google-cloud 文档
在 Vertex AI 上使用 TEI DLC 部署 Embedding 模型
并获得增强的文档体验
开始使用
在 Vertex AI 上使用 TEI DLC 部署 Embedding 模型
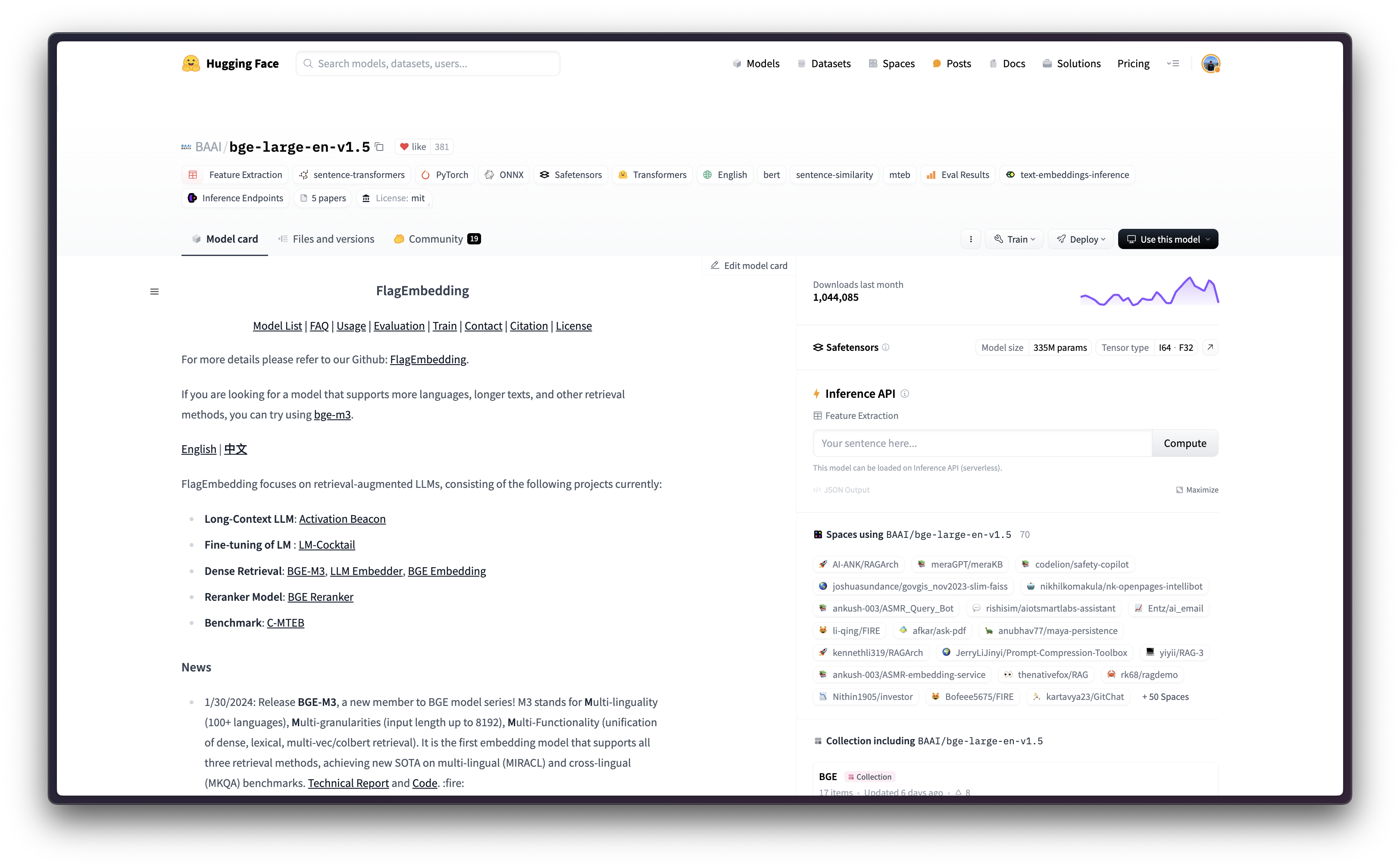
BGE(BAAI General Embedding 的缩写)是 BAAI 发布的一系列 Embedding 模型,它是一个用于通用 Embedding 任务的英语基础模型,在 MTEB 排行榜中名列前茅。Text Embeddings Inference (TEI) 是 Hugging Face 开发的一个工具包,用于部署和提供开源文本 Embedding 和序列分类模型;它能够为最流行的模型(包括 FlagEmbedding、Ember、GTE 和 E5)实现高性能提取。此外,Google Vertex AI 是一个机器学习 (ML) 平台,可让您训练和部署 ML 模型和 AI 应用程序,并自定义大型语言模型 (LLM) 以用于您的 AI 驱动应用程序。
本示例展示了如何使用 Google Cloud Platform (GCP) 中提供的 TEI DLC,在 CPU 和 GPU 实例中,将任何受支持的 Embedding 模型(本例中为 BAAI/bge-large-en-v1.5)从 Hugging Face Hub 部署到 Vertex AI。
设置 / 配置
首先,您需要在本地计算机上安装 gcloud,它是 Google Cloud 的命令行工具,请按照 Cloud SDK 文档 - 安装 gcloud CLI 中的说明进行操作。
然后,您还需要安装 google-cloud-aiplatform Python SDK,这是以编程方式创建 Vertex AI 模型、注册模型、创建端点并在 Vertex AI 上部署模型所需的。
!pip install --upgrade --quiet google-cloud-aiplatform
或者,为了简化本教程中命令的使用,您需要为 GCP 设置以下环境变量
%env PROJECT_ID=your-project-id
