推理端点(专用)文档
使用数据集构建嵌入管道
并获得增强的文档体验
开始使用
使用数据集构建嵌入管道
本教程将引导您部署嵌入端点并构建一个 Python 脚本,以高效处理带有嵌入的数据集。我们将使用强大的 Qwen/Qwen3-Embedding-4B 模型为您的数据创建高质量的嵌入。
本教程侧重于创建可用于生产的脚本,该脚本可以使用 **文本嵌入推理 (TEI)** 引擎处理任何数据集并添加嵌入,以优化性能。
创建您的嵌入端点
首先,我们需要创建一个针对嵌入优化的推理端点。
首先导航到 Inference Endpoints UI,登录后您应该会看到一个用于创建新推理端点的按钮。单击“New”按钮。
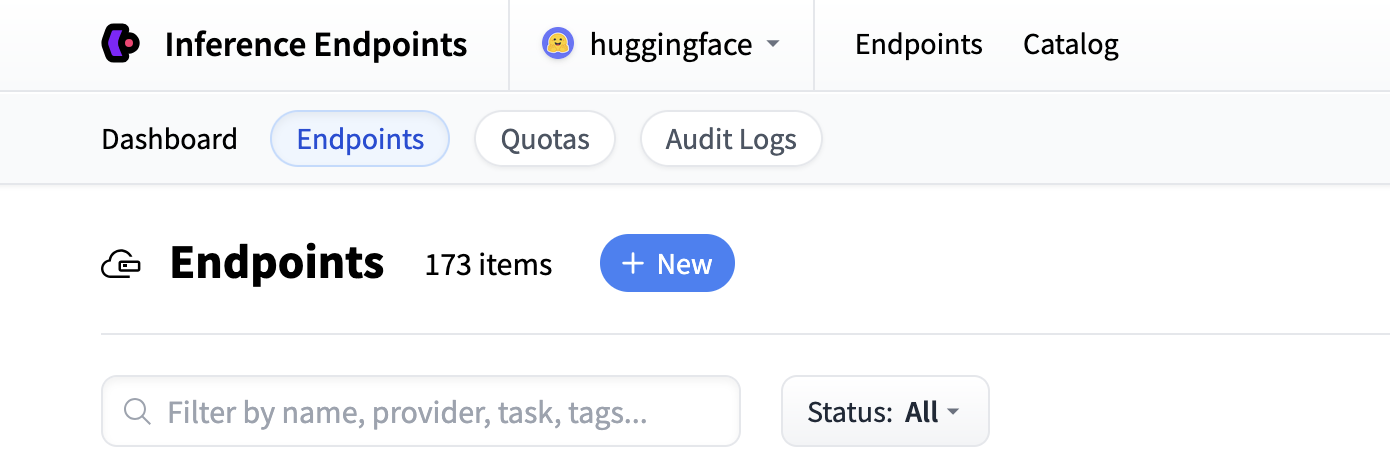
从那里,您将被定向到目录。模型目录包含流行的模型,这些模型具有经过调优的配置,可以一键部署。您可以搜索嵌入模型或创建自定义端点。
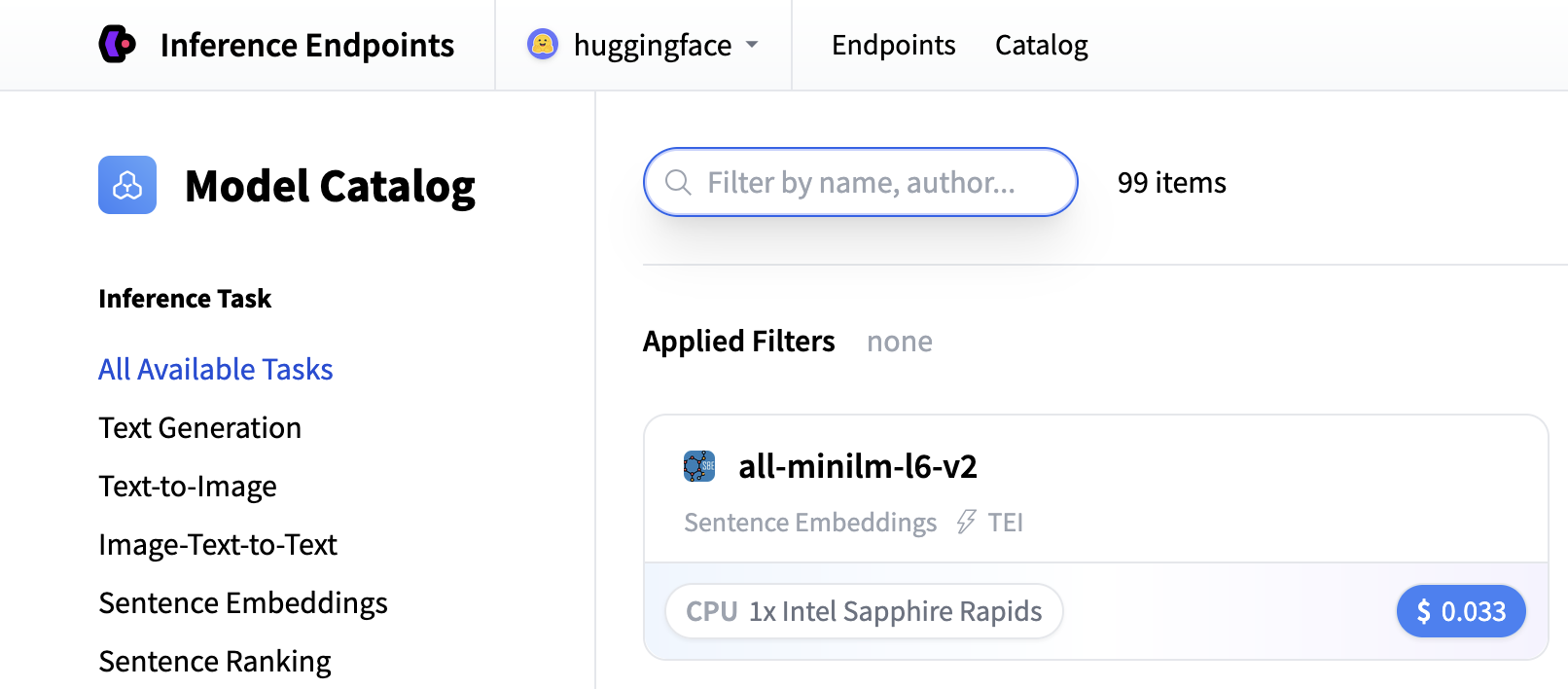
