google-cloud 文档
在 Vertex AI 上使用 TGI DLC 部署 Gemma 7B
并获得增强的文档体验
开始使用
在 Vertex AI 上使用 TGI DLC 部署 Gemma 7B
Gemma 是由 Google DeepMind 和 Google 其他团队开发的轻量级、最先进的开放模型系列,它们采用与 Gemini 模型相同的研究和技术构建。Text Generation Inference (TGI) 是 Hugging Face 开发的工具包,用于部署和提供 LLM,具有高性能的文本生成能力。Google Vertex AI 是一个机器学习 (ML) 平台,可让您训练和部署 ML 模型和 AI 应用程序,并自定义大型语言模型 (LLM) 以用于您的 AI 驱动应用程序。
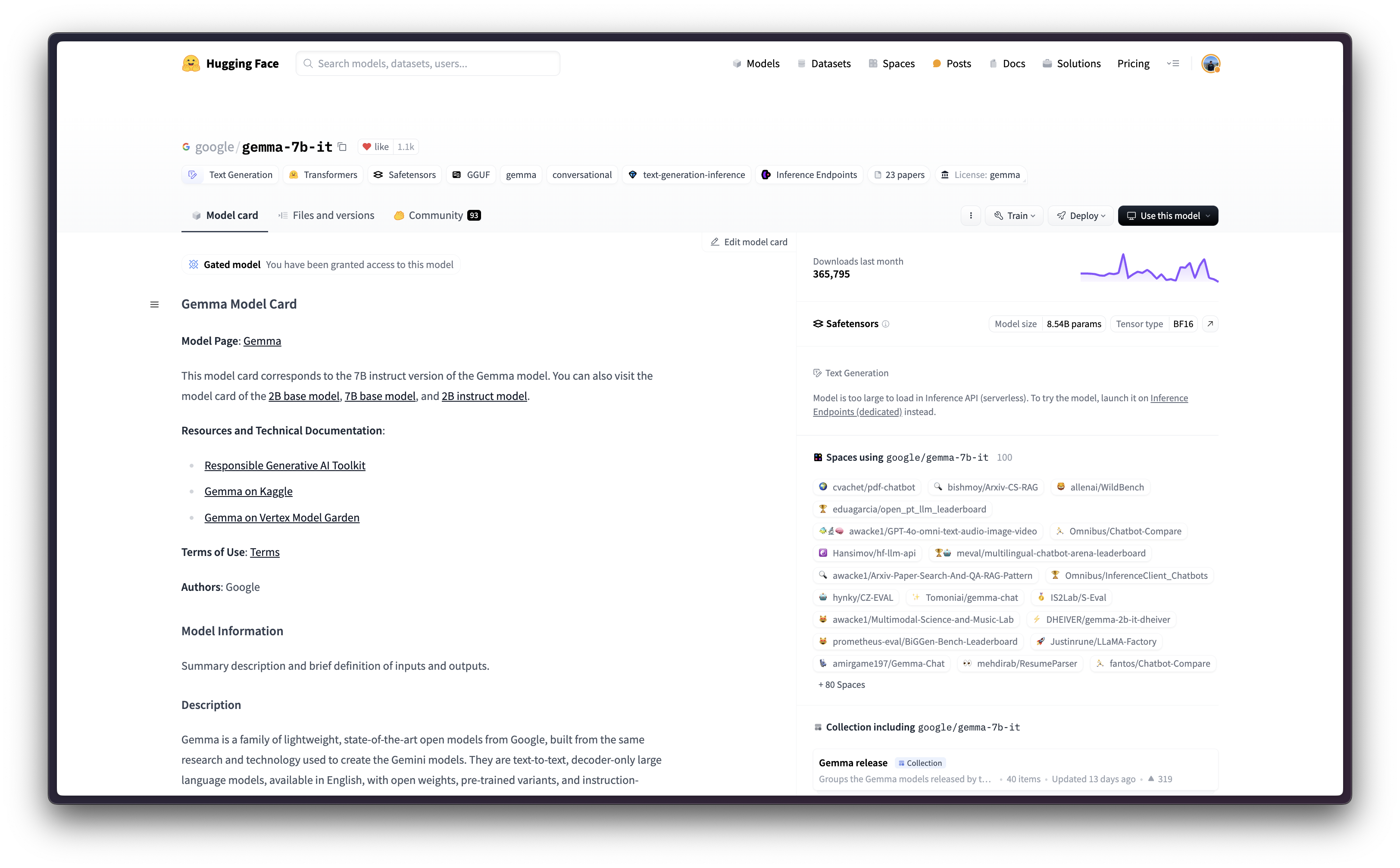
本示例展示了如何使用 Google Cloud Platform (GCP) 中提供的 TGI DLC,将 Hugging Face Hub 中的任何受支持的文本生成模型(本例中为 google/gemma-7b-it)部署到 Vertex AI。
设置/配置
首先,您需要在本地机器上安装 gcloud,这是 Google Cloud 的命令行工具,请按照 Cloud SDK 文档 - 安装 gcloud CLI 中的说明进行操作。
然后,您还需要安装 google-cloud-aiplatform Python SDK,这是以编程方式创建 Vertex AI 模型、注册模型、创建端点并在 Vertex AI 上部署模型所需的。
!pip install --upgrade --quiet google-cloud-aiplatform
或者,为了简化本教程中命令的使用,您需要为 GCP 设置以下环境变量
%env PROJECT_ID=your-project-id
%env LOCATION=your-location
%env CONTAINER_URI=us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-text-generation-inference-cu124.2-3.ubuntu2204.py311然后您需要登录您的 GCP 帐户,并将项目 ID 设置为您想要用于在 Vertex AI 上注册和部署模型的项目 ID。
!gcloud auth login
!gcloud auth application-default login # For local development
!gcloud config set project $PROJECT_ID登录后,您需要启用 GCP 中必要的服务 API,例如 Vertex AI API、Compute Engine API 和 Google Container Registry 相关 API。
