推理端点(专用)文档
构建和部署您自己的聊天应用程序
并获得增强的文档体验
开始使用
构建并部署您自己的聊天应用程序
本教程将端到端地指导您如何使用 Hugging Face Inference Endpoints 部署您自己的聊天应用程序。我们将使用 Gradio 创建聊天界面,并使用 OpenAI 客户端连接到推理端点。
本教程使用 Python,但您的客户端可以是任何可以发出 HTTP 请求的语言。您在 Inference Endpoints 上部署的模型和引擎使用 **OpenAI Chat Completions 格式**,因此您可以使用任何 OpenAI 客户端(如 JavaScript、Java 和 Go)连接它们。
创建您的推理端点
首先,我们需要为可以聊天的模型创建一个推理端点。
首先导航到 Inference Endpoints UI,登录后您应该会看到一个用于创建新推理端点的按钮。单击“New”按钮。
从那里您将被定向到目录。模型目录包含流行的模型,这些模型已调整配置以实现一键部署。您可以按名称、任务、硬件价格等进行筛选。
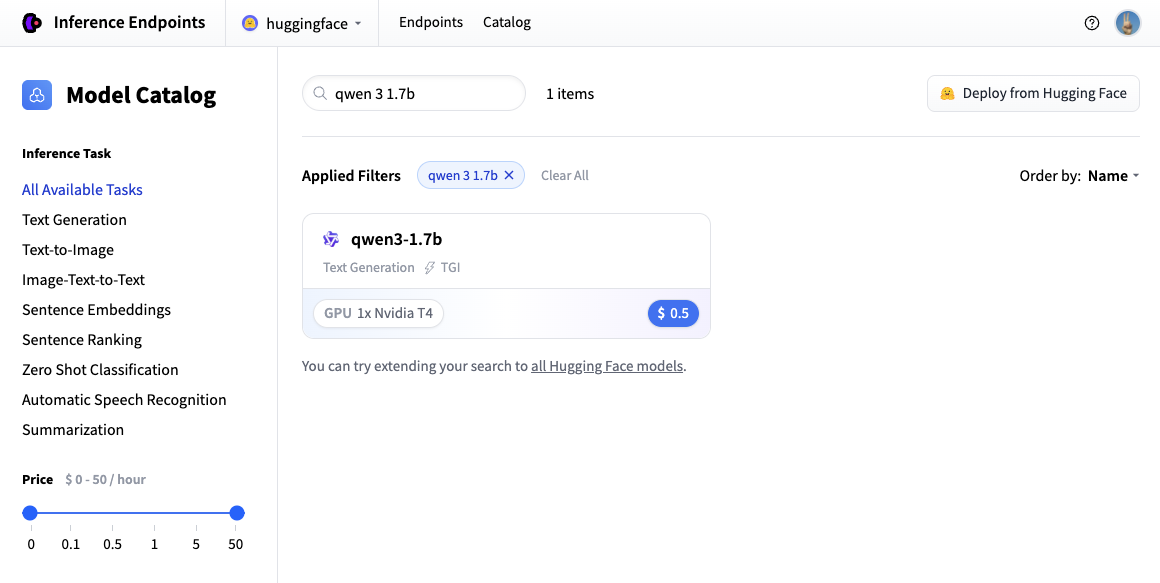
在此示例中,让我们部署 Qwen/Qwen3-1.7B 模型。您可以通过在搜索字段中搜索 qwen3 1.7b 并单击卡片来找到并部署它。
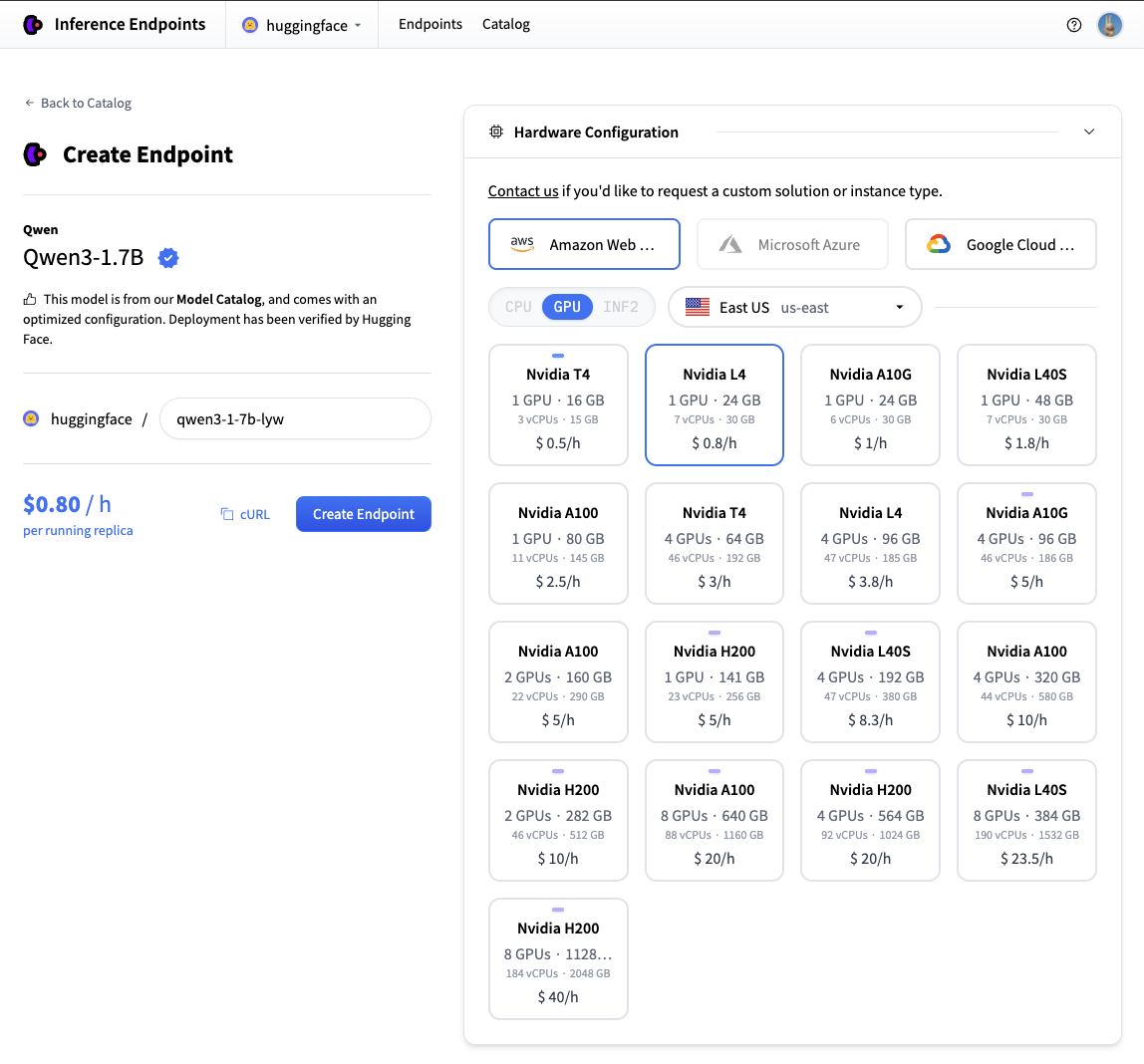
接下来我们将选择我们想要的硬件和部署设置。由于这是一个目录模型,所有预选的选项都是非常好的默认值。因此,在这种情况下,我们不需要更改任何内容。如果您想深入了解不同设置的含义,可以查看 配置指南。
对于此模型,Nvidia L4 是推荐的选择。它将非常适合我们的测试。性能良好但价格合理。另请注意,默认情况下,端点将缩减为零,这意味着它在闲置 1 小时后将进入空闲状态。
现在您所需要做的就是单击“创建端点”🚀
现在我们的推理端点正在初始化,通常需要大约 3-5 分钟。如果您愿意,可以允许浏览器通知,当端点达到运行状态时会给您一个提示。
