hub 文档
Langfuse on Spaces
并获得增强的文档体验
开始使用
Spaces 上的 Langfuse
本指南将向您展示如何在 Hugging Face Spaces 上部署 Langfuse 并开始为您的 LLM 应用程序配置可观测性。此集成有助于您在 Hugging Face Hub 上试验 LLM API,在一处管理提示,并评估模型输出。
什么是 Langfuse?
Langfuse 是一个开源 LLM 工程平台,可帮助团队协作调试、评估和迭代其 LLM 应用程序。
Langfuse 的主要功能包括 LLM 跟踪以捕获应用程序执行流的完整上下文、用于集中和协作提示迭代的提示管理、用于评估输出质量的评估指标、用于测试和基准测试的数据集创建,以及用于试验提示和模型配置的游乐场。
此视频是对 Langfuse 功能的 10 分钟演示
为什么需要 LLM 可观测性?
- 随着语言模型越来越普及,了解它们的行为和性能非常重要。
- LLM 可观测性涉及通过输出监控和理解 LLM 应用程序的内部状态。
- 它对于解决以下挑战至关重要:
- 复杂的控制流,带有重复或链式调用,使调试变得困难。
- 非确定性输出,增加了持续质量评估的复杂性。
- 多样的用户意图,需要深入理解以改善用户体验。
- 构建 LLM 应用程序涉及复杂的工作流,可观测性有助于管理这些复杂性。
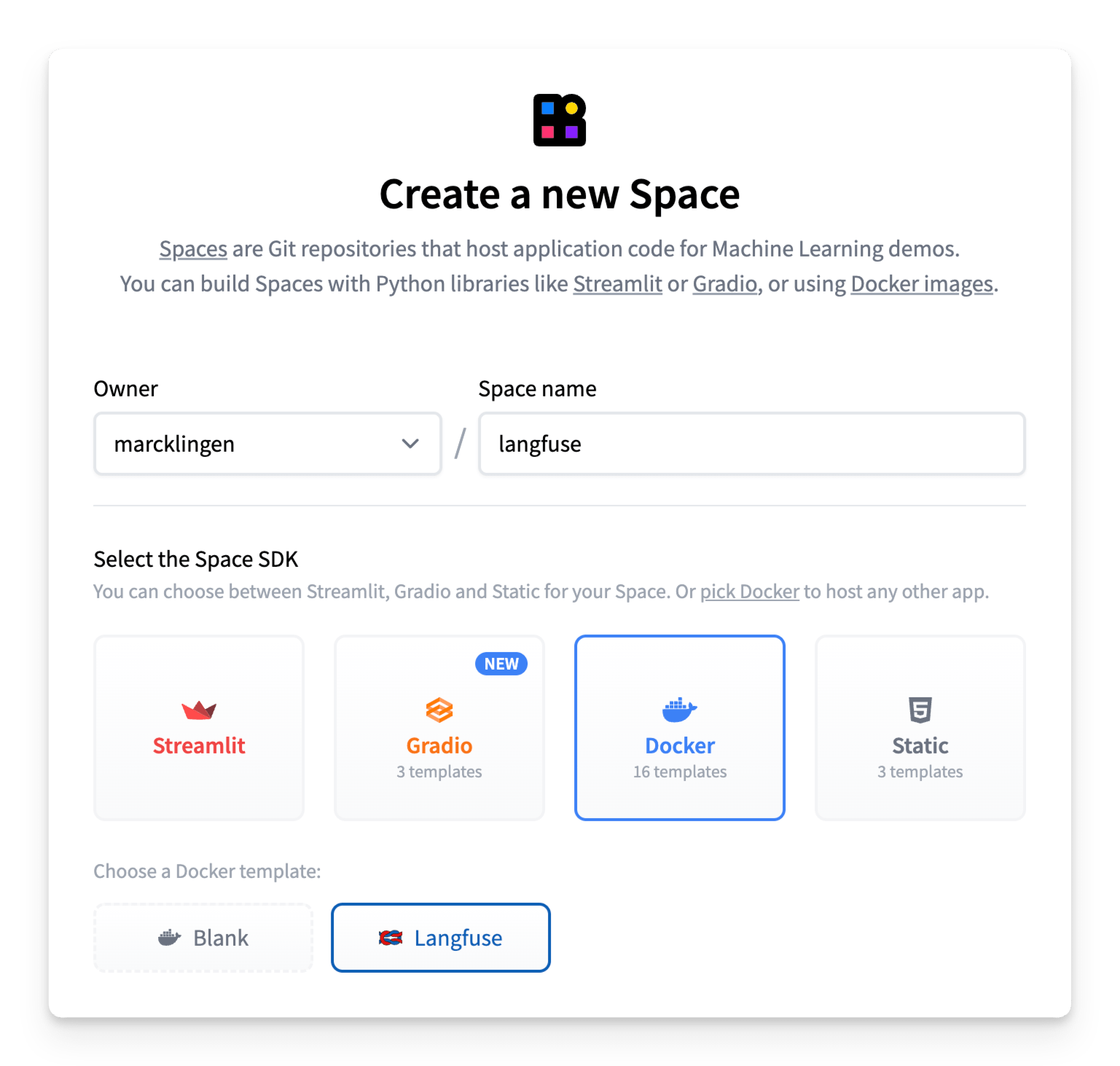
步骤 1:在 Spaces 上设置 Langfuse
Langfuse Hugging Face Space 允许您通过几次点击即可部署 Langfuse 版本并开始运行。

要开始,请点击上面的按钮或按照以下步骤操作
- 创建一个新的 Hugging Face Space
- 选择 Docker 作为 Space SDK
- 选择 Langfuse 作为 Space 模板
- 启用持久存储以确保您的 Langfuse 数据在重启后仍然存在
- 确保 Space 设置为公共可见,以便 Langfuse API/SDK 可以访问该应用程序(有关详细信息,请参见下面的注释)
- [可选但推荐] 为了安全部署,请替换环境变量的默认值