!gcloud services enable aiplatform.googleapis.com !gcloud services enable compute.googleapis.com !gcloud services enable container.googleapis.com !gcloud services enable containerregistry.googleapis.com !gcloud services enable containerfilesystem.googleapis.com
在 Vertex AI 上注册模型
一切设置完成后,您就可以通过 google-cloud-aiplatform Python SDK 初始化 Vertex AI 会话,如下所示
import os
from google.cloud import aiplatform
aiplatform.init(
project=os.getenv("PROJECT_ID"),
location=os.getenv("LOCATION"),
)由于 google/gemma-7b-it 是一个受控模型,您需要使用具有对受控模型的细粒度访问权限的只读访问令牌,或仅具有对您账户的整体只读访问权限的令牌登录到 Hugging Face Hub 账户。有关如何在 Hugging Face Hub 上生成只读访问令牌的更多信息,请参阅 https://huggingface.co/docs/hub/en/security-tokens 中的说明。
!pip install --upgrade --quiet huggingface_hub
from huggingface_hub import interpreter_login
interpreter_login()然后,您就可以“上传”模型,即在 Vertex AI 上注册模型。这并非严格意义上的上传,因为模型将在启动时通过 MODEL_ID 环境变量从 Hugging Face Hub 中的 Hugging Face TGI DLC 自动下载,因此上传的只是配置,而非模型权重。
在深入代码之前,我们先快速回顾一下提供给 upload 方法的参数
display_name是将在 Vertex AI 模型注册表中显示的名称。serving_container_image_uri是将用于服务模型的 Hugging Face DLC for TGI 的位置。serving_container_environment_variables是将在容器运行时使用的环境变量,因此它们与text-generation-inference定义的环境变量保持一致,这些变量类似于text-generation-launcher参数。此外,Hugging Face 的 TGI DLC 还会捕获 Vertex AI 中的AIP_环境变量,如 Vertex AI 文档 - 预测自定义容器要求 中所述。MODEL_ID是 Hugging Face Hub 中模型的标识符。