在浏览器中测试您的推理端点
现在我们已经创建了推理端点,我们可以在 Playground 部分进行测试。
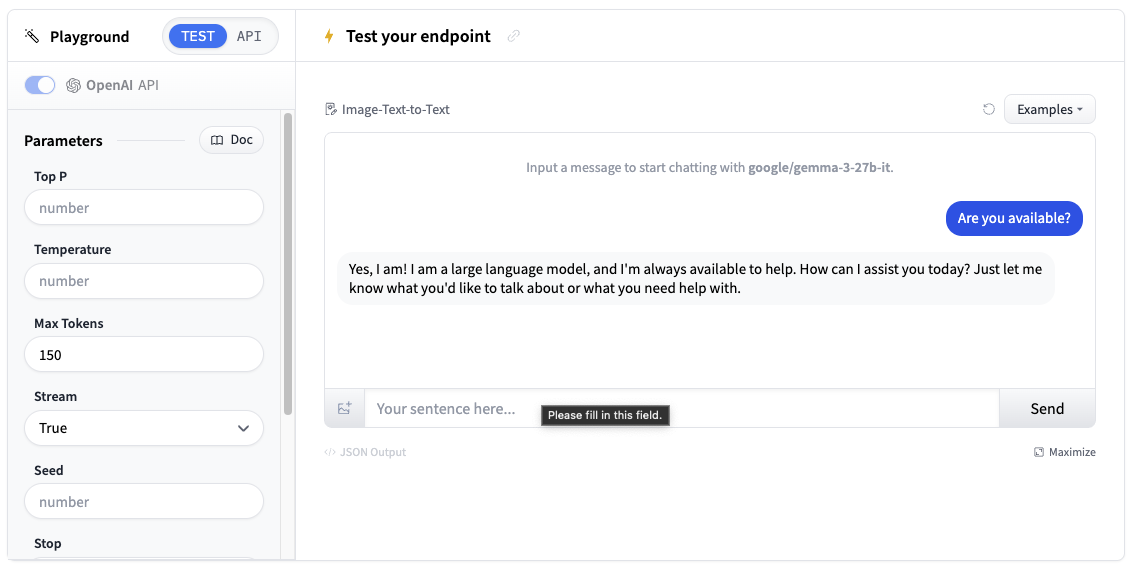
您可以通过聊天界面使用模型,或复制代码片段在您自己的应用程序中使用它。
获取您的推理端点详细信息
我们需要获取推理端点的详细信息,这些信息可以在端点的概览中找到。我们将需要以下详细信息:
- 端点的基本 URL 以及 OpenAI API 的版本(例如,`https://
. . .endpoints.huggingface.cloud/v1/`) - 要使用的端点名称(例如,`qwen3-1-7b-xll`)
- 用于身份验证的令牌(例如,`hf_
`)
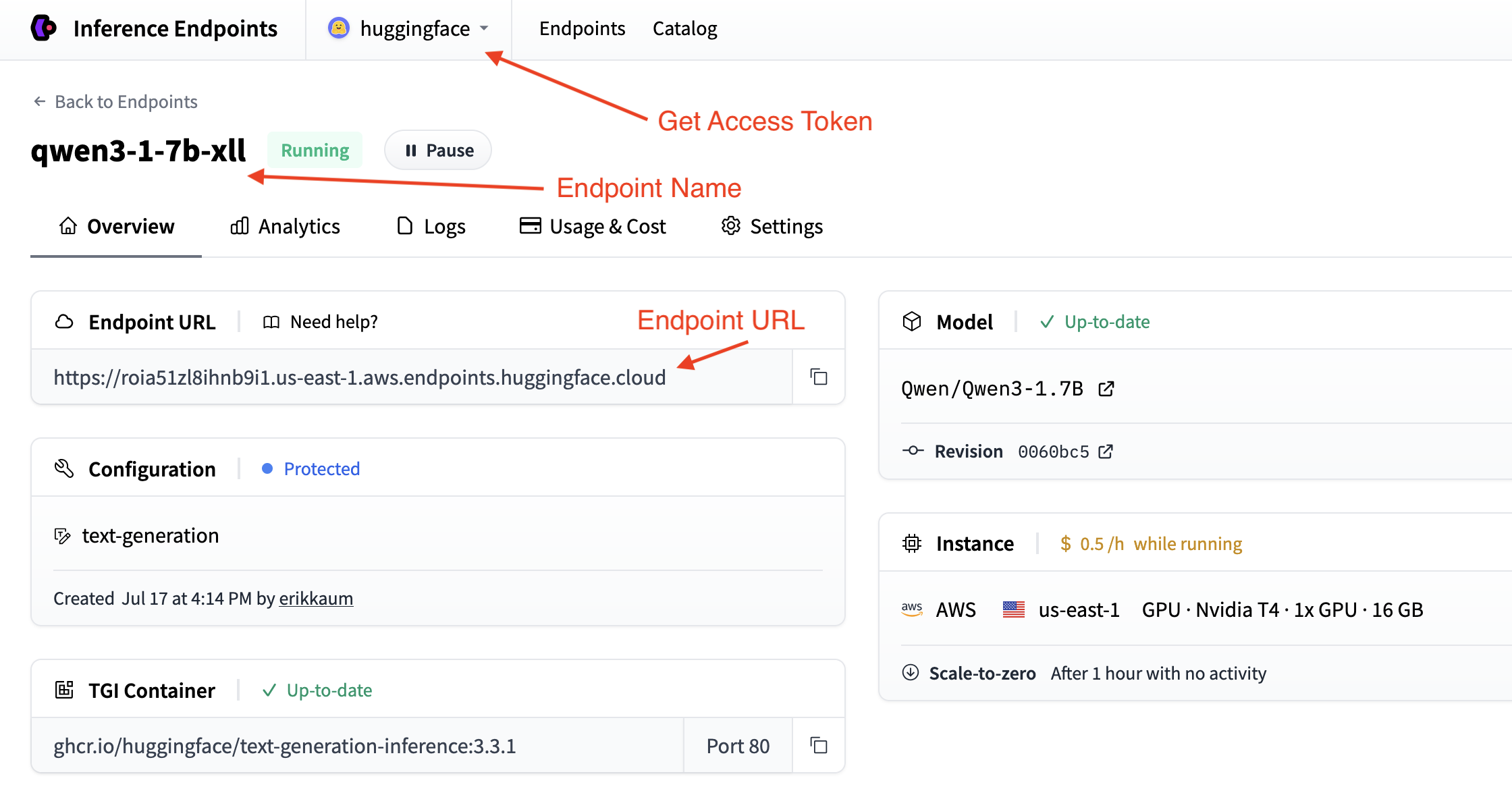
您可以在帐户设置中找到令牌,通过顶部下拉菜单并单击您的帐户名称即可访问。
几行代码即可部署
使用 Gradio 部署聊天应用程序最简单的方法是使用便捷的 load_chat 方法。这抽象了所有内容,您可以快速拥有一个可用的聊天应用程序。
import os
import gradio as gr
gr.load_chat(
base_url="<endpoint-url>/v1/", # Replace with your endpoint URL + version
model="endpoint-name", # Replace with your endpoint name
token=os.getenv("HF_TOKEN"), # Replace with your token
).launch()load_chat 方法无法满足您的生产需求,但它是入门和测试应用程序的好方法。
构建您自己的自定义聊天应用程序
如果您想更好地控制聊天应用程序,您可以使用 Gradio 构建自己的自定义聊天界面。这为您提供了更大的灵活性来定制行为、添加功能和处理错误。
选择您首选的连接推理端点的方法
使用 Hugging Face InferenceClient
首先,安装所需的依赖项
