扩散模型课程文档
第 4 单元:深入了解扩散模型
并获得增强的文档体验
开始使用
第 4 单元:深入了解扩散模型
欢迎来到 Hugging Face 扩散模型课程的第 4 单元!在本单元中,我们将探讨最新研究中出现的对扩散模型的诸多改进和扩展。与之前的单元相比,本单元的代码量会少一些,旨在为您提供进一步研究的起点。
开始本单元 :rocket:
以下是本单元的步骤:
- 请确保您已经注册本课程,以便在课程增加新单元时收到通知。
- 请通读以下材料,了解本单元涵盖的不同主题的概览。
- 通过链接的视频和资源,深入研究任何特定的主题。
- 探索演示笔记本,然后阅读“下一步”部分,了解一些项目建议。
:loudspeaker: 别忘了加入 Discord,您可以在 #diffusion-models-class 频道中讨论课程材料并分享您的创作。
目录
通过蒸馏加速采样
渐进式蒸馏是一种技术,它利用现有的扩散模型来训练一个新版本的模型,这个新模型在推理时需要更少的步骤。“学生”模型的权重从“教师”模型的权重初始化。在训练过程中,教师模型执行两个采样步骤,学生模型则尝试在一个步骤内匹配最终的预测结果。这个过程可以重复多次,前一次迭代的学生模型成为下一阶段的教师模型。最终得到的模型可以在比原始教师模型少得多的步骤(通常是 4 或 8 步)内生成质量不错的样本。其核心机制在提出该想法的论文中的这张图中有所说明。
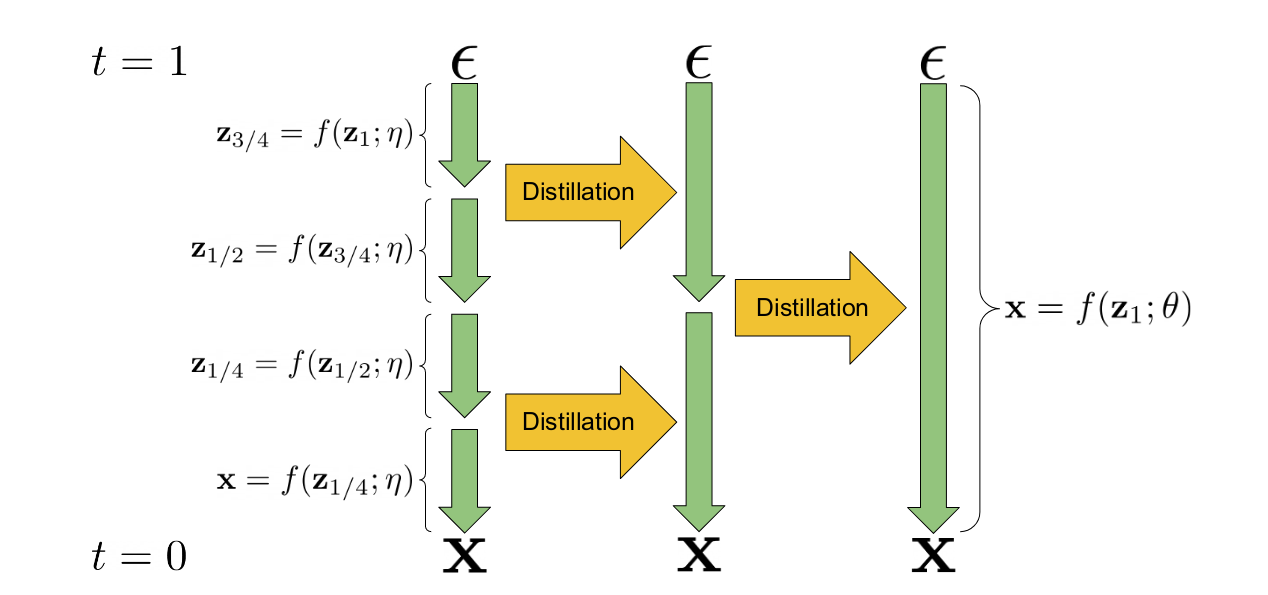
渐进式蒸馏图解(来自论文)
利用现有模型来“教导”新模型的想法可以扩展到创建引导模型,其中教师模型使用无分类器引导技术,而学生模型必须学会在一个步骤内,根据指定目标引导尺度的额外输入,产生等效的输出。这进一步减少了生成高质量样本所需的模型评估次数。这段视频概述了这种方法。
注意:Stable Diffusion 的蒸馏版本可以在这里使用。
关键参考文献
- 用于快速采样扩散模型的渐进式蒸馏(Progressive Distillation For Fast Sampling Of Diffusion Models)
- 关于引导扩散模型的蒸馏(On Distillation Of Guided Diffusion Models)
训练改进
为了改进扩散模型的训练,已经开发了一些额外的技巧。在本节中,我们试图捕捉近期论文中的核心思想。不断有研究涌现出更多的改进,所以如果您看到一篇您认为应该加在这里的论文,请告诉我们!