要探索所有支持的模型,您可以访问 https://huggingface.co/models?sort=trending&other=text-generation-inference。NUM_SHARD是在您不想使用给定机器上的所有 GPU 时使用的分片数量,例如,如果您有两个 GPU 但只想将一个用于 TGI,则NUM_SHARD=1,否则它与CUDA_VISIBLE_DEVICES匹配。MAX_INPUT_TOKENS是允许的最大输入长度(以 token 数量表示),它越大,提示词可以越大,但也会消耗更多的内存。MAX_TOTAL_TOKENS是最重要的设置值,因为它定义了运行客户端请求的“内存预算”,该值越大,每个请求在 RAM 中占用的量就越大,批处理效率就越低。MAX_BATCH_PREFILL_TOKENS限制预填充操作的 token 数量,因为它占用内存最多且受计算限制,因此限制可以发送的请求数量是很有趣的。HUGGING_FACE_HUB_TOKEN是 Hugging Face Hub 令牌,由于google/gemma-7b-it是一个门控模型,因此需要它。
(可选)
serving_container_ports是 Vertex AI 端点将暴露的端口,默认为 8080。
有关支持的 aiplatform.Model.upload 参数的更多信息,请查阅其 Python 参考文档:https://cloud.google.com/python/docs/reference/aiplatform/latest/google.cloud.aiplatform.Model#google_cloud_aiplatform_Model_upload。
从 TGI 2.3 DLC(即 us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-text-generation-inference-cu124.2-3.ubuntu2204.py311)及更高版本开始,您可以将环境变量值 MESSAGES_API_ENABLED="true" 设置为在 Vertex AI 上部署 消息 API,否则将部署 生成 API。
from huggingface_hub import get_token
model = aiplatform.Model.upload(
display_name="google--gemma-7b-it",
serving_container_image_uri=os.getenv("CONTAINER_URI"),
serving_container_environment_variables={
"MODEL_ID": "google/gemma-7b-it",
"NUM_SHARD": "1",
"MAX_INPUT_TOKENS": "512",
"MAX_TOTAL_TOKENS": "1024",