pip install gradio huggingface-hub
Hugging Face InferenceClient 提供了一个与 OpenAI API 格式兼容的简洁接口
import os
import gradio as gr
from huggingface_hub import InferenceClient
# Initialize the Hugging Face InferenceClient
client = InferenceClient(
base_url="<endpoint-url>/v1/", # Replace with your endpoint URL
token=os.getenv("HF_TOKEN") # Use environment variable for security
)
def chat_with_hf_client(message, history):
# Convert Gradio history to messages format
messages = [{"role": msg["role"], "content": msg["content"]} for msg in history]
# Add the current message
messages.append({"role": "user", "content": message})
# Create chat completion
chat_completion = client.chat.completions.create(
model="endpoint-name", # Use the name of your endpoint (i.e. qwen3-1.7b-instruct-xxxx)
messages=messages,
max_tokens=150,
temperature=0.7,
)
# Return the response
return chat_completion.choices[0].message.content
# Create the Gradio interface
demo = gr.ChatInterface(
fn=chat_with_hf_client,
type="messages",
title="Custom Chat with Inference Endpoints",
examples=["What is deep learning?", "Explain neural networks", "How does AI work?"]
)
if __name__ == "__main__":
demo.launch()添加流式支持
为了获得更好的用户体验,您可以实现流式响应。这将要求我们处理消息并将其 `yield` 给客户端。
以下是如何为每个客户端添加流式传输:
Hugging Face InferenceClient 流式传输
Hugging Face InferenceClient 支持类似于 OpenAI 客户端的流式传输
import os
import gradio as gr
from huggingface_hub import InferenceClient
client = InferenceClient(
base_url="<endpoint-url>/v1/",
token=os.getenv("HF_TOKEN")
)
def chat_with_hf_streaming(message, history):
# Convert history to messages format
messages = [{"role": msg["role"], "content": msg["content"]} for msg in history]
messages.append({"role": "user", "content": message})
# Create streaming chat completion
chat_completion = client.chat.completions.create(
model="endpoint-name",
