扩散模型课程文档
引言
并获得增强的文档体验
开始使用
简介
本 Notebook 将介绍如何使用 Stable Diffusion 通过现有 pipeline 来创建和修改图像的基础知识。我们还将简要介绍 pipeline 中的关键组件,而将更深入的探索留给深度剖析的 Notebook。具体来说,我们将涵盖:
- 使用
StableDiffusionPipeline从文本生成图像,并尝试可用的参数 - 了解一些关键 pipeline 组件的实际作用
- VAE(变分自编码器),它使这成为一个“潜在扩散模型”
- 处理文本提示的 tokenizer 和文本编码器
- UNet 本身
- 调度器(scheduler),并探索不同的调度器
- 使用 pipeline 组件复现采样循环
- 使用 Img2Img pipeline 编辑现有图像
- 使用 inpainting 和 Depth2Img pipeline
❓如果你有任何问题,请在 Hugging Face Discord 服务器的 #diffusion-models-class 频道中提出。如果你还没有注册,可以在这里注册:https://huggingface.co/join/discord
设置
%pip install -Uq diffusers ftfy accelerate
# Installing transformers from source for now since we need the latest version for Depth2Img
%pip install -Uq git+https://github.com/huggingface/transformersimport torch
import requests
from PIL import Image
from io import BytesIO
from matplotlib import pyplot as plt
# We'll be exploring a number of pipelines today!
from diffusers import (
StableDiffusionPipeline,
StableDiffusionImg2ImgPipeline,
StableDiffusionInpaintPipeline,
StableDiffusionDepth2ImgPipeline,
)
# We'll use a couple of demo images later in the notebook
def download_image(url):
response = requests.get(url)
return Image.open(BytesIO(response.content)).convert("RGB")
# Download images for inpainting example
img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
img_height = 512
img_width = 512
init_image = download_image(img_url).resize((img_height, img_width))
mask_image = download_image(mask_url).resize((img_height, img_width))# Set device
device = "mps" if torch.backends.mps.is_available() else "cuda" if torch.cuda.is_available() else "cpu"从文本生成图像
让我们加载一个 Stable Diffusion pipeline,看看它能做什么。Stable Diffusion 有多个不同版本,在撰写本文时最新的是 2.1 版本。如果你想探索旧版本,只需将模型 ID 替换为相应的模型(例如,你可以尝试“CompVis/stable-diffusion-v1-4”或从 dreambooth 概念库 中选择一个模型)。
# Load the pipeline
model_id = "stabilityai/stable-diffusion-2-1-base"
pipe = StableDiffusionPipeline.from_pretrained(model_id).to(device)如果你的 GPU 内存不足,可以采取一些措施来减少 RAM 使用量:
加载 FP16 版本(并非所有系统都支持)。使用此版本时,在实验 pipeline 的各个组件时,你可能还需要将张量转换为 torch.float16。
pipe = StableDiffusionPipeline.from_pretrained(model_id, revision="fp16", torch_dtype=torch.float16).to(device)启用注意力切片(attention slicing)。这会降低 GPU 内存使用,但会略微降低速度。
pipe.enable_attention_slicing()减小你正在生成的图像尺寸。
加载 pipeline 后,我们可以使用以下代码根据提示生成图像:
>>> # Set up a generator for reproducibility
>>> generator = torch.Generator(device=device).manual_seed(42)
>>> # Run the pipeline, showing some of the available arguments
>>> pipe_output = pipe(
... prompt="Palette knife painting of an autumn cityscape", # What to generate
... negative_prompt="Oversaturated, blurry, low quality", # What NOT to generate
... height=480,
... width=640, # Specify the image size
... guidance_scale=8, # How strongly to follow the prompt
... num_inference_steps=35, # How many steps to take
... generator=generator, # Fixed random seed
... )
>>> # View the resulting image
>>> pipe_output.images[0]