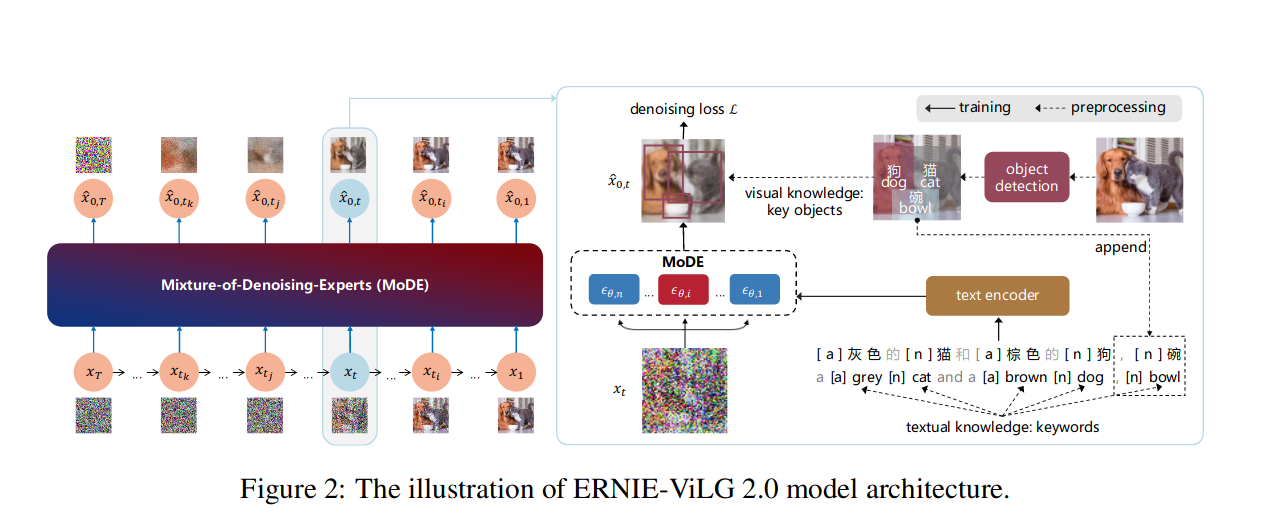 图 2 来自 ERNIE-ViLG 2.0 论文
图 2 来自 ERNIE-ViLG 2.0 论文
关键训练改进
- 调整噪声调度、损失权重和采样轨迹以实现更高效的训练。Karras 等人撰写的《阐明基于扩散的生成模型的设计空间》(Elucidating the Design Space of Diffusion-Based Generative Models)是一篇探讨这些设计选择的优秀论文。
- 在多种宽高比上进行训练,如课程发布会上的这段视频所述。
- 级联扩散模型,即先训练一个低分辨率模型,然后再训练一个或多个超分辨率模型。这种方法被用于 DALLE-2、Imagen 等模型中以生成高分辨率图像。
- 更好的条件设置,整合丰富的文本嵌入(Imagen 使用了一个名为 T5 的大型语言模型)或多种类型的条件(eDiffi)。
- “知识增强”——在训练过程中整合预训练的图像字幕和物体检测模型,以创建信息更丰富的字幕并产生更好的性能(ERNIE-ViLG 2.0)。
- “去噪专家混合”(MoDE)——为不同的噪声水平训练模型的不同变体(“专家”),如上图 ERNIE-ViLG 2.0 论文中的插图所示。
关键参考文献
- 阐明基于扩散的生成模型的设计空间(Elucidating the Design Space of Diffusion-Based Generative Models)
- eDiffi: 具有专家去噪器集成的文本到图像扩散模型(eDiffi: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers)
- ERNIE-ViLG 2.0: 利用知识增强的去噪专家混合改进文本到图像扩散模型(ERNIE-ViLG 2.0: Improving Text-to-Image Diffusion Model with Knowledge-Enhanced Mixture-of-Denoising-Experts)
- Imagen - 具有深度语言理解的逼真文本到图像扩散模型(演示网站)
对生成和编辑的更多控制
除了训练方面的改进,采样和推理阶段也出现了几项创新,其中许多方法可以为现有的扩散模型增加新功能。
 由“词语作画”(paint-with-words)生成的样本(eDiffi)
由“词语作画”(paint-with-words)生成的样本(eDiffi)
视频“使用扩散模型编辑图像”概述了使用扩散模型编辑现有图像的不同方法。可用的技术可以分为四个主要类别:
1) 添加噪声,然后用新的提示进行去噪。这是 img2img 工作流背后的思想,该思想在各种论文中得到了修改和扩展。
- SDEdit 和 MagicMix 建立在这一思想之上。
- DDIM 反演(TODO 链接教程)使用模型来“反转”采样轨迹,而不是添加随机噪声,从而实现更好的控制。
- 空文本反演通过在每一步优化用于无分类器引导的无条件文本嵌入,极大地提升了这类方法的性能,实现了极高质量的基于文本的图像编辑。 2) 扩展(1)中的思想,但使用蒙版来控制效果的应用位置。
- 混合扩散(Blended Diffusion)介绍了这个基本思想。
- 这个演示使用现有的分割模型(CLIPSeg)根据文本描述创建蒙版。