"MAX_BATCH_PREFILL_TOKENS": "1512",
"HUGGING_FACE_HUB_TOKEN": get_token(),
},
serving_container_ports=[8080],
)
model.wait()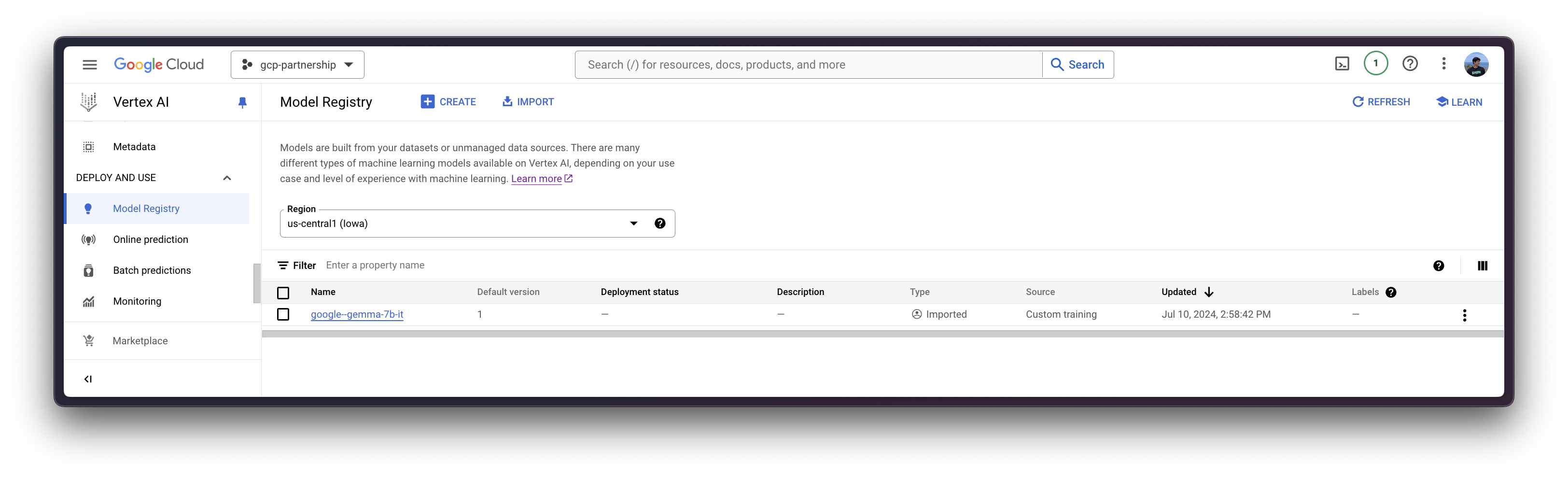
在 Vertex AI 上部署模型
在 Vertex AI 上注册模型后,您需要定义要将模型部署到的端点,然后将模型部署链接到该端点资源。
为此,您需要调用 aiplatform.Endpoint.create 方法来创建一个新的 Vertex AI 端点资源(该资源尚未链接到模型或任何可用的东西)。
endpoint = aiplatform.Endpoint.create(display_name="google--gemma-7b-it-endpoint")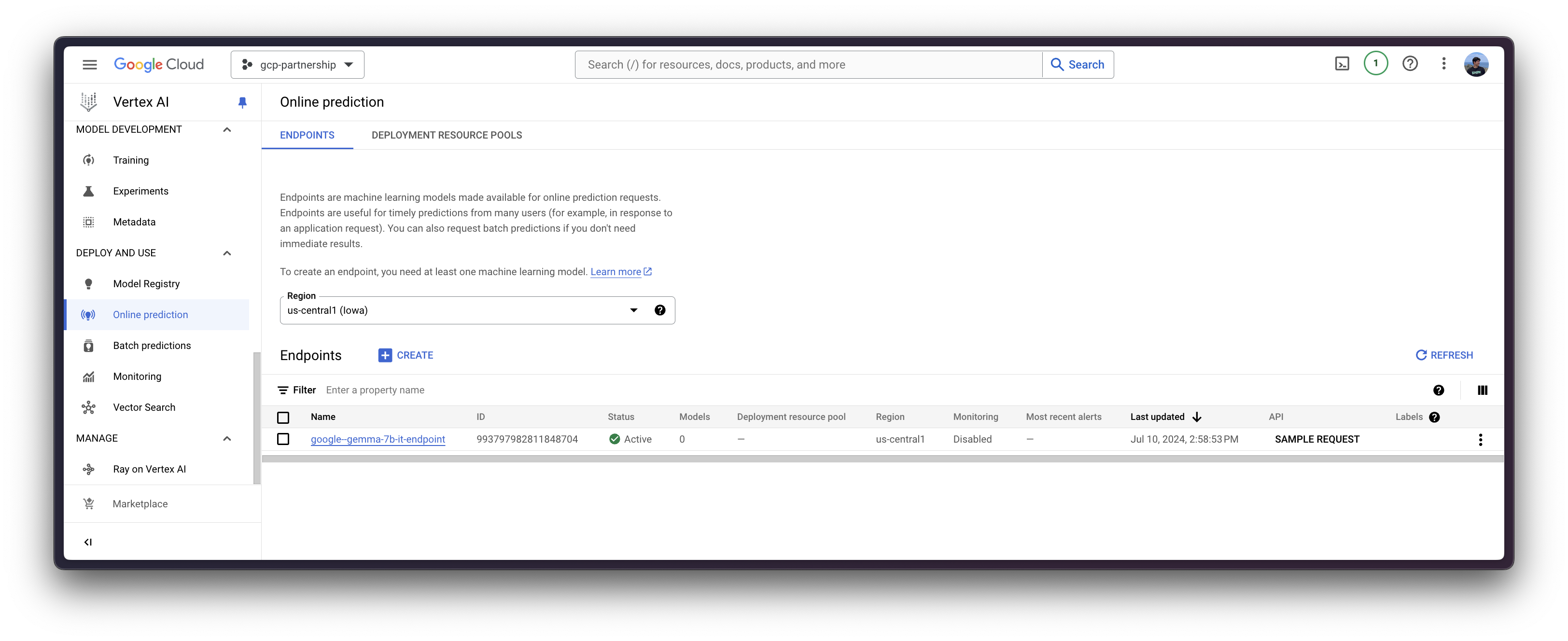
现在您可以在 Vertex AI 上的端点中部署已注册的模型。
deploy 方法会将之前创建的端点资源与包含服务容器配置的模型链接起来,然后将其部署到指定实例的 Vertex AI 上。
在深入代码之前,我们先快速回顾一下提供给 deploy 方法的参数
endpoint是要将模型部署到的端点,它是可选的,默认情况下将设置为模型显示名称加上_endpoint后缀。machine_type、accelerator_type和accelerator_count分别是定义要使用的实例、加速器以及加速器数量的参数。machine_type和accelerator_type是关联的,因此您需要选择支持您正在使用的加速器的实例,反之亦然。有关不同实例的更多信息,请参阅 Compute Engine 文档 - GPU 机器类型,有关accelerator_type命名方式的更多信息,请参阅 Vertex AI 文档 - MachineSpec。
有关受支持的 `aiplatform.Model.deploy` 参数的更多信息,请查阅其 Python 参考资料:https://cloud.google.com/python/docs/reference/aiplatform/latest/google.cloud.aiplatform.Model#google_cloud_aiplatform_Model_deploy。
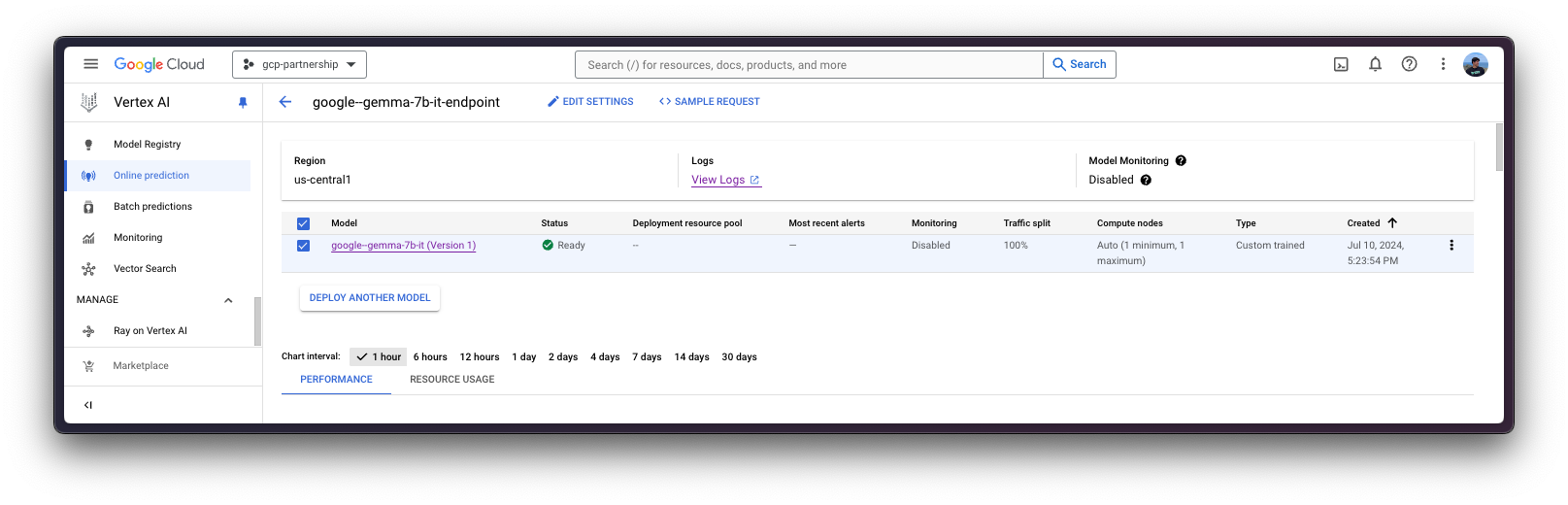
deployed_model = model.deploy(
endpoint=endpoint,
machine_type="g2-standard-4",
accelerator_type="NVIDIA_L4",
accelerator_count=1,
)警告:通过 deploy 方法部署 Vertex AI 端点可能需要 15 到 25 分钟。