练习: 花一些时间玩一下上面的代码块,使用你自己的提示并调整设置,看看它们如何影响输出。使用不同的随机种子或移除 generator 参数以每次获得不同的结果。
可调整的关键参数:
- 宽度(Width)和高度(height)指定了生成图像的大小。它们必须能被 8 整除,以便 VAE 正常工作(我们将在后面的章节中看到)。
- 步数(number of steps)影响生成质量。默认值(50)效果很好,但在某些情况下,少至 20 步也可以得到不错的结果,这对于实验很方便。
- 负面提示(negative prompt)在无分类器引导(classifier-free guidance)过程中使用,是增加额外控制的有用方法。你可以省略它,但许多用户发现在负面提示中列出一些不希望出现的描述很有用,如上所示。
guidance_scale参数决定了无分类器引导(CFG)的强度。较高的值会使生成的图像更好地匹配提示,但如果值太高,结果可能会变得过度饱和和不美观。
如果你在寻找提示词的灵感,Stable Diffusion 提示词手册 是一个很好的起点。
在下面的代码块中,你可以看到增加引导尺度的效果:
>>> # @markdown comparing guidance scales:
>>> cfg_scales = [1.1, 8, 12] # @param
>>> prompt = "A collie with a pink hat" # @param
>>> fig, axs = plt.subplots(1, len(cfg_scales), figsize=(16, 5))
>>> for i, ax in enumerate(axs):
... im = pipe(
... prompt,
... height=480,
... width=480,
... guidance_scale=cfg_scales[i],
... num_inference_steps=35,
... generator=torch.Generator(device=device).manual_seed(42),
... ).images[0]
... ax.imshow(im)
... ax.set_title(f"CFG Scale {cfg_scales[i]}")
调整上面的值以尝试不同的尺度和提示。当然,解读是主观的,但在我看来,8-12 范围内的任何值产生的结果都比低于或高于此范围的值要好。
Pipeline 组件
我们正在使用的 StableDiffusionPipeline 比我们在前几个单元中探索的 DDPMPipeline 要复杂一些。除了 UNet 和调度器之外,pipeline 中还包含许多其他组件:
>>> print(list(pipe.components.keys())) # List components['vae', 'text_encoder', 'tokenizer', 'unet', 'scheduler', 'safety_checker', 'feature_extractor', 'image_encoder']
为了更好地理解 pipeline 的工作原理,让我们简要地看一下每个组件的实际作用,然后将它们组合在一起,自己复现 pipeline 的功能。
VAE

VAE(变分自编码器)是一种模型,可以将其输入编码为压缩表示,然后将此“潜在”(latent)表示解码回接近原始输入的内容。在使用 Stable Diffusion 生成图像时,我们首先通过在 VAE 的“潜在空间”中应用扩散过程来生成潜在表示,然后在最后解码它们以查看生成的图像。
这里有一些代码,它接受一个输入图像,将其编码为潜在表示,然后再次使用 VAE 将其解码:
>>> # Create some fake data (a random image, range (-1, 1))
>>> images = torch.rand(1, 3, 512, 512).to(device) * 2 - 1
>>> print("Input images shape:", images.shape)
>>> # Encode to latent space
>>> with torch.no_grad():
... latents = 0.18215 * pipe.vae.encode(images).latent_dist.mean
>>> print("Encoded latents shape:", latents.shape)
>>> # Decode again
>>> with torch.no_grad():
... decoded_images = pipe.vae.decode(latents / 0.18215).sample
>>> print("Decoded images shape:", decoded_images.shape)Input images shape: torch.Size([1, 3, 512, 512]) Encoded latents shape: torch.Size([1, 4, 64, 64]) Decoded images shape: torch.Size([1, 3, 512, 512])
如你所见,512x512 的图像被压缩成一个 64x64 的潜在表示(有四个通道)。这个每个空间维度 8 倍的缩减是指定的宽度和高度需要是 8 的倍数的原因。
处理这些信息丰富的 4x64x64 潜在表示比处理巨大的 512px 图像更高效,从而实现了更快的扩散模型,训练和使用所需的资源更少。VAE 解码过程并非完美,但它足够好,以至于通常值得进行微小的质量权衡。
注意:上面的代码示例包含了匹配 SD 训练期间使用的处理所需的缩放因子 0.18215。
Tokenizer 和文本编码器

文本编码器的目标是将输入字符串(提示)转换为可以作为条件输入到 UNet 的数值表示。文本首先使用 pipeline 的 tokenizer 转换为一系列 token。文本编码器有一个约 5 万个 token 的词汇表——任何不在这个词汇表中的词都会被分解成更小的子词。然后,这些 token 被输入到文本编码器模型本身——一个 Transformer 模型,最初是作为 CLIP 的文本编码器训练的。我们希望这个预训练的 Transformer 模型已经学习到了丰富的文本表示,这对于扩散任务也很有用。
让我们通过编码一个示例提示来测试这个过程,首先手动进行 tokenization 并将其输入文本编码器,然后使用 pipeline 的 encode_prompt 方法来展示完整的处理过程,包括将长度填充/截断到最大长度 77 个 token。
>>> # Tokenizing and encoding an example prompt manually
>>> # Tokenize