NEXTAUTH_SECRET:用于验证登录会话 cookie,使用openssl rand -base64 32生成至少 256 位熵的密钥。SALT:用于哈希 API 密钥加盐,使用openssl rand -base64 32生成至少 256 位熵的密钥。ENCRYPTION_KEY:用于加密敏感数据。必须为 256 位,采用十六进制格式的 64 个字符串字符,通过以下方式生成:openssl rand -hex 32。
- 点击创建 Space!
用户访问
您的 Langfuse Space 已预先配置 Hugging Face OAuth 以进行安全身份验证,因此您首次登录时需要按照弹窗中的说明授权对您的 Hugging Face 帐户的 read 访问权限。
进入应用程序后,您可以使用Langfuse 原生功能来管理组织、项目和用户。
Langfuse 空间必须设置为公共可见,以便 Langfuse API/SDK 可以访问该应用程序。这意味着默认情况下,任何已登录的 Hugging Face 用户都将能够访问 Langfuse 空间。
您可以通过两种不同的方法阻止新用户注册和访问空间
1. (推荐)Hugging Face 原生组织级别 OAuth 限制
如果您想将访问权限限制为仅特定组织的成员,您只需在 Space 的 README.md 文件中设置 hf_oauth_authorized_org 元数据字段,如此处所示。
配置完成后,只有指定组织的成员用户才能访问该空间。
2. 手动访问控制
您还可以通过将 AUTH_DISABLE_SIGNUP 环境变量设置为 true 来限制每个用户的访问。请务必在设置此变量之前先登录并验证空间,否则您自己的用户配置文件将无法进行身份验证。
注意:如果您已将 AUTH_DISABLE_SIGNUP 环境变量设置为 true 以限制访问,并且想授予新用户访问空间,您需要先将其设置回 false(等待重建完成),然后添加用户并让他们通过 OAuth 进行身份验证,然后再将其设置回 true。
步骤 2:使用 Langfuse
现在 Langfuse 已经运行,您可以开始配置您的 LLM 应用程序以捕获跟踪并管理您的提示。让我们看看如何操作!