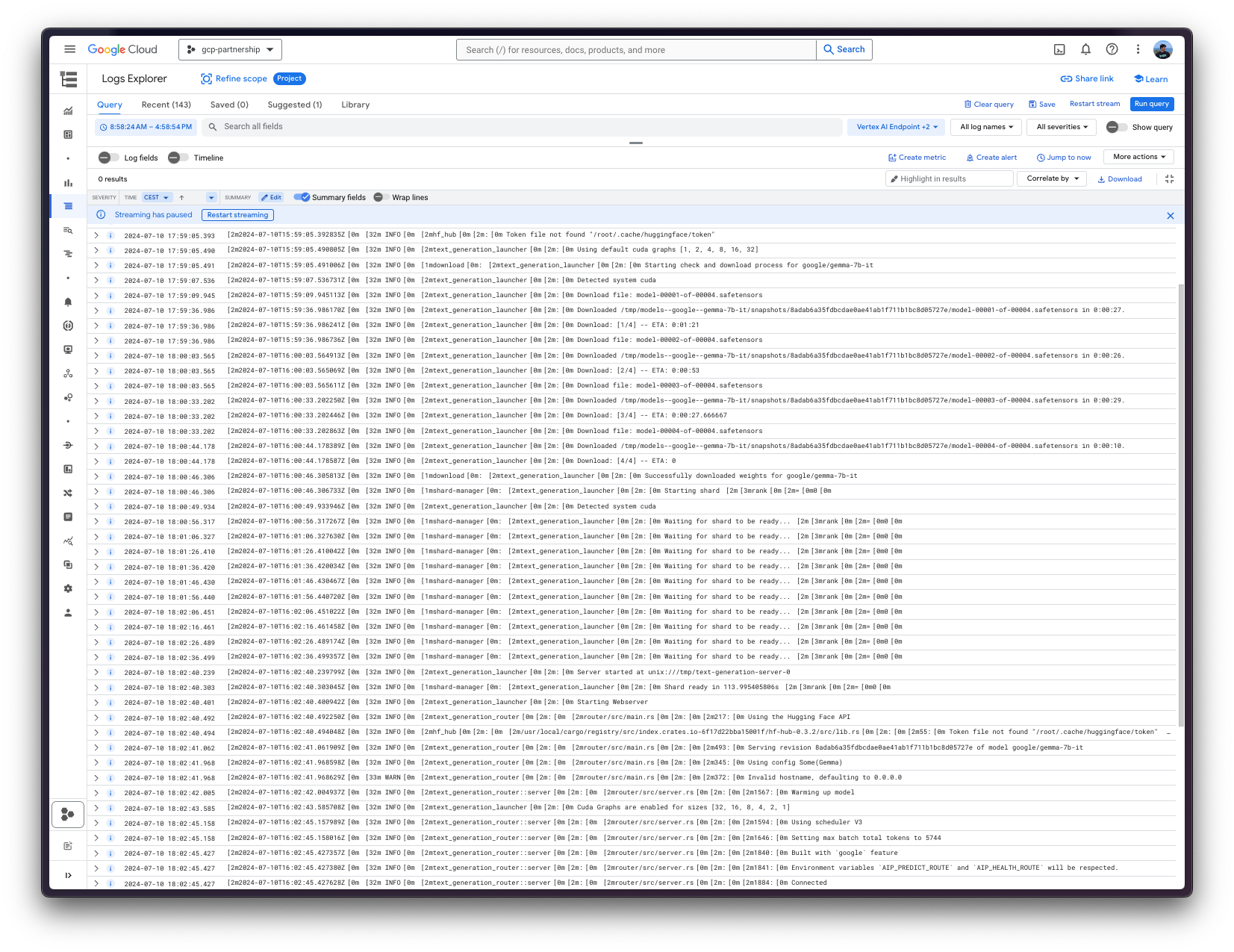
Vertex AI 上的在线预测
最后,您可以使用 `predict` 方法在 Vertex AI 上运行在线预测,该方法将根据 Vertex AI I/O 有效载荷格式,将请求发送到容器中 `/predict` 路由中指定的运行中端点。
由于您正在提供一个 `text-generation` 模型,因此您需要确保对话模板(如果有)已正确应用于输入对话;这意味着需要安装 `transformers`,以便实例化 `google/gemma-7b-it` 的 `tokenizer`,并在将输入发送到 Vertex AI 端点之前,对输入对话运行 `apply_chat_template` 方法。
!pip install --upgrade --quiet transformers
安装完成后,以下代码片段会将聊天模板应用于对话
from huggingface_hub import get_token
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("google/gemma-7b-it", token=get_token())
messages = [
{"role": "user", "content": "What's Deep Learning?"},
]
inputs = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
# <bos><start_of_turn>user\nWhat's Deep Learning?<end_of_turn>\n<start_of_turn>model\n这就是您将通过有效负载发送到已部署的 Vertex AI 端点的内容,以及生成参数,如 https://huggingface.co/docs/huggingface_hub/main/en/package_reference/inference_client#huggingface_hub.InferenceClient.text_generation 中所述。
通过 Python
在同一会话中
如果您希望在当前会话中运行在线预测,可以通过 aiplatform.Endpoint(由 aiplatform.Model.deploy 方法返回)以编程方式发送请求,如下所示
output = deployed_model.predict(
instances=[
{
"inputs": "<bos><start_of_turn>user\nWhat's Deep Learning?<end_of_turn>\n<start_of_turn>model\n",
"parameters": {
"max_new_tokens": 256,
"do_sample": True,
"top_p": 0.95,
"temperature": 1.0,
},
},
]
)