>>> input_ids = pipe.tokenizer(["A painting of a flooble"])["input_ids"]
>>> print("Input ID -> decoded token")
>>> for input_id in input_ids[0]:
... print(f"{input_id} -> {pipe.tokenizer.decode(input_id)}")
>>> # Feed through CLIP text encoder
>>> input_ids = torch.tensor(input_ids).to(device)
>>> with torch.no_grad():
... text_embeddings = pipe.text_encoder(input_ids)["last_hidden_state"]
>>> print("Text embeddings shape:", text_embeddings.shape)Input ID -> decoded token 49406 -> <|startoftext|> 320 -> a 3086 -> painting 539 -> of 320 -> a 4062 -> floo 1059 -> ble 49407 -> <|endoftext|> Text embeddings shape: torch.Size([1, 8, 1024])
# Get the final text embeddings using the pipeline's encode_prompt function
text_embeddings = pipe._encode_prompt("A painting of a flooble", device, 1, True, "")
text_embeddings.shape这些文本嵌入(文本编码器模型中最后一个 Transformer 块的所谓“隐藏状态”)将作为额外参数输入到 UNet 的 forward 方法中,我们将在下一节中看到。
UNet

UNet 接受一个带噪的输入并预测噪声,就像我们在之前单元中看到的 UNet 一样。与之前的例子不同,输入不是图像,而是图像的潜在表示。除了时间步条件外,这个 UNet 还将提示的文本嵌入作为额外输入。下面是它对一些虚拟数据进行预测的例子:
>>> # Dummy inputs
>>> timestep = pipe.scheduler.timesteps[0]
>>> latents = torch.randn(1, 4, 64, 64).to(device)
>>> text_embeddings = torch.randn(1, 77, 1024).to(device)
>>> # Model prediction
>>> with torch.no_grad():
... unet_output = pipe.unet(latents, timestep, text_embeddings).sample
>>> print("UNet output shape:", unet_output.shape) # Same shape as the input latentsUNet output shape: torch.Size([1, 4, 64, 64])
调度器
调度器(scheduler)存储噪声计划,并根据模型预测管理更新带噪样本。默认的调度器是 PNDMScheduler,但你也可以使用其他调度器(例如 LMSDiscreteScheduler),只要它们使用相同的配置进行初始化。
我们可以绘制噪声计划来查看噪声水平(基于 $\bar{\alpha}$)随时间的变化:
>>> plt.plot(pipe.scheduler.alphas_cumprod, label=r"$\bar{\alpha}$")
>>> plt.xlabel("Timestep (high noise to low noise ->)")
>>> plt.title("Noise schedule")
>>> plt.legend()
如果你想尝试不同的调度器,可以按如下方式更换一个新的:
>>> from diffusers import LMSDiscreteScheduler
>>> # Replace the scheduler
>>> pipe.scheduler = LMSDiscreteScheduler.from_config(pipe.scheduler.config)
>>> # Print the config
>>> print("Scheduler config:", pipe.scheduler)
>>> # Generate an image with this new scheduler
>>> pipe(
... prompt="Palette knife painting of an winter cityscape",
... height=480,
... width=480,
... generator=torch.Generator(device=device).manual_seed(42),
... ).images[0]Scheduler config: LMSDiscreteScheduler { "_class_name": "LMSDiscreteScheduler", "_diffusers_version": "0.30.3", "beta_end": 0.012, "beta_schedule": "scaled_linear", "beta_start": 0.00085, "clip_sample": false, "num_train_timesteps": 1000, "prediction_type": "epsilon", "set_alpha_to_one": false, "skip_prk_steps": true, "steps_offset": 1, "timestep_spacing": "linspace", "trained_betas": null, "use_karras_sigmas": false }
你可以在这里阅读更多关于使用不同调度器的信息。
DIY 采样循环
现在我们已经看到了所有这些组件的实际作用,我们可以将它们组合起来,复现 pipeline 的功能:
>>> guidance_scale = 8 # @param
>>> num_inference_steps = 30 # @param
>>> prompt = "Beautiful picture of a wave breaking" # @param