%env LOCATION=your-location
%env CONTAINER_URI=us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-text-embeddings-inference-cu122.1-4.ubuntu2204然后您需要登录您的 GCP 帐户,并将项目 ID 设置为您想要用于在 Vertex AI 上注册和部署模型的项目 ID。
!gcloud auth login
!gcloud auth application-default login # For local development
!gcloud config set project $PROJECT_ID登录后,您需要启用 GCP 中必要的服务 API,例如 Vertex AI API、Compute Engine API 和 Google Container Registry 相关 API。
!gcloud services enable aiplatform.googleapis.com !gcloud services enable compute.googleapis.com !gcloud services enable container.googleapis.com !gcloud services enable containerregistry.googleapis.com !gcloud services enable containerfilesystem.googleapis.com
在 Vertex AI 上注册模型
一切设置完成后,您就可以通过 google-cloud-aiplatform Python SDK 初始化 Vertex AI 会话,如下所示
import os
from google.cloud import aiplatform
aiplatform.init(
project=os.getenv("PROJECT_ID"),
location=os.getenv("LOCATION"),
)然后您可以“上传”模型,即在 Vertex AI 上注册模型。这本身并不是一个上传,因为模型将通过 MODEL_ID 环境变量在启动时自动从 Hugging Face Hub 中的 Hugging Face TEI DLC 下载,因此上传的只是配置,而不是模型权重。
在深入代码之前,我们先快速回顾一下提供给 upload 方法的参数
display_name是将在 Vertex AI 模型注册表中显示的名称。serving_container_image_uri是用于提供模型服务的 Hugging Face TEI DLC 的位置。serving_container_environment_variables是将在容器运行时使用的环境变量,因此这些环境变量与text-embeddings-inference定义的环境变量保持一致,它们与text-embeddings-router参数类似。此外,Hugging Face TEI DLCs 还像 Vertex AI 文档 - 预测的自定义容器要求 中那样捕获来自 Vertex AI 的AIP_环境变量。MODEL_ID是 Hugging Face Hub 中模型的标识符,要查看所有 TEI 支持的模型,请访问 https://huggingface.co/models?other=text-embeddings-inference&sort=trending。
(可选)
serving_container_ports是 Vertex AI 端点将暴露的端口,默认为 8080。
有关受支持的 aiplatform.Model.upload 参数的更多信息,请查看其 Python 参考文档:https://cloud.google.com/python/docs/reference/aiplatform/latest/google.cloud.aiplatform.Model#google_cloud_aiplatform_Model_upload。
model = aiplatform.Model.upload(
display_name="BAAI--bge-large-en-v1.5",
serving_container_image_uri=os.getenv("CONTAINER_URI"),
serving_container_environment_variables={