print(output.predictions[0])生成以下 output
Prediction(predictions=['\n\nDeep learning is a type of machine learning that uses artificial neural networks to learn from large amounts of data, making it a powerful tool for various tasks, including image recognition, natural language processing, and speech recognition.\n\n**Key Concepts:**\n\n* **Artificial Neural Networks (ANNs):** Structures that mimic the interconnected neurons in the brain.\n* **Deep Learning Architectures:** Multi-layered ANNs that learn hierarchical features from data.\n* **Transfer Learning:** Reusing learned features from one task to improve performance on another.\n\n**Types of Deep Learning:**\n\n* **Supervised Learning:** Models are trained on labeled data, where inputs are paired with corresponding outputs.\n* **Unsupervised Learning:** Models learn patterns from unlabeled data, such as clustering or dimensionality reduction.\n* **Reinforcement Learning:** Models learn through trial-and-error by interacting with an environment to optimize a task.\n\n**Benefits:**\n\n* **High Accuracy:** Deep learning models can achieve high accuracy on complex tasks.\n* **Adaptability:** Deep learning models can adapt to new data and tasks.\n* **Scalability:** Deep learning models can handle large amounts of data.\n\n**Applications:**\n\n* Image recognition\n* Natural language processing (NLP)\n'], deployed_model_id='***', metadata=None, model_version_id='1', model_resource_name='projects/***/locations/us-central1/models/***', explanations=None)
从不同会话中
如果 Vertex AI 端点是在不同的会话中部署的,并且您想使用它,但无法访问 `aiplatform.Model.deploy` 方法返回的 `deployed_model` 变量(如上一节所示);您也可以运行以下代码片段,通过其资源名称(例如 `projects/{PROJECT_ID}/locations/{LOCATION}/endpoints/{ENDPOINT_ID}`)实例化已部署的 `aiplatform.Endpoint`。
您需要自行通过 Google Cloud 控制台检索资源名称,即 `projects/{PROJECT_ID}/locations/{LOCATION}/endpoints/{ENDPOINT_ID}` URL,或者直接替换下面可以从先前实例化的 `endpoint`(`endpoint.id`)或通过 Google Cloud 控制台在列出端点的在线预测部分找到的 `ENDPOINT_ID`。
import os
from google.cloud import aiplatform
aiplatform.init(project=os.getenv("PROJECT_ID"), location=os.getenv("LOCATION"))
endpoint_display_name = "google--gemma-7b-it-endpoint" # TODO: change to your endpoint display name
# Iterates over all the Vertex AI Endpoints within the current project and keeps the first match (if any), otherwise set to None
ENDPOINT_ID = next(
(endpoint.name for endpoint in aiplatform.Endpoint.list() if endpoint.display_name == endpoint_display_name), None
)
assert ENDPOINT_ID, (
"`ENDPOINT_ID` is not set, please make sure that the `endpoint_display_name` is correct at "