在本教程中,我们将使用推理端点模型目录中提供的 Qwen3-Embedding-4B 模型。请注意,如果它不在目录中,您可以通过输入模型仓库 ID `Qwen/Qwen3-Embedding-4B`,将其作为自定义端点从 Hugging Face Hub 部署。
对于嵌入模型,我们建议使用:
- GPU:NVIDIA、T4、L4 或 A10G,以获得良好性能。
- 实例大小:x1(足以满足大多数嵌入工作负载)
- 自动扩缩:启用缩放到零,以便在不使用端点时将其切换到暂停状态,从而节省成本。
- 超时:设置 10 分钟的超时时间以避免长时间运行的请求。您应该根据预期如何使用端点来定义超时。
如果您正在寻找计算要求较低的模型,可以使用 sentence-transformers/all-MiniLM-L6-v2 模型。
Qwen3-Embedding-4B 模型将自动使用 **文本嵌入推理 (TEI)** 引擎,该引擎提供优化的推理和自动批处理。
点击“创建端点”以部署您的嵌入服务。
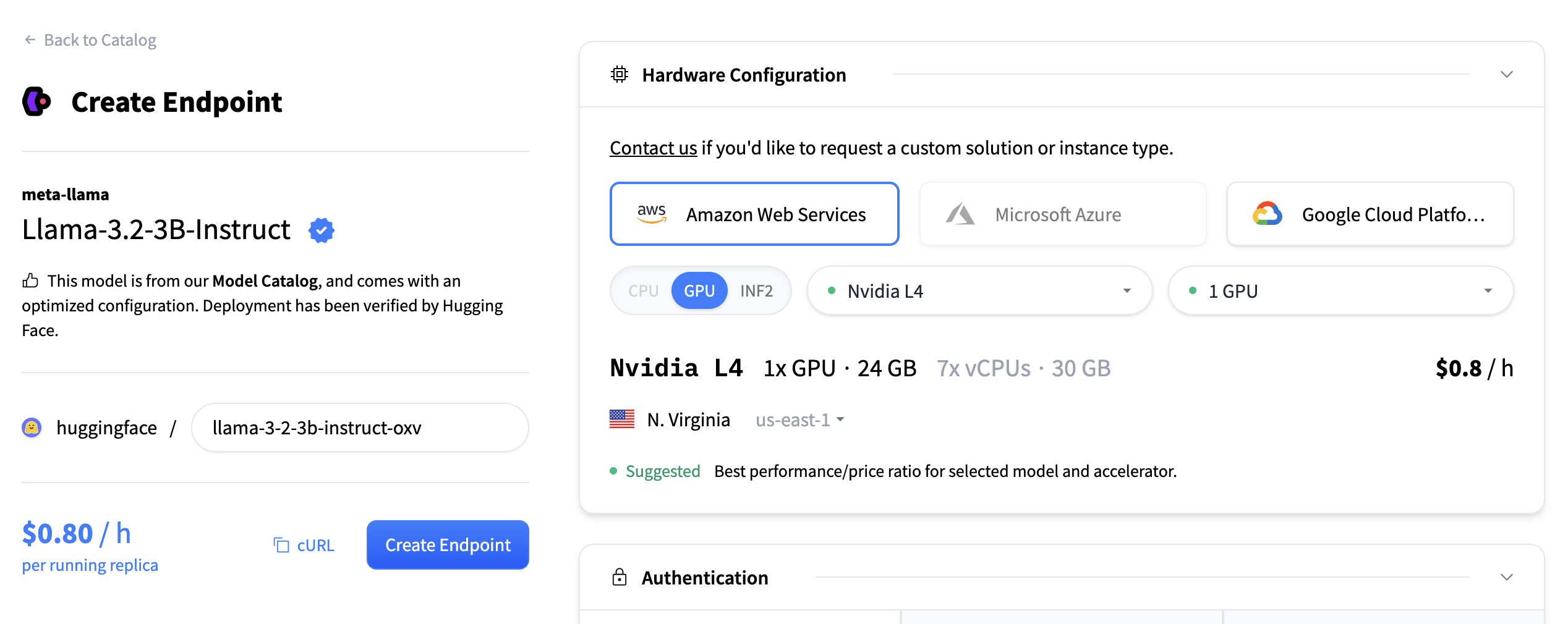
这可能需要大约 5 分钟来初始化。
测试您的端点
推理端点运行后,您可以在游乐场中直接测试它。它接受文本输入并返回高维向量。