>>> negative_prompt = "zoomed in, blurry, oversaturated, warped" # @param
>>> # Encode the prompt
>>> text_embeddings = pipe._encode_prompt(prompt, device, 1, True, negative_prompt)
>>> # Create our random starting point
>>> latents = torch.randn((1, 4, 64, 64), device=device, generator=generator)
>>> latents *= pipe.scheduler.init_noise_sigma
>>> # Prepare the scheduler
>>> pipe.scheduler.set_timesteps(num_inference_steps, device=device)
>>> # Loop through the sampling timesteps
>>> for i, t in enumerate(pipe.scheduler.timesteps):
... # Expand the latents if we are doing classifier free guidance
... latent_model_input = torch.cat([latents] * 2)
... # Apply any scaling required by the scheduler
... latent_model_input = pipe.scheduler.scale_model_input(latent_model_input, t)
... # Predict the noise residual with the UNet
... with torch.no_grad():
... noise_pred = pipe.unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
... # Perform guidance
... noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
... noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
... # Compute the previous noisy sample x_t -> x_t-1
... latents = pipe.scheduler.step(noise_pred, t, latents).prev_sample
>>> # Decode the resulting latents into an image
>>> with torch.no_grad():
... image = pipe.decode_latents(latents.detach())
>>> # View
>>> pipe.numpy_to_pil(image)[0]
在大多数情况下,使用现有的 pipeline 会更容易,但拥有这个可修改的采样循环对于理解和修改每个组件的工作方式很有用。如果你想深入了解这段代码以及所有不同组件的探索和修改,请查看“Stable Diffusion 深度剖析”notebook 和视频,以进行更详尽的探索。
其他 Pipeline
那么,除了仅仅从提示生成图像之外,我们还能做什么呢?还有很多!在本节中,我们将演示几个很酷的 pipeline,让你了解 Stable Diffusion 可以用于的一些其他任务。其中一些需要下载新模型,所以如果你时间紧迫,可以只浏览本节,看看已有的输出,而不用自己下载和运行所有模型。
Img2Img
在到目前为止的示例中,我们通过从随机潜在表示开始并应用完整的扩散采样循环来从头开始生成图像。但我们不必从头开始。Img2Img pipeline 首先将现有图像编码为一组潜在表示,然后向这些潜在表示添加一些噪声,并以此作为起点。添加的噪声量和应用的去噪步数决定了 img2img 过程的“强度”。只添加少量噪声(低强度)将导致变化很小,而添加最大量的噪声并运行完整的去噪过程将得到一个除了整体结构上的一些相似之处外,与输入图像几乎不相似的图像。
为了更好地理解 img2img 过程,让我们手动实现该 pipeline。这种方法将有助于阐明潜在表示是如何编码、噪声是如何添加以及扩散是如何应用的。在手动构建 pipeline 之后,我们将看到 diffusers 库如何提供一个即用型的 StableDiffusionImg2ImgPipeline 以实现简单和高效。
以下是你如何手动实现 img2img pipeline 的方法:
DIY Img2Img 循环
import numpy as np
# Encode init_image
init_image_tensor = torch.from_numpy(np.array(init_image).transpose(2, 0, 1)).float() / 255.0 # 0~255 => 0~1
init_image_tensor = 2.0 * init_image_tensor - 1.0 # 0~1 => -1~1
init_image_tensor = init_image_tensor.unsqueeze(0).to(device) # add batch dim.
with torch.no_grad():
init_image_latents = pipe.vae.encode(init_image_tensor).latent_dist.sample() * pipe.vae.config.scaling_factor>>> guidance_scale = 7.5 # @param
>>> num_inference_steps = 30 # @param
>>> strength = 0.6
>>> prompt = "An oil painting of a man on a bench" # @param
>>> # Encode the prompt
>>> text_embeddings = pipe._encode_prompt(prompt, device, 1, True, "")
>>> # Prepare the scheduler
>>> pipe.scheduler.set_timesteps(num_inference_steps, device=device)
>>> # Prepare latent variables
>>> # We don't use all timesteps in the noise scheduler.