"MODEL_ID": "BAAI/bge-large-en-v1.5",
},
serving_container_ports=[8080],
)
model.wait()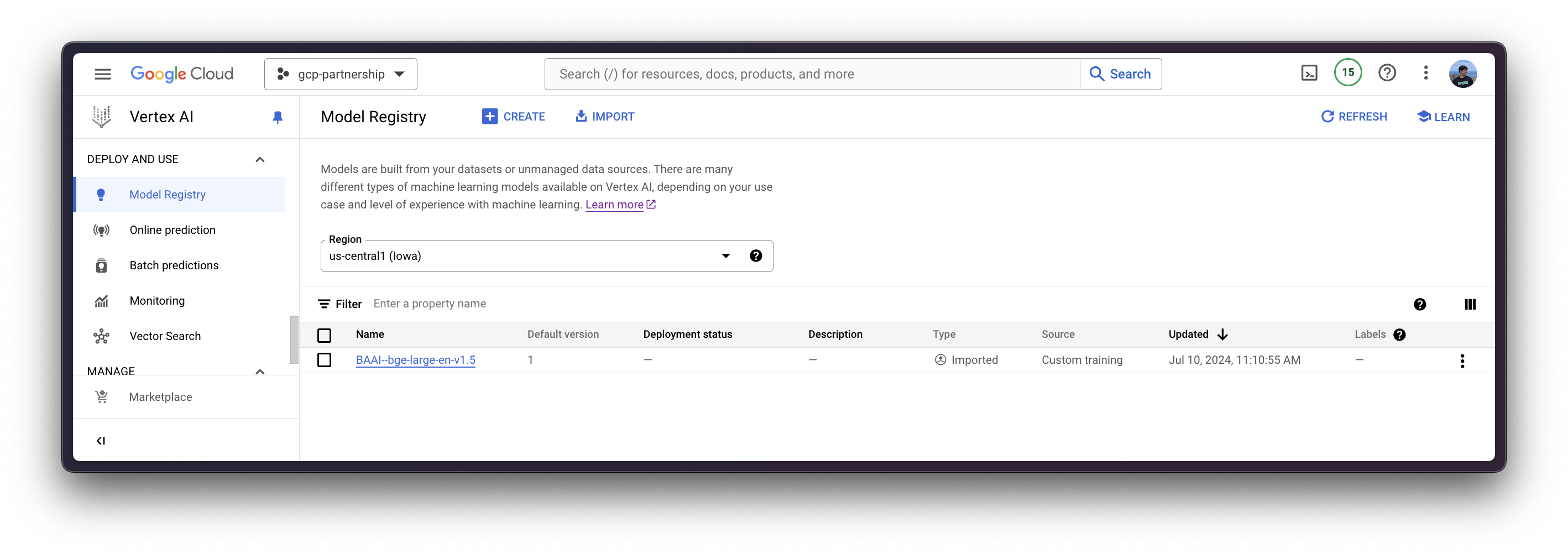
在 Vertex AI 上部署模型
在 Vertex AI 上注册模型后,您需要定义要将模型部署到的端点,然后将模型部署链接到该端点资源。
为此,您需要调用 aiplatform.Endpoint.create 方法来创建一个新的 Vertex AI 端点资源(该资源尚未链接到模型或任何可用的东西)。
endpoint = aiplatform.Endpoint.create(display_name="BAAI--bge-large-en-v1.5-endpoint")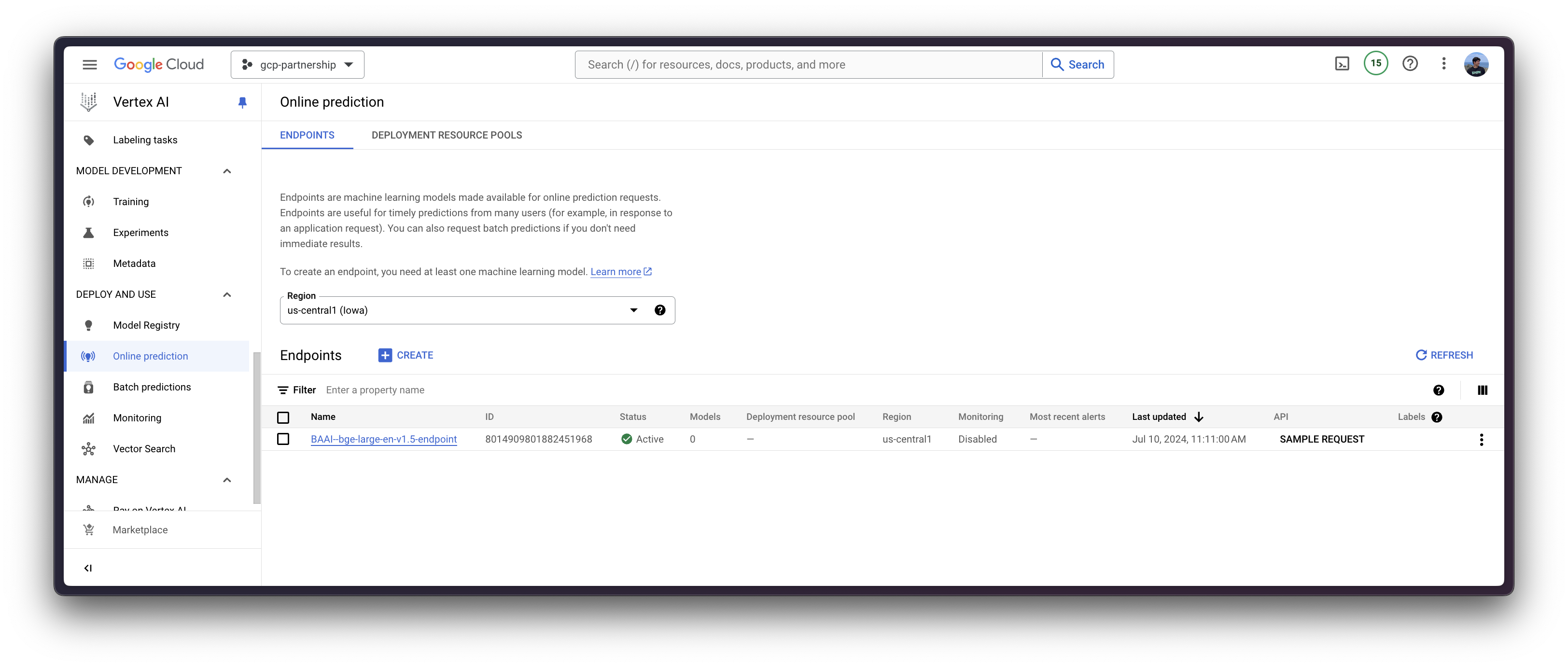
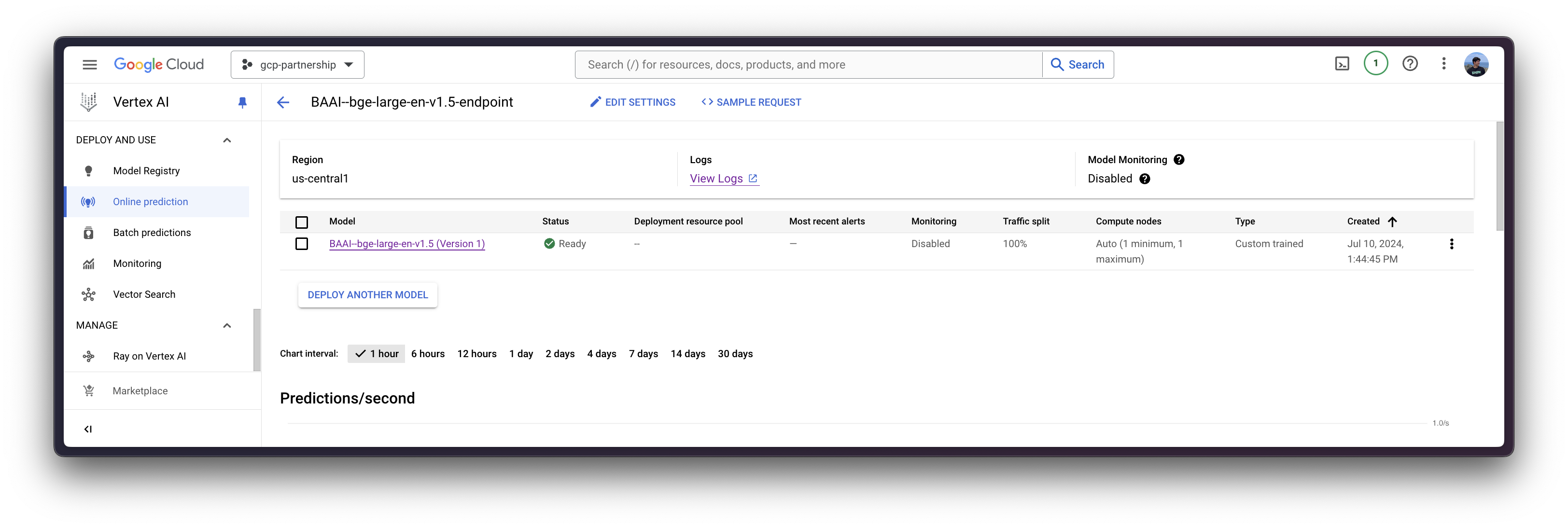
现在您可以在 Vertex AI 上的端点中部署已注册的模型。
deploy 方法会将之前创建的端点资源与包含服务容器配置的模型链接起来,然后将其部署到指定实例的 Vertex AI 上。
在深入代码之前,我们先快速回顾一下提供给 deploy 方法的参数
endpoint是要将模型部署到的端点,它是可选的,默认情况下将设置为模型显示名称加上_endpoint后缀。machine_type、accelerator_type和accelerator_count是用于定义要使用的实例、加速器以及加速器数量的参数。machine_type和accelerator_type是关联的,因此您需要选择一个支持您正在使用的加速器的实例,反之亦然。有关不同实例的更多信息,请参见 Compute Engine 文档 - GPU 机器类型;有关accelerator_type命名的更多信息,请参见 Vertex AI 文档 - MachineSpec。