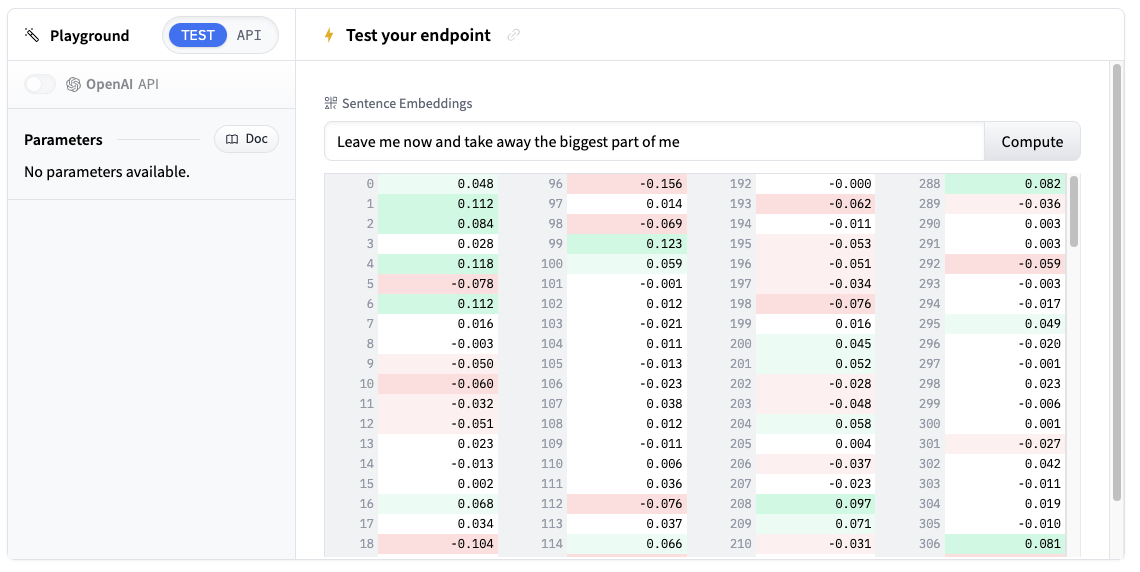
尝试输入一些示例文本,例如“机器学习正在改变我们处理数据的方式”,并查看嵌入输出。
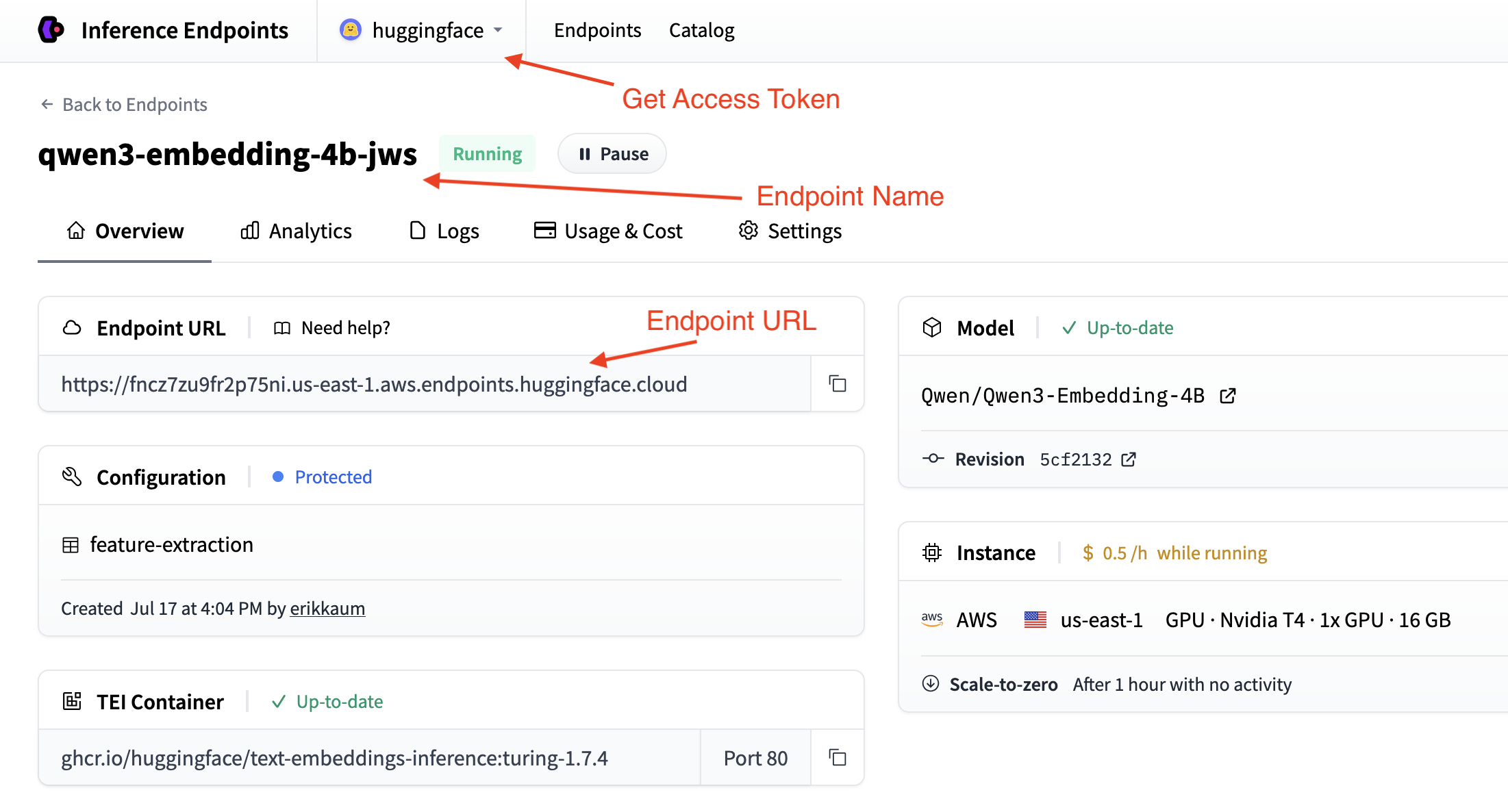
获取您的端点详细信息
要以编程方式使用您的端点,您需要从端点的 概述 中获取这些详细信息:
- 基本 URL:`https://<endpoint-name>.endpoints.huggingface.cloud/v1/`
- 模型名称:您的端点名称
- 令牌:您从 设置 中获取的 HF 令牌
构建嵌入脚本
现在,让我们逐步构建一个处理带有嵌入的数据集的脚本。我们将它分解成逻辑块。
步骤 1:设置依赖项和导入
我们将使用 OpenAI 客户端连接到端点,并使用 `datasets` 库加载和处理数据集。因此,我们首先安装所需的包:
pip install datasets openai
然后,在一个新的 Python 文件中设置您的导入:
import os
from datasets import load_dataset
from openai import OpenAI步骤 2:配置连接
根据您上一步收集的详细信息,设置连接到推理端点的配置。
# Configuration
ENDPOINT_URL = "https://your-endpoint-name.endpoints.huggingface.cloud/v1/" # Endpoint URL + version
HF_TOKEN = os.getenv("HF_TOKEN") # Your Hugging Face Hub token from hf.co/settings/tokens
# Initialize OpenAI client for your endpoint
client = OpenAI(
base_url=ENDPOINT_URL,
api_key=HF_TOKEN,
)您的 OpenAI 客户端现在已配置为连接到您的推理端点。如需进一步阅读,您可以查阅文本嵌入客户端文档 此处。
步骤 3:创建嵌入函数
接下来,我们将创建一个函数来处理批量的文本并返回嵌入。
def get_embeddings(examples):
"""Get embeddings for a batch of texts."""