>>> # Calculate a subset of timesteps based on `strength` to apply to the initial image.
>>> init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
>>> t_start = max(num_inference_steps - init_timestep, 0)
>>> timesteps = pipe.scheduler.timesteps[t_start:]
>>> # The first timestep of the new timesteps will be the starting point for adding noise to the initial image.
>>> latent_timestep = timesteps[:1]
>>> # Add noise to init_image_latents at the noise level specified by latent_timestep.
>>> noise = torch.randn((1, 4, 64, 64), device=device, generator=torch.Generator(device=device).manual_seed(42))
>>> latents = pipe.scheduler.add_noise(init_image_latents, noise, latent_timestep)
>>> # Loop through the sampling timesteps
>>> for i, t in enumerate(timesteps):
... # Expand the latents if we are doing classifier free guidance
... latent_model_input = torch.cat([latents] * 2)
... # Apply any scaling required by the scheduler
... latent_model_input = pipe.scheduler.scale_model_input(latent_model_input, t)
... # Predict the noise residual with the UNet
... with torch.no_grad():
... noise_pred = pipe.unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
... # Perform guidance
... noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
... noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
... # Compute the previous noisy sample x_t -> x_t-1
... latents = pipe.scheduler.step(noise_pred, t, latents).prev_sample
>>> # Decode latents
>>> latents_norm = latents / pipe.vae.config.scaling_factor
>>> with torch.no_grad():
... result_image = pipe.vae.decode(latents_norm).sample
>>> result_image = (result_image / 2 + 0.5).clamp(0, 1).squeeze()
>>> result_image = (result_image.permute(1, 2, 0) * 255).to(torch.uint8).cpu().numpy()
>>> result_image = Image.fromarray(result_image)
>>> # View the result
>>> fig, axs = plt.subplots(1, 2, figsize=(12, 5))
>>> axs[0].imshow(init_image)
>>> axs[0].set_title("Input Image")
>>> axs[1].imshow(result_image)
>>> axs[1].set_title("Result")
现在我们已经手动实现了 img2img 过程,让我们看看如何使用 diffusers 库提供的 StableDiffusionImg2ImgPipeline 更高效地实现相同的结果。
此 pipeline 不需要特殊的模型,所以只要模型 ID 与我们上面的文生图示例相同,就不需要下载新文件。
Img2Img Pipeline
# Loading an Img2Img pipeline
model_id = "stabilityai/stable-diffusion-2-1-base"
img2img_pipe = StableDiffusionImg2ImgPipeline.from_pretrained(model_id).to(device)在“设置”部分,我们加载了一个示例 init_image 用于此演示,但如果你愿意,可以将其替换为你自己的图像。下面是 pipeline 的实际运行情况:
>>> # Apply Img2Img
>>> result_image = img2img_pipe(
... prompt="An oil painting of a man on a bench",
... image=init_image, # The starting image
... strength=0.6, # 0 for no change, 1.0 for max strength
... ).images[0]
>>> # View the result
>>> fig, axs = plt.subplots(1, 2, figsize=(12, 5))
>>> axs[0].imshow(init_image)
>>> axs[0].set_title("Input Image")
>>> axs[1].imshow(result_image)
>>> axs[1].set_title("Result")
练习: 实验这个 pipeline。尝试你自己的图像,或玩转不同的强度和提示。你可以使用许多与文生图 pipeline 相同的参数,所以可以随意尝试不同的尺寸、步数等。
In-Painting(图像修复)
如果我们想保持输入图像的某些部分不变,但在其他部分生成新的内容呢?这被称为“inpainting”(图像修复)。虽然这可以用与之前演示相同的模型(通过 StableDiffusionInpaintPipelineLegacy)来完成,但我们可以通过使用一个定制微调的 Stable Diffusion 版本来获得更好的结果,该版本将蒙版图像和蒙版本身作为额外的条件。蒙版图像应与输入图像形状相同,要替换的区域为白色,要保留的区域为黑色。