有关受支持的 aiplatform.Model.deploy 参数的更多信息,请查看其 Python 参考文档:https://cloud.google.com/python/docs/reference/aiplatform/latest/google.cloud.aiplatform.Model#google_cloud_aiplatform_Model_deploy。
deployed_model = model.deploy(
endpoint=endpoint,
machine_type="g2-standard-4",
accelerator_type="NVIDIA_L4",
accelerator_count=1,
sync=True,
)通过 deploy 方法部署 Vertex AI 端点可能需要 15 到 25 分钟。
Vertex AI 上的在线预测
最后,您可以使用 predict 方法在 Vertex AI 上运行在线预测,该方法将根据 Vertex AI I/O 负载格式,向容器内指定的 /predict 路由中的运行中端点发送请求。
output = deployed_model.predict(instances=[{"inputs": "What is Deep Learning?"}])
print(output.predictions[0][0][:5], len(output.predictions[0][0])这会产生以下输出(为简洁起见已截断,但原始张量长度为 1024,这是 BAAI/bge-large-en-v1.5 的 Embedding 维度)
([0.018108826, 0.0029993146, -0.04984767, -0.035081815, 0.014210845], 1024)
资源清理
最后,您可以在同一个 Python 会话中以编程方式释放资源,如下所示:
deployed_model.undeploy_all用于从所有端点取消部署模型。deployed_model.delete在undeploy_all之后优雅地删除部署模型的端点。model.delete用于从注册表中删除模型。
deployed_model.undeploy_all() deployed_model.delete() model.delete()
📍 在 GitHub 此处 找到完整的示例!