response = client.embeddings.create(
model="your-endpoint-name", # Replace with your actual endpoint name
input=examples["context"], # In the squad dataset, the text is in the "context" column
)
# Extract embeddings from response objects
embeddings = [sample.embedding for sample in response.data]
return {"embeddings": embeddings} # datasets expects a dictionary with a key "embeddings" and a value of a list of embeddings`datasets` 库将向我们的函数传递一批来自数据集的示例,作为批量值的字典。键将是我们要嵌入的列的名称,值将是该列的值列表。
步骤 4:加载和处理您的数据集
加载您的数据集并应用嵌入函数
# Load a sample dataset (you can replace this with your own)
dataset = load_dataset("squad", split="train[:100]") # Using first 100 examples for demo
# Process the dataset with embeddings
dataset_with_embeddings = dataset.map(
get_embeddings,
batched=True,
batch_size=10, # Process in small batches to avoid timeouts
desc="Adding embeddings",
)数据集库的 `map` 函数经过优化,可自动为我们批处理行。推理端点还可以根据批量大小的需求进行扩展,因此为了获得最佳性能,您应该根据推理端点的配置校准批量大小。
例如,为您的模型选择尽可能高的批处理大小,并将批处理大小与推理端点在 `max_concurrent_requests` 中的配置同步。
步骤 5:保存并分享您的结果
最后,让我们将嵌入式数据集本地保存或推送到 Hugging Face Hub
# Save the processed dataset locally
dataset_with_embeddings.save_to_disk("./embedded_dataset")
# Or push directly to Hugging Face Hub
dataset_with_embeddings.push_to_hub("your-username/squad-embeddings")后续步骤
干得好!您现在已经构建了一个可以处理任何数据集的嵌入管道。以下是完整的脚本:
点击查看完整脚本
import os
from datasets import load_dataset
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
# Configuration
ENDPOINT_URL = "https://your-endpoint-name.endpoints.huggingface.cloud/v1/"
HF_TOKEN = os.getenv("HF_TOKEN")
# Initialize OpenAI client for your endpoint
client = OpenAI(
base_url=ENDPOINT_URL,
api_key=HF_TOKEN,
)
def get_embeddings(examples):
"""Get embeddings for a batch of texts."""
response = client.embeddings.create(
model="your-endpoint-name", # Replace with your actual endpoint name
input=examples["context"],
)
# Extract embeddings from response
embeddings = [sample.embedding for sample in response.data]
return {"embeddings": embeddings}
# Load a sample dataset (you can replace this with your own)
print("Loading dataset...")
dataset = load_dataset("squad", split="train[:1000]") # Using first 1000 examples for demo
# Process the dataset with embeddings
print("Processing dataset with embeddings...")
dataset_with_embeddings = dataset.map(
get_embeddings,
batched=True,
batch_size=10, # Process in small batches to avoid timeouts
desc="Adding embeddings",
)
# Save the processed dataset locally
print("Saving processed dataset...")
dataset_with_embeddings.save_to_disk("./embedded_dataset")
# Or push directly to Hugging Face Hub
print("Pushing to Hugging Face Hub...")
dataset_with_embeddings.push_to_hub("your-username/squad-embeddings")
print("Dataset processing complete!")以下是一些扩展脚本的方法:
- 处理多个数据集:修改脚本以处理不同的数据集源
- 添加错误处理:为失败的 API 调用实现重试逻辑
- 优化批量大小:试验不同的批量大小以获得更好的性能
- 添加验证:检查嵌入质量和维度
- 自定义预处理:添加文本清洗或规范化步骤
- 构建语义搜索应用程序:使用嵌入构建语义搜索应用程序。
您的嵌入数据集现在已准备好用于语义搜索、推荐系统或 RAG 应用程序等下游任务!
< > 在 GitHub 上更新