推理端点(专用)文档
SGLang
加入 Hugging Face 社区
并获得增强的文档体验
开始使用
SGLang
SGLang 是一个用于大型语言模型和视觉语言模型的快速服务框架。它与 TGI 和 vLLM 非常相似,并具有生产就绪功能。
核心功能包括:
快速后端运行时:
- 通过 RadixAttention 实现高效服务,支持前缀缓存
- 零开销 CPU 调度器
- 持续批处理、分页注意力、张量并行和流水线并行
- 专家并行、结构化输出、分块预填充、量化(FP8/INT4/AWQ/GPTQ)和多 LoRA 批处理
广泛的模型支持:支持各种生成模型(Llama、Gemma、Mistral、Qwen、DeepSeek、LLaVA 等)、嵌入模型(e5-mistral、gte、mcdse)和奖励模型(Skywork),并且易于扩展以集成新模型。
配置
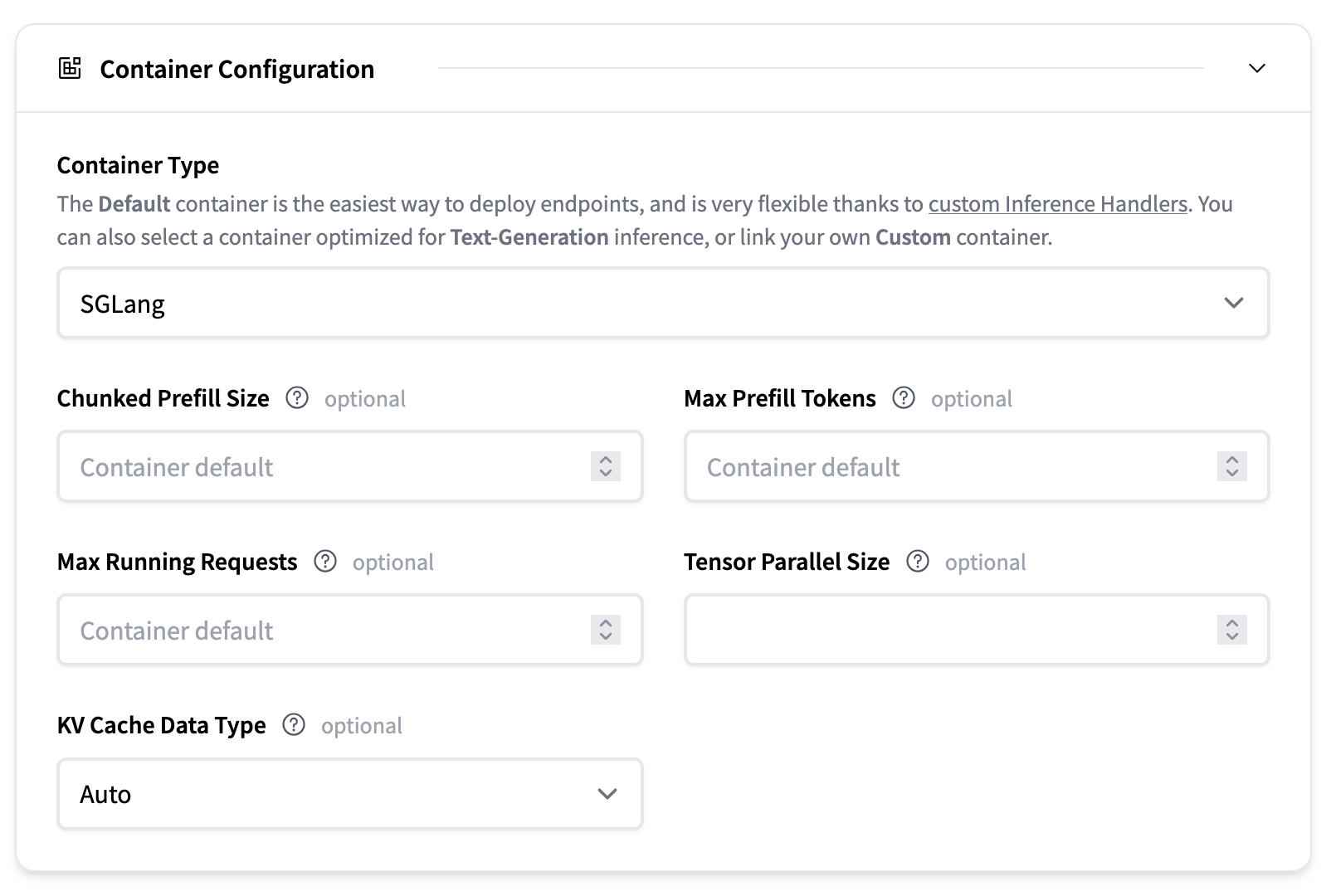
- 最大运行请求数:并发请求的最大数量
- 最大预填充令牌数(每批次):在单个预填充操作中可以处理的最大令牌数。这控制了预填充阶段的批次大小,并有助于在提示处理期间管理内存使用。
- 分块预填充大小:设置在预填充阶段一次处理多少个令牌。如果提示符长于此值,它将被分成更小的块并按顺序处理,以避免在预填充长提示符时出现内存不足错误。例如,将 —chunked-prefill-size 设置为 4096 意味着每个块一次最多处理 4096 个令牌。将其设置为 -1 表示禁用分块预填充。
