推理端点(专用)文档
关于推理端点
并获得增强的文档体验
开始使用
关于推理端点
推理端点是一项托管服务,用于将您的 AI 模型部署到生产环境。基础设施经过管理和配置,以便您可以专注于构建您的 AI 应用程序。
要将 AI 模型投入生产,您需要三个关键组件:
模型权重和工件:这些是定义 AI 模型的经过训练的参数和文件,存储并在 Hugging Face Hub 上进行版本控制。
推理引擎:这是加载和运行模型以生成预测的软件。流行的引擎包括 vLLM、TGI 等,每个引擎都针对不同的用例和性能需求进行了优化。
生产基础设施:这就是推理端点。一个可扩展、安全且可靠的环境,您的模型在此环境中运行——处理请求、根据需求进行扩展并确保正常运行时间。
推理端点将所有这些组件整合到一项托管服务中。您从 Hub 中选择模型,选择推理引擎,然后推理端点负责其余部分——调配基础设施、部署模型,并通过简单的 API 使其可访问。这使您能够专注于构建应用程序,而我们负责处理生产 AI 部署的复杂性。
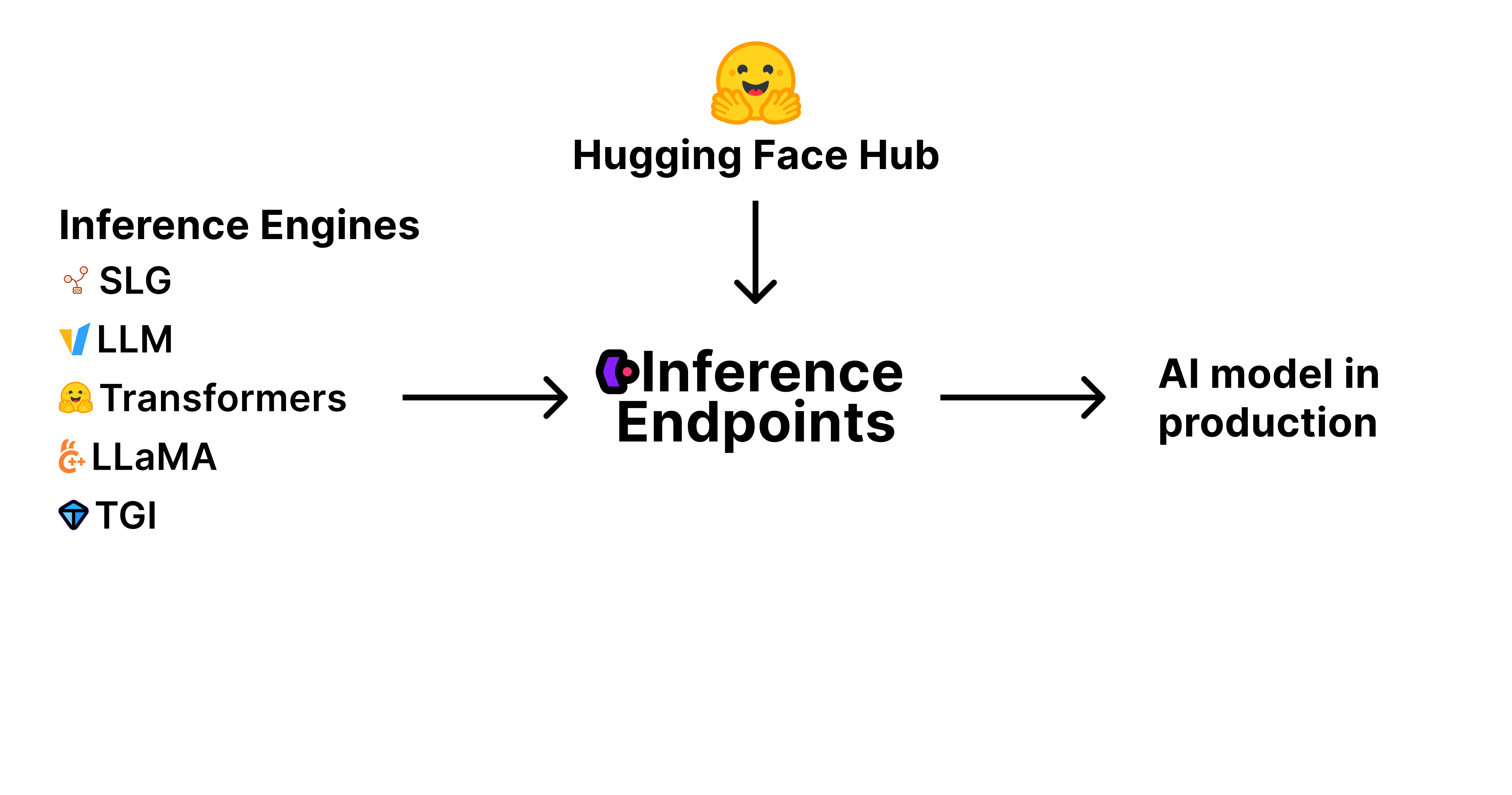
推理引擎
为此,我们已将推理端点打造成部署高性能开源推理引擎的中心位置。
目前,我们原生支持:
- vLLM
- 文本生成推理 (TGI)
- SGLang
- llama.cpp
- 以及文本嵌入推理 (TEI)
对于原生支持的引擎,我们尝试设置合理的默认值,公开最相关的配置设置,并与维护推理引擎的团队密切合作,以确保它们针对生产性能进行优化。
如果您在此处找不到您喜欢的引擎,请通过 api-enterprise@huggingface.co 与我们联系。
幕后
当您部署推理端点时,在幕后,您选择的推理引擎(如 vLLM、TGI、SGLang 等)被打包并作为预构建的 Docker 容器启动。此容器包含推理引擎软件、您选择的模型权重和工件(直接从 Hugging Face Hub 下载),以及您指定的任何配置或环境变量。
我们管理这些容器的完整生命周期:启动、停止、扩展(包括自动扩展和缩放到零),以及监控它们的健康状况和性能。这种编排由我们完全为您管理,因此您无需担心容器化、网络或云资源管理的复杂性。
企业或团队订阅
如需更多功能,请考虑订阅 团队版或企业版。
它让您的组织对访问控制、专属支持等拥有更多控制权。功能包括:
- 更高性能 GPU 的更高配额
- 单点登录 (SSO)
- 访问审计日志
- 使用资源组管理团队和项目访问控制
- 您的存储库的私有存储
- 禁用创建公共存储库的功能(或默认将存储库设置为私有)
- 您可以请求基于合同的发票报价,该报价提供更多付款选项 + 预付积分
- 以及更多!