messages=messages,
max_tokens=150,
temperature=0.7,
stream=True # Enable streaming
)
response = ""
for chunk in chat_completion:
if chunk.choices[0].delta.content:
response += chunk.choices[0].delta.content
yield response # Yield partial response for streaming
# Create streaming interface
demo = gr.ChatInterface(
fn=chat_with_hf_streaming,
type="messages",
title="Streaming Chat with Inference Endpoints"
)
demo.launch()部署您的聊天应用程序
我们的应用程序将在端口 7860 上运行,看起来像这样:
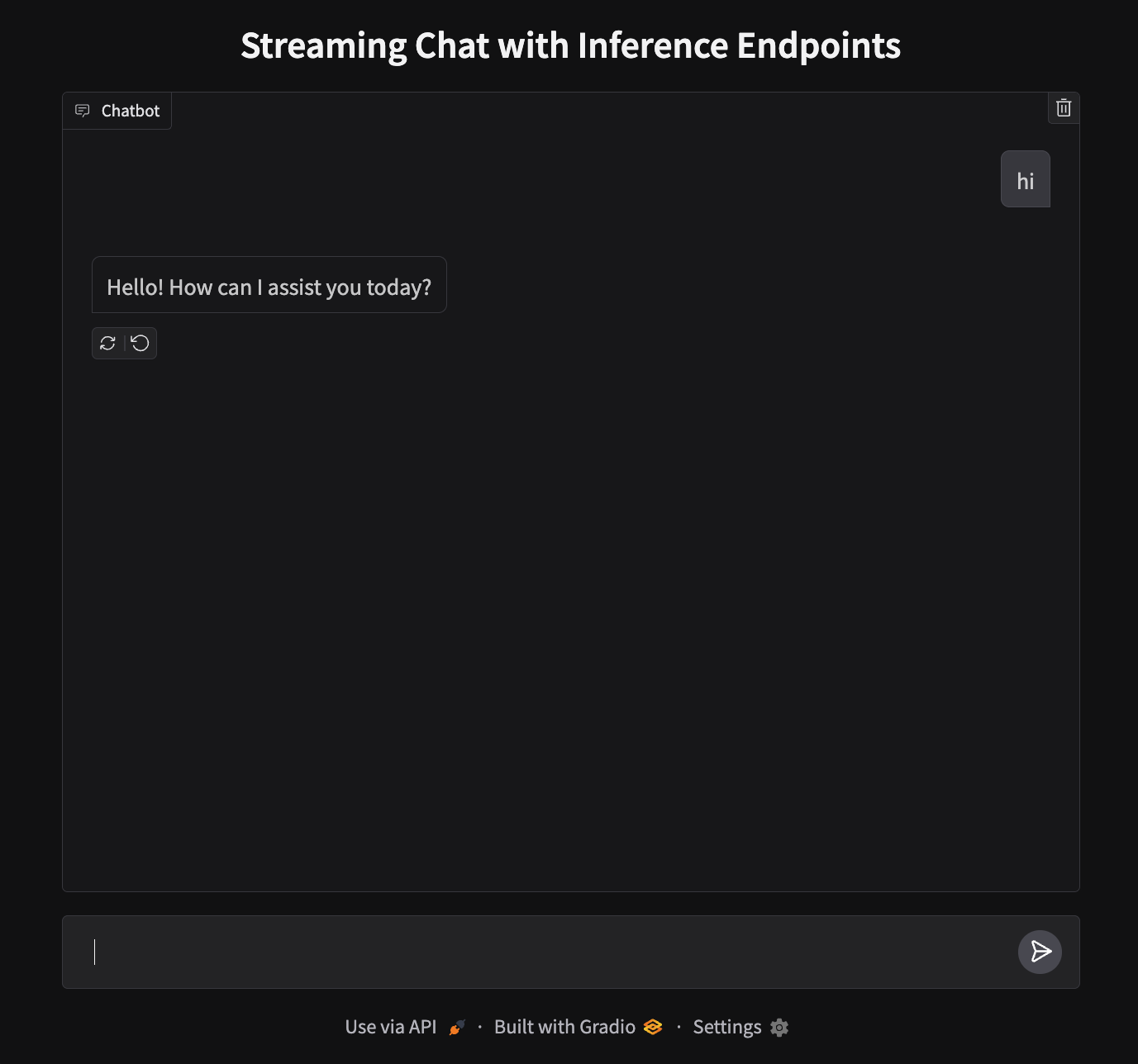
要部署,我们需要创建一个新的空间并上传我们的文件。
- 创建一个新空间:前往 huggingface.co/new-space
- 选择 Gradio SDK 并将其设置为公开
- 上传您的文件:上传
app.py - 添加您的令牌:在空间设置中,将
HF_TOKEN添加为秘密(从您的设置中获取) - 启动:您的应用程序将在
https://huggingface.co/spaces/your-username/your-space-name上上线
注意:虽然我们在本地使用 CLI 身份验证,但 Spaces 要求将令牌作为部署环境的秘密。
下一步
就是这样!您现在拥有一个在 Hugging Face Spaces 上运行的聊天应用程序,由 Inference Endpoints 提供支持。
何不更进一步,尝试下一个指南来构建一个文本转语音应用程序呢?
< > 在 GitHub 上更新