f"https://console.cloud.google.com/vertex-ai/online-prediction/endpoints?project={os.getenv('PROJECT_ID')}"
)
endpoint = aiplatform.Endpoint(
f"projects/{os.getenv('PROJECT_ID')}/locations/{os.getenv('LOCATION')}/endpoints/{ENDPOINT_ID}"
)
output = endpoint.predict(
instances=[
{
"inputs": "<bos><start_of_turn>user\nWhat's Deep Learning?<end_of_turn>\n<start_of_turn>model\n",
"parameters": {
"max_new_tokens": 128,
"do_sample": True,
"top_p": 0.95,
"temperature": 0.7,
},
},
],
)
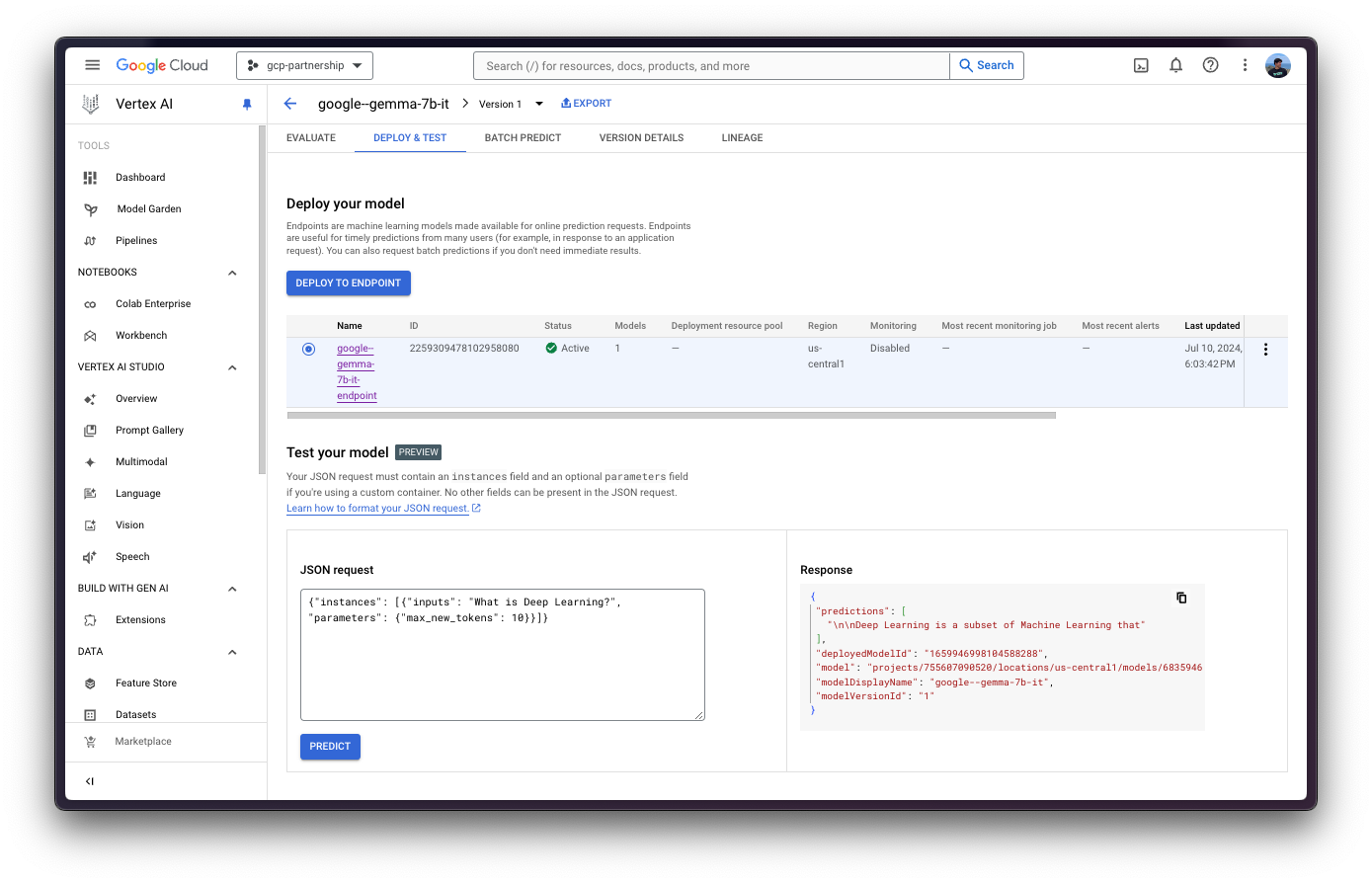
print(output.predictions[0])通过 Vertex AI 在线预测 UI
或者,出于测试目的,你也可以使用 Vertex AI 在线预测用户界面,该界面提供了一个字段,用于输入根据 Vertex AI 规范(如上例所示)格式化的 JSON 有效负载:
{
"instances": [
{
"inputs": "<bos><start_of_turn>user\nWhat's Deep Learning?<end_of_turn>\n<start_of_turn>model\n",
"parameters": {
"max_new_tokens": 128,
"do_sample": true,
"top_p": 0.95,
"temperature": 0.7
}
}
]
}
资源清理
最后,您可以按如下方式释放您已创建的资源,以避免不必要的成本:
deployed_model.undeploy_all用于从所有端点取消部署模型。deployed_model.delete用于在undeploy_all方法后,从部署模型的端点中优雅地删除模型。model.delete用于从注册表中删除模型。
deployed_model.undeploy_all() deployed_model.delete() model.delete()
或者,你也可以按照以下步骤从 Google Cloud Console 中删除这些资源:
- 前往 Google Cloud 中的 Vertex AI
- 前往“部署和使用”->“在线预测”
- 点击端点,然后点击已部署的模型以“从端点取消部署模型”
- 然后返回端点列表并删除该端点
- 最后,前往“部署和使用”->“模型注册表”,然后删除模型
📍 在 GitHub 上查找完整示例:此处!