监控任何应用程序
Langfuse 与模型无关,可用于跟踪任何应用程序。请参阅 Langfuse 文档中的入门指南,了解如何配置您的代码。
Langfuse 支持与许多流行的 LLM 框架(包括 Langchain、LlamaIndex 和 OpenAI)原生集成,并提供 Python 和 JS/TS SDK 来配置您的代码。Langfuse 还提供各种 API 端点来摄取数据,并已集成到其他开源项目中,例如 Langflow、Dify 和 Haystack。
示例 1:跟踪对推理提供商的调用
作为一个简单的示例,下面是如何使用 Langfuse Python SDK 跟踪对推理提供商的 LLM 调用。
请务必首先配置您的 LANGFUSE_HOST、LANGFUSE_PUBLIC_KEY 和 LANGFUSE_SECRET_KEY 环境变量,并确保您已使用您的 Hugging Face 帐户进行身份验证。
from langfuse.openai import openai
from huggingface_hub import get_token
client = openai.OpenAI(
base_url="https://router.huggingface.co/hf-inference/models/meta-llama/Llama-3.3-70B-Instruct/v1",
api_key=get_token(),
)
messages = [{"role": "user", "content": "What is observability for LLMs?"}]
response = client.chat.completions.create(
model="meta-llama/Llama-3.3-70B-Instruct",
messages=messages,
max_tokens=100,
)示例 2:监控 Gradio 应用程序
我们创建了一个 Gradio 模板空间,展示了如何使用 Hugging Face 模型创建简单的聊天应用程序,并在 Langfuse 中跟踪模型调用和用户反馈——而无需离开 Hugging Face。
要开始,请复制此 Gradio 模板空间并按照README 中的说明进行操作。
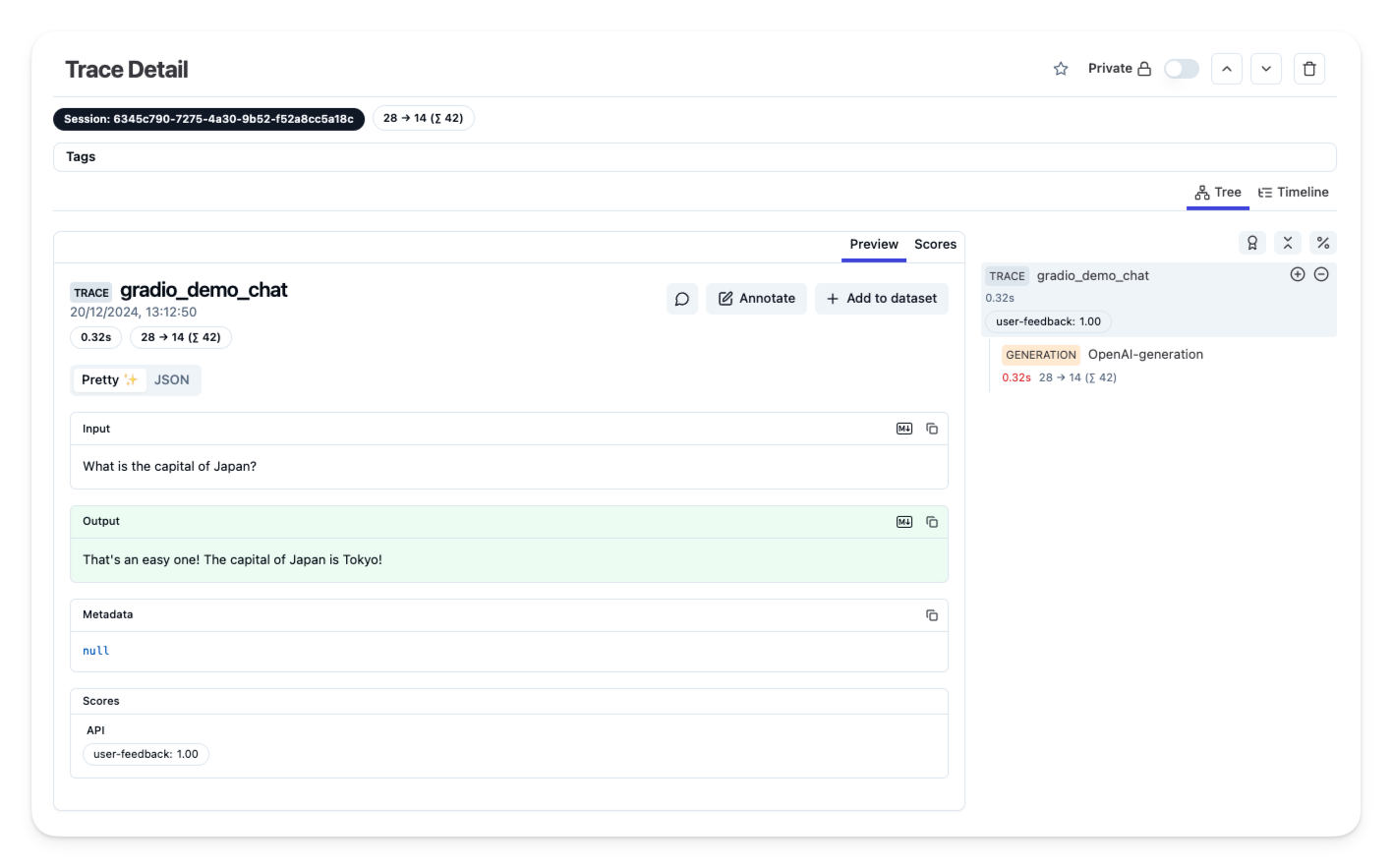
步骤 3:在 Langfuse 中查看跟踪
一旦您配置了您的应用程序,并将跟踪或用户反馈摄取到 Langfuse 中,您就可以在 Langfuse 中查看您的跟踪。
其他资源和支持
如需更多帮助,请在GitHub discussions 上提出支持线程或提出问题。
< > 在 GitHub 上更新