为了更深入地了解 inpainting 过程,让我们手动实现 StableDiffusionInpaintPipelineLegacy 背后的逻辑。这种方法将阐明 inpainting 在较低层面上的工作原理,并提供对 Stable Diffusion 如何处理输入的见解。完成此操作后,我们将探索微调的 pipeline 以进行比较。以下是如何手动实现 inpainting pipeline 并将其应用于在“设置”部分加载的示例图像和蒙版的方法:

DIY Inpainting 循环
>>> # Resize mask image
>>> mask_image_latent_size = mask_image.resize((64, 64))
>>> mask_image_latent_size = torch.tensor((np.array(mask_image_latent_size)[..., 0] > 5).astype(np.float32))
>>> plt.imshow(mask_image_latent_size.numpy(), cmap="gray")
>>> mask_image_latent_size = mask_image_latent_size.to(device)
>>> mask_image_latent_size.shape
再次编写去噪循环。
>>> guidance_scale = 8 # @param
>>> num_inference_steps = 30 # @param
>>> prompt = "A small robot, high resolution, sitting on a park bench"
>>> negative_prompt = "zoomed in, blurry, oversaturated, warped"
>>> generator = torch.Generator(device=device).manual_seed(42)
>>> # Encode the prompt
>>> text_embeddings = pipe._encode_prompt(prompt, device, 1, True, negative_prompt)
>>> # Create our random starting point
>>> latents = torch.randn((1, 4, 64, 64), device=device, generator=generator)
>>> latents *= pipe.scheduler.init_noise_sigma
>>> # Prepare the scheduler
>>> pipe.scheduler.set_timesteps(num_inference_steps, device=device)
>>> for i, t in enumerate(pipe.scheduler.timesteps):
... # Expand the latents if we are doing classifier free guidance
... latent_model_input = torch.cat([latents] * 2)
... # Apply any scaling required by the scheduler
... latent_model_input = pipe.scheduler.scale_model_input(latent_model_input, t)
... # Predict the noise residual with the UNet
... with torch.no_grad():
... noise_pred = pipe.unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
... # Perform guidance
... noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
... noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
... # Compute the previous noisy sample x_t -> x_t-1
... latents = pipe.scheduler.step(noise_pred, t, latents, return_dict=False)[0]
... # Perform inpainting to fill in the masked areas
... if i < len(pipe.scheduler.timesteps) - 1:
... # Add noise to the original image's latent at the previous timestep t-1
... noise = torch.randn(init_image_latents.shape, generator=generator, device=device, dtype=torch.float32)
... background = pipe.scheduler.add_noise(
... init_image_latents, noise, torch.tensor([pipe.scheduler.timesteps[i + 1]])
... )
... latents = latents * mask_image_latent_size # white in the areas
... background = background * (1 - mask_image_latent_size) # black in the areas
... # Combine the generated and original image latents based on the mask
... latents += background
>>> # Decode latents
>>> latents_norm = latents / pipe.vae.config.scaling_factor
>>> with torch.no_grad():
... inpainted_image = pipe.vae.decode(latents_norm).sample
>>> inpainted_image = (inpainted_image / 2 + 0.5).clamp(0, 1).squeeze()
>>> inpainted_image = (inpainted_image.permute(1, 2, 0) * 255).to(torch.uint8).cpu().numpy()
>>> inpainted_image = Image.fromarray(inpainted_image)
>>> inpainted_image
Inpainting Pipeline
现在我们已经手动实现了 inpainting 逻辑,让我们看看如何使用专为 inpainting 任务设计的微调 pipeline。下面是如何加载这样一个 pipeline 并将其应用于在“设置”部分加载的示例图像和蒙版:
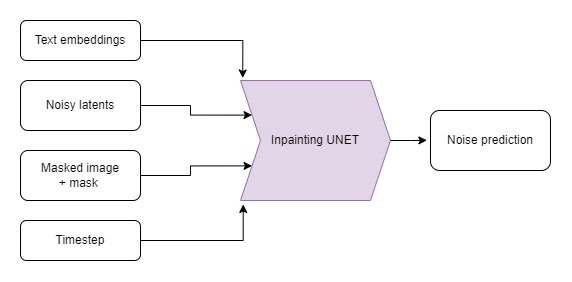
# Load the inpainting pipeline (requires a suitable inpainting model)
# pipe = StableDiffusionInpaintPipeline.from_pretrained("runwayml/stable-diffusion-inpainting")
# "runwayml/stable-diffusion-inpainting" is no longer available.
# Therefore, we are using the "stabilityai/stable-diffusion-2-inpainting" model instead.
pipe = StableDiffusionInpaintPipeline.from_pretrained("stabilityai/stable-diffusion-2-inpainting")
pipe = pipe.to(device)>>> # Inpaint with a prompt for what we want the result to look like
>>> prompt = "A small robot, high resolution, sitting on a park bench"
>>> image = pipe(prompt=prompt, image=init_image, mask_image=mask_image).images[0]
>>> # View the result
>>> fig, axs = plt.subplots(1, 3, figsize=(16, 5))
>>> axs[0].imshow(init_image)
>>> axs[0].set_title("Input Image")
>>> axs[1].imshow(mask_image)
>>> axs[1].set_title("Mask")
>>> axs[2].imshow(image)
>>> axs[2].set_title("Result")
当与其他模型结合以自动生成蒙版时,这可能特别强大。例如,这个演示空间使用一个名为 CLIPSeg 的模型,根据文本描述来遮盖要替换的对象。
补充:管理你的模型缓存
探索不同的 pipeline 和模型变体可能会占满你的磁盘空间。你可以用以下命令查看当前下载了哪些模型:
>>> !ls ~/.cache/huggingface/hub/ # List the contents of the cache directorymodels--CompVis--stable-diffusion-v1-4 models--ddpm-bedroom-256 models--google--ddpm-bedroom-256 models--google--ddpm-celebahq-256 models--runwayml--stable-diffusion-inpainting models--stabilityai--stable-diffusion-2-1-base
请查看关于缓存的文档,了解如何有效地查看和管理你的缓存。
Depth2Image
输入图像、深度图像和生成的示例(图片来源:StabilityAI)
Img2Img 很棒,但有时我们想创建一个具有原始构图但颜色或纹理完全不同的新图像。很难找到一个既能保留我们想要的布局,又不会保留输入颜色的 Img2Img 强度。
是时候使用另一个微调模型了!这个模型在生成时将深度信息作为额外的条件。该 pipeline 使用一个深度估计模型来创建深度图,然后将其输入到微调的 UNet 中,以(希望)在生成图像时保留初始图像的深度和结构,同时填充全新的内容。
# Load the Depth2Img pipeline (requires a suitable model)
pipe = StableDiffusionDepth2ImgPipeline.from_pretrained("stabilityai/stable-diffusion-2-depth")
pipe = pipe.to(device)>>> # Inpaint with a prompt for what we want the result to look like
>>> prompt = "An oil painting of a man on a bench"
>>> image = pipe(prompt=prompt, image=init_image).images[0]
>>> # View the result
>>> fig, axs = plt.subplots(1, 2, figsize=(16, 5))
>>> axs[0].imshow(init_image)
>>> axs[0].set_title("Input Image")
>>> axs[1].imshow(image)
>>> axs[1].set_title("Result")
注意输出与 img2img 示例的比较——这里有更多的颜色变化,但整体结构仍然忠实于原始图像。在这种情况下,这并不理想,因为为了匹配狗的形状,这个男人的身体结构变得非常奇怪,但在某些情况下,这非常有用。有关此方法的“杀手级应用”示例,请查看这条推文,它展示了如何使用深度模型为 3D 场景添加纹理!
下一步去哪儿?
希望这让你体验到了 Stable Diffusion 的许多功能!一旦你玩腻了这个 notebook 中的示例,可以查看 DreamBooth 黑客松 notebook,了解如何微调你自己的 Stable Diffusion 版本,该版本可用于我们在这里看到的文生图或图生图 pipeline。
如果你想更深入地了解不同组件的工作原理,请查看 Stable Diffusion 深度剖析 notebook,它会更详细地介绍并展示一些我们可以做的额外技巧。
请务必与我们和社区分享你的创作!
< > 在 GitHub 上更新