- DiffEdit 是一篇优秀的论文,展示了如何使用扩散模型本身来生成适当的蒙版,以根据文本编辑图像。
- SmartBrush:文本和形状引导的物体修复与扩散模型(SmartBrush: Text and Shape Guided Object Inpainting with Diffusion Model)对扩散模型进行了微调,以实现更准确的蒙版引导修复。 3) 交叉注意力控制:利用扩散模型中的交叉注意力机制来控制编辑的空间位置,以实现更精细的控制。
- 使用交叉注意力控制进行提示到提示的图像编辑(Prompt-to-Prompt Image Editing with Cross Attention Control)是介绍这一思想的关键论文,该技术后来被应用于 Stable Diffusion。
- 这个思想也用于“词语作画”(eDiffi,如上图所示)。 4) 在单个图像上进行微调(“过拟合”),然后使用微调后的模型进行生成。以下论文几乎同时发表了该思想的变体:
- Imagic:基于文本的真实图像编辑与扩散模型.
- UniTune:通过在单个图像上微调图像生成模型实现文本驱动的图像编辑.
论文InstructPix2Pix: 学习遵循图像编辑指令值得注意,因为它使用了一些上述图像编辑技术来构建一个包含图像对和图像编辑指令(由 GPT3.5 生成)的合成数据集,以训练一个能够根据自然语言指令编辑图像的新模型。
视频
 来自 Imagen Video 生成的示例视频的静止帧
来自 Imagen Video 生成的示例视频的静止帧
视频可以表示为图像序列,扩散模型的核心思想可以应用于这些序列。最近的研究集中在寻找合适的架构(例如作用于整个序列的“3D UNet”)以及高效处理视频数据。由于高帧率视频比静态图像涉及更多的数据,目前的方法倾向于首先生成低分辨率和低帧率的视频,然后应用空间和时间上的超分辨率来产生最终的高质量视频输出。
关键参考文献
- 视频扩散模型(Video Diffusion Models)
- IMAGEN VIDEO: 使用扩散模型进行高清视频生成(IMAGEN VIDEO: HIGH DEFINITION VIDEO GENERATION WITH DIFFUSION MODELS)
音频
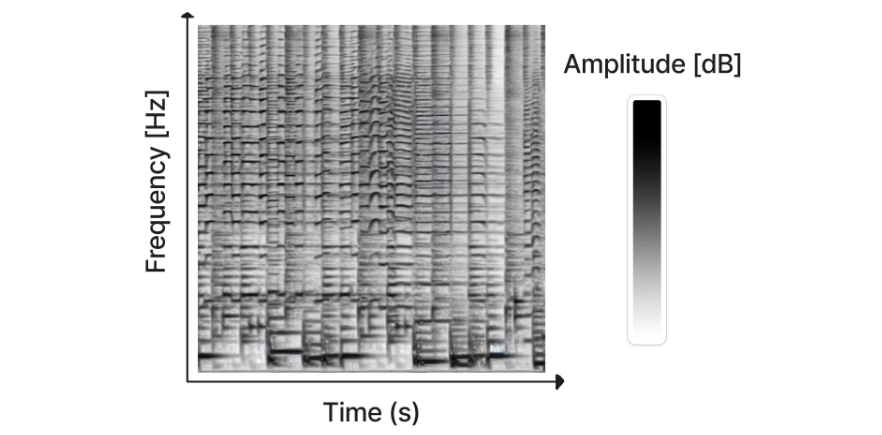
Riffusion 生成的频谱图(图片来源)
虽然已经有一些工作直接使用扩散模型生成音频(例如 DiffWave),但迄今为止最成功的方法是将音频信号转换成一种叫做频谱图的东西,它有效地将音频“编码”成一个二维“图像”,然后可以用来训练我们习惯于用于图像生成的那种扩散模型。生成的频谱图随后可以使用现有方法转换回音频。最近发布的 Riffusion 就是基于这种方法,它对 Stable Diffusion 进行了微调,以根据文本生成频谱图 - 点击这里试用。
音频生成领域发展极其迅速。在过去的一周里(在撰写本文时),至少有 5 项新进展被宣布,这些进展在下面的列表中用星号标记。
关键参考文献
- DiffWave: 一个用于音频合成的多功能扩散模型
- “Riffusion”(以及代码)
- *谷歌的 MusicLM 可以根据文本生成连贯的音频,并且可以用哼唱或吹口哨的旋律作为条件。
- *RAVE2 - 一种新版本的变分自编码器,可用于音频任务的潜在扩散。这在即将发布的 *AudioLDM 模型中被使用。