- 张量并行大小:用于张量并行的 GPU 数量。这允许模型在多个 GPU 上进行分片,以处理无法在单个 GPU 上容纳的更大模型。例如,将其设置为 2 将在 2 个 GPU 上拆分模型。
- KV 缓存 DType:用于在生成过程中存储键值缓存的数据类型。选项包括“auto”、“fp8_e5m2”和“fp8_e4m3”。使用较低精度的类型可以减少内存使用,但可能会稍微影响生成质量。
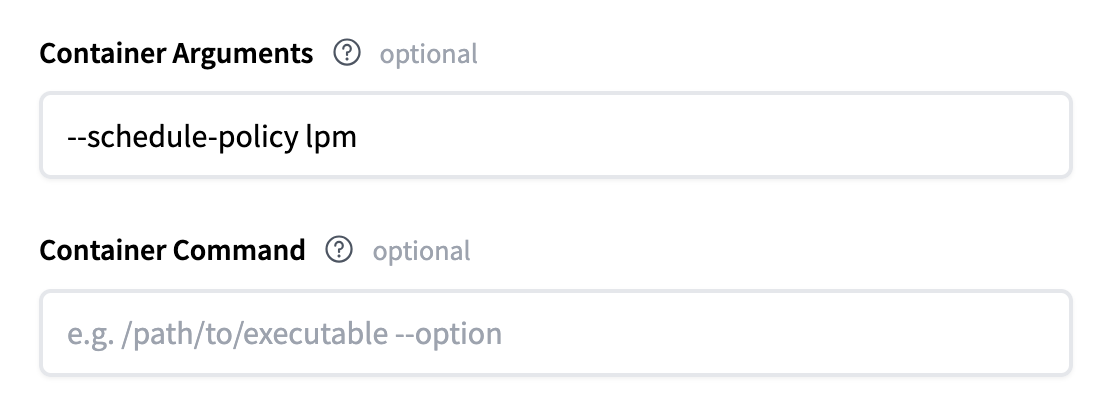
对于更高级的配置,您可以将 SGLang 支持的任何服务器参数作为容器参数传递。例如,将 schedule-policy 更改为 lpm 看起来像这样:
支持的模型
SGLang 广泛支持大型语言模型、多模态语言模型、嵌入模型等。我们建议阅读 SGLang 文档中的支持的模型部分以获取完整列表。
在推理端点 UI 中,默认情况下,Hugging Face Hub 上任何带有 transformers 标签的模型都可以用 SGLang 部署。这是因为如果 SGLang 没有自己的模型实现,SGLang 会实现一个回退来使用 transformers。
参考资料
我们还建议阅读 SGLang 文档以获取更深入的信息。
< > 在 GitHub 上更新