- *Noise2Music - 一个经过训练的扩散模型,可根据文本描述生成高质量的 30 秒音频片段。
- *Make-An-Audio: 基于提示增强扩散模型的文本到音频生成 - 一个经过训练的扩散模型,可根据文本生成多样的声音。
- *Moûsai: 基于长上下文潜在扩散的文本到音乐生成
新的架构和方法 - 迈向“迭代优化”

冷扩散(Cold Diffusion)论文中的图 1
我们正在逐渐超越“扩散”模型最初的狭隘定义,迈向一类更通用的模型,这些模型执行迭代优化,即通过逐步逆转某种形式的损坏(如前向扩散过程中的高斯噪声添加)来生成样本。“冷扩散”论文证明,许多其他类型的损坏也可以被迭代地“撤销”以生成图像(如上图所示),而最近基于 Transformer 的方法已经证明了令牌替换或掩码作为加噪策略的有效性。
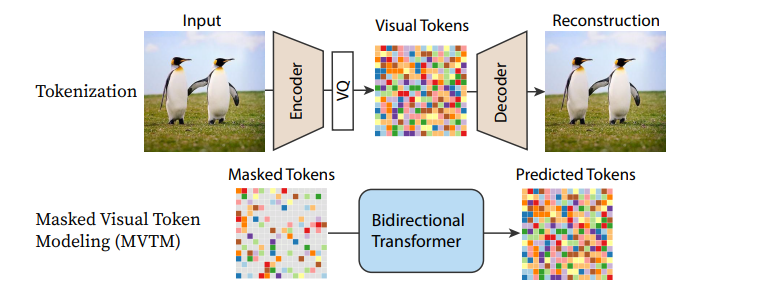
MaskGIT 的流程图
作为许多现有扩散模型核心的 UNet 架构也正在被不同的替代方案所取代,其中最引人注目的是各种基于 Transformer 的架构。在使用 Transformer 的可扩展扩散模型(DiT)中,一个 Transformer 被用来替代 UNet,用于一个相当标准的扩散模型方法,并取得了优异的结果。循环接口网络(Recurrent Interface Networks)应用了一种新颖的基于 Transformer 的架构和训练策略,以追求更高的效率。MaskGIT 和 MUSE 使用 Transformer 模型来处理图像的标记化表示,尽管 Paella 模型证明 UNet 也可以成功地应用于这些基于标记的范式中。
随着每一篇新论文的发表,更高效的方法正在被开发出来,可能还需要一段时间我们才能看到这类迭代优化任务的性能巅峰。还有很多东西有待探索!
关键参考文献
- 冷扩散:无噪声地反转任意图像变换
- 使用 Transformer 的可扩展扩散模型 (DiT)
- MaskGIT: 掩码生成式图像 Transformer
- Muse: 通过掩码生成式 Transformer 实现文本到图像生成
- 在向量量化潜在空间上的快速文本条件离散去噪 (Paella)
- 循环接口网络 - 一种有前途的新架构,在不依赖潜在扩散或超分辨率的情况下,能很好地生成高分辨率图像。另见 简单扩散:端到端的用于高分辨率图像的扩散模型,该文强调了噪声调度对于在更高分辨率下训练的重要性。
动手实践笔记本
| 章节 | Colab | Kaggle | Gradient | Studio Lab |
|---|---|---|---|---|
| DDIM 反演 |  |  | ||
| 音频扩散 | | |
在本单元中,我们已经涵盖了非常多的不同思想,其中许多都值得在未来开设更详细的后续课程。目前,您可以通过我们准备的动手实践笔记本选择两个主题进行学习。
- DDIM 反演展示了如何使用一种称为反演的技术来编辑使用现有扩散模型的图像。
- 音频扩散介绍了频谱图的概念,并展示了一个在特定音乐流派上微调音频扩散模型的最小示例。
下一步?
这是本课程目前的最后一个单元,这意味着接下来要学什么取决于您!请记住,您可以随时在 Hugging Face 的 Discord 上提问和讨论您的项目。我们期待看到您的创作 🤗。
< > 在 